
참고 블로그 : https://herbwood.tistory.com/
01. Object Detection metrics & Library
1.1 Object Detection 평가 지표
- mAP (mean Average Precision)
- mAP는 클래스별 평균 정밀도(Average Precision)를 평균낸 것으로, 객체 탐지 알고리즘의 성능을 평가하는 데 중요한 지표
- mAP를 이해하려면 정밀도(Precision), 재현율(Recall), AP, IOU 등의 개념을 알아야 함.
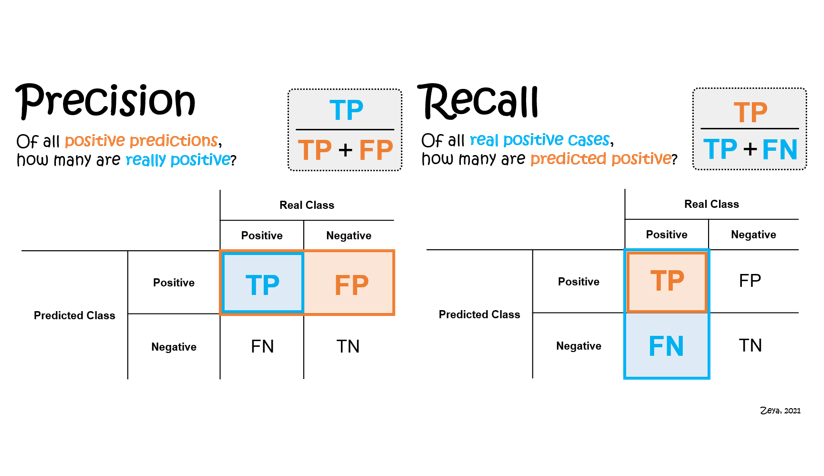
- Precision & Recall
- 정밀도(Precision)는 Positive로 예측한 대상 중 실제로 Positive인 비율.
- 재현율(Recall)은 실제 Positive인 대상 중 올바르게 예측된 비율.
- TP(True Positive), FP(False Positive), TN(True Negative) 등의 개념을 통해 계산.
- IOU
- 교차집합 / 합집합
- 값이 1에 가까울수록 두 집합이 더 유사하다는 것을 의미하며, 0에 가까울수록 두 집합이 더 차이가 있다는 것을 의미
- mAP 계산
- 정밀도와 재현율 곡선(Precision-Recall curve)을 사용해 계산되며, 여기서 얻어진 정밀도의 평균이 AP.
- mAP는 다양한 객체에 대한 AP의 평균값으로, 객체 탐지 성능의 전반적인 척도를 제공.


1.2 Object Detection 라이브러리
- MMDetection
- PyTorch 기반의 객체 탐지 오픈소스 라이브러리
- Detectron2
- 페이스북 AI 리서치에서 개발한 PyTorch 기반의 객체 탐지 및 세그멘테이션 라이브러리.
- YOLOv5
- COCO 데이터셋으로 사전 학습된 모델로, 여러 연구와 개발을 거쳐 발전한 객체 탐지 모델.
- 다양한 플랫폼에서 오픈 소스로 제공.
- EfficientDet
- Google Research & Brain에서 연구한 모델로, EfficientNet을 응용해 만든 객체 탐지 모델.
- TensorFlow와 PyTorch 기반 라이브러리가 제공.
02. 2 Stage Detectors
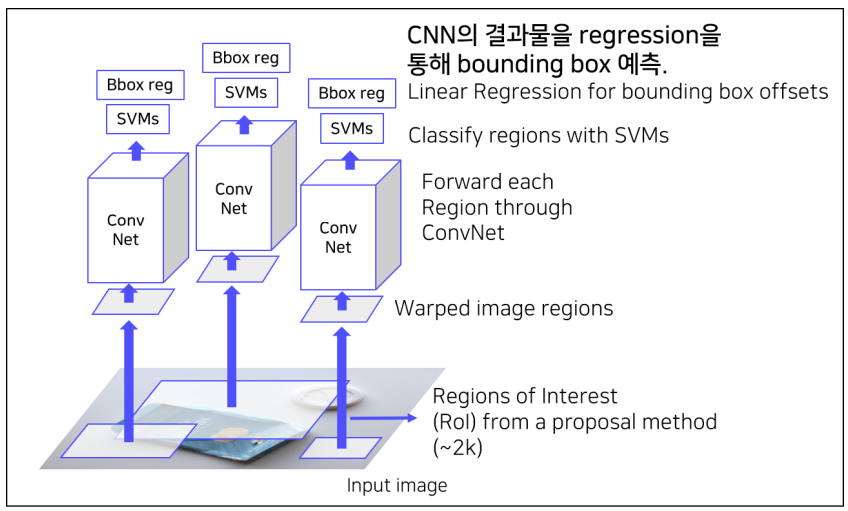
- 파이프라인
- 주요 과정은 입력 이미지 처리
- Region Proposal 추출
- CNN을 통한 feature 추출
- SVM 분류, Bounding Box Regression
- 학습 방법
- Pretrained AlexNet을 사용하여 4096차원의 feature vector를 추출.
- 각 Region에 대해 SVM을 사용하여 클래스를 분류하고, Bounding Box Regressor로 정확한 위치를 예측합니다.
- 단점
- 각각의 Region을 CNN에 통과시켜야 해서 계산 비용이 큼.
- Warping을 통해 이미지를 변형시키는 과정에서 성능 저하가 발생 가능.
- CNN, SVM, Bounding Box Regressor를 각각 별도로 학습해야함.
- End-to-End 학습이 아니기 때문에 최적화가 어려움.
