
해당 스터디는 90DaysOfDevOps
https://github.com/MichaelCade/90DaysOfDevOps
를 기반으로 진행한 내용입니다.
Day 56 - Automated database deployment within the DevOps process
1. DevOps 프로세스 내 DB 통합의 필요성
현대적인 데브옵스 프로세스의 궁극적인 목표는 고객에게 올바른 품질의 가치를 신속하게 제공하는 것이다.
이를 달성하기 위한 이상적인 지표로 '100 deployments a day' 가 제시되는데, 이는 사람이 더 빨리 일해서 달성하는 것이 아니라 빌드, 배포, 테스트의 전 과정이 완전히 자동화되어야만 가능하다.
특히, 변경 사항을 격리하여 실제 프로덕션과 거의 동일한 환경에서 검증하는 Pull Request 배포와, 복잡성을 줄이기 위한 작고 잦은 릴리즈가 필수이다.
하지만 애플리케이션 개발과 달리, 데이터베이스 개발은 여전히 수동 프로세스에 의존하거나 별도의 팀에 의해 관리되는 등 통합되지 못한 경우가 많다.
이로 인해 개발 환경과 프로덕션 환경 간의 스키마 불일치가 발생하는 것이 가장 치명적인 문제다. 이를 해결하기 위해 다음과 같은 핵심 원칙과 과제를 해결해야 한다.
-
Database as Code :
-
데이터베이스 스키마도 C# 코드처럼 취급해야 한다.
-
즉, Git과 같은 소스 제어 저장소 내에서 관리되어야 하며, 애플리케이션 기능 브랜치와 동일한 브랜치 및 풀 리퀘스트에 포함되어 함께 배포되어야 한다.
-
-
복잡한 마이그레이션과 데이터 처리:
-
단순한 스키마 변경 (Column 추가 등) 외에도 비즈니스 로직에 따른 데이터 변환이 필요하다.
-
레이블이나 메시지 같은 참조 데이터를 업데이트해야 하며, 이를 위해 프로덕션과 유사한 데이터 환경에서 Dry run을 수행할 수 있어야 한다.
-
Dry run : 실제 상황을 대비해 실제 자원을 사용하지 않고 미리 해보는 모의 연습이나 테스트로, 시스템이 제대로 작동하는지 확인하거나 오류를 미리 발견하여 수정하는 과정
-
-
Zero Downtime 배포:
-
클라우드 네이티브 환경에서는 계획된 유지보수 시간이 별도로 존재하지 않는다.
-
따라서 서비스 중단 없이 스키마를 변경하고 배포할 수 있는 전략이 요구된다.
-
2. SSDT (SQL Server Data Tools)
데이터베이스를 코드로 관리하고 CI/CD 파이프라인에 통합하기 위한 도구로 마이크로소프트의 SSDT(SQL Server Data Tools)가 소개된다.
SSDT는 Visual Studio 및 MS Build 프로세스에 완전히 통합되어 있어, 데이터베이스 개발을 애플리케이션 개발 수명 주기에 녹여낼 수 있다는 장점이 있다.
-
빌드 타임 유효성 검사 (Build Time Validation):
-
데이터베이스 스키마를 단순한 SQL 스크립트 문자열이 아닌 프로젝트 코드로 인식
-
컴파일 시 타입 검사와 일관성 검사를 수행하므로, 잘못된 참조나 문법 오류를 배포 전 단계에서 즉시 발견할 수 있음.
-
-
소스 제어 및 병합 용이성:
-
각 데이터베이스 객체 (Table, View 등)는 개별 SQL 텍스트 파일로 저장
-
이는 Git을 통해 버전 관리가 가능함을 의미하며, 여러 개발자가 동시에 작업할 때 발생하는 충돌을 일반 코드처럼 Merge하고 추적할 수 있음.
