CCTV와 범죄 검거율
 평소에 tv를 보면 드라마 같은 곳에서 도주하는 범인을 cctv로 추적해서 따라가 체포하는 장면을 보신적이 있으신가요?
평소에 tv를 보면 드라마 같은 곳에서 도주하는 범인을 cctv로 추적해서 따라가 체포하는 장면을 보신적이 있으신가요?
저는 이런 장면을 볼 때 마다 진짜로 CCTV가 범인을 잡는데 도움을 줄까? 하고 생각을 합니다.
그래서 저는 이러한 궁금증을 풀기 위해서 데이터를 분석해 보았습니다.
참고로 이 코드는 google colab을 사용하여 작업하였습니다.
코드를 작성하기 전에 어떠한 데이터가 필요할까요?
일단 CCTV에 대한 데이터가 필요할 것이고, 범죄 검거율을 구하기 위한 데이터가 필요합니다.
그래서 이러한 정보를 얻기 위해 국가통계포털에 들어가서 자료를 찾았습니다.
CCTV 설치/운영 현황
중요범죄발생및검거현황
지역별 면적
저는 이렇게 3개의 데이터를 이용했습니다.
사용할 라이브러리
먼저 사용할 라이브러리 부터 불러왔습니다.
import matplotlib.pyplot as plt
import csv
import pandas as pd
from scipy.stats import pearsonr파일에서 정보를 불러오기 위한 pandas,csv 라이브러리, 데이터 시각화를 위한 matplotlib 라이브러리, 그리고 피어슨 상관 계수를 구하기 위한 pearsonr 라이브러리를 사용했습니다.
데이터 구하기
일단은 구해야할 값은 지역 '면적/CCTV개수'랑 '범죄 검거율'을 구해야 합니다.
먼적 '면적/CCTV개수'를 구하겠습니다.
f_cctv = open('/content/CCTV_설치_운영_현황_20230216233331.csv', encoding = 'cp949')
data_cctv = csv.reader(f_cctv)
cctv = []
for row in data_cctv:
if '지역별' in row[0]:
cctv.append(int(row[8]))지열별로 현재 설치되고 운행하고 있는 CCTV 수를 CCTV 배열 안에 순서대로 추가합니다.
area = []
data_area = pd.read_csv('/content/지역별_면적_20230216233535.csv', skiprows=17, header=None, encoding = 'cp949')
for row in data_area[5]:
area.append(row)그리고 지역의 면적을 불러옵니다. 해당 파일에는 위쪽에는 북한의 지역 면적에 대한 값이 있기 때문에 skiprows를 이용하여 해당 열을 건너뛰고 그 뒤의 값을 area 배열에 추가합니다.
위 값을 이용하여 area/cctv 값을 구합니다.
cctv_area = []
for i in range(len(area)):
cctv_area.append(int(area[i]*1000000)/int(cctv[i]))해당 값을 cctv_area 배열에 순서대로 추가합니다.
그럼 다음 필요한 범죄 검거율을 구해보겠습니다.
f_arrest = open('/content/중요범죄발생및검거현황_시도__20230216233349.csv', encoding='cp949')
data_arrest = csv.reader(f_arrest)
crime = []
arrest = []
for row in data_arrest:
if '전국' not in row[0]:
if '경찰청' not in row[0]:
if '해양경비 안전본부' not in row[0]:
if '총범죄' in row[1]:
crime.append(row[2])
arrest.append(row[3])해당 파일 중에 세부적인 범죄를 제외하고 총범죄에 대한 발생건수, 검거 건수를 각각 crime, arrest 배열에 추가합니다.
그리고 이 값을 arrest/crime을 하고 백분율을 하여 검거율을 구합니다.
arrest_rate = []
for i in range(len(crime)):
arrest_rate.append((int(arrest[i])/int(crime[i]))*100)그 값을 arrest_rate 배열에 추가 합니다.
그러면 이제 시각화를 할 준비가 모두 되었습니다.
시각화 하기
plt.scatter(cctv_area,arrest_rate)
plt.xlabel('cctv 개당 면적(m^2)')
plt.ylabel('검거율(%)')
plt.grid(True)
plt.show아까 구해놨던 데이터를 각각 x축 y축으로 설정하고 각 축에 제목을 설정했습니다.