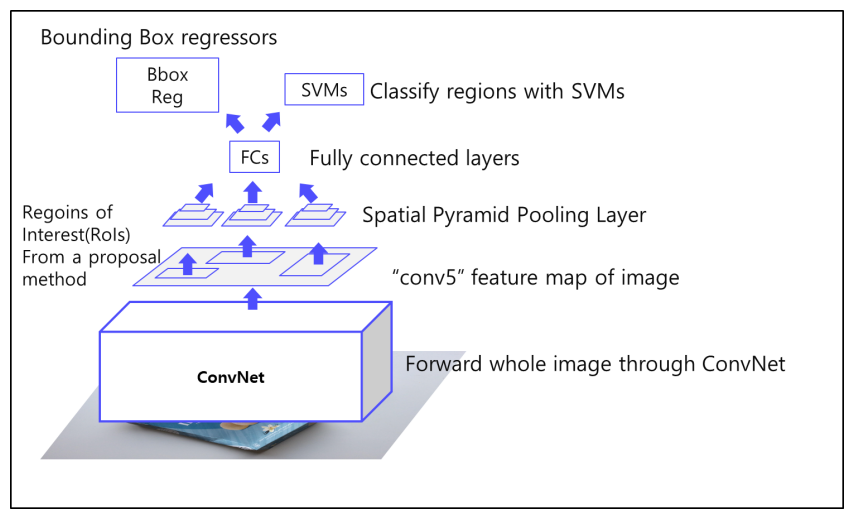
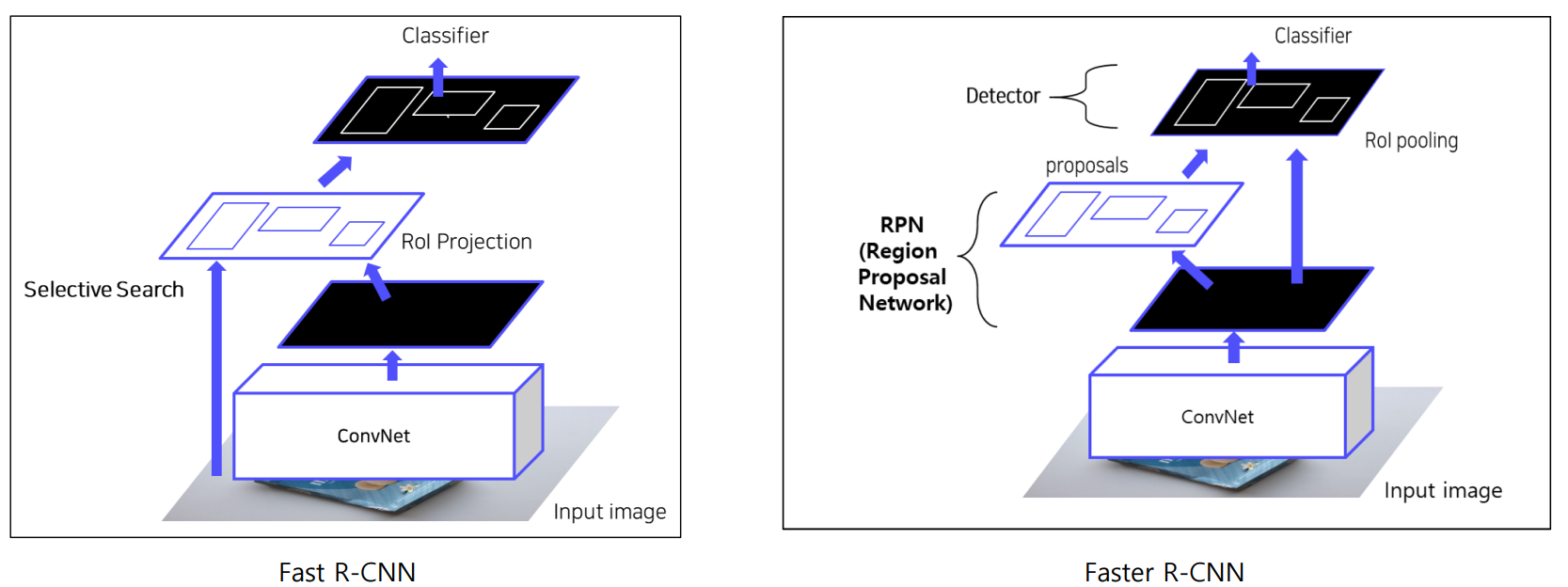
- 파이프라인
- R-CNN과 달리 CNN을 먼저 통과
- Spatial Pyramid Pooling을 사용하여 다양한 크기의 feature map에서 고정된 크기의 feature를 추출.
Spatial Pyramid Pooling : 이미지의 다양한 크기의 영역에 대해 고정된 크기의 특징 벡터를 생성(spatial bins의 개수를 정하고 pooling을 진행하기에 이미지의 크기에 상관없이 고정길이 feature 추출 가능)
- Fully connected layer를 통과
- SVM, Bounding Box Regressor 학습

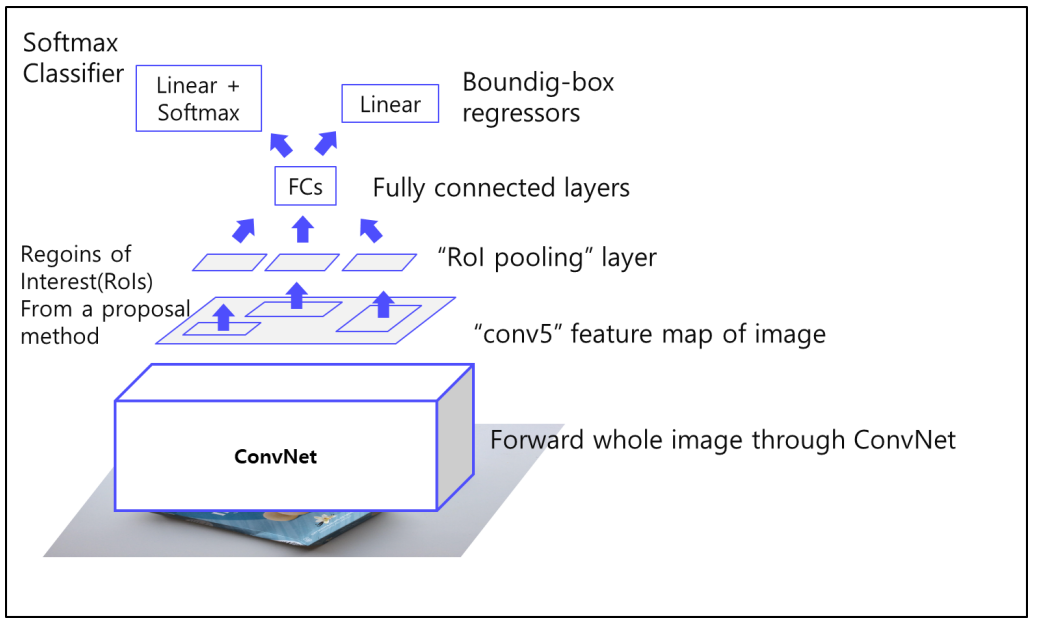
- 파이프라인
- 한 번의 CNN 처리를 통해 feature를 추출하고
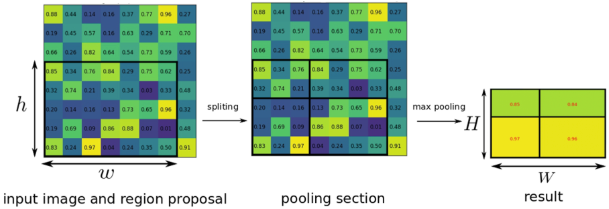
- RoI Pooling을 사용하여 모든 Region에 대해 고정된 크기의 feature를 추출.
