
해당 스터디는 90DaysOfDevOps
https://github.com/MichaelCade/90DaysOfDevOps
를 기반으로 진행한 내용입니다.
Day 71 - Chatbots are going to destroy infrastructures and your cloud bills
1. 발표자의 프로젝트 개요
해당 프레젠테이션은 오픈소스 제2의 뇌(Second Brain) 챗봇 프로젝트인 Quiver의 공동 창립자 Stan이 공유한 기술적 경험, 인프라 구조, 그리고 챗봇 서비스 운영 시 겪었던 시행착오와 해결책에 관한 프레젠테이션이다.
Quiver는 현재 28,000개 이상의 Star를 보유한 오픈소스 프로젝트이다.
사용자는 '브레인(Brain)'이라는 단위를 생성하여 파일을 업로드하거나 API와 연동할 수 있으며, GPT-4 등 다양한 LLM을 연결해 자신만의 지식 베이스와 대화할 수 있다.
핵심 기능: 파일 업로드(RAG), API 연동, 커스텀 LLM 브레인 생성
리소스: 모든 코드는 오픈소스(quiver-hq/quiver)로 공개되어 있으며 로컬 환경에서의 구동을 지원한다.
Quiver는 로컬 실행 가능성과 개발 속도를 최우선으로 고려하여 다음과 같은 기술 스택을 구성했다.
-
인프라 및 백엔드
-
Supabase:
-
Firebase의 대안으로 채택
-
인증(Auth), 데이터베이스(DB), 스토리지, Edge Functions(Lambda) 등을 모두 처리
-
선정의 핵심 이유는 사용자가 로컬 환경에서 전체 서비스를 구동할 수 있도록 지원하기 위함
-
-
FastAPI:
- 백엔드 프레임워크로 Python 기반의 FastAPI를 사용
-
LangChain:
-
LLM 애플리케이션 구축을 위해 사용
-
호불호가 갈리는 라이브러리지만, 개발 속도를 획기적으로 단축해주고 다양한 도구를 제공한다는 장점 때문에 채택
-
-
-
AI 및 LLM 처리
-
LiteLLM:
-
OpenAI, Anthropic 등 다양한 LLM 모델을 쉽게 전환하고 로컬 모델까지 구동할 수 있도록 해주는 오픈소스 프로젝트
-
이를 통해 특정 모델에 종속되지 않는 유연성을 확보
-
-
RAG & OCR:
-
사용자가 업로드한 문서를 처리하기 위해 Unstructured 라이브러리를 사용
-
이는 이미지나 문서의 텍스트 변환(OCR)을 담당
-
-
2. 프로젝트의 문제점 : 의존성과 성능 병목
2-1. Docker 이미지의 비대화 (Dependency Hell)
챗봇, 특히 RAG 기반 서비스는 LangChain과 LLM 처리를 위해 Python 의존도가 매우 높다.
그런데 Python은 의존성 관리가 까다롭기로 유명하다.
-
초기: 이미지 크기가 약 400~500MB 수준으로 관리되었다.
-
현재: 기능 추가, 특히 Unstructured 라이브러리 도입 후 Tesseract와 같은 OCR 패키지들이 추가되면서 이미지 크기가 5배~10배 증가하여 약 5GB에 달하게 되었다. 이는 배포와 스케일링에 큰 부담이 된다.
2-2. 모놀리식 아키텍처의 한계
초기 Quiver는 하나의 도커 이미지가 모든 역할(채팅, 파일 업로드, API 응답, DB 쿼리)을 수행하는 모놀리식 구조였다.
이로 인해 심각한 성능 이슈가 발생했다.
-
응답 지연 (Latency):
-
LangSmith 분석 결과, 쿼리의 50%가 응답 완료까지 3.5초가 소요된다.
-
스트리밍을 적용해 첫 토큰은 0.3~0.4초 만에 전송되지만, 전체 답변 완료에는 평균 4.22초, 길게는 12초 이상 소요된다.
-
-
리소스 점유 문제:
-
일반적인 웹 API는 DB 사양(RAM, CPU)을 높이거나 인덱싱으로 해결 가능하다.
-
그러나 챗봇은 LLM 응답 대기 시간 동안 연결을 계속 점유한다.
-
3명의 사용자가 12초 걸리는 질문을 동시에 하면, 해당 컨테이너의 연결이 모두 점유되어 0.5초면 처리될 단순한 API 요청조차 처리하지 못하고 대기 상태(Pending)에 빠진다.