-
-
양방향 스키마 비교 :
-
코드 (SSDT 프로젝트)와 실제 운영 중인 데이터베이스 간의 양방향 비교 기능을 제공
-
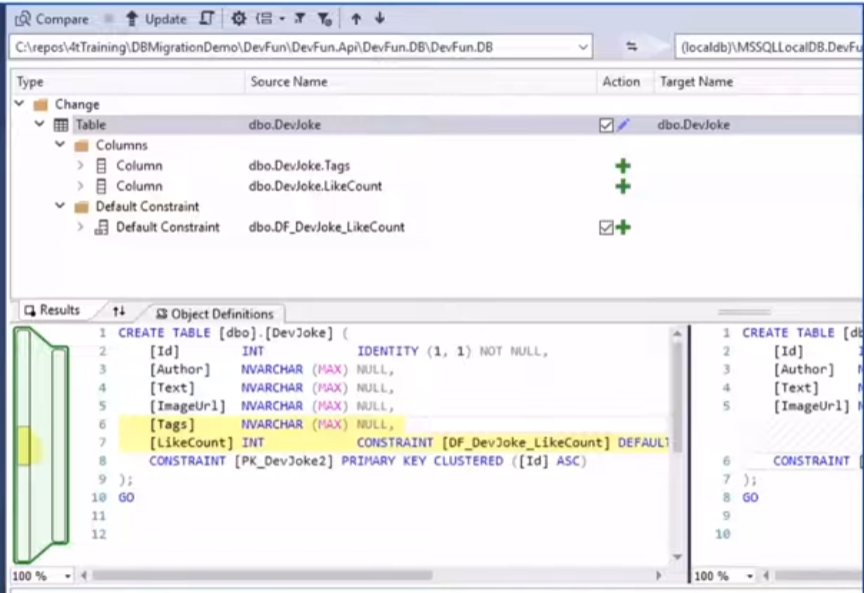
-
DBA가 DB에서 직접 수행한 튜닝 작업을 코드로 가져오거나, 반대로 코드의 변경 사항을 개발 DB에 반영하는 동기화 작업이 수월
-
-
DACPAC을 통한 선언적 배포:
-
빌드 결과물로 마이그레이션 스크립트가 아닌, 데이터베이스의 바람직한 상태를 정의한 DACPAC 파일이 생성
-
배포 시점에는 DACPAC 파일과 대상 데이터베이스의 상태를 비교하여 필요한 변경 사항만을 담은 스크립트를 즉석에서 생성
-
현재 DB 버전을 일일이 추적할 필요 없이 목표 상태로의 동기화를 보장
-
-
확장성:
-
단순 스키마 변경 외에 데이터 핸들링이 필요한 경우를 위해, 배포 전과 후에 실행될 사용자 정의 스크립트 (Hook Points)를 연결할 수 있음.
-
NuGet 패키지나 SDK를 통해 커스텀 배포 CLI를 제작하여 파이프라인에 유연하게 통합하는 것도 가능
-
3. SSDT 기반 로컬 개발자 워크플로우
이론적으로 정립된 Database as Code를 실현하기 위해 개발자는 로컬 환경에서 SSDT를 활용하여 Work Flow를 따른다.
Work Flow는 소스 제어 (Git), Visual Studio (IDE), 로컬 데이터베이스 (Docker 등) 간의 유기적인 순환 구조를 가진다.