ROI Pooling : Receptive field가 RoI에 맞게끔 계산하여 영역을 정하고 해당 부분에 대해서 pooling을 진행. 아래 그림에서 정중앙이 아닌 이유는 영역의 크기가 홀수 여서 버림을 진행하였기 때문!
- 이하 동일
- 학습 방법
- Multi-task loss(분류 및 Bounding Box Regression)를 사용.
- VGG16과 같은 강력한 CNN 구조를 사용하여 성능을 향tkd.
- 파이프라인
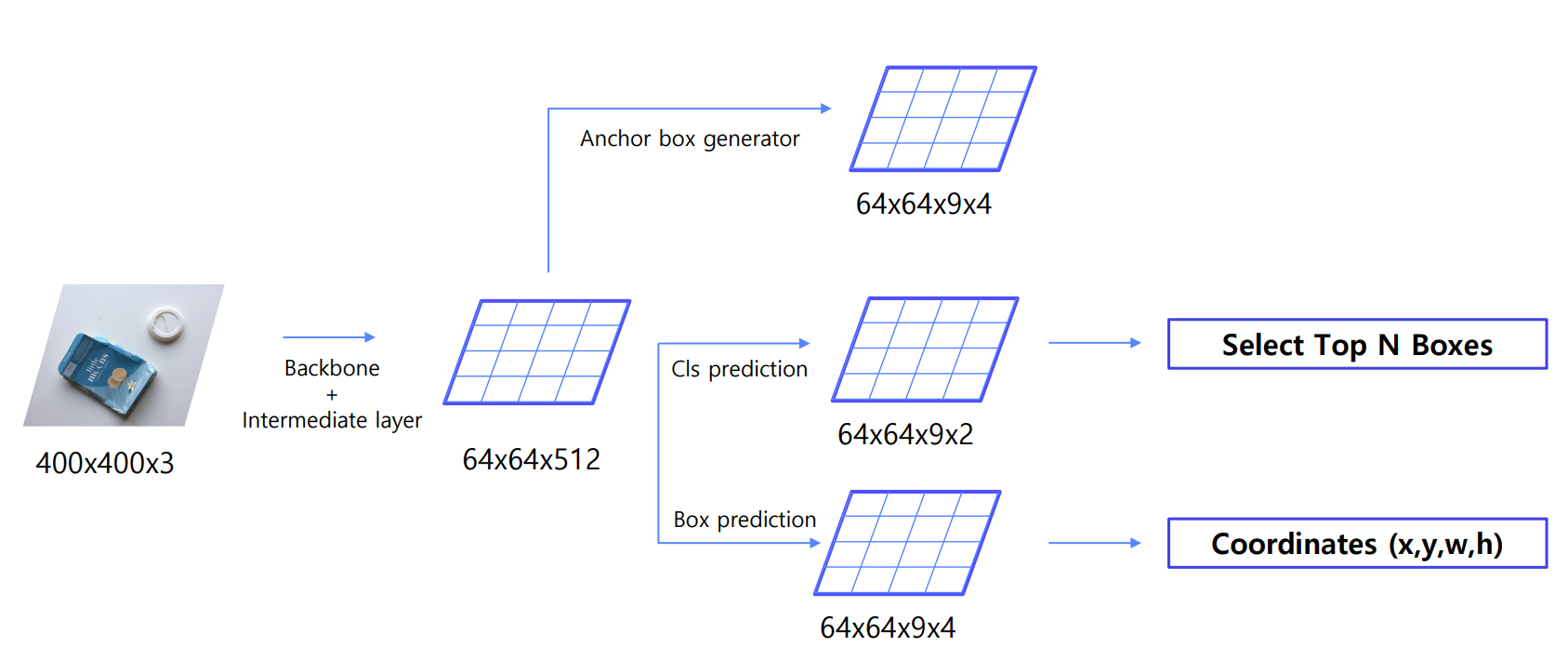
- Feature extraction by pre-trained VGG16
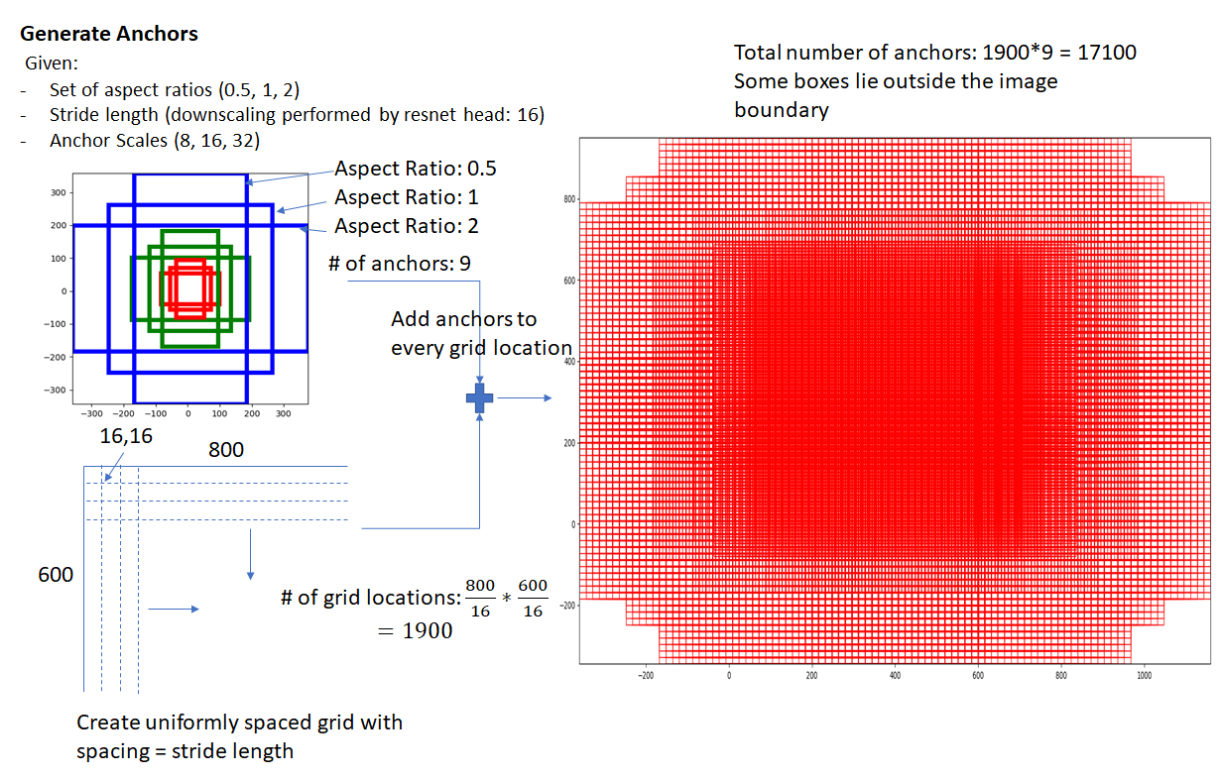
- Generate Anchors by Anchor generation layer : 각각의 Grid Cell(원본이미지를 sub sampling ratio를 기준으로 기준으로 나눈 특정 영역)을 중심으로 기준(Anchor)를 생성하여 사전 정의된 9개의 anchor box 생성.
