
이번에는 프로세스(Process)에 대해 알아보도록 하자.
프로세스는 실행 중인 프로그램이다.
보조기억장치에 있는 프로그램이 메모리에 적재된 상태를 말한다.
컴퓨터에는 여러 개의 프로세스가 실행되고 있다.
CPU 자원은 한정적이지만 프로세스는 훨씬 많을 수 있다.
이러한 상황에서 운영체제는 프로세스들을 효율적으로 실행하기위해 프로세스 스케줄링을 수행한다.
프로세스의 개념과 운영체제가 프로세스를 어떻게 스케줄링하는지, 프로세스간 통신은 어떻게 이루어지는지 알아보자.
프로세스
프로세스는 실행 중인 프로그램을 말한다.
프로그램이 메모리에 적재되어 실행 중인 것을 말한다.
프로세스는 메모리에 어떻게 적재될까?
아래 그림과 같이 여러 개의 섹션으로 나뉘어져 적재된다.
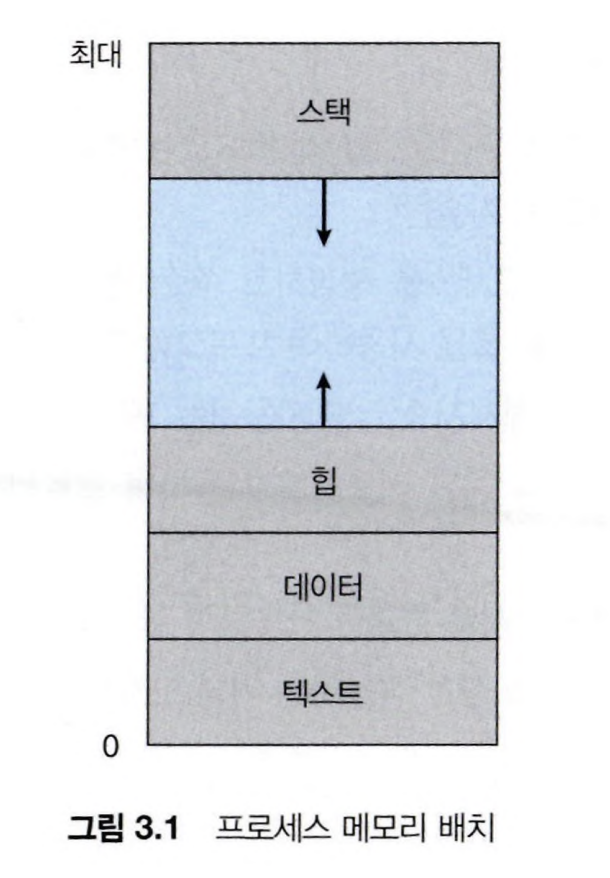
- 텍스트(Text) 섹션
- 프로그램 실행 코드가 포함되어있다.
- 데이터(Data) 섹션
- 전역 변수, 정적 변수가 포함되어있다.
- 힙(Heap) 섹션
- 프로그램 실행 중 동적 할당 받는 메모리가 포함되어 있다.
- 스택(Stack) 섹션
- 함수를 호출할 때 필요한 데이터를 저장할 때 사용된다.
텍스트 및 데이터 섹션의 크기는 고정되어 있어 프로그램 실행 중 변하지 않는다.
스택과 힙은 프로그램 실행 중에 동적으로 줄어들거나 커질 수 있다.
스택에는 함수가 호출될 때마다 함수의 매개변수, 지역변수, 복귀 주소를 포함하는 활성 레코드가 들어가게된다(Push).
함수 호출이 끝나면 활성 레코드가 스택에서 없어진다(Pop).
활성 레코드는 스택 프레임으로 불리기도 한다.
힙은 메모리가 동적 할당 될 때마다 증가하고 메모리 반납시 줄어든다.
스택과 힙이 서로의 방향으로 커지더라도 운영체제는 서로 겹치지 않도록 해야한다.
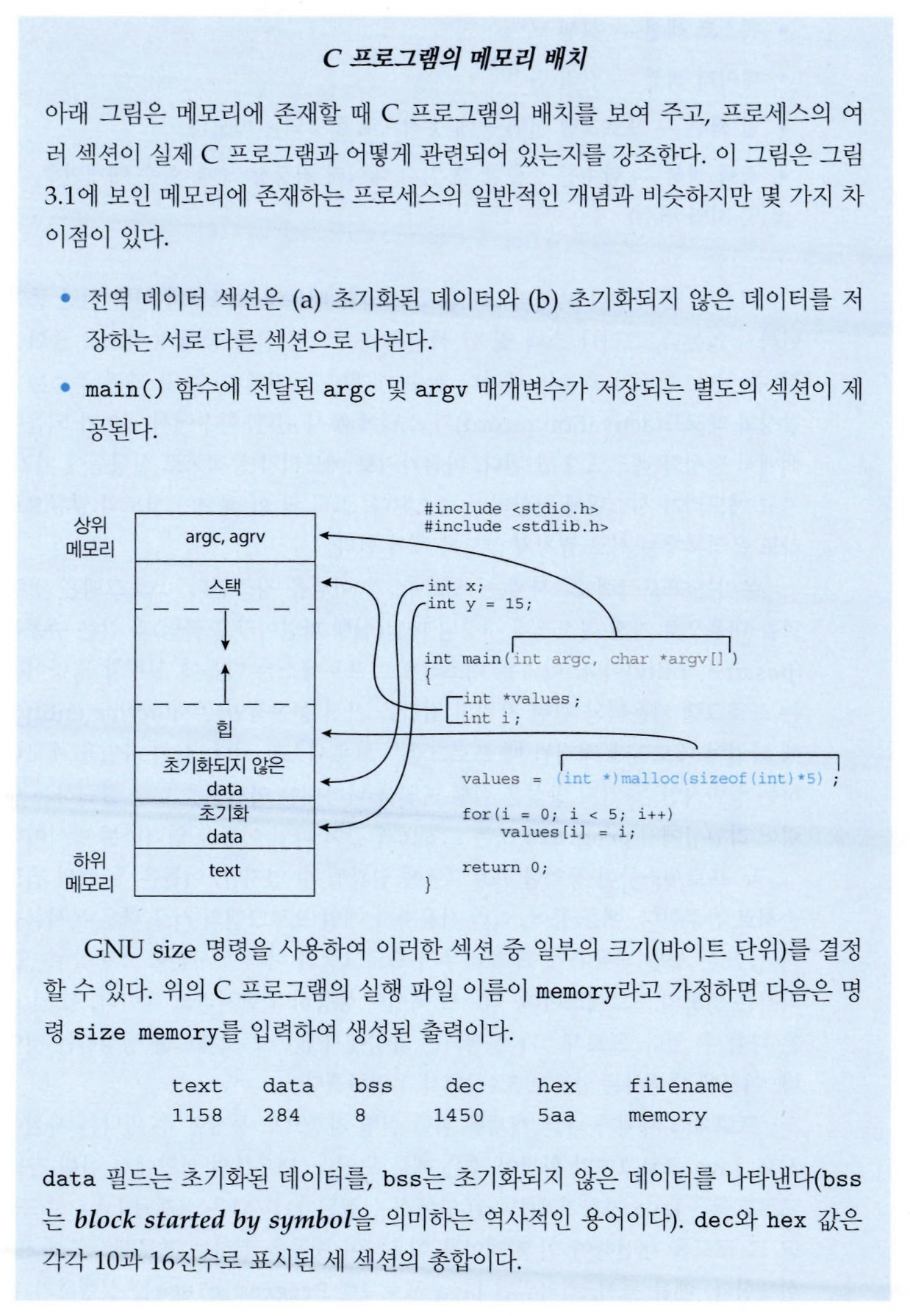
프로세스 상태
프로세스는 실행되면서 어떤 활동을 하는지에 따라 상태가 변한다.
- New
- 프로세스가 생성 중인 상태.
- Ready
- 실행되기를 기다리는 상태.
- Running
- 실행 중인 상태.
