
C++ 에 대해서 기초부터 공부해 본저이 없어 수업중에 나오는 내용들을 기반으로 조금씩 정리해 보고자 한다.
1. Hearder file 선언시 <>와 ""의 차이
#include <iostream><> 의 경우 표준 라이브러리의 일부인 헤더 파일을 포함하는데 사용, 컴파일러는 standard system directories에서 헤더 파일을 검색하도록 지시.
#include "myheader.h""" 는 사용자 정의 헤더 파일이나, 표준 라이브러리의 일부가 아닌 파일을 포함하는데 사용하며 컴파일러가 현재 디렉토리, 혹은 검색 경로에 지정된 디렉토리에서 헤더 파일을 검색하게 된다.
2. Namespace
mylib::function1();
mylib::variable1;Namespace는 library간의 이름 충돌을 피하고, 코드를 논리적인 그룹으로 묶기 위해서 사용한다.
서로다른 library 에서 동일한 이름의 함수를 작성했다면, C 에서는 Namespace 개념이 없기 때문에 컴파일러가 정상 작동할 수 없지만, C++ 에서는 Namespace를 이용하여 충돌을 피할 수 있다.
#include <iostream>
// Namespace declaration
namespace mynamespace {
int x = 5;
void print() {
std::cout << "x = " << x << std::endl;
}
}
int main() {
// Using directive
using namespace mynamespace;
// Names can now be used without the namespace prefix
x = 10;
print();
return 0;
}위와 같이 using namespace를 사용하여 기본적으로 컴파일러가 알지 못하는 함수를 만났을 때 어떤 namespace를 확인할지 설정할 수 있다.
3. Reference Type &
C 언어에는 없던 Reference 타입이 C++ 에는 존재한다. int, double 등과 같이 변수 type 중 하나이다.
#include <iostream>
int main()
{
int value = 5; // normal integer
int& ref = value; // reference to variable value
value = 6; // value is now 6
ref = 7; // value is now 7
std::cout << value; // prints 7
++ref;
std::cout << value; // prints 8
return 0;
}Reference type은 원본 객체와 동일한 메모리 주소에 대해 새로운 참조를 생성한다. 따라서 원본 객체에 대한 다른 별명이라고 생각할 수 있다.
Reference type은 선언과 동시에 초기화 해주어야 한다. 이렇게 초기화된 변수는 원본 객체와 동일하게 사용할 수 있다. 그렇가애 포인터 변수를 출력하는경우 입력되어 있는 주소가 나오지만 Reference 변수의 경우 해당 값이 나온다.
C의 포인터와 유사한 개념이지만, 보다 직관적이고 편리하게 사용할 수 있다.(수동 메모리 관리가 필요하지 않다는 장점도 있다.)
// Function that takes an integer argument by reference
void increment(int& x) {
// int& x = x
x++;
}
int main() {
int a = 10;
// Call function with reference argument
increment(a);
std::cout << a << std::endl; // Output: 11
return 0;
}위의 코드와 같이 Call by Reference를 포인터를 이용하지 않고 사용할 수 있다. 조금더 세부적으로 들여다 보자면, increment() 함수에서 주석 처리된 int& x = x이 자동적으로 이루어지기 때문에, 우리는 변수 자체를 입력에 넣을 수 있게 되었다.
4. Overloading VS Overriding
Overloading
Overloading은 이름은 같지만 매개변수가 다른 여러 함수를 정의 하는 것을 의미한다. 이때 매개 변수가 다르다는 것은 매개변수의 수, 혹은 type 이 다른 것을 의미한다.
int add(int x, int y) {
return x + y;
}
float add(float x, float y) {
return x + y;
}
int main() {
int a = add(1, 2); // calls the int version of add
float b = add(3.0f, 4.0f); // calls the float version of add
return 0;
}위의 예제와 같이 매개변수가 int에서 float이 되었기 때문에 둘은 add 라는 함수에 두개의 함수가 Overloading 되었다.
이때 return type은 Overloading 으로 인정하지 않는다. 즉 int add() 라는 함수가 있고, float add()라는 함수가 있으면, 에러가 발생하게 된다. 이는 호출할때 문제가 생기기 때문이다. 우리는 함수를 호출할때, 함수명을 호출하지 해당 함수의 return type까지 적지 않는다. 따라서 컴파일러 입장에서는 add()를 호출한경우 int add()를 호출한 것인지, float add()를 호출한 것인지 확인할 수 없으므로 문제가 발생한다.