- Class scores and Bounding box regressor by RPN
RPN : 미지 내에서 객체 후보 영역을 빠르게 제안하는 역할
- Region proposal by Proposal layer : anchor boxes와 RPN에서 반환된 class scores, bounding box regrerssor를 사용하여 anchor box가 객체의 위치를 더 잘 detect하도록 조정
- ROI pooling
- Classification
NMS(Non-Maximum Suppression): confidence score가 낮은 박스 OR highest IoU score인 박스를 비교해가며 하나씩 삭제해 나감
- 학습 방법
- Imagenet pretrained backbone과 RPN을 번갈아 가며 학습하는 4단계 학습 방법을 사용.
- Fast R-CNN과 동일한 loss 함수를 사용하며, RPN 단계에서의 classification과 regressor 학습을 위해 anchor box를 사용.
03. Object Detection Library
3.1 MMDetection
- 기본 구조
- Pytorch 기반의 Object Detection 오픈소스 라이브러리입니다.
- MMDetection 라이브러리의 주요 특징은 전체 프레임워크를 모듈 단위로 분리해 관리할 수 있으며, 다양한 프레임워크를 지원하고 속도가 빠른 점입니다.
- Pipeline 구조
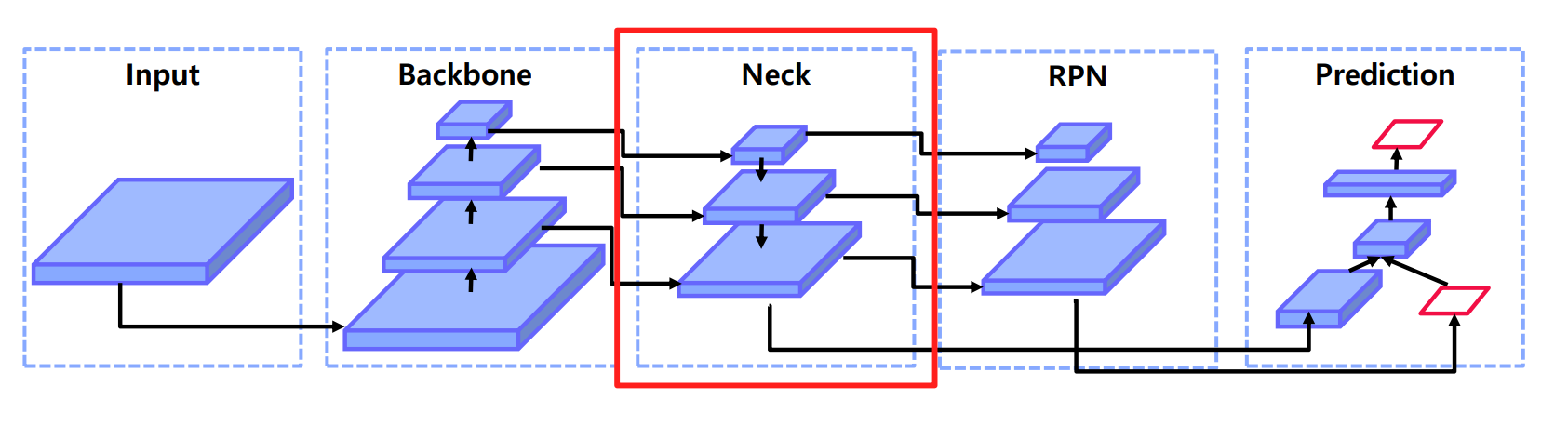
- Backbone, Neck, Dense Prediction Prediction 등 여러 단계를 거칩니다.
- 2 Stage 모델은 크게 Backbone, Neck, DenseHead, RoIHead 모듈로 나눌 수 있으며, 각 모듈 단위로 커스터마이징이 가능합니다.
- 이러한 시스템은 config 파일을 통해 제어됩니다.
- Config File
- Config 파일은 데이터셋부터 모델, scheduler, optimizer를 정의할 수 있으며, 다양한 object detection 모델들의 config 파일들이 정의되어 있습니다.
- 기본 구성요소
- dataset : Train, Validation, Test
- model : type, backbone, neck, rpn_head, roi_head, bbox_head, train_cfg
- schedule
- default_runtime

3.2 Detectron2
- 기본 구조
- Facebook AI Research의 Pytorch 기반 라이브러리입니다.
- Object Detection 외에도 Segmentation, Pose prediction 등의 알고리즘을 지원합니다.
- Pipeline 구조
- Setup Config, Setup Trainer, Start Training의 단계를 포함합니다.
- Config 파일 수정, 데이터셋 등록, Augmentation mapper 정의, Trainer 정의 등의 단계로 구성됩니다.
- Config File
- MMDetection과 유사하게 config 파일을 수정하여 파이프라인을 구축하고 학습을 진행합니다.
