HTTP Definitive Guide Chap. 1 : Overview of HTTP
{}:여기 안에는 개인생각
Part I. HTTP: The Web's Foundation
Chapter 1. Overview of HTTP
모든 웹 브라우져, 서버, 웹 어플리케이션은 전부 HTTP를 통해서 통신한다.
(스마트폰 앱도 HTTP를 이용한다고함)
1.1 HTTP: The Internet's Multimedia Courier
HTTP는 인터넷의 모든자료들을 전송해준다.
HTTP는 안정적이여서 데이터가 유실, 변조, 파괴될 걱정이 없다.
1.2 Web Clients and Servers
-
Server = Web Server = Onweb Server = HTTP Server = HTTP Protocol Server
-
Client = Web Client(크롬, 익스플로러)
웹 컨텐츠들을 웹 서버에 저장된다.
클라이언트 ----(request)---> 서버
서버 ----(response)---> 클라이언트
클라이언트 + 서버 = WWW(World Wide Web)의 기본적인 구성요소
요청이 성공하면 Object(웹콘텐츠를 말하는듯)과 Object의 정보(타입,길이)등을 응답해줌.
1.3 Resources
웹 컨텐츠의 소스가 웹 리소스
Web Resources = Static Web Resources + Dynamic Web Resources
Static Web Resources = text, pdf, 음악, 이미지등 정적파일
Dynamic Web Resources = 컨텐츠를 생산하는 프로그램(검색 엔진, 부동산가격, 주식거래, 온라인 쇼핑 검색 및 구매)
1.3.1 Media Types
인터넷은 다양한 종류의 데이터 타입들을 host하기 때문에, MIME 타입이라고 불리는 data format label로 전송된다.
MIME = Multipurpose Internet Mail Extensions
이름처럼 원래는 사용자간 메일을 주고받는데에 생긴 문제들을 해결하기 위해 설계됐다.
MIME가 Mail계에서 워낙 뛰어났어서 HTTP가 멀티미디어컨텐츠의 label을 descibe하기위해 채택했다.
웹 서버가 모든 HTTP 오브젝트에 MIME Type을 붙여서 보낸다.
- 크롬의 개발자모드에서도 확인할수 있다.

- 사이트에서 빈곳을 우클릭->검사->네트워크탭,새로고침->왼쪽밑에 여러가지 response를 받는데 그중 아무거나 클리하면 위와 같은 화면이 나온다.
- 중간에 content-length와 content-type을 확인할 수 있다.
브라우져들을 이 MIME을 보고 어떻게 사용자에게 전달될지 결정한다.(이미지를 보여주던지, 노래를 스피커에 켜주던지등)
- 형식: Primary object type/specific subtype('/'로 구분)
1.3.2 URIs
웹서버 리소스들은 당연히 각각 이름이 있어서 클라이언트들이 찾을 수 있다.
그 이름이 URI(Uniform resource identifier)이다.
http://www.joes-hardware.com/specials/saw-blade.gif
{kind=link}
요런 형식이다.(다 접속 안됨)
URI에는 URL과 URN 2가지가 있다.
1.3.3 URL(Uniform Resource Locator)
특정서버에 있는 리소스의 정확한 위치를 알려준다.
http://www.joes-hardware.com/inventory-check.cgi?item=12731
- Scheme : 어떤 프로토콜로 접속할 지 알려준다.
http:// - 서버의 인터넷 주소
www.joes-hardware.com - 세번째 파트는 웹서버에 있는 리소스를 가리킨다.
/specials/saw-blade.gif
오늘날 대부분의 URI는 URL이다.
1.3.4 URN(Uniform Resurce Name)
- URL과 다르게 프로토콜과 위치에 대해 독립적임
(URL은 1번째 파트가 프로토콜이고 2번째 파트가 서버의 위치를 나타내므로 이 둘을 모르고는 알 수가 없음)
-
urn:ietf:rfc:2141이런식으로 생김
URN은 아직 실험적이고 널리 사용되지 않는다. -
특별한 말이 없으면 앞으로 URI와 URL을 혼용
1.4 Transactions
어떻게 클라이언트가 HTTP를 이용해 웹서버의 리소스를 요청을 전송하는지 알아보자
HTTP 전송(transaction)은 request command와 response result가 있다.
