<마켓과 머신러닝>
1. 도미 데이터 준비하기
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0, 31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0, 35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0, 500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0, 700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]특성(feature) : 데이터의 특징
2. 도미 데이터 시각화 하기
import matplotlib.pyplot as plt
plt.scatter(bream_length, bream_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()matplotlib를 사용하여 산점도(scatter)로 나타냄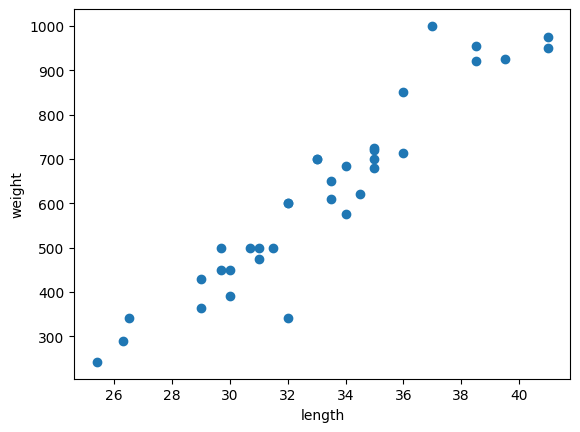
3. 빙어 데이터 준비하기
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]4. 빙어 데이터 시각화 추가하기
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()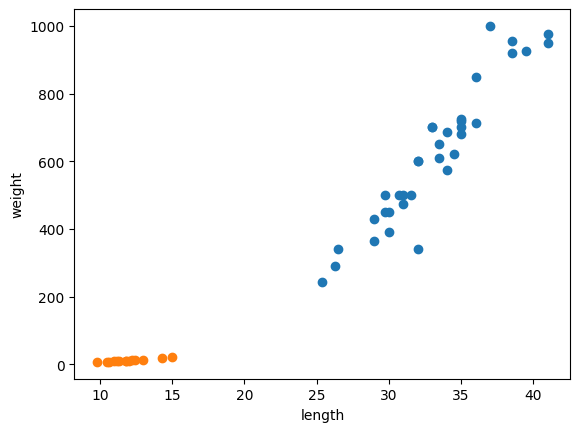
K-근접 이웃 알고리즘(K-NN) 사용하기
K-근접 이웃 알고리즘(K-NN)이란?
- 새로운 데이터 포인트를 분류할 때, 그와 가장 가까운 K개의 이웃 데이터를 참고하여 분류하는 비지도 학습 알고리즘
- 주로 분류(Classification)와 회귀(Regression) 문제에 사용되며, K-NN은 간단하면서도 직관적인 알고리즘
과정
- 거리 계산: 새로운 데이터 포인트와 모든 학습 데이터 포인트 간의 거리를 계산합니다. 가장 많이 쓰이는 거리는 유클리드 거리(Euclidean Distance)이며, 맨해튼 거리나 코사인 유사도 등을 사용하기도 함
- 이웃 선택: 계산된 거리 중 가장 가까운 K개의 이웃을 선택
- 결정: 이웃의 다수결(분류) 또는 평균(회귀)에 따라 새로운 데이터 포인트의 값을 예측
length = bream_length+smelt_length
weight = bream_weight+smelt_weight사이킷런 사용 (2차원 시트를 만드는 머신러닝 패키지)
- zip(0함수로 2차원 그래프를 구성한 후
fish_data = [[l, w] for l, w in zip(length, weight)]결과
[[25.4, 242.0], [26.3, 290.0], [26.5, 340.0], [29.0, 363.0], [29.0, 430.0], [29.7, 450.0], [29.7, 500.0], [30.0, 390.0], [30.0, 450.0], [30.7, 500.0], [31.0, 475.0], [31.0, 500.0], [31.5, 500.0], [32.0, 340.0], [32.0, 600.0], [32.0, 600.0], [33.0, 700.0], [33.0, 700.0], [33.5, 610.0], [33.5, 650.0], [34.0, 575.0], [34.0, 685.0], [34.5, 620.0], [35.0, 680.0], [35.0, 700.0], [35.0, 725.0], [35.0, 720.0], [36.0, 714.0], [36.0, 850.0], [37.0, 1000.0], [38.5, 920.0], [38.5, 955.0], [39.5, 925.0], [41.0, 975.0], [41.0, 950.0], [9.8, 6.7], [10.5, 7.5], [10.6, 7.0], [11.0, 9.7], [11.2, 9.8], [11.3, 8.7], [11.8, 10.0], [11.8, 9.9], [12.0, 9.8], [12.2, 12.2], [12.4, 13.4], [13.0, 12.2], [14.3, 