- 틀이 갖춰진 기본 config를 상속 받아 필요한 부분만 수정하여 사용합니다.

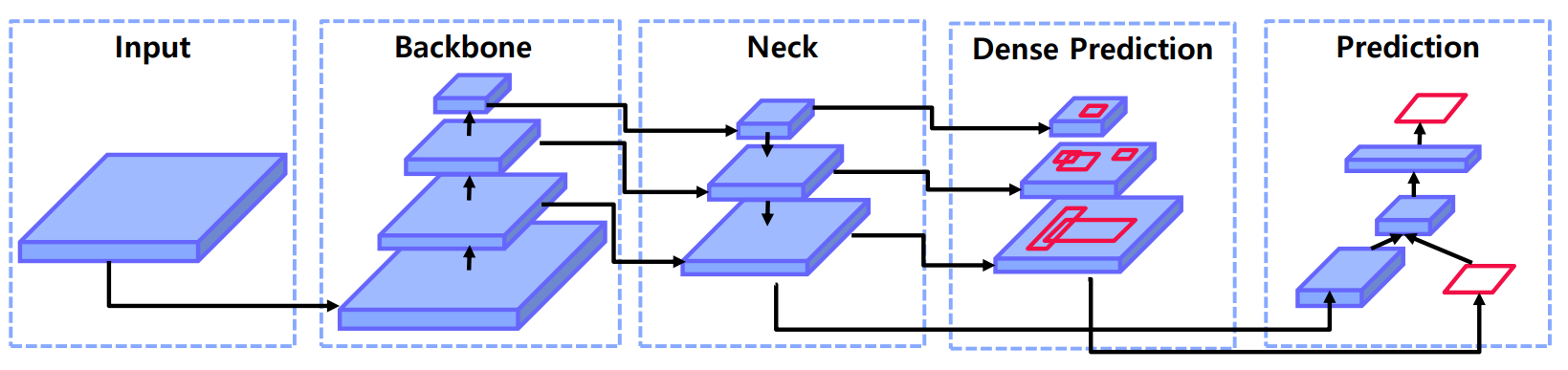
04. Neck 구조
4.1 Neck
- 구조
- 필요성
- 입력, Backbone, Neck, RPN, Prediction의 유의미한 연결.
- 다양한 크기의 객체를 더 잘 탐지하기 위해 필요.
- 하위 레벨의 feature가 세맨틱적으로 약할 때, 상위 레벨의 강한 세맨틱 feature와의 교환을 수행.
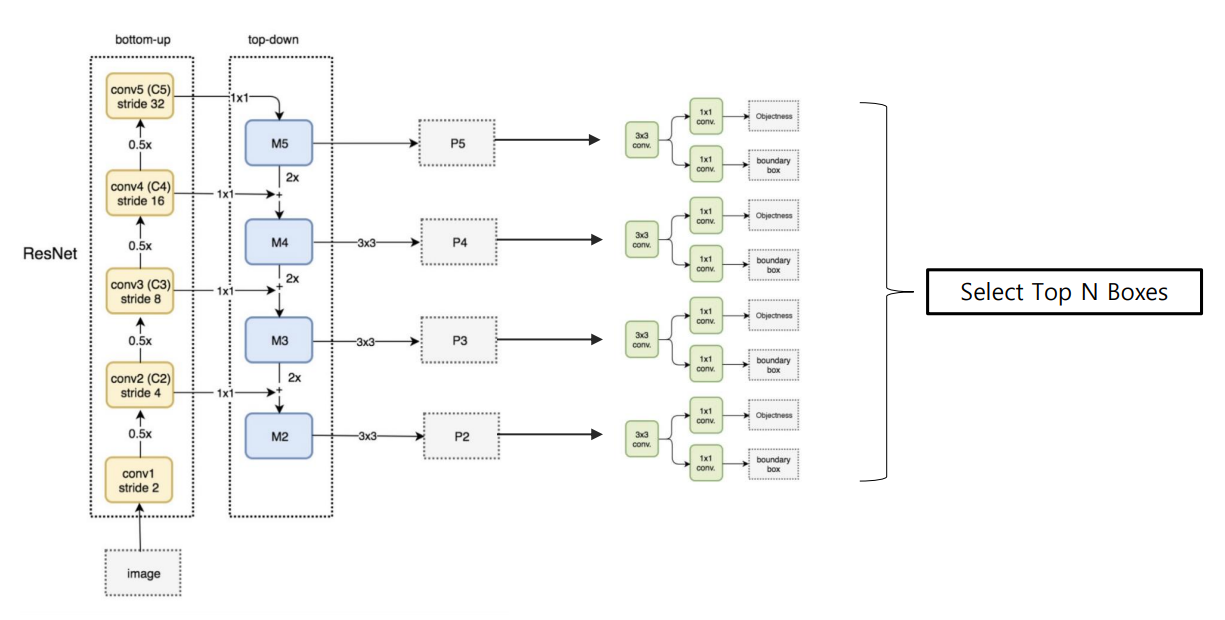
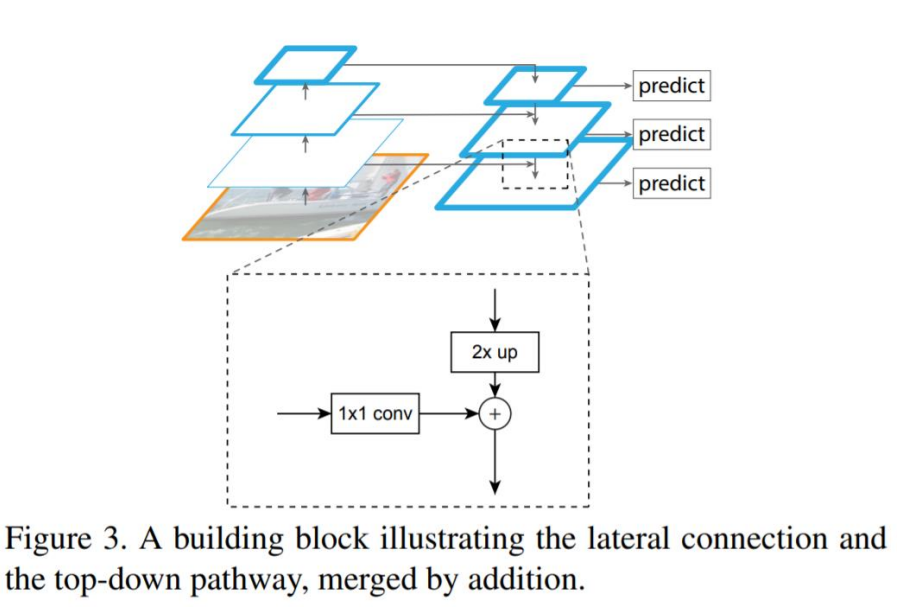
4.2 Feature Pyramid Network (FPN)
- high level에서 low level로 세맨틱 정보를 전달하는 방식.