-
-
메모리 과다 사용:
-
FastAPI의 워커(Uvicorn Worker)들은 RAM을 많이 소모한다.
-
동시 접속 처리를 위해 워커 수를 늘리면 RAM 사용량이 급증한다. 현재 2 vCPU, 8GB RAM 인스턴스를 사용하는데, 이는 CPU 연산 때문이 아니라 거대한 도커 이미지와 Python 워커들의 메모리 점유 때문이다.
-
3. 아키텍처 개선 과정
3-1. 비동기 워커 도입 (Celery)
가장 시간이 오래 걸리는 작업인 파일 업로드(OCR 포함)와 채팅을 분리하기 시작했다.
-
파일 업로드 처럼 수 초에서 수 분이 걸리는 작업은 Celery를 이용해 비동기 워커로 분리
-
하지만 여전히 채팅 로직과 일반 API 로직이 코드 레벨에서 얽혀 있어 완벽한 분리는 이루어지지 않았다.
3-2. 인프라 현황
-
AWS ECS (Elastic Container Service): 쿠버네티스도 시도했으나 관리 복잡도 대비 이점이 크지 않아 관리형 서비스인 ECS를 선택
-
현재 구성: 백엔드 컨테이너 5개를 운영 중
-
불안정성: 요청 처리가 오래 걸려(12초 이상) Health Check 실패 등으로 인해 컨테이너가 재시작되는 경우가 종종 발생한다. 스팟 인스턴스 사용으로 인한 영향도 있다.
3-3. Celery란?
Celery는 Python으로 작성된 분산 메시지 전달 기반의 비동기 작업 큐(Asynchronous Task Queue)이다.
웹 서비스에서 응답 시간이 오래 걸리는 무거운 작업을 백그라운드에서 처리하기 위해 가장 널리 사용되는 라이브러리 중 하나이다.
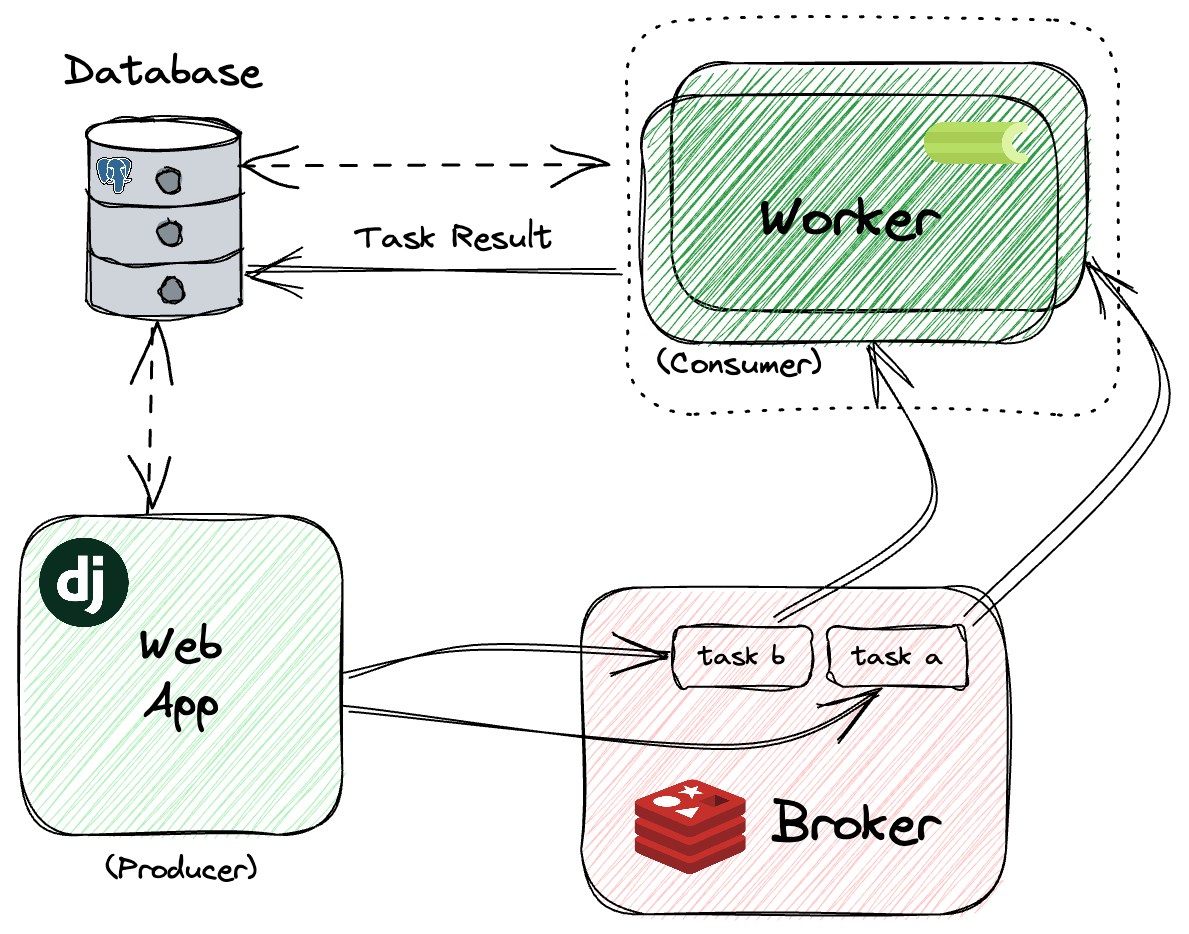
-
Celery 아키텍처 및 동작 원리:
-
Producer (Web Server/API):
- 사용자의 요청(예: 파일 업로드)을 받으면, 작업을 직접 처리하지 않고 "이 작업을 처리해 달라"는 메시지를 Broker에게 전달하고 즉시 응답을 반환한다.
-
Broker (Message Queue):
-
Producer와 Worker 사이의 중개자 역할을 한다.
-
대기열(Queue)에 쌓인 작업 메시지를 관리한다.
-
주로 Redis나 RabbitMQ가 사용된다.
-
-
Worker:
- 브로커의 대기열을 감시하고 있다가, 새로운 작업이 들어오면 이를 가져와 백그라운드에서 실제로 실행한다.
- 브로커의 대기열을 감시하고 있다가, 새로운 작업이 들어오면 이를 가져와 백그라운드에서 실제로 실행한다.
-
-
어디에서 사용하는가? (주요 사용처):
-
주로, 웹 서비스의 응답 속도를 저해하지 않기 위하여 사용
-
무거운 연산 작업: 이미지/비디오 처리, 복잡한 데이터 분석, 대용량 파일의 OCR 및 임베딩 (Quiver의 사례)
-
외부 API 호출 : 이메일 발송, SMS 전송, 타사 서비스 데이터 동기화 등 네트워크 대기 시간이 불확실한 작업
-
스케줄링 작업: 'Celery Beat'를 사용하여 매일 자정 리포트 생성, 주기적인 데이터 백업 등 정해진 시간에 반복해야 하는 작업
-
4. LLM 어플리케이션 구축을 위한 조언
4-1. 채팅 기능을 별도 컨테이너로 격리하라
채팅 기능은 반드시 별도의 컨테이너, 인스턴스, 혹은 Lambda로 분리해야 한다.
-
채팅은 LLM 응답 대기 시간 때문에 연결을 오래 점유한다.
-
이를 일반 API(페이지 로딩, 단순 CRUD 등)와 같은 모놀리식 구조에 두면, 채팅 사용자가 몰릴 때 서비스 전체가 먹통이 된다.
-
채팅 로직을 코드 레벨에서부터 분리하여 마이크로서비스화 하는 것이 필수적이다.
4-2. 마이크로서비스 아키텍처를 지향하라
Python 기반의 AI 서비스는 의존성 패키지가 매우 무겁다.
-
RAG, OCR 등 기능이 추가될수록 도커 이미지는 기하급수적으로 커진다
(Quiver의 경우 333MB -> 3.3GB 이상). -
모든 기능을 하나의 이미지에 담지 말고, 기능별(예: OCR 워커, 채팅 서버, API 서버)로 쪼개어 가벼운 이미지를 유지해야 한다.
4-3. 비용 모니터링을 철저히 하라
LLM 호스팅과 고사양 인스턴스 비용은 매우 비싸다.
-
Quiver는 초기에 채팅을 분리하지 않아, 불필요하게 많은 수의 고사양 인스턴스(8GB RAM 등)를 띄워야 했고 이는 막대한 비용 지출로 이어졌다.
-
오픈소스 LLM(LiteLLM 등)을 쓰더라도 인프라 비용과 OpenAI API 비용을 합치면 상당하다.
-
Sentry와 같은 모니터링 도구를 활용해 실행 시간이 긴 쿼리를 식별하고 최적화해야 한다.