그리고 그리그를 추가 했습니다.
문제 발생!!
이렇게 코드를 작성하고 실행했더니 label의 한국어가 깨지는 문제가 발생했습니다.
그래서 이 문제를 해결할 방법을 찾았더니 폰트를 설치하고 설정을 해주면 된다는 것을 알았습니다.
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf폰트를 설치하고
plt.rc('font', family='NanumBarunGothic')
plt.scatter(cctv_area,arrest_rate)
plt.xlabel('cctv 개당 면적(m^2)')
plt.ylabel('검거율(%)')
plt.grid(True)
plt.show폰트까지 설정해주었습니다.
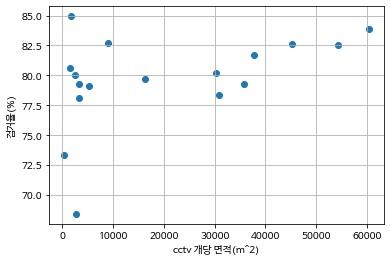
위 코드를 실행한 결과 입니다.
이 산점도를 보면 어느점이 어떤 위치인지 확인하기 어렵습니다.
그래서 구별하기 쉽게 점 옆에 위치를 작성하고, 점의 색을 각각 다르게 해주겠습니다.
f_place = open('/content/CCTV_설치_운영_현황_20230216233331.csv', encoding = 'cp949')
place_data = csv.reader(f_place)
place = []
for row in place_data:
if '지역별' in row[0]:
place.append(row[1])먼저 지역 이름을 가져오고,
import numpy as np
plt.rc('font', family='NanumBarunGothic')
colors = np.random.rand(len(place))
plt.scatter(cctv_area,arrest_rate, c = colors)
plt.xlabel('cctv 개당 면적(m^2)')
plt.ylabel('검거율(%)')
for i in range(len(place)):
plt.text(cctv_area[i], arrest_rate[i], place[i],horizontalalignment='right', fontsize = '12')
plt.grid(True)
plt.showplt.text를 이용하여 글씨를 추가 하고 random을 이용하여 색을 랜덤하게 결정하였습니다.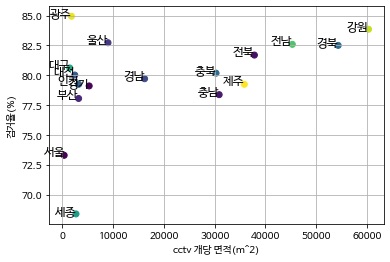
피어슨 상관 계수
위 결과가 상관관계가 있을까? 를 확인하기 위해서 피어슨 상관 계수를 사용했습니다.
피어슨 상관 계수에 대해 설명하면 길어지니깐 설명은 넘어가겠습니다.
print(pearsonr(cctv_area, arrest_rate))위 코드의 결과는 (0.43691416357534146, 0.07949716390378787) 입니다.
앞의 값이 상관계수이고, 뒤의 값이 p값 입니다.
상관계수가 1에 가까우면 양의 상관관계, -1에 가까우면 음의 상관관계를 나타냅니다.
그러면 이 데이터의 상관계수는 약 0.4이기 때문에 양의 상관계수를 갖고 있는 것일까요?
하지만 p값이 0.05 이상이 나오면 상관계수가 없는 것과 같습니다.
그래서 이 데이터의 상관계수는 없다 라고 볼 수 있습니다.
마무리
이 프로젝트를 하면서 새로운 것을 많이 배웠지만 아쉬웠던 점도 있었습니다.
그건 데이터 값이 그렇게 많지 않았다는 것입니다.
데이터 1개를 1개의 도시로 잡았고 광역시가 아닌 다른 지역은 충남, 충북 등으로 나뉘어져서 데이터의 개수가 더 적어졌던거 같습니다.
데이터의 개수가 너무 적어서 값이 적확하게 나오지 않은 것은 아닌가 하는 생각도 하게 됩니다.
다음번에는 데이터 값이 더 많은 데이터를 다뤄보고 싶습니다.
이것으로 글을 마치겠습니다.