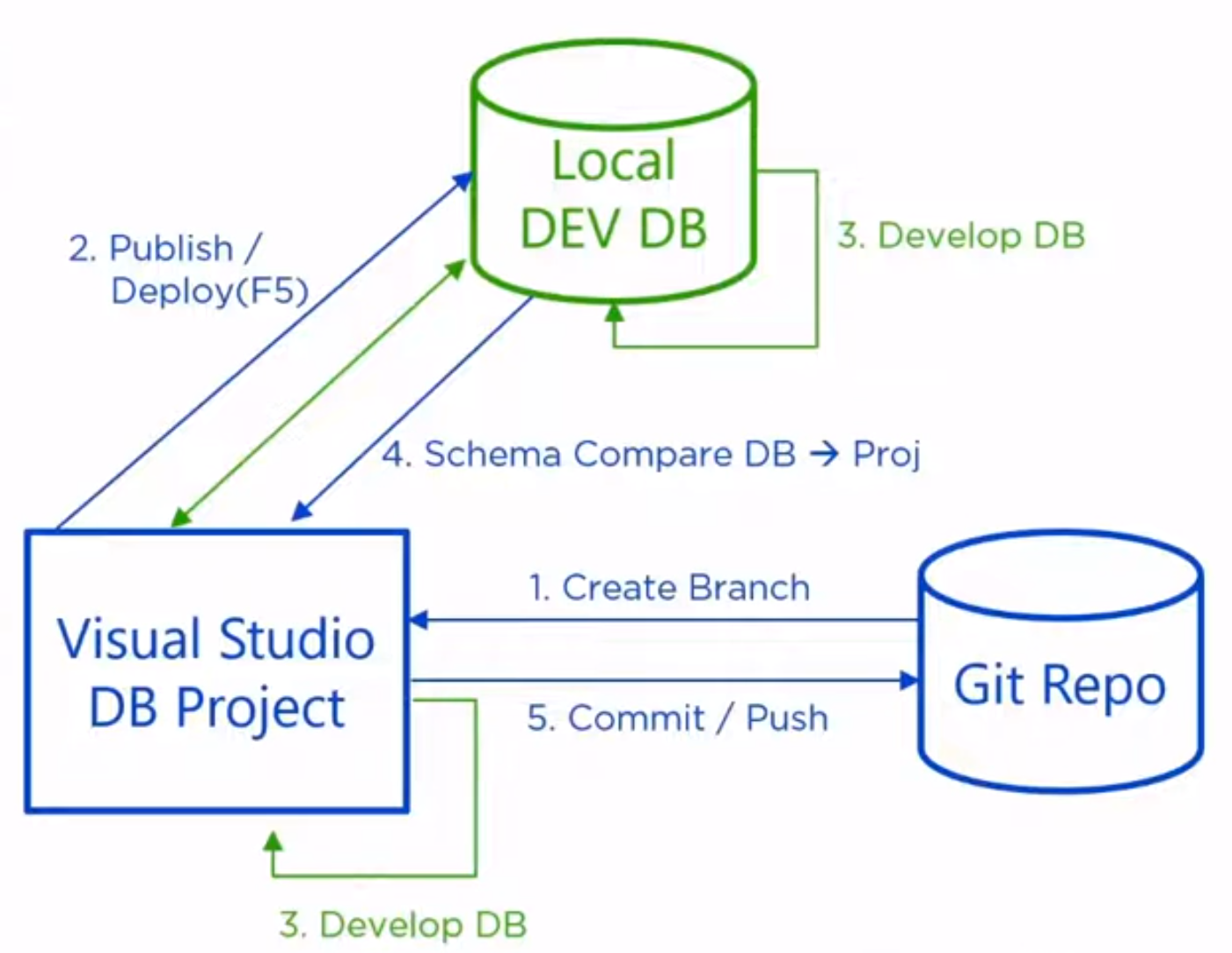
-
기능 브랜치 생성 (Create Branch):
-
작업은 Git 저장소에서 시작된
-
기존의 안정된 코드베이스에서 새로운 기능을 개발하기 위한 Feature Branch를 생성
-
이를 통해 데이터베이스 변경 사항을 격리된 환경에서 안전하게 작업할 수 있음.
-
-
초기 배포 및 게시 (Publish / Deploy - F5) :
-
브랜치를 생성한 후 가장 먼저 수행하는 단계는 Visual Studio 프로젝트의 내용을 로컬 개발 DB (주로 Docker 컨테이너로 실행된 SQL Server)에 Publish
-
단순 비교가 아닌 Publish를 하는 이유: 스키마 비교는 구조적 차이만 맞추지만, Publish 기능은 스키마 변경뿐만 아니라 사용자 정의 스크립트 까지 모두 실행하기 때문 (이를 통해 로컬 DB를 프로젝트가 의도한 완벽한 상태로 초기화할 수 있음.)