- Waiting
- 프로세스가 입출력 작업과 같은 이유로 대기 중인 상태.
- 입출력 완료 인터럽트와 같은 이벤트가 일어나기를 기다린다.
- End
- 프로세스가 종료된 상태.
프로세스 제어 블록(PCB)
각각의 프로세스들은 PCB를 통해 표현된다.
운영체제가 프로세스들을 관리할 때, 프로세스의 PCB를 가지고 관리한다.
PCB에는 프로세스에 관련된 정보들이 들어있다.
PCB에 저장되는 정보는 다음과 같다.
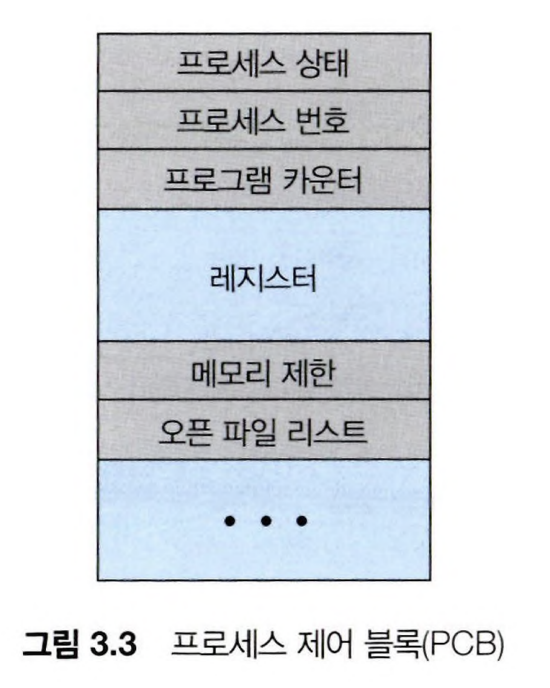
- 프로세스 상태
- 프로세스가 현재 어떤 상태에 있는지를 나타낸다.
- 프로세스 번호
- 프로세스를 식별하기 위한 고유 번호(PID).
- 프로세스 카운터
- 프로세스가 다음에 실행할 명령어를 가리킨다.
- CPU 레지스터
- 프로세스가 번갈아 실행될 때, 현재 사용하던 레지스터 값들을 저장하는 곳.
- 스케줄링 정보
- 프로세스의 우선순위, 프로세스 스케줄링에 대한 정보들을 저장하는 곳.
- 메모리 관리 정보
- 프로세스가 사용하는 메모리에 관련된 정보를 저장하는 곳.
- accounting 정보
- CPU 사용시간, 경과 시간 등의 정보들을 포함한다.
- 입출력 상태 정보
- 프로세스에 할당된 입출력 장치들과 open한 파일의 목록 등을 포함한다.
PCB는 프로세스를 시작시키거나, 다시 시작시키는데 필요한 모든 데이터를 위한 저장소 역할을 한다.

스레드
스레드는 프로세스 내부의 실행 단위이다.
현재까지는 단일 스레드를 사용하는 프로세스를 설명했다.
하나의 프로세스에서 여러 개의 스레드를 사용하면, 실행 분기를 여러 개로 사용할 수 있다.
또한, 여러 스레드가 병렬로 실행될 수 있다.
스레드를 지원하는 시스템에서는 PCB에 각 스레드에 관한 정보를 포함한다.
프로세스 스케줄링
프로세스 하나를 실행하는데 CPU 코어 한 개가 필요하다.
CPU 코어의 개수는 한정되어 있고, 많은 프로세스들이 동시에 실행을 원할 수 있다.
운영체제는 이러한 상황에서 모든 프로세스들이 효율적으로 실행되기 위해 CPU를 적절하게 할당해준다.
이 작업을 프로세스 스케줄링이라고 한다.