- Bottom-up, Top-down, Lateral connections 등을 통해 구성
- Upsampling시 Nearest Neighbor Upsampling 방식을 사용.
- Backbone으로 ResNet을 사용하며, Top N Boxes를 선택하는 과정을 포함.
- ROI Pooling을 진행하기 위해서, ROI의 크기에 따라 적절한 feature map(p5~p2)을 선정하여 진행하였음.

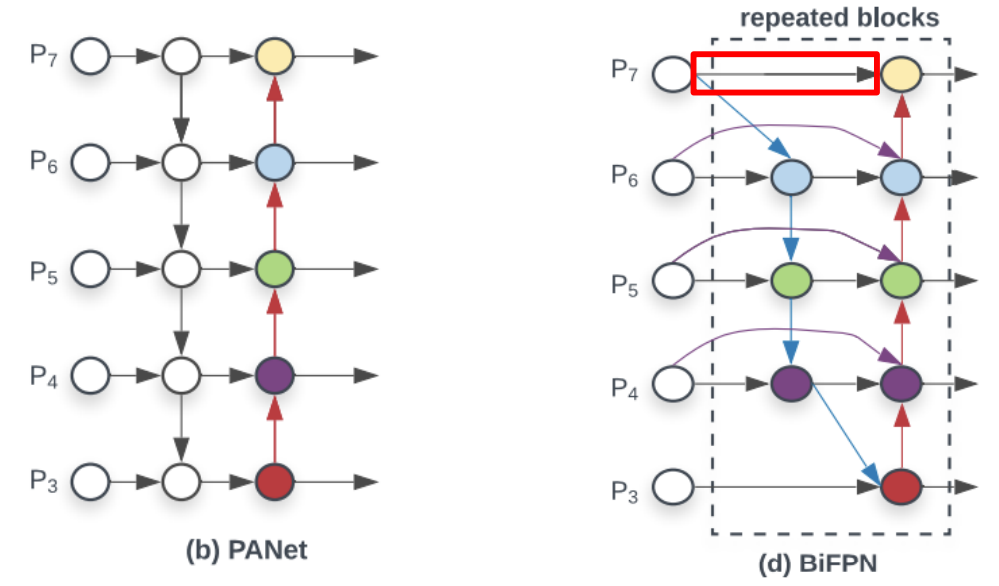
4.3 Path Aggregation Network (PANet)
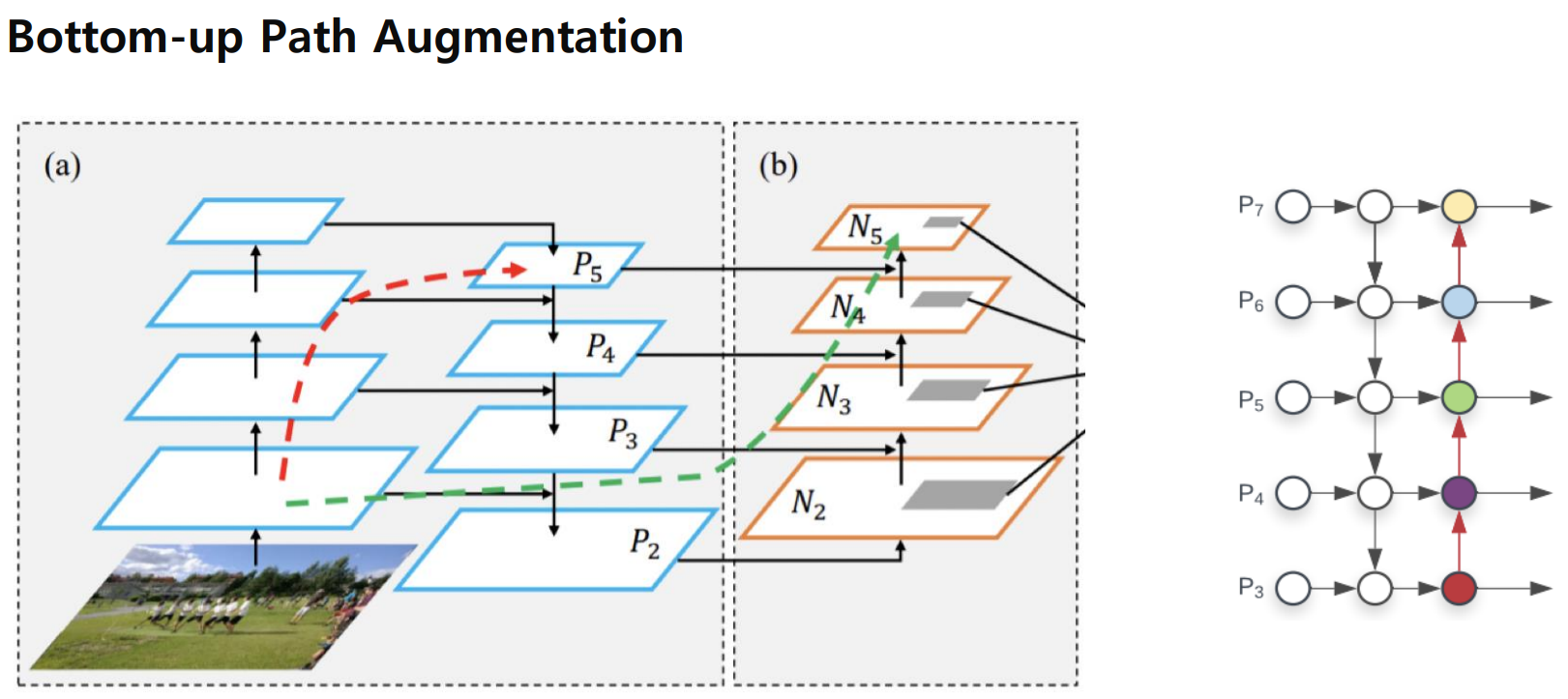
- Bottom-up Path Augmentation
- Top-down을 진행할 때 과연 Row level feature가 high level featuer에 전달이 되지 않을 수 있다.