HTTP messages라고 불리는 정형화된 데이터 블록을 주고 받는다.

- 이 또한 크롬 개발자 모드에서 확인할 수 있다.
Figure 1-5. HTTP transaction은 request와 response 메세지로 이루어져 있다
그림처럼 규칙성있는 문자데이터들로 서로 소통하는데
이를 HTTP messages라고 한다.
1.4.1 Methods
HTTP는 몇개의 request commands를 제공하는데 이를 HTTP methods라고 말한다.
모든 HTTP request message는 이 method를 한개씩 갖는다.
이 method는 서버에게 어떤 행동을 할지 알려준다.
(웹 페이지 보내줘, 게이트웨이 프로그램 돌려줘, 파일 지워줘등등)
| HTTP method | Description |
|---|---|
| GET | 서버에 있는 특정 리소스를 보내줘 |
| PUT | 클라이언트에서 보낸 데이터를 서버에 있는 특정 리소스에 저장해줘 |
| DELETE | 서버에 리소스를 지워줘 |
| POST | 클라이언트 데이터를 서버 게이트웨이 어플리케이션에게 보내줘 |
| HEAD | 특정 리소스의 response에 관한 HTTP 헤더만 보내줘 |
이것들은 Chapter 3에서 자세히 살펴볼거다.
1.4.2 Status Codes
또한 모든 HTTP response message는 status code와 함께 돌아온다.
요청의 성공/실패 혹은 다른 추가 행동 필요여부등을 알려주는 3자리 숫자 코드이다.
| HTTP status code | Description |
|---|---|
| 200 | OK. 정상적으로 받음 |
| 302 | 리다이렉트. 다른 주소로 요청 보냄 |
| 404 | Not Found. 리소스를 찾지 못함 |
HTTP는 또 'reason phrase'라는 설명 문구를 각각의 status code와 함께 보내는데
이 설명문구는 부가 설명일뿐 중요한 것은 숫자코드이다.
1.4.3 Web Pages Can Consist of Multiple Objects
한페이지내에서 여러가지 HTTP transaction이 일어날수 있고 그렇게 전송받은 object들로 이루어질수있다.
심지어 서로 다른 서버에서 가져온 리소스를 페이지내에 넣을수 있다.
1.5 Messages
HTTP message = Request MSG + Response MSG
각각 3파트로 이루어짐
- Start line
request의 경우: 무엇을 해야하는지
response의 경우: 무엇이 일어났는지
- Header fields (start line 다음 줄부터, 생략 가능)
name: value형식
header fields는 항상 빈줄로 끝남
- Body (생략가능)
헤더필드는 텍스트 기반이어야 했지만 바디는 모든 데이터 형태가 가능함.
1.5.1 Simple Message Example
Figure 1-8. Example GET transaction for http://www.joes-hardware.com/tools.html
이거 HTTP message의 예이다.
그림을 보면 HTTP request message를 브라우져가 보낸다.
start line에 GET method가 local resource인 /tools.html을 요청한다.
HTTP protocol의 버전이 쓰여있고
바디가 없다. 왜냐하면 GET method는 data가 필요하지 않기 때문이다.
서버쪽 HTTP response message를 보자
HTTP 버전, success status code(200), reason phrase(OK), 이 start line에 있다.
header fields밑에는 요청했던 문서들이 있다.
요청한 문서의 lenth는 Content-Length로, 문서의 MIME type은 Content-Type으로 전부 header에 들어있다.
1.6 Connections
HTTP 메세지에 대해서 다뤘는데 이제 이 메세지가 어떻게 TCP(Transmission Control Protocol) 연결에 의해 이동 될 수 있는지 알아보자.