-
-
양방향 개발 및 동기화 (Develop DB & Schema Compare) :
-
해당 워크플로우의 핵심은 코드와 로컬 DB 간의 양방향 동기화가 가능하다는 점
-
Visual Studio 중심 개발: 개발자가 IDE 내의 에디터나 디자이너를 통해 테이블 컬럼을 추가
-> 이후 스키마 비교 (Schema Compare) 기능을 사용해 변경 사항을 로컬 DB에 적용 -
DB 직접 수정 (DBA 스타일): SSMS 등의 도구를 사용해 로컬 DB에 직접 쿼리를 날려 컬럼을 추가하거나 최적화 작업을 수행
-> 스키마 비교 (Schema Compare)를 실행하면, DB의 변경 사항이 감지되고 이를 Visual Studio의 SQL 프로젝트 파일로 역으로 Update -
해당 양방향 개발을 통해 개발자와 DBA는 각자 선호하는 방식대로 작업하되, 결과물은 항상 소스 코드 (SQL 파일)로 일원화됨.
-
-
커밋 및 푸시 (Commit / Push) :
-
양방향 동기화를 통해 로컬 테스트가 완료되면, 변경된 SQL 파일들을 Git 저장소에 Commit하고 원격 저장소로 Push
-
이후 PR를 통해 코드 리뷰를 거쳐 통합
-
-
추가 팁 (Cross-platform & Hooks) :
-
크로스 플랫폼 빌드 지원:
-
SSDT는 기본적으로 Windows 및 Visual Studio 종속성이 강함.
-
리눅스 컨테이너 기반의 빌드 파이프라인을 지원하기 위해, 기존 SQL 파일들을 Link 형태로 참조하는 별도의 SDK 스타일 프로젝트 (.NET SDK)를 추가하여 리눅스 환경에서도 빌드가 가능하도록 구성하는 트릭을 사용함.
-
-
사용자 정의 스크립트 (Hooks):
- 단순 스키마 변경 외에 데이터 마이그레이션이 필요한 경우 (예: 카테고리 데이터 매핑 등), SSDT가 제공하는 Pre-Script (배포 전) 및 Post-Script (배포 후) 후크 포인트를 활용하여 비즈니스 로직을 배포 과정에 포함시킴
-
4. 사용자 정의 마이그레이션 스크립트 확장 전략
SSDT는 테이블 추가나 컬럼 변경과 같은 구조적 마이그레이션에는 훌륭하지만, 비즈니스 로직이 포함된 데이터 마이그레이션에는 한계가 있다.
SSDT는 기본적으로 배포 전과 배포 후실행할 수 있는 Hook 포인트를 각각 하나씩만 제공하기 때문이다.
엔터프라이즈 환경에서는 수백 개의 스크립트를 관리해야 하며, 각 스크립트가 실행될 순서와 조건 (이미 실행되었는지 여부 등)을 제어해야 한다.
이를 해결하기 위해 다음과 같은 확장 전략을 사용한다.
-
접착 코드 (Glue Code)를 통한 확장:
-
단일 후크 포인트의 한계를 극복하기 위해, MS Build 프로젝트 내에 사용자 정의 로직 (Glue Code)을 주입
-
폴더 내의 스크립트 파일들을 타임스탬프나 정수 값을 기준으로 정렬하여 실행 순서를 보장
-
-
히스토리 테이블과 해시추적:
-
스크립트의 멱등성 (Idempotency)을 보장하기 위해 데이터베이스 내에 별도의 히스토리 테이블을 생성
-
실행된 스크립트의 해시 값을 기록하여, 해당 스크립트가 이미 실행되었는지, 한 번만 실행되어야 하는지, 아니면 반복 실행이 가능한지를 판단하고 제어
-
-
참조 데이터 관리:
-
애플리케이션 구동에 필수적인 메시지, 공통 코드, 드롭다운 메뉴 값 등의 참조 데이터는 단순 스키마 변경으로 처리할 수 없음.
