
1. Neural Networks & Multi-Layer Perceptron
1.1 Neural networks
- 정의 : 비선형 변환을 통해 우리가 원하는 함수로 근사시키는 모델
1.2 MLP
- 다층 신경망으로, Neural Networks가 적층되어 있는 구조
- 각각의 Layer를 다른 차원으로 변환시켜주는 행렬로 생각해주는 것이 좋음
- 이때 Activation Function을 활용하여 비선형성을 주지 못한다면 합성곱으로 인해 그저 하나의 층이 있는 것과 동일하다.
2. Optimization
2.1 Important Concepts in Optimization
- Generalization : 보지 않은 데이터에 대해서 모델이 어떻게 반응할 것인가
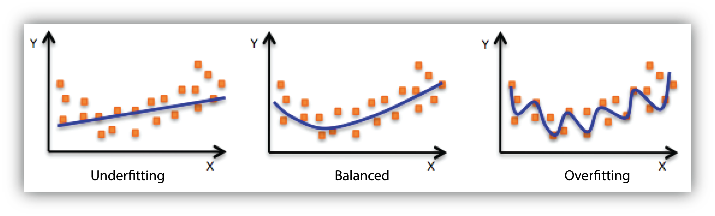
- Underfitting : 과소적합
- Overfitting : 과적합
- Cross-validation : Validation Set을 K개로 나누어 K-1 개로 학습을 진행하고, 나머지 하나에 대해서 검증을 진행하는 방식.
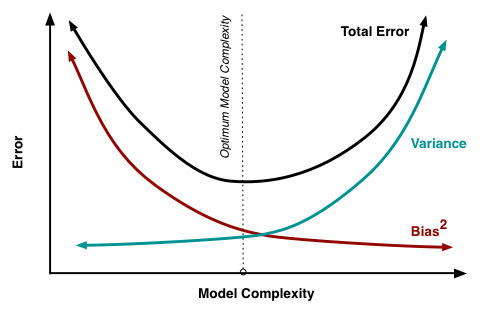
- Bias and Variance Tradeoff : 모델의 복잡도가 증가하면 Bias는 감소 할수 있을지 몰라라도 반대로 Variance가 커진다. 아래의 그림과 같이 Bias와 Variance는 Trade Off 관계로 두개를 모두 만족하는 모델을 찾기란 어렵다.
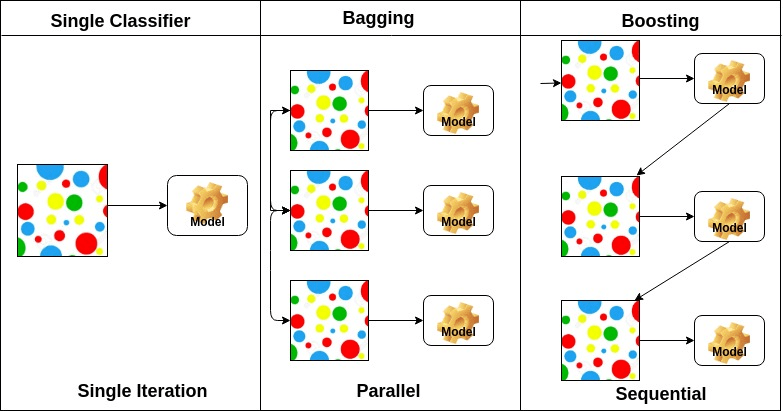
- Bootstrapping : 표본 데이터로부터 추가적인 표본을 생성하여 여러 모델을 학습하고, 모델들의 결과를 종합해 결론을 내는 방식
- Bagging(Bootstrapping aggregating) : bootstrapping을 통해 생성된 여러 모델들의 voting 혹은 평균값을 활용하여 결과를 도출
- Boosting : 순차적으로 강화되는 방식으로 모델을 훈련시킴. 이전 모델이 잘못 예측한 샘플에 가중치를 높여서 다음 모델을 훈련시키는 방식.

2.2 Gradient Descent Method
- Batch-size
- Batch gradient descent : 전체 데이터를 사용하여 gradient를 계산, 시간이 오래걸린다는 단점이 있음
- Mini-batch gradient descent : Mini-batch 단위에 들어있는 데이터를 활용하여 데이터를 계산
- Stochastic gradient descent : 무작위로 선택된 하나의 데이터 포인트에 대한 그래디언트을 활용해 gradient 계산, 로컬 미니마로 부터 벗어날 가능성이 있음.