일반적으로 프로세스 스케줄링을 할 때 고려하는 사항 중 하나는 프로세스의 유형이 I/O Bound인지, CPU Bound인지 확인하는 것이다.
I/O Bound 프로세스는 계산보다 입출력에 더 많은 시간을 소비하며, CPU Bound 프로세스는 계산에 더 많은 시간을 사용하는 프로세스를 말한다.
스케줄링 큐
프로세스는 각 상태에 따라 해당 상태에 맞는 스케줄링 큐에 들어가게된다.
운영체제는 스케줄링 큐에 있는 프로세스들을 스케줄링한다.
이때 사용되는 큐는 일반적으로 연결 리스트로 저장된다.
각각의 연결 리스트의 노드는 각 프로세스의 PCB 정보를 가지고 있다.
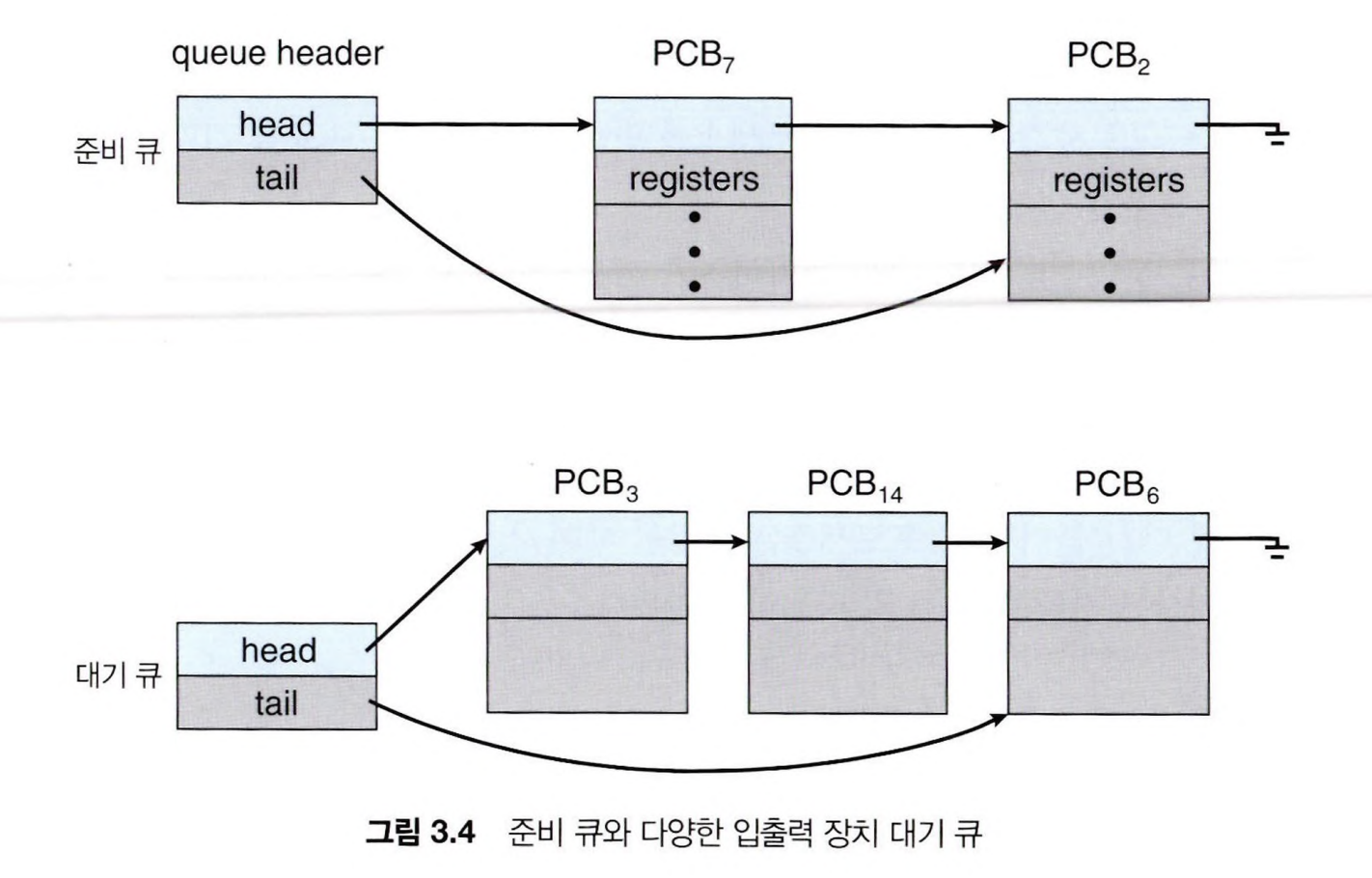
프로세스가 실행되면 준비 큐(Ready Queue)에 들어가서 준비 상태가 되어 CPU를 할당 받기를 기다린다.
프로세스가 CPU를 할당받아 실행 되면, 프로세스 실행이 완료되어 종료되거나, 인터럽트를 받거나, 입출력 작업을 하면서 입출력 완료와 같은 이벤트를 기다린다.
입출력 완료와 같은 이벤트를 기다리는 프로세스는 대기 큐(Wait Queue)에 삽입된다.
프로세스 스케줄링의 일반적인 표현은 아래와 같은 큐잉 다이어그램으로 표현된다.