- Bottom-up Path Augmentation을 사용하여 하위 level feature가 보다 상위 level에 잘 전달 하게 구조 개선
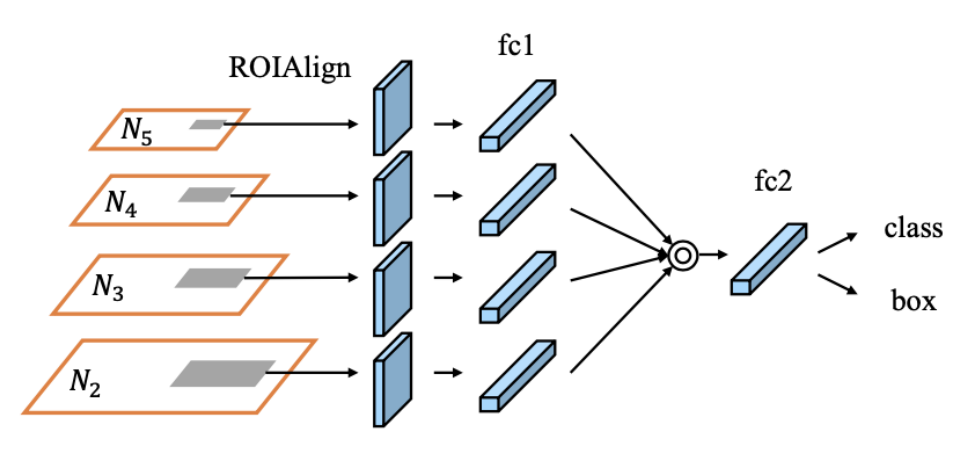
- Adaptive Feature Pooling
- ROI 풀링 시 경계 값에서 feture map을 선택하는데 있어 불연속적
- Adaptive Feature Pooling을 통해서 모든 feature map을 고려
4.4 DetectoRS
- DetectoRS 동기
- (RPN), Cascade R-CNN 등을 고려하여 반복적인 계산을 통해 성능 개선을 이룰 수 있을 거라 판단.
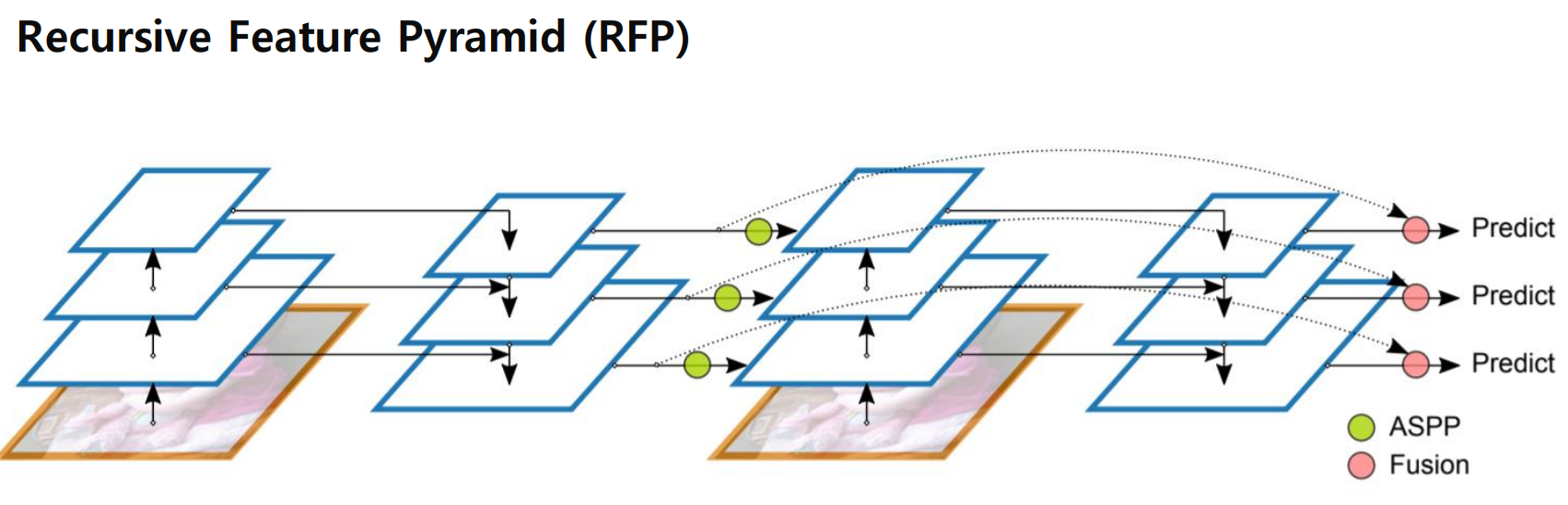
- Recursive Feature Pyramid (RFP)
- Neck의 정보를 활용하여 Backborn Network를 재학습
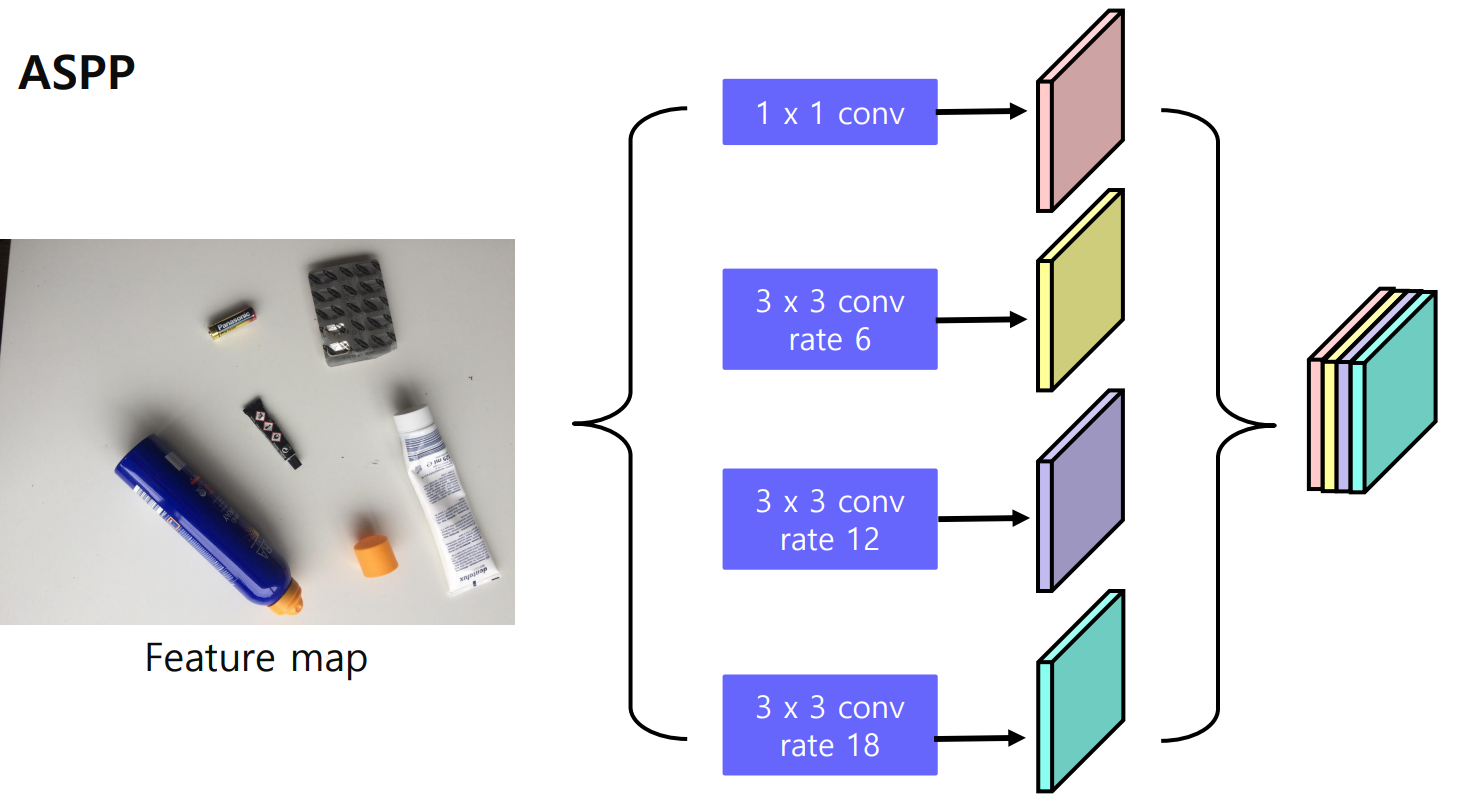