19.7], [15.0, 19.9]][[25.4, 242.0], [26.3, 290.0], [26.5, 340.0], [29.0, 363.0], [29.0, 430.0], [29.7, 450.0], [29.7, 500.0], [30.0, 390.0], [30.0, 450.0], [30.7, 500.0], [31.0, 475.0], [31.0, 500.0], [31.5, 500.0], [32.0, 340.0], [32.0, 600.0], [32.0, 600.0], [33.0, 700.0], [33.0, 700.0], [33.5, 610.0], [33.5, 650.0], [34.0, 575.0], [34.0, 685.0], [34.5, 620.0], [35.0, 680.0], [35.0, 700.0], [35.0, 725.0], [35.0, 720.0], [36.0, 714.0], [36.0, 850.0], [37.0, 1000.0], [38.5, 920.0], [38.5, 955.0], [39.5, 925.0], [41.0, 975.0], [41.0, 950.0], [9.8, 6.7], [10.5, 7.5], [10.6, 7.0], [11.0, 9.7], [11.2, 9.8], [11.3, 8.7], [11.8, 10.0], [11.8, 9.9], [12.0, 9.8], [12.2, 12.2], [12.4, 13.4], [13.0, 12.2], [14.3, 19.7], [15.0, 19.9]]도미는 1, 빙어는 0으로 표현
fish_target = [1]*35 + [0]*14K-최근접 이웃 알고리즘 라이브러리 가져오기
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()머신러닝 학습
kn.fit(fish_data, fish_target)fit 함수
- 훈련 데이터 학습: X와 y를 입력으로 받아 데이터와 정답의 관계를 학습
- 모델 파라미터 최적화: 예측 성능을 최대화할 수 있도록 모델의 내부 파라미터(예: 회귀 계수, 가중치 등)를 최적화
학습 결과 확인
kn.score(fish_data, fish_target)score 함수
- 분류 모델: 예측 결과의 정확도를 반환 (예: KNeighborsClassifier, LogisticRegression)
- 회귀 모델: 결정 계수(𝑅^2스코어)를 반환하여 예측이 얼마나 잘 맞는지를 나타냄. 𝑅^2스코어는 1에 가까울수록 예측이 잘된 것을 의미 (예: LinearRegression, Ridge)
- 모델 비교: 모델의 성능을 다른 모델과 비교하여 최적의 모델을 선택하는 데 도움
- 성능 평가: 주어진 데이터셋에 대한 모델의 성능을 빠르게 평가할 수 있어, 하이퍼파라미터 튜닝 등에서 유용하게 쓰임
데이터 예측 하기
예시 데이터 정하기
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.scatter(30, 600, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()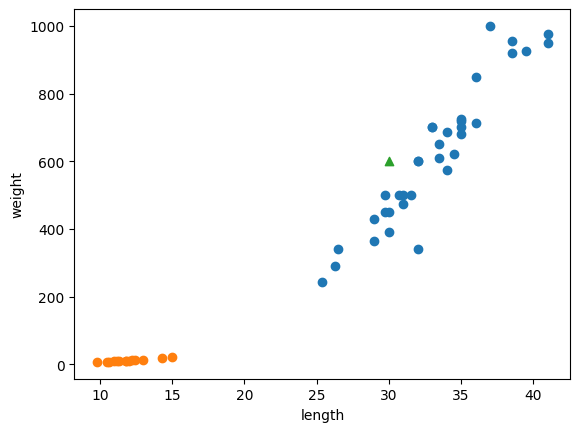
초록색 삼각형을 예시 데이터로 설정
예측하기
kn.predict([[30, 600]])결과
array([1])도미의 결과에 가까움
predict 함수
- 새로운 데이터에 대한 예측 생성: 학습된 모델의 패턴을 기반으로, 새로운 입력 데이터에 대한 결과 값을 예측
- 출력 형식: 입력 데이터의 형식에 따라 단일 값 또는 여러 값으로 이루어진 배열 형태로 반환
- 미지의 데이터 예측: 이미 학습된 모델로 새로운 데이터나 실제 테스트 데이터의 예측값을 빠르게 생성
- 모델 평가 및 비교: predict 함수를 통해 예측한 값과 실제 값을 비교하여, 모델의 성능을 평가하고 최적의 모델을 선택
kn._fit_X : 학습 값 확인
kn._y : 결과 값 확인
지금까지는 가장 가까운 5개의 이웃을 통해서 판별했습니다. 이제는 도미와 빙어의 데이터를 모두 포함한 49개의 데이터를 통해서 판별하도록 해보겠습니다.