-
이를 위해 병합 쿼리를 작성하여 배포 파이프라인에 포함시킴.
-
병합 쿼리: 데이터가 존재하면 업데이트하고, 없으면 삽입하며, 불필요하면 삭제하는 로직을 통해 데이터의 상태를 코드에 정의된 바람직한 상태로 동기화하는 역할
-
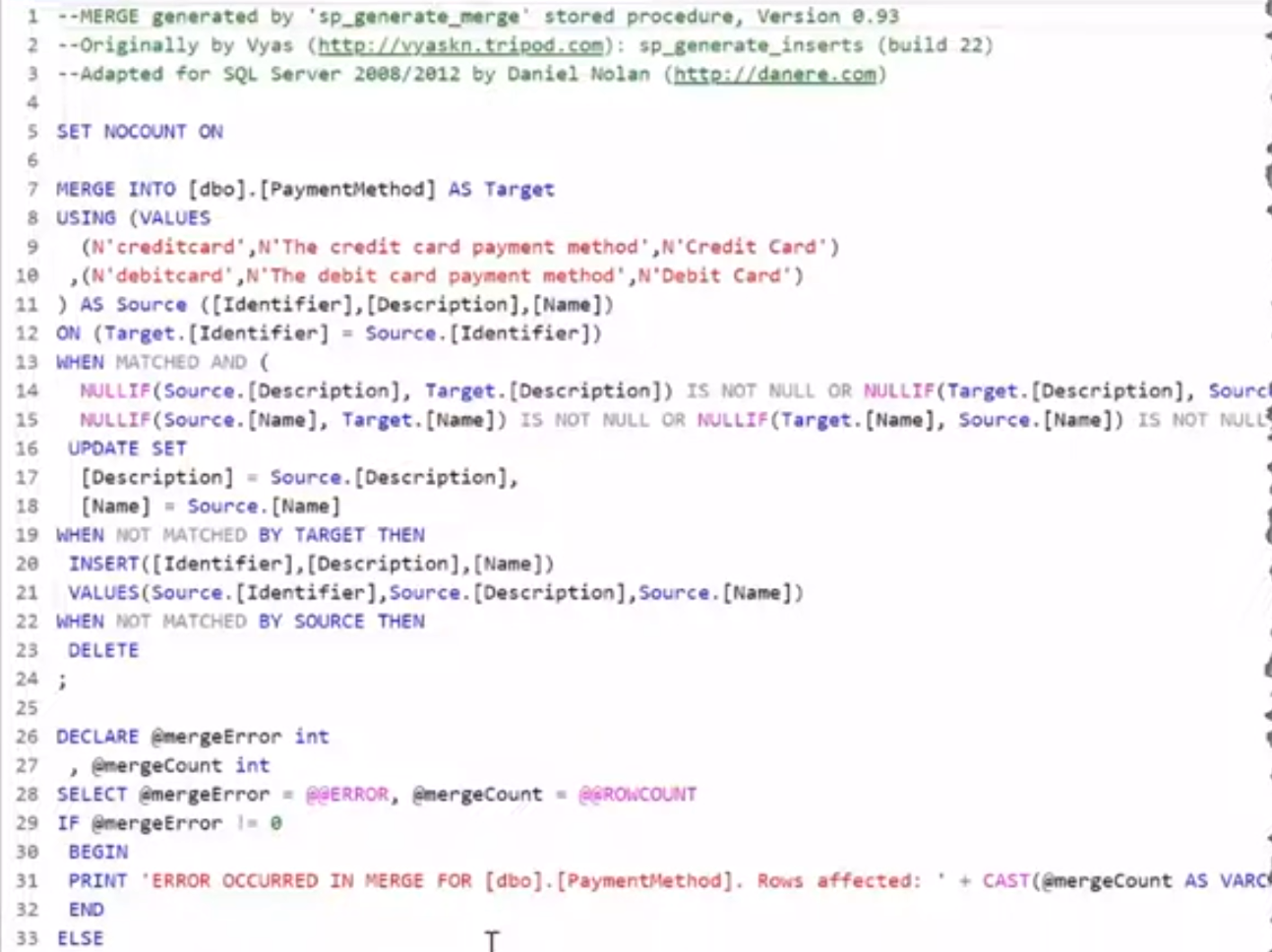
-
5. Zero Downtime과 롤백 시나리오
CI/CD 파이프라인 통합 시 가장 큰 기술적 과제는 Downtime 최소화다.