1.6.1 TCP/IP
HTTP는 어플리케이션 레이어의 프로토콜이다.
HTTP는 TCP/IP에 기반하고 있기 때문에 인터넷의 핵심적인 사항들을 TCP/IP가 담당한다.
TCP는 유명하고 안정된 프로토콜인데 다음과 같은 사항들을 제공한다.
1. 에러없는 데이터전송
2. 순서대로 전달
3. 원본 크기 그대로 전달(어느 크기로든 언제나 보낼 수 있음)
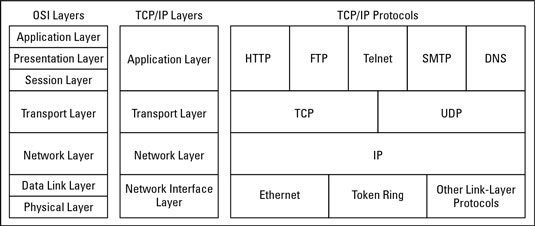 (출처: https://www.dummies.com/programming/networking/network-basics-tcpip-protocol-suite/)
(출처: https://www.dummies.com/programming/networking/network-basics-tcpip-protocol-suite/)
TCP/IP는 개개의 네트워크가 하드웨어의 특이사항이나 결점들을 가리고 컴퓨터들과 네트워크들이 어떤타입으로도 안정성있게 이야기하게 해준다.
일단 TCP가 연결되면 클라이언트와 서버의 주고받은 메세지는 없어지거나 손상되거나 꼬이는 일이 없다.
네트워크용어로 HTTP 프로토콜은 TCP위에 기반하고 있다.(HTTP protocol is layered over TCP)
HTTP는 메세지 데이타를 전송할때 TCP를 사용하고 TCP는 IP를 사용한다.
1.6.2 Connections, IP Addresses, and Port Numbers
HTTP 클라이언트가 message를 서버에게 보내기 전에, Internet protocol(IP) 주소와 포트넘버를 사용해 클라이언트와 서버간의 TCP/IP 연결을 설정해줘야한다.
TCP연결 설정은 회사에 있는 누군가에게 전화하는것과 비슷하다.
먼저 회사에 전화해서 올바른 기관에 연결되고 그다음에 연결하고 싶은 사람의 내선번호로 접근한다.
TCP에서는 서버 컴퓨터의 IP주소와 서버를 돌리고 있는 특정 프로그램과 관련있는 port number가 필요하다.
이 IP주소는 앞서 배운 URL을 통해 알수 있다. URL을 리소스에 위치지만 가운데 파트만 떼어낸다면 IP주소를 알수 있다.
http://207.200.83.29:80/index.html
http://www.netscape.com:80/index.html
http://www.netscape.com/index.html
예를 들어 첫번째 URL은 207.200.83.29라는 IP주소를 갖고 있고 port number는 80이다.
80은 3번째 URL처럼 생략될수 있다.
{https의 경우에는 443이 생략된다.}
Figure 1-10. Basic browser connection process
IP주소와 port number가 있으면 클라이언트는 쉽게 TCP/IP를 통해 소통할수 있다.
그림은 브라우져가 어떻게 HTTP를 이요해 HTML 리소스를 보여주는지 알려준다.
(a) 브라우져가 URL에서 서버의 hostname을 추출한다.
(b) 브라우져가 서버의 hostname을 IP 주소로 변환한다.
(c) 브라우져가 URL에서 port number(있다면)을 추출한다.
(d) 브라우져가 웹 서버와의 TCP연결을 설정한다.
(e) 브라우져가 HTTP request message를 서버에게 보낸다.
(f) 서버가 HTTP response를 브라우져에게 되돌려준다.
(g) 연결이 끊겼다. 브라우져가 문서를 보여준다.