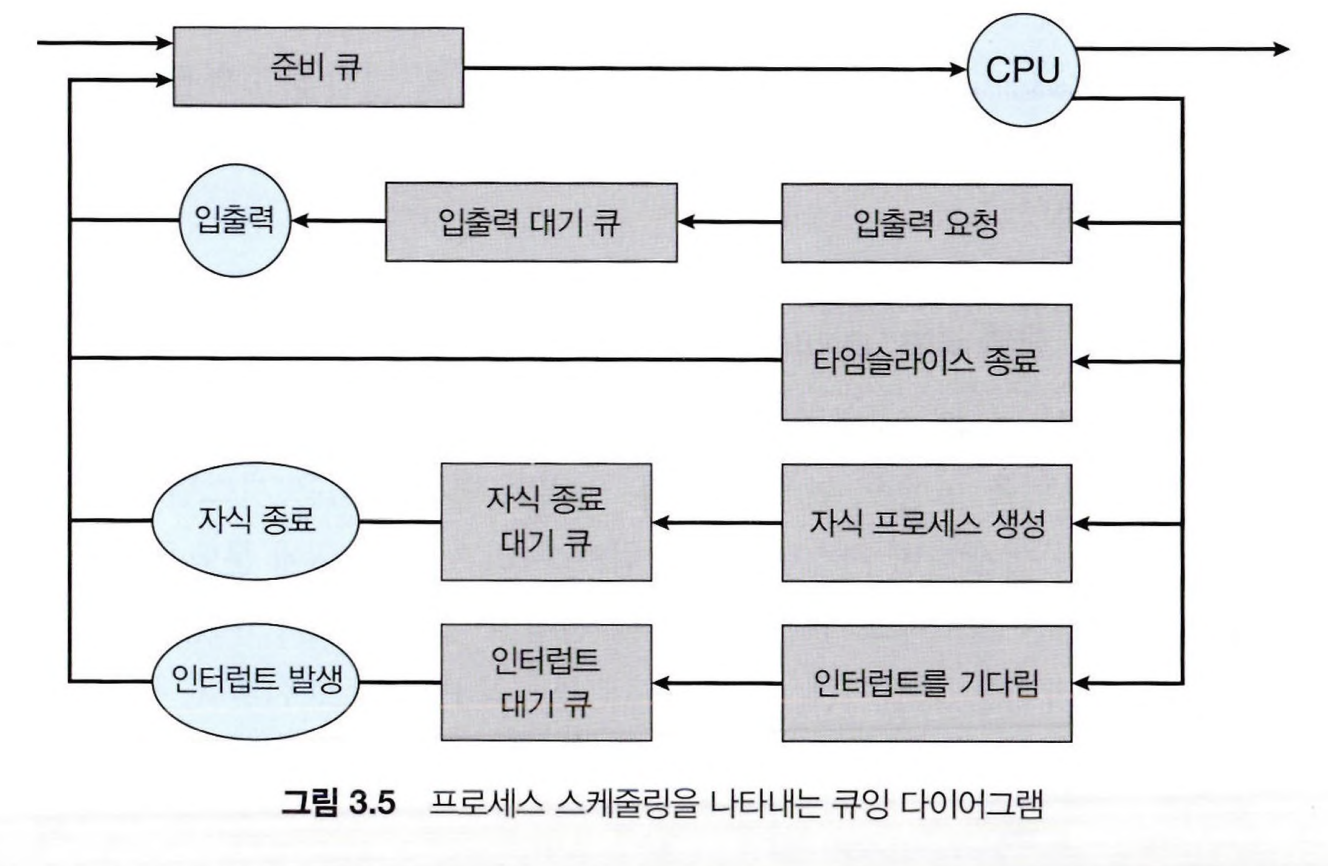
새 프로세스는 일단 준비 큐에 들어간다.
CPU가 할당되어 실행되면, 여러 이벤트 중 하나가 발생할 수 있으며 각 이벤트에 맞는 큐에 들어가게된다.
- 프로세스가 입출력 작업을 요청 후 입출력 대기 큐에 들어갈 수 있다.
- 프로세스가 자식 프로세스를 만들고 자식 프로세스의 종료를 기다리는 동안 대기 큐에 있을 수 있다.
- 인터럽트를 받거나 타임 슬라이스(CPU 할당 시간)가 만료되어 준비 큐로 돌아갈 수 있다.
프로세스가 종료되면 큐에서 제거되고 PCB 및 사용했던 자원이 반환된다.
문맥 교환(Context Switching)
프로세스가 CPU를 할당받아 실행 중, 운영체제는 다른 프로세스에게 CPU를 할당하기 위해 인터럽트를 사용하여 할당 받은 CPU를 뺏을 수 있다.
이때 인터럽트를 받은 프로세스는 인트럽트 처리 후 현재까지의 상태(문맥)를 저장한다.
이후 다시 CPU를 할당 받으면, 저장했던 상태(문맥)부터 다시 실행할 수 있게 된다.
이 과정을 문맥 교환이라고 한다.
즉, CPU를 반납하는 프로세스는 현재 문맥을 백업하고, CPU를 할당받는 프로세스는 이전에 백업한 문맥을 복원하는 작업을 문맥 교환이라고 한다.
문맥는 PCB에 저장되며, 문맥 교환은 PCB를 사용한다.