5. Overriding
Overriding은 부모 클래스의 이름 및 매개 변수가 동일한 함수를 재정의 하는 것을 의미한다. 그 기능자체를 재정의 한다고 볼 수 있다.
class Animal {
public:
virtual void speak() {
cout << "I am an animal." << endl;
}
};
class Cat : public Animal {
public:
void speak() {
cout << "Meow!" << endl;
}
};
int main() {
Animal* animalPtr = new Cat();
animalPtr->speak(); // calls the Cat version of speak
return 0;
}6. Stack VS Heap
C++에서 스택과 힙은 프로그램 실행 중에 데이터를 저장하는 데 사용되는 두 개의 서로 다른 메모리 영역이다.
stack
stack은 컴파일러에 의해 자동으로 관리되는 메모리 영역이며 로컬 변수 및 함수 호출 정보를 저장하는 데 사용된다.
스택 메모리는 LIFO(후입선출) 순서로 구성된다. 스택의 크기는 제한되어 있으며 스택에 할당된 메모리의 양은 compile 타임에 결정된다. 스택은 빠르고 함수가 반환될 때 메모리가 자동으로 해제되므로 소량의 데이터를 저장하는 데 효율적이다.(heap에 비해 비교적 메모리 공간이 작다.)
예를 들어 다음과 같이 선언을하게 되면 Stack에 올라가게 된다.
MyClass obj;heap
heap은 프로그래머가 수동으로 관리하는 메모리 영역이며 프로그램 실행 중에 메모리를 동적으로 할당하는 데 사용된다.
heap 메모리는 보다 임의적인 순서로 구성되어 있으므로 임의의 순서로 할당하고 해제할 수 있다.
힙 크기는 시스템에서 사용 가능한 메모리 양에 의해서만 제한되며, 자동으로 관리되지 않으므로 프로그래머는 메모리 누수 및 기타 문제를 방지하기 위해 명시적으로 메모리를 할당하고 해제해야 한다(delete 연산!). 힙은 스택보다 느리지만 더 유연하고 많은 양의 데이터를 저장하는 데 사용할 수 있다.
아래와 같이 선언하는 경우 heap에 메모리가 잡히게 된다.
MyClass* obj = new MyClass;7. Static
static 키워드는 정의된 컴파일 단위로 제한된 범위와 수명을 가진 엔티티(변수, 함수 및 클래스)를 정의하는 데 사용된다.
static으로 선언된 경우 그 값이 초기화 되지 않고 계속해서 유지되며, 일반적으로 클래스의 모든 인스턴스가 공유해야하는 데이터를 나타내는데 사용된다.
또한 static 이라는 키워드는 클래스의 인스턴스가 아닌 클래스 자체에 속하는 클래스 멤버를 의미한다. Static 함수의 경우 호출하는데 별도의 인스턴스를 생성하지 않더라도 (컴파일 시에 이미 메모리에 올라가 있음으로) 바로 호출할 수 있다.
Static으로 선언된 함수에서는 static으로 선언되지 않은 다른 멤버 변수들에 대한 접근이 금지된다. 이는 static 함수가 메모리에 올라가는 순간 생성되지 않은 멤버 변수들에 대해서 접근하려 한다면 오류가 발생하기 때문이다.
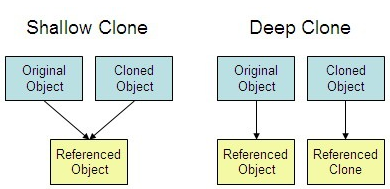
8. Shallow copy VS Deep copy
C++에서 object를 복사할 때 shallow copy 혹은 deep copy 모두 가능하다. 이 두가지의 복사의 차이는 복사본이 생성되는 방식과, 원본과 복사본 사이의 관계성에 있다.
Shallow copy
shallow copy(얕은 복사)의 경우 원본의 메모리 주소값 만을 복사하여 사용한다.
따라서 Deep copy에 비해 빠르지만 복사본을 수정하는 경우 원본도 수정되며, 반대로 원본이 수정되는 경우에 복사본 또한 수정된다.
Deep copy
deep copy(깊은 복사)의 경우 새로운 인스턴스를 생성하여, 그 안에 원본의 값을 저장한다.
원본과 복사본이 서로 다른 대상을 참조하기에 서로 영향을 미치지 않는다.
class MyClass {
public:
int* data;
MyClass() { data = new int; }
MyClass(const MyClass& other) { data = new int(*other.data); } // deep copy constructor
//MyClass(const MyClass& other) { data = other.data; } // shallow copy constructor
~MyClass() { delete data; }
};
int main() {
MyClass a;
*(a.data) = 42;
MyClass b = a; // copy constructor
*(b.data) = 13;
std::cout << *(a.data) << std::endl; // prints 42 for deep copy, but 13 for shallow copy
std::cout << *(b.data) << std::endl; // prints 13 for both
return 0;
}만약 위에서 주석처리되어 있는 얕은 복사 생성자를 사용한다면, 첫번째 출력값이 13이 나오게 된다.