DACPAC 배포 도구는 구조적 변경을 위해 순차적 트랜잭션을 생성하는데, 대용량 테이블 변경 시 테이블 Lock이 발생하여 다른 요청들이 대기열에 쌓이는 문제가 발생할 수 있다.
이를 해결하기 위한 전략은 다음과 같다.
-
파괴적 변경 회피:
-
첫 번째 배포에서 테이블이나 컬럼을 즉시 삭제하지 않음.
-
대신 View나 Trigger를 사용하여 기존 구조를 모방함으로써 구 버전 애플리케이션이 계속 작동할 수 있도록 함.
-
실제 삭제는 이후 릴리즈에서 진행
-
-
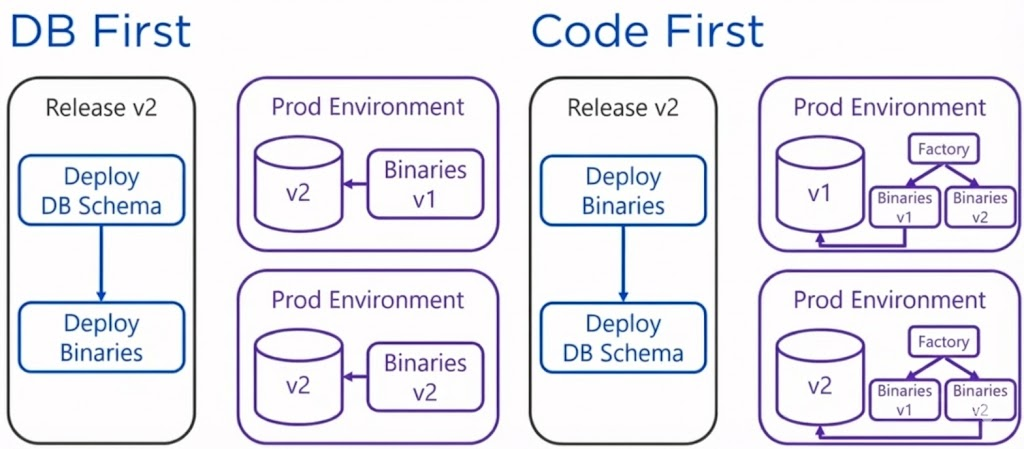
DB 우선 접근 방식:
-
약 80%의 고객이 사용하는 방식으로, 데이터베이스를 먼저 업데이트한 후 애플리케이션 바이너리를 배포함.
-
애플리케이션 코드 내에 복잡한 분기 로직을 넣을 필요가 없어 유지보수가 쉬움.
-
-
코드 우선(Code First) 접근 방식:
-
애플리케이션을 먼저 배포하고, 내부 Factory Pattern이나 Feature Flag를 통해 DB 버전에 따라 작동 로직을 다르게 가져가는 방식
-
테스트는 용이하나 구현 복잡도가 높음
-
-
Roll Forward 전략:
-
롤백 시나리오는 테스트 비용이 매우 높고 실패 확률도 큼.