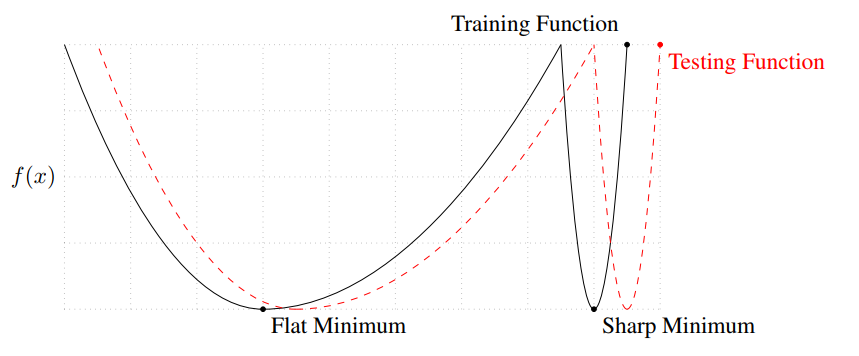
- Batch-size Matter
Batch Size가 작을수록 Flat Minimum로 수렴하기 때문에 보다 일반화 성능이 올라감. Flat Minimum의 경우 함수의 굴곡이 작아, 비교적 적은 차이를 만들어낼 수 있기 때문.
- Gradient Descent Methods
- Stochastic gradient descent
여기서 는 손실함수
- Momentum :이전의 gradient 변화를 고려하여 관성을 부여하는 방식. 기울기가 0인 지점에서 momentum이 존재하여 local minima에서 벗어날 수 있음. 는 모멘텀
- Nesterov Accelerated Gradient (NAG): 모멘텀을 사용하지만, 현재 위치가 아니라, 모멘텀 방향으로 더 진행한 상태의 gradient를 업데이트 하는 방식
- Adagrad : 매개변수 마다 학습률을 조절하여 업데이트 하는 방식. 변화값이 클 수록 학습속도가 감소함. 학습이 지속되면서 결국 학습이 잘 일어나지 않는 문제가 존재. : 각 매개 변수의 gradient의 누적 값
- Adadelta : Accumulation window를 활용하여 학습률이 지속적으로 감소하는 것을 방지
- RMSprop: 경험적으로 이렇게 하니깐 잘되더라~
- Adam : 모멘텀과 RMSprop을 결합하여 사용하는 최적화 알고리즘.(대체로 Adam이 성능이 잘나온다)
: EMA of gradient squares
- AdamW :
AdamW는 Adam 옵티마이저의 변형으로, 가중치 감쇠(weight decay)를 적용하여 모델의 복잡성을 제어하고, 오버피팅(overfitting)을 완화.

3. Regularization
Regularization
- Early Stopping : 학습중에 과적합이 되는 것을 방지하기 위해, Validation error가 더이상 증가하지 않는 시점에서 학습을 중지하는 기법.
- Parameter Norm Penalty : 모델의 파라미터가 너무 커지지 않도록 손실함수에 정규화 항을 추가하는 기법. 파라미터가 작은 값을 가지면 함수공간에서 더욱 부드러운 함수가 생성되어 보다 일반화 성능이 높을 것이라고 예상.
- Data Augmentation : 습 데이터를 다양한 방법으로 변형하여 모델의 일반화 성능을 향상시키는 기법.
- Noise Robustness : 모델이 입력 데이터에 포함된 노이즈에 강건하게 대응할 수 있도록 학습하는 기법. input 뿐만 아니라 학습 중간에 모델의 가중치에도 노이즈를 적용할 수 있음.
- Label Smoothing : 모델이 과적합되거나 너무 확신하지 않도록 하기 위해 정답 라벨에 소프트 업데이트를 적용하는 기법
- Mix up : 서로다른 레이블의 input 데이터를 섞고, label 또한 값을 섞어주는 방식
- Cut mix : 서로다른 레이블의 input 데이터를 자르고 붙이고, label 또한 적정 비율로 섞어주는 방식
- Dropout : 학습 중에 무작위로 선택된 뉴런을 비활성화하여 모델의 과적합을 방지하는 기법
- Batch Normalization : 학습 중에 각 미니배치의 입력을 정규화하여 학습을 안정화시키고 속도를 향상시키는 기법



4. Convolutional Neural Networks
4.1 Convolutional Neural Networks
- Conv : 데이터와 필터(또는 커널) 간의 연산으로, 입력 데이터에서 유용한 정보를 추출. 필터는 작은 가중치 행렬로, 입력 데이터를 도장처럼 스캔하면서 특징을 감지.