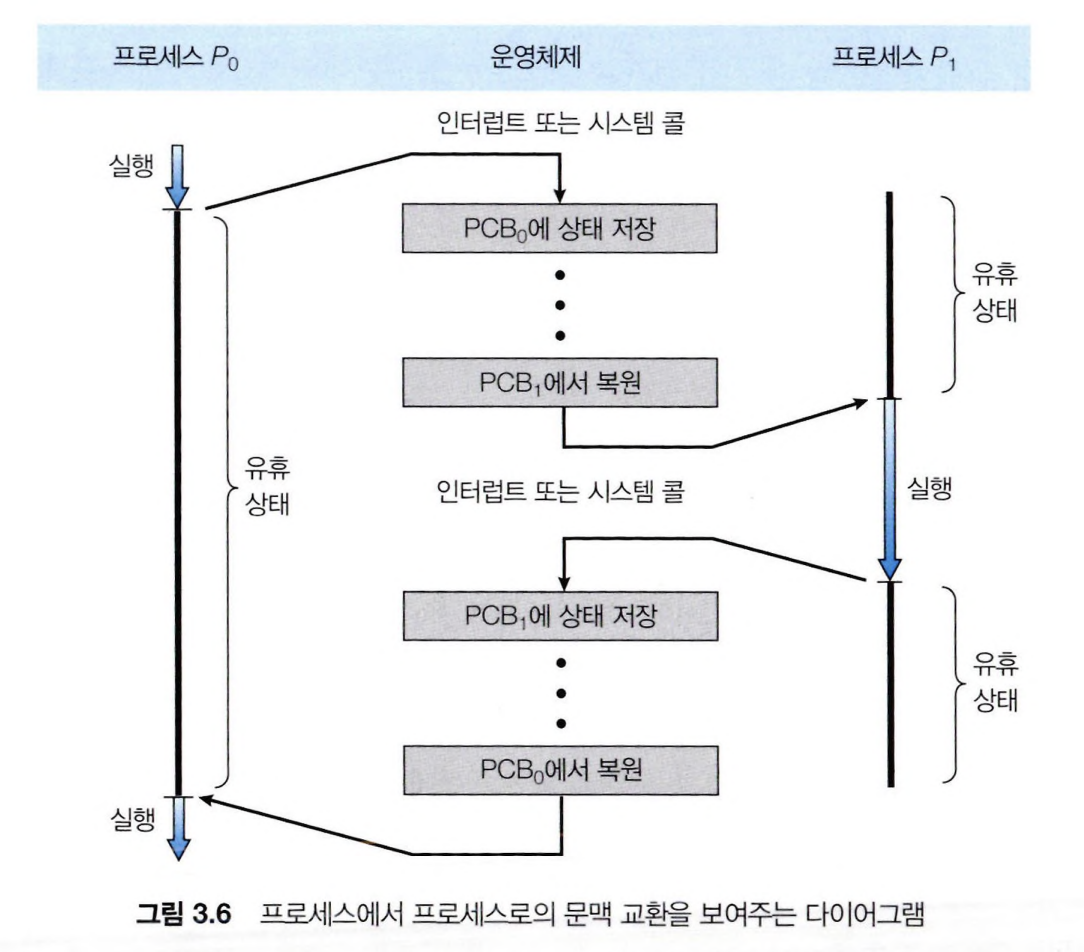
문맥 교환이 진행되는 동안에는 시스템이 아무런 일을 못 하기 때문에 오버헤드가 발생한다.
문맥 교환 시간은 운영체제마다 다르지만 전형적으로 수 마이크로초(us)까지 분포되어 있다.
프로세스 계층 구조
프로세스는 실행되는 동안 여러 개의 새로운 프로세스들을 생성할 수 있다.
생성한 프로세스를 "부모 프로세스"라고 부르고 생성된 프로세스를 "자식 프로세스"라고 부른다.
생성된 프로세스도 또 다른 새로운 프로세스를 생성할 수 있으며, 그 결과 프로세스는 계층 구조(트리)로 이루어지게 된다.
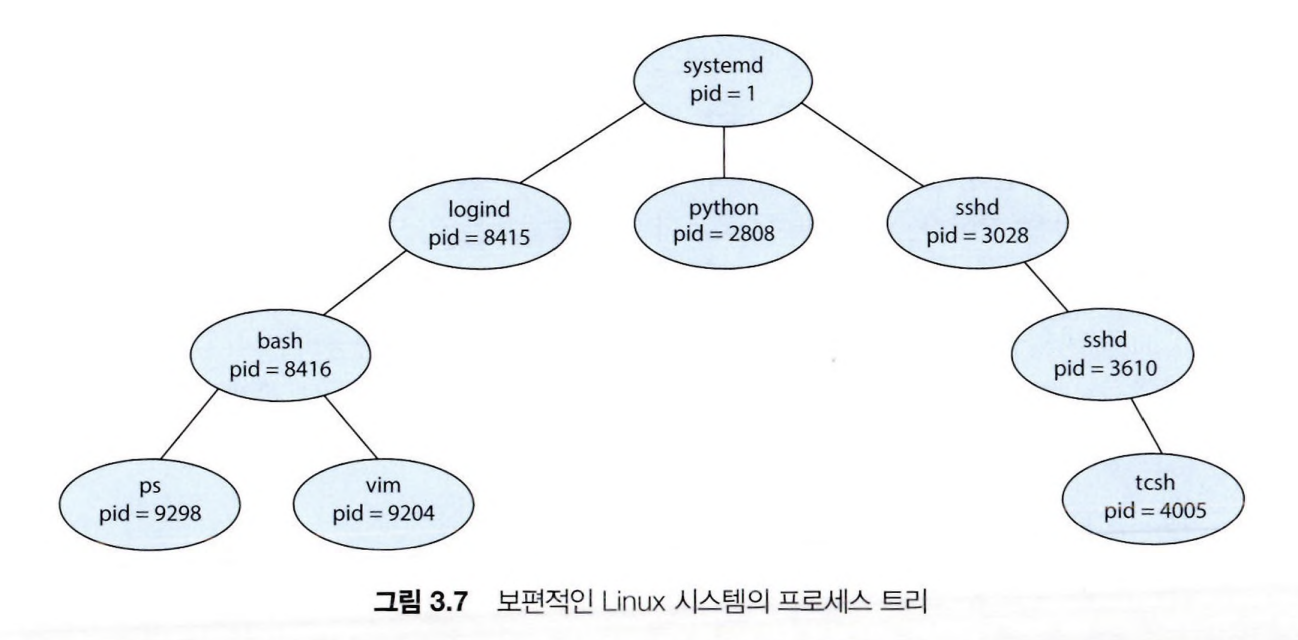
UNIX, Linux, Windows와 같은 대부분의 현대 운영체제는 프로세스마다 고유한 프로세스 식별자(PID)를 사용하여 프로세스를 구분한다.
프로세스 생성
새로운 프로세스는 fork() 시스템 콜로 생성된다.
생성된 자식 프로세스는 부모 프로세스와 동일한 복사본으로 생성되며, 자신만의 메모리 영역을 가진다.
두 프로세스는 fork() 이후의 코드부터 실행되며, fork()의 반환 값으로 부모 프로세스, 자식 프로세스를 구별할 수 있다.