1.6.3 A real Example Using telnet
예제가 예전꺼라 www.naver.com으로 직접 접속해봄
telnet으로 naver.com 접속해서 response받기
텔넷: 원격 서버에 접속하는 프로토콜
보안의 문제가 있어서 현재는 SSH(Secure Shell)로 완전히 대체되었음
telnet naver.com 80처럼telnet 주소 포트번호형식으로 쓰임
참고: https://www.ssh.com/ssh/telnet
1.7 Protocol Versions
현재는 HTTP/1.1을 쓰고 있고 HTTP/2.0과 3.0이 개발중
HTTP/3.0을 TCP기반이 아닌 UDP기반이라고 함.
이 밑은 제대로 이해를 못했고 추후에 나올 장에서 공부한다고해서 제대로 요약을 못함
1.8 Architectural Components of the web
여기서 두 웹 어플리케이션(웹 브라우져와 웹서버)가 어떻게 서로 메세지를 주고받으면서 기본 전송을 이행하는지에 초점을 맞출것이다.
1.8.1 Proxies
클라이언트와 서버사이에 있는 HTTP 중개자
모든 클라이언트의 HTTP request를 받아 (어쩌면 수정을해서) 서버에게 전달한다.
마치 대리인처럼(proxy) 유저를 대신해서 서버에 접근해준다.
보통 프록시는 보안때문에 사용된다. request, response모두 필터링할수있다. 예를 들어 회사에서 어플리케이션을 다운로드할때 바이러스를 감지하거나 초등학생이 성인컨텐츠를 접근 못하게 해준다.
(Chapter 6에서 자세히 다룰거다.)
1.8.2 Caches
웹 캐시나 캐싱 프록시는 HTTP proxy 서버의 특별한 타입니다. 프록시를 통해 전달되는 유명한 문서의 복사본을 저장한다.
다음 클라이언트가 똑같은 문서를 요청했을때 캐쉬의 개인카피본에서 제공해줄수 있다.
Figure 1-12. Caching proxies keep local copies of popular documents to improve performance
클라이언트는 멀리있는 서버보다 가까이 있는 캐쉬에서 훨씬 빨리 다운받을수 있다.
(Chapter7에서 자세히 다룰거다)
1.8.3 Gateways
게이트웨이는 다른 서버들과의 중개인역할을 하는 특별한 서버이다.
보통 HTTP 트래픽을 다른 protocol로 전환하는데 사용된다.
게이트웨이는 항상 리소스의 원래 서버인것처럼 작동한다.
클라이언트는 게이트웨이랑 통신하는지 인지할수 없을 것이다.
예를 들어 HTTP/FTP 게이트웨이는 HTTP request를 통해 FTP URI의 request를 수신받는데 FTP protocol을 사용해 문서를 전달한다.
그결과 문서는 HTTP message들로 구성되어 클라이언트에게 보내진다.
(Chapter8에서 자세히 다룰거다)
1.8.4 Tunnels
HTTP 통신을 맹목적으로 전달하는 특별한 프록시(proxies)
HTTP tunnel은 보통 non-HTTP데이타를 하나이상의 HTTP 통신을 통해 전송되는데 쓰인다.
어떤데이타인지 보지도 않고 전송한다
One popular use of HTTP tunnels is to carry encrypted Secure Sockets Layer (SSL) traffic through an HTTP connection, allowing SSL traffic through corporate firewalls that permit only web traffic.
Figure 1-14. Tunnels forward data across non-HTTP networks (HTTP/SSL tunnel shown)
1.8.5 Agents
자동으로 HTTP request를 만들어내는 반 똑똑한(Semi-intelligent) 클라이언트
User agents(혹은 그냥 agent)는 HTTP request를 유저대신 만들어주는 클라이언트 프로그램이다.웹 request를 실행하는 모든 어플리케이션은 전부 HTTP agent이다.
지금까지는 한가지 agent만 얘기 했는데 그게 브라우져다.
종류가 많다는데 뭔지는 잘모르겠다. 아래 그림이 그중하나인 spider이다. 정보들을 자동으로 모아주는 로봇이라고한다.