-
따라서 문제가 발생했을 때 과거로 되돌리기보다는, 수정 사항을 담은 새로운 버전을 빠르게 배포하여 문제를 해결하는 롤 포워드 전략이 훨씬 효율적
-
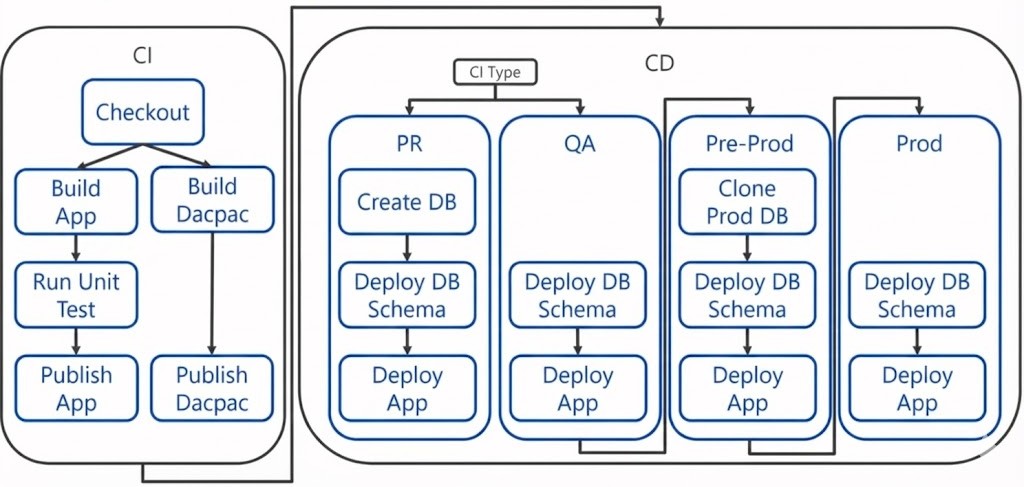
6. CI/CD 파이프라인 아키텍처와 아티팩트 관리
자동화된 파이프라인은 크게 CI와 CD 단계로 나뉘며, 핵심은 데이터베이스 스키마를 Artifact로 관리하는 것이다.
-
CI (지속적 통합) 단계:
-
애플리케이션 코드와 SSDT 데이터베이스 프로젝트도 함께 컴파일
-
빌드 결과물로 애플리케이션 바이너리 (DLL)와 함께 데이터베이스 스키마 정의를 담은 DACPAC 파일을 생성
-
Docker 기반 빌드 시, 멀티 스테이지 빌드나 라벨 필터링을 통해 컨테이너 내부에서 생성된 DACPAC 파일을 추출하여 파이프라인 아티팩트로 Publish
-
-
CD (지속적 배포) 단계:
-
SqlPackage 도구 활용:
-
배포 단계에서는 SqlPackage.exe를 사용하여 DACPAC 아티팩트를 대상 데이터베이스에 게시
-
이때 BlockOnPossibleDataLoss (데이터 손실 가능 시 차단)와 같은 안전장치 옵션을 파라미터로 전달
-
-
단계별 배포:
-
PR 배포: 매번 새로운 테스트용 DB를 생성하고 테스트 데이터를 주입하여 격리된 환경에서 검증을 수행
-
프리 프로덕션 (Pre-Prod): 프로덕션 DB는 너무 크고 민감하여 로컬 테스트가 불가능 -> 프로덕션 DB를 복제한 환경 (Pre-Prod)에 먼저 배포하여 실제 데이터 규모에서의 안정성을 최종 확인
-
프로덕션 배포: 모든 검증이 완료된 후 실제 운영 환경에 배포
-
-
7. Self-Contained Deployment와 Helm
파이프라인 외부에서 실행되는 배포 로직을 애플리케이션 패키지 내부로 이동시켜, 배포의 자율성을 높이는 고급 전략이다.