생성된 프로세스는 exec() 시스템 콜을 사용하여 메모리 공간을 새로운 프로그램으로 교체하고 실행할 수 있다.
부모 프로세스는 자식 프로세스가 종료될 때까지 wait() 시스템 콜을 사용하여 준비 큐에서 자신을 제거한다.

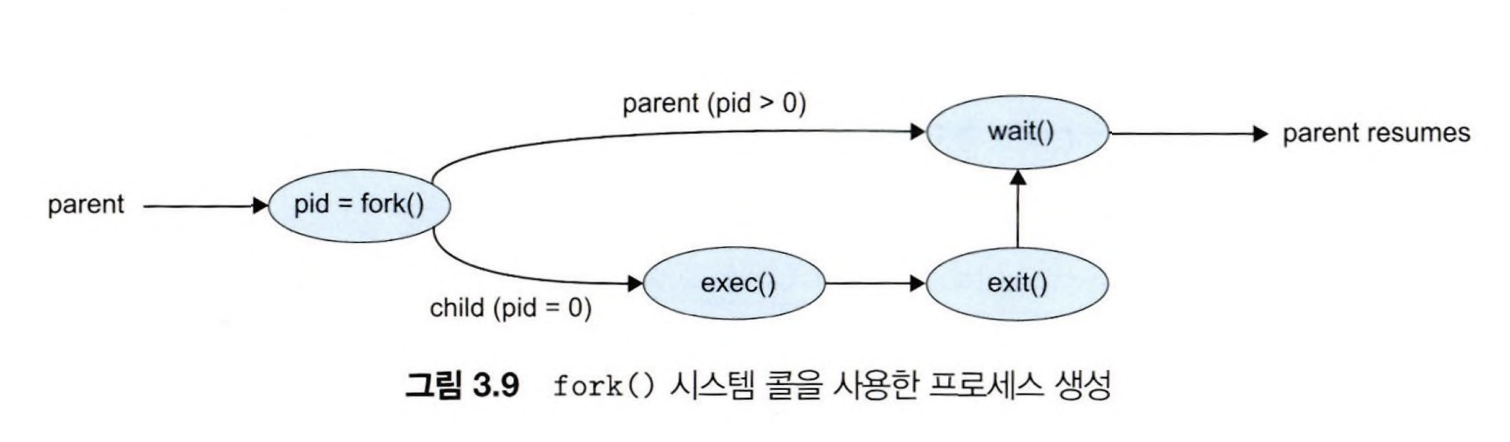
프로세스 종료
프로세스가 마지막 문장의 실행을 끝내고 exit() 시스템 콜을 사용하여 운영체제에게 자신의 삭제를 요청하면 종료된다.
이때 wait() 시스템 콜을 통해 자신의 종료를 기다리고 있는 부모 프로세스에게 상태 값을 반환할 수 있다.
프로세스를 종료시킬 수 있는 다른 방법은 kill() 같은 시스템 콜을 사용하여 다른 프로세스의 종료를 유발하는 것이다.
이런 시스템 콜은 종료될 프로세스의 부모 프로세스만 호출할 수 있다.
그렇지 않으면 오작동하는 프로세스가 다른 프로세스를 종료시킬 수 있기 때문이다.
좀비 프로세스
프로세스가 종료되면 사용하던 자원은 운영체제가 되찾아 간다.
그러나 프로세스의 정보가 저장되는 프로세스 테이블은 부모 프로세스가 wait()를 호출 할 때까지 남아 있게 되어 시스템 리소스가 소모되는 문제를 야기할 수 있다.
즉, 종료되었지만 부모 프로세스가 아직 wait() 호출을 하지 않은 프로세스를 "좀비 프로세스"라고 한다.
모든 프로세스는 종료되면 아주 짧은 시간 동안 좀비 프로세스가 된다.
부모 프로세스가 wait()를 호출하면 좀비 프로세스의 프로세스 식별자와 프로세스 테이블의 해당 항목이 운영체제에 반환된다.
고아 프로세스
부모 프로세스가 자식 프로세스보다 먼저 종료되어 버리면 자식 프로세스는 "고아 프로세스"가 된다.
이때 고아 프로세스의 부모 프로세스를 최상단 부모 프로세스로 변경하고, 최상단 부모 프로세스는 주기적으로 wait()를 호출하여 고아 프로세스를 정상적으로 종료시킨다.
프로세스 간 통신(IPC)
프로세스들은 기본적으로 각각의 고유한 메모리 영역을 가지고 있기 때문에 통신이 불가능하다.
하지만 어떠한 이유 때문에 프로세스간 통신이 필요할 수 있다.
프로세스간 통신은, 프로세스간 통신 기법에 의해 수행된다.