- 모델의 parameter 계산 : Kernel W x Kernel W x input channel x output channel (input channel의 개수 만큼 동일한 크기의 kernel이 확장된다고 생각해야함. 동일한 kernel을 재사용하는 것이 아니다.)
4.2 Modern CNN
- AlexNet
- ReLU activation : ReLU(Rectified Linear Unit) 활성화 함수가 사용. 빠르게 수렴하며, 그레디언트 소실 문제를 줄여 학습이 효과적(양수 영역에서는 y = x 형태의 선형함수의 형질을 유지하고 있기에 미분도 용이)
- Data Augmentation
- Dropout
- VGGNet
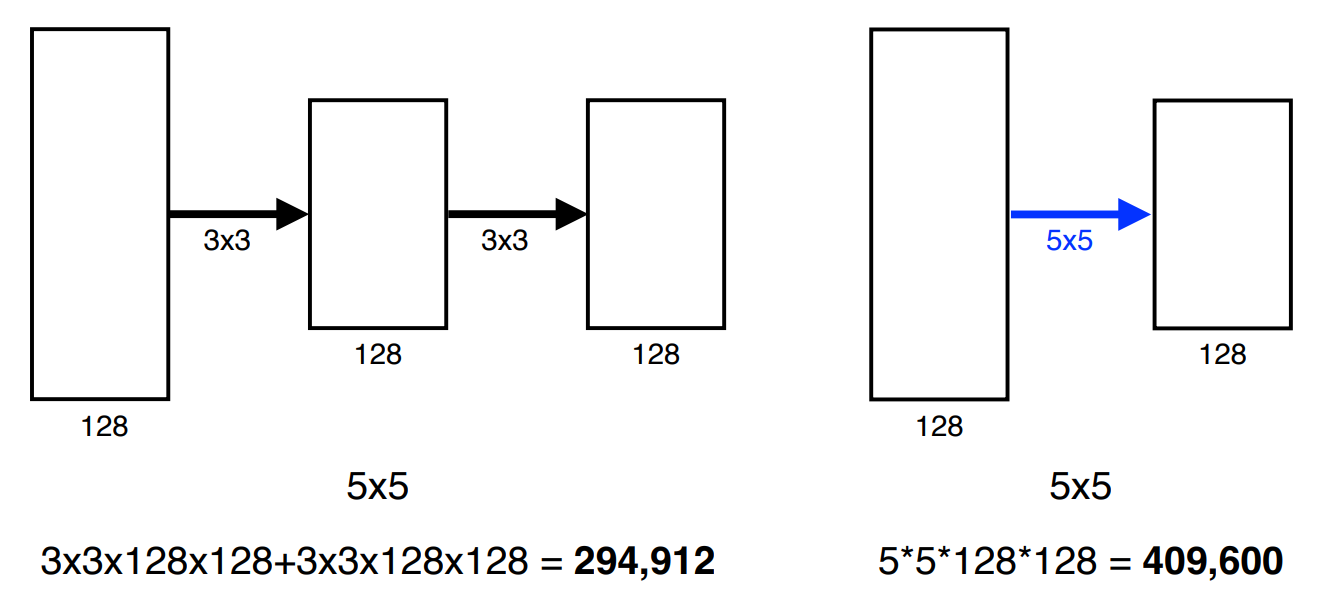
- 3x3 크기의 kernel 사용 : 동일한 Receptive field를 가지게 하는 kernel 간의 비교에서, 작은 크기의 kernel을 활용하는 것이 parameter 측면에서 이득이 존재.(parameter 수의 감소로 학습이 용이 )
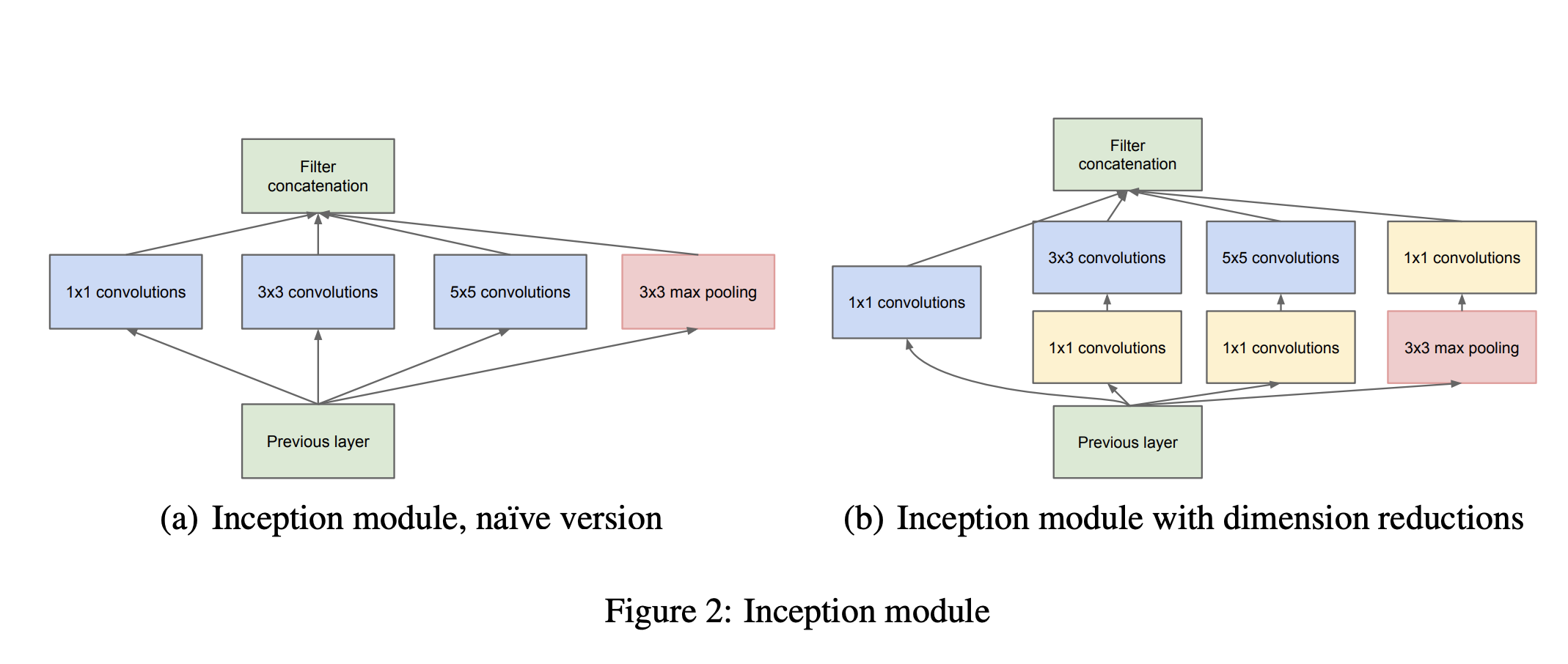
- GoogLeNet
- NiN 구조 : Network 안에 Network가 있는 구조를 활용하였음
- Inception block : 1x1 Conv Layer를 활용하여 Parameter 수를 감소시키고, 다양한 크기의 Conv Layer를 거친 정보를 취합.
- ResNet
- Residual Block : Skip Connection을 이용하여 Gradient vanishing을 완화하고, 이로인해 더 깊은 Layer에 대해서 학습이 가능하게 한다. (BN은 conv 뒤에 오기도 하고, ReLU 뒤에 오기도 한다)
- Bottlenck architecture: 1x1 layer를 활용하여 차원 축소의 효과를 발생시키고, parameter수를 감소시킨다.
- DenseNet
- DensBlock : Resnet과 다르게 모든 선행 layer의 output을 concatenate 하여 다음 layer로 전달.(이때 concatenate 하기 때문에 output의 channel이 기하적으로 증가한다. 또한 DensBlock 내의 layer에서는 output의 크기가 모두 동일하기 때문에 concatenate 가능하다.)