49개의 데이터를 사용한 모델 선언 및 학습
kn49 = KNeighborsClassifier(n_neighbors=49)
kn49.fit(fish_data, fish_target)49개의 이웃 고려: n_neighbors=49로 설정하면, 예측할 때 데이터 포인트와 가장 가까운 49개의 학습 데이터 인스턴스를 찾습니다.
다수결 기반 예측: 분류 작업에서는 49개의 이웃 중 가장 많이 등장하는 클래스가 최종 예측 결과가 됩니다.
n_neighbors 설정의 영향
- n_neighbors 값을 크게 설정할수록 더 많은 이웃의 정보를 활용하여 예측이 안정화될 수 있지만, 과소적합(underfitting)될 가능성
- 작은 값으로 설정하면 학습 데이터에 민감해져 과적합(overfitting)이 발생
학습 결과 확인
kn49.score(fish_data, fish_target)결과
0.7142857142857143정확도가 떨어진 것을 확인할 수 있습니다.
이웃 개수에 따른 정확도를 확인해보겠습니다.
이웃 개수에 따른 정확도 확인
kn = KNeighborsClassifier()
kn.fit(fish_data, fish_target)
for n in range(5, 50):
kn.n_neighbors = n
score = kn.score(fish_data, fish_target)
if score < 1:
print(n, score)결과
18 0.9795918367346939
19 0.9795918367346939
20 0.9795918367346939
21 0.9795918367346939
22 0.9795918367346939
23 0.9795918367346939
24 0.9795918367346939
25 0.9795918367346939
26 0.9795918367346939
27 0.9795918367346939
28 0.9591836734693877
29 0.7142857142857143
30 0.7142857142857143
31 0.7142857142857143
32 0.7142857142857143
33 0.7142857142857143
34 0.7142857142857143
35 0.7142857142857143
36 0.7142857142857143
37 0.7142857142857143
38 0.7142857142857143
39 0.7142857142857143
40 0.7142857142857143
41 0.7142857142857143
42 0.7142857142857143
43 0.7142857142857143
44 0.7142857142857143
45 0.7142857142857143
46 0.7142857142857143
47 0.7142857142857143
48 0.7142857142857143
49 0.7142857142857143이웃값이 많아지면 정확도가 떨어지는 것을 확인할 수 있습니다.
원인
- 과소적합(Underfitting)
이웃의 수가 너무 많으면 (예: 49), 모델이 지나치게 일반화되어 특정 데이터 포인트에 대한 민감성이 떨어질 수 있습니다. 이 경우, 여러 클래스가 섞여 있는 데이터에 대한 예측 성능이 저하됩니다.- 데이터의 특성
데이터가 잘 분리되어 있지 않거나 클래스 간에 겹침이 많을 경우, K-NN은 혼동을 일으킬 수 있습니다. 이는 올바른 이웃을 찾기 어렵게 만듭니다.
노이즈와 이상치: 데이터에 노이즈(측정 오류)나 이상치가 포함되어 있을 경우, 가까운 이웃이 잘못된 레이블을 가진 경우가 많아질 수 있습니다. 이로 인해 정확도가 감소합니다.- 특징 스케일링 부족
K-NN은 거리 기반 알고리즘이므로, 입력 특성의 스케일이 다르면 특정 특성이 과도하게 영향을 미칠 수 있습니다. 따라서, 특징의 스케일을 조정하지 않으면 모델 성능이 떨어질 수 있습니다.
예를 들어, 길이 단위와 무게 단위가 서로 다를 경우, K-NN은 더 큰 값의 특성에 따라 이웃을 선택하게 됩니다.- 훈련 데이터의 양
데이터 샘플 수가 충분하지 않으면, 모델이 패턴을 학습하기 어려워지며, 예측 성능이 저하될 수 있습니다.- 복잡한 결정 경계
K-NN은 비선형 경계의 적합에 강하지만, 데이터가 복잡한 분포를 가진 경우 정확도가 떨어질 수 있습니다. 즉, 데이터의 결정 경계가 복잡할수록 모델의 성능이 저하될 수 있습니다.- 하이퍼파라미터 조정 부족
n_neighbors 값을 적절하게 조정하지 않으면, 모델이 과적합하거나 과소적합할 수 있습니다. 적절한 이웃 개수를 찾는 것이 중요합니다.

코딩 공부하는 고등학생