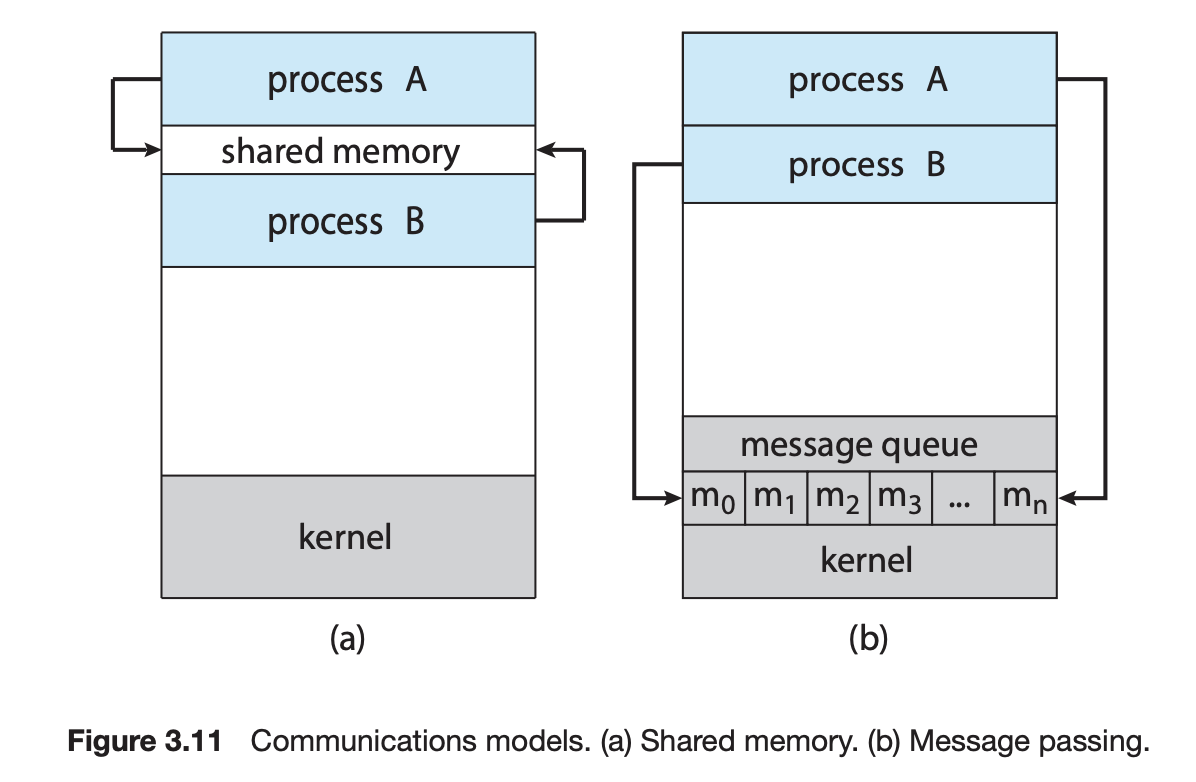
공유 메모리(Shared Memory)
프로세스간 공유되는 메모리를 만들어서 통신하는 기법이다.
프로세스들은 공유 메모리에 데이터를 읽고 써서 정보를 교환한다.
프로세스들이 공유 메모리 영역을 구축해야 한다.
일반적으로 공유 메모리 영역은 공유 메모리 세그먼트를 생성하는 프로세스의 주소 공간에 위치한다.
그 공유 메모리 세그먼트를 이용하여 통신하고자 하는 다른 프로세스들은 이 세그먼트를 자신의 주소 공간에 추가하여야 한다.
그 후 프로세스들은 공유 영역에 데이터를 읽고 쓰면서 정보를 교환할 수 있다.
데이터의 형식과 위치는 프로세스에 의해 결정되며, 동시에 동일한 위치에 쓰지 않도록 해야한다.
메세지 전달(Message Passing)
프로세스들간 메세지를 교환하여 통신한다.
프로세스들이 동일한 주소 공간을 공유하지 않고도 프로세스들이 통신을 하고, 동기화할 수 있도록 해준다.
메세지 전달 방식은 프로세스들이 네트워크에 의해 연결된 다른 컴퓨터들에 존재하는 환경에서 특히 유용하다.
메세지 전달 시스템은 최소한 두 가지 연산을 제공한다.
- send(message)
- receive(message)
프로세스 P와 Q가 통신을 원하면 먼저 통신 연결이 설정되어야 한다.
send() / receive() 연산을 논리적으로 구현하는 방법은 다음과 같다.
- 직접 또는 간접 통신
- 동기식 또는 비동기식 통신
- 자동 또는 명시적 버퍼링
직접 통신
직접 통신에서, 통신을 원하는 각 프로세스는 통신의 수신자 또는 송신자의 이름을 명시해야 한다.
- send(P, message)
- 프로세스 P에게 메세지를 전송.
- receive(Q, message)
- 프로세스 Q로부터 메세지를 수신.
직접 통신은 프로세스를 지정하는 방식 때문에, 프로세스의 이름을 바꾸면 코드의 모든 부분을 바꿔야 하는 단점이 있다.
간접 통신
간접 통신에서 메세지들은 메일박스(Mailbox) 또는 포트(Port)로 송수신된다.
메일박스는 프로세스들에 의해 메세지들이 넣어지고 제거될 수 있는 객체라고 볼 수 있다.
포트는 네트워크 통신에서 데이터 통신 지점을 식별할 때 주로 사용된다.
각 메일박스는 고유한 id를 가진다.
- send(A, message)
- 메세지를 메일박스 A로 송신한다.
- receive(A, message)
- 메세지를 메일박스 A로부터 수신한다.
한 쌍의 프로세스들 사이의 연결은 공유 메일박스를 가질 때 구축된다.
여러 개의 프로세스들간 연결이 가능하다.
통신하고 있는 각 프로세스 사이에는 다수의 서로 다른 연결이 존재할 수 있고, 각 연결은 하나의 메일박스에 대응된다.
동기화
프로세스간 통신은 send와 receive 호출에 의해 발생한다.
메세지 전달은 블로킹(blocking) 또는 논블로킹(nonblocking) 방식으로 전달된다.
이 두 방식은 각각 동기식(Sync), 비동기식(Async) 이라고도 알려져 있다.
- blocking send
- 송신하는 프로세스는 메세지가 수신 프로세스 또는 메일박스에 의해 수신될 때까지 blocking된다.
- nonblocking send
- 송신하는 프로세스가 메세지를 보내고 다른 작업을 한다.
- blocking receive
- 메세지가 이용 가능할 때까지 수신 프로세스가 blocking된다.
- nonblocking receive
- 수신하는 프로세스가 유효한 메세지 또는 널(NULL)을 받는다.
버퍼링
통신이 직접적이든 간접적이든 통신하는 프로세스들에 의해 교환되는 메세지는 임시 큐에 들어있다.
이러한 큐를 구현하는 방식은 세 가지가 있다.
- 무용량(Zero Capacity)
- 큐의 길이가 0이다.