- Transition Block : Dense Block 사이을 이어주는 block으로 1x1 Conv, 2x2 AvgPooling 진행






5. Computer Vision Applications
5.1 Semantic Segmentation
- Semantic Segmentation : 미지를 픽셀 단위로 분할하여 각 픽셀을 해당하는 객체 또는 클래스로 할당하는 작업
- Fully Convolutional Network (FCN)
- 기존의 네트워크는 Dense Lyaer를 거치면서 대부분의 공간정보를 손실한다. 이를 해결하기 위해 모든 layer를 Conv layer로 사용한다.
- 이와 같이 진행하는 경우 input 이미지의 size와 상관없이 동작하며 heatmap 형식으로 결과를 도출 할 수 있음
- Upsampling : 앞에서 추출한 feature를 바탕으로 Upsampling을 하여 기존의 이미지 크기로 복원. 이때 Deconvolution을 활용

5.2 Detection
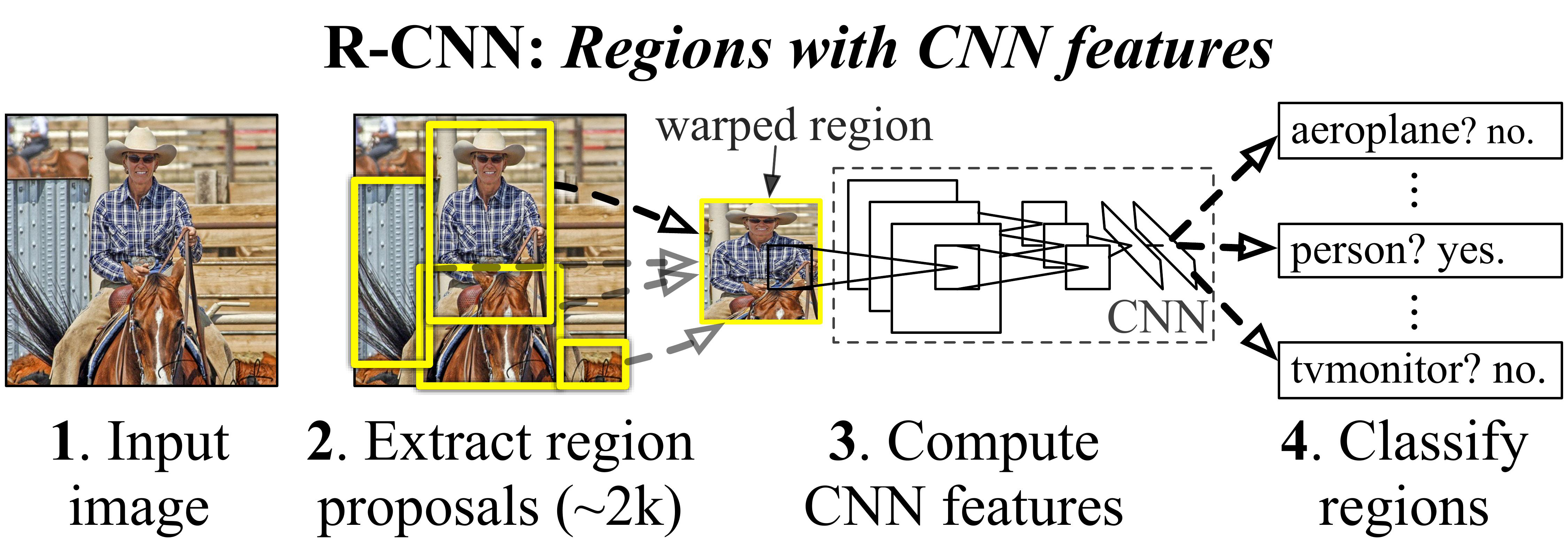
- R-CNN
- image input
- Region proposals : Selective search를 활용하여 2000개의 객체 위치 제안
- feature 계산 : 각 Region Proposal에 대한 특징값을 계산(CNN 활용)
- 객체 분류 : SVM(Support Vector Machine)을 활용하여 객체의 클래스 분류
🔍 Selective search : 각각의 segment로 임의 분할하고, 각각의 segment간의 유사도를 측정하여 유사한 특징을 가지는 객체끼리 같은 객체로 분류
- SPP-Net
- Convolutional Feature Extraction: R-CNN과 다르게 Conv layer를 우선적으로 수행
- Spatial Pyramid Pooling : 이미지의 다양한 크기의 영역에 대해 고정된 크기의 특징 벡터를 생성(spatial bins의 개수를 정하고 pooling을 진행하기에 이미지의 크기에 상관없이 고정길이 feature 추출 가능)
- Fully Connected Layers : 위에서 생성한 feature map을 FC layer에 입력.