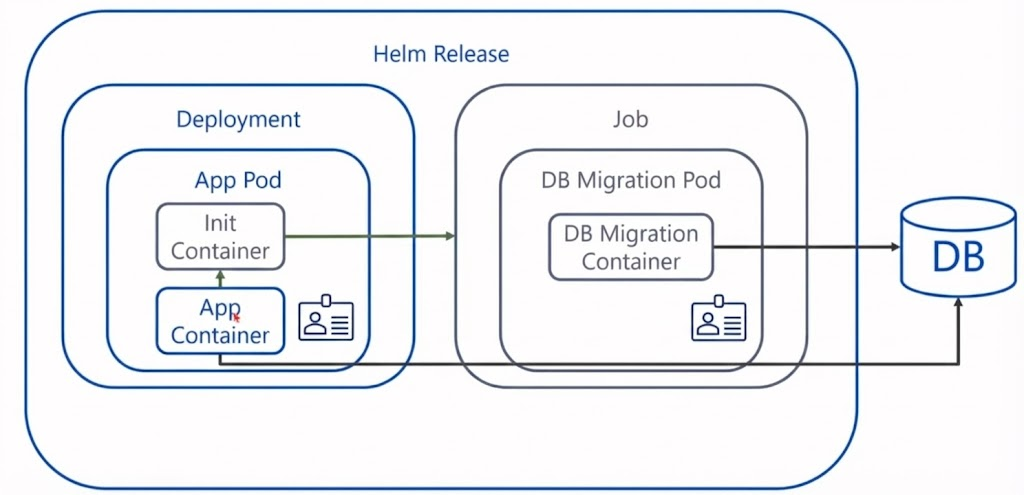
-
Helm 차트 배포 시, DB 마이그레이션을 수행하는 Job과 애플리케이션 Pod를 함께 정의
-
애플리케이션 파드에는 초기화 컨테이너를 추가 (해당 초기화 컨테이너는 마이그레이션 Job이 성공적으로 완료될 때까지 애플리케이션 컨테이너의 시작을 Block 역할)
-
Job이 성공 신호를 보내면 초기화 컨테이너가 종료되고, 새로운 버전의 애플리케이션이 구동
-
해당 방식을 사용하면 복잡한 CD 파이프라인의 오케스트레이션 없이도, 단일 Helm 릴리즈 명령만으로 선 DB 업데이트, 후 앱 배포 순서를 보장하는 롤링 업데이트가 가능
8. 정리: Database as Code
해당 프레젠테이션의 핵심은 데이터베이스 배포가 더 이상 데브옵스 프로세스의 병목이 되어서는 안 된다는 것이다.
애플리케이션은 하루에도 수십 번씩 자동 배포되는 시대에, 데이터베이스만 수동 스크립트와 관리자의 손길에 의존한다면 진정한 의미의 DevOps는 불가능하다.
-
Database as Code의 실현:
-
데이터베이스 스키마를 단순한 데이터 저장소의 구조가 아닌, 애플리케이션 코드의 일부로 취급해야 한다.
-
소스 제어 (Git), 빌드 타임 검증, 아티팩트 (DACPAC) 생성을 통해 DB 변경 사항도 애플리케이션과 동일한 생명 주기를 가져야 한다.
-
-
수동 프로세스의 제거:
-
운영 환경에 직접 접속하여 쿼리를 날리는 위험한 관행을 없애고, SSDT와 같은 도구를 통해 검증되고 자동화된 파이프라인을 구축해야 한다.
-
이를 통해 사람의 실수를 방지하고, 배포의 신뢰성을 확보할 수 있다.
-
-
속도와 안정성의 동시 달성:
-
DB 우선 접근이나 롤 포워드 전략, 컨테이너 기반의 테스트 환경을 통해 다운타임을 최소화해야 한다.
-
결과적으로 고객에게 가치를 전달하는 속도 (100 deployments a day)를 높이면서도 서비스의 안정성을 유지하는 것이 최종 목표이다.
-