- 즉, 링크 안에 대기하는 메세지를 가질 수 없다.
- 이 경우 송신자는 수신자가 메세지를 수신할 때 까지 blocking 된다.
- 유한 용량(Bounded Capacity)
- 큐가 유한한 길이 n을 가진다.
- 큐가 꽉 차면, 공간이 빌 때까지 송신자는 blocking 된다.
- 큐가 비어있다면, 송신자는 nonblocking 된다.
- 무한 용량(Unbounded Capacity)
- 큐가 잠재적으로 무한한 길이를 가지며, 메세지들이 큐 안에서 대기할 수 있다.
- 송신자는 절대 blocking 되지 않는다.
무용량은 버퍼가 없는 메세지 시스템이라고 부른다.
다른 경우는 자동 버퍼링이라고 불린다.
클라이언트-서버 환경에서 통신
네트워크로 연결된 클라이언트-서버 환경에서 사용할 수 있는 두 가지 통신 기법이 있다.
소켓
소켓은 통신의 끝점(End Point)를 뜻한다.
두 프로세스가 네트워크상에서 통신하려면 각 프로세스마다 하나씩 총 두 개의 소켓이 필요하다.
각 소켓은 IP주소와 포트 번호를 결합하여 구별한다.
일반적으로 소켓은 클라이언트-서버 구조를 사용한다.
서버는 지정된 포트에 클라이언트 요청 메세지가 도착하기를 기다린다.
요청이 수신되면 서버는 클라이언트 소켓으로부터 연결 요청을 수락함으로써 연결이 완료된다.
Telnet, SSH, FTP, HTTP 같은 특정 서비스의 서버는 Well-Known 포트로부터 메세지를 기다린다.
Well-Known 포트란, 특정 서비스에 대해 전 세계에서 표준으로 사용하는 포트 번호이다.
예를들면 Telnet = 23번, SSH = 22번, FTP = 21번, HTTP = 80번 포트를 사용한다.
1024 미만의 모든 포트는 Well-Known 포트로 간주되며 표준 서비스를 구현하는데 사용된다.
[포트 번호 참고 사이트]
https://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers
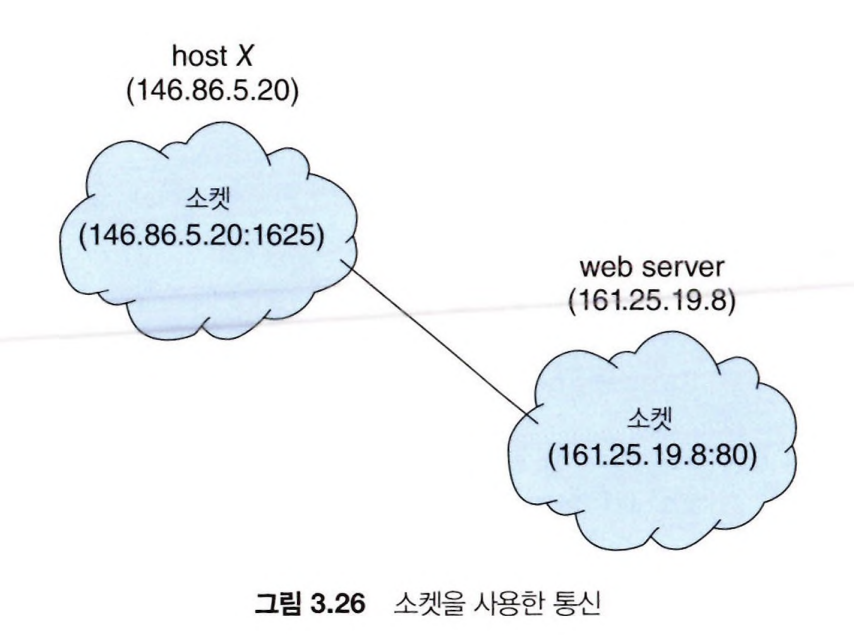
위의 그림을 참고하여 소켓 통신을 이해해보자.
- 클라이언트 = host X
- 서버 = web server
클라이언트 프로세스가 연결을 요청하면 호스트 컴퓨터가 포트 번호를 부여한다.
이때 포트 번호는 1024보다 크고 65536보다 작거나 같은 임의의 정수가 된다. (1024 < x <= 65536)
host X의 클라이언트 프로세스가 web server에 접속하려고 하면, host X는 클라이언트에 포트 번호 1625를 부여한다.
web server는 http 서비스를 제공하기 위해 Well-Known 포트 번호 80을 사용하여 요청을 대기한다.
두 호스트 사이에 패킷들이 오갈 때, 그 패킷들은 이 목적지 포트 번호에 따라 적절한 프로세스로 전달된다.
모든 연결은 유일해야 한다.
즉, host X에서 또 다른 클라이언트 프로세스가 web server에 연결한다면, 해당 프로세스는 1024 보다 크고 65535보다 작거나 같은 숫자 중 다른 클라이언트에서 사용하는 포트번호 1625를 제외한 포트 번호를 부여 받는다.
이것은 모든 연결이 유일한 소켓 쌍으로 구성되는 것을 보장한다.
소켓을 이용한 통신은 네트워크상에서 널리 사용되고 효율적이긴 하지만, 너무 low-level 이다.
소켓은 프로세스간 구조화되지 않는 바이트 스트림만을 통신하기 때문에, 이런 바이트 스트림을 구조화하여 해석하는 것은 클라이언트와 서버의 책임이 된다.
원격 프로시저 호출(RPC)
네트워크로 연결된 서버의 함수를 호출할 수 있는 통신 기법이다.
RPC 통신에서는 전달되는 메세지가 구조화되어 있다.
메세지에는 원격지 포트에서 listen 중인 RPC 데몬 주소가 지정되어 있고, 실행되어야할 함수의 식별자, 매개 변수가 포함된다.
요청된 함수가 실행되고 결과 값이 별도의 메세지를 통해 클라이언트에게 반환된다.