- 분류 및 예측 : SVM, BBox 등 진행
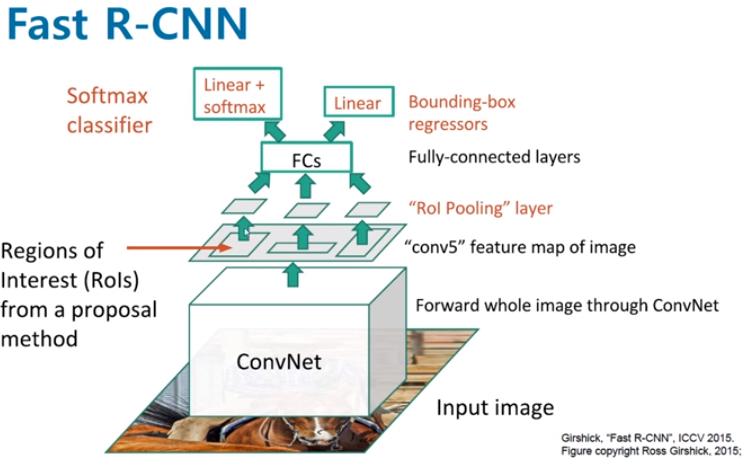
- Fast R-CNN
- Selective Search : RoI(Resion Of Interset) 추출
- ConvNet : Conv를 통해 feature map 추출
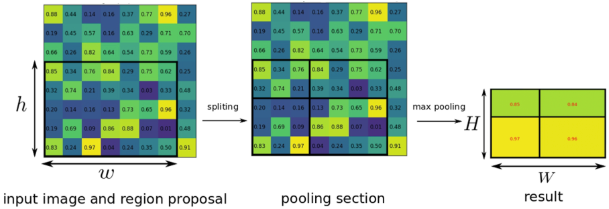
- RoI pooling : RoI를 projection 시켜 해당 영역의 feature map에 대해서 RoI pooling 진행
- FC layer : FC layer를 활용하여 고정길이 vector로 변환
RoI Pooling : Receptive field가 RoI에 맞게끔 계산하여 영역을 정하고 해당 부분에 대해서 pooling을 진행. 아래 그림에서 정중앙이 아닌 이유는 영역의 크기가 홀수 여서 버림을 진행하였기 때문!
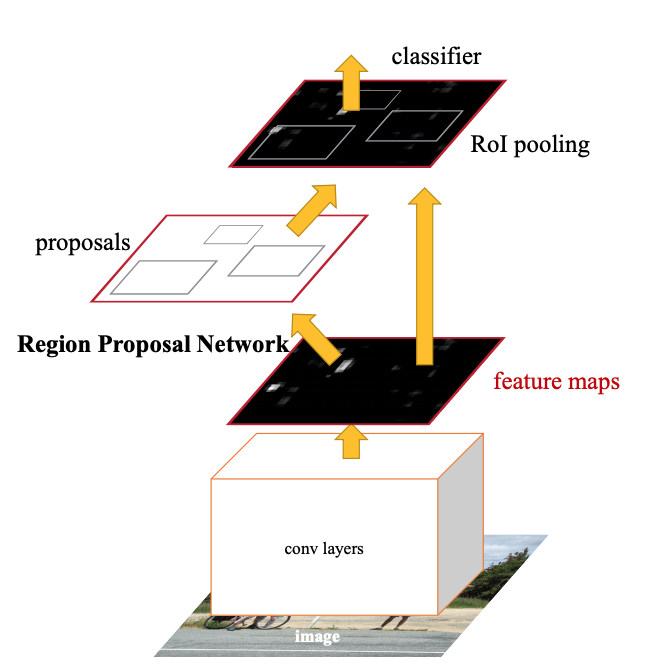
- Faster R-CNN
- RPN(Region Proposal Network) : 기존의 Selective Search 대신 해당 기능을 수행하는 RPN을 학습시켜 보다 빠르게 진행.
- YOLO



Hi~