- Atrous Spatial Pyramid Pooling(ASPP) : 원본 feature를 여러 필터로 탐색하여, 보다 다양한 scale에서 유용한 정보를 뽑는 기법
- Atros Convolution

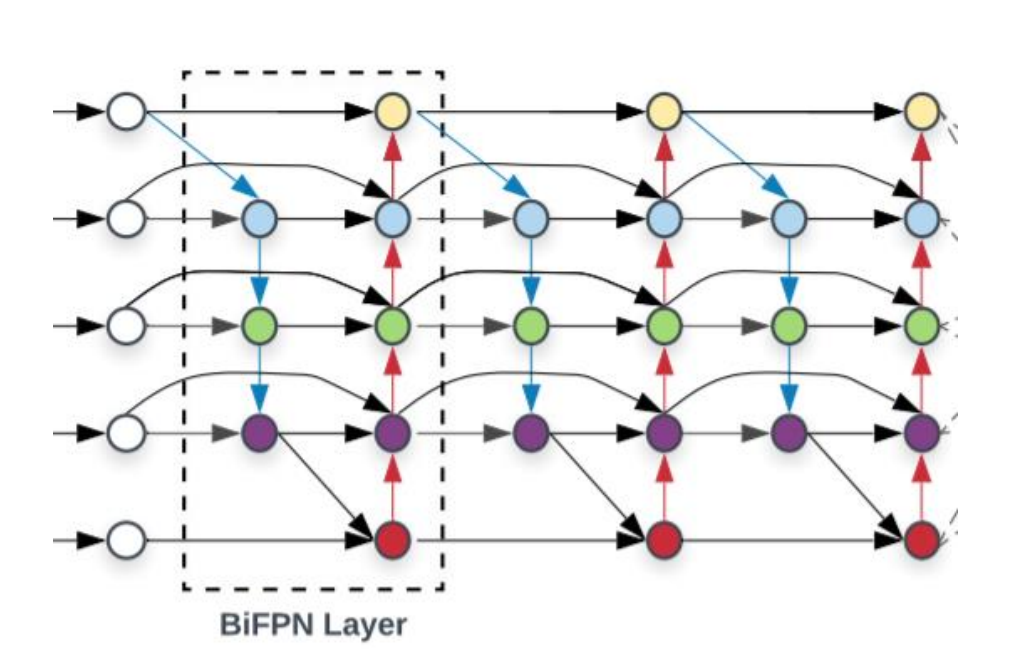
4.5 Bi-directional Feature Pyramid (BiFPN)
- 하나의 feature의 정보만 받게되는 노드 삭제
- 반복적으로 진행
- FPN과 달리, 각 feature에 가중치를 부여한 후 summation하는 방식
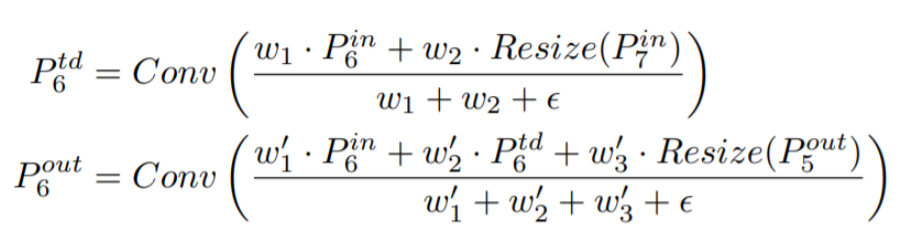
4.6 NASFPN
- FPN 아키텍처를 NAS(Neural architecture search)를 통해서 찾아보려는 시도
- Architecture, Search, Stacking 단계를 포함.
- COCO dataset ResNet 기준으로 찾은 architecture가 범용적이지 못하며, 많은 파라미터와 높은 search cost가 필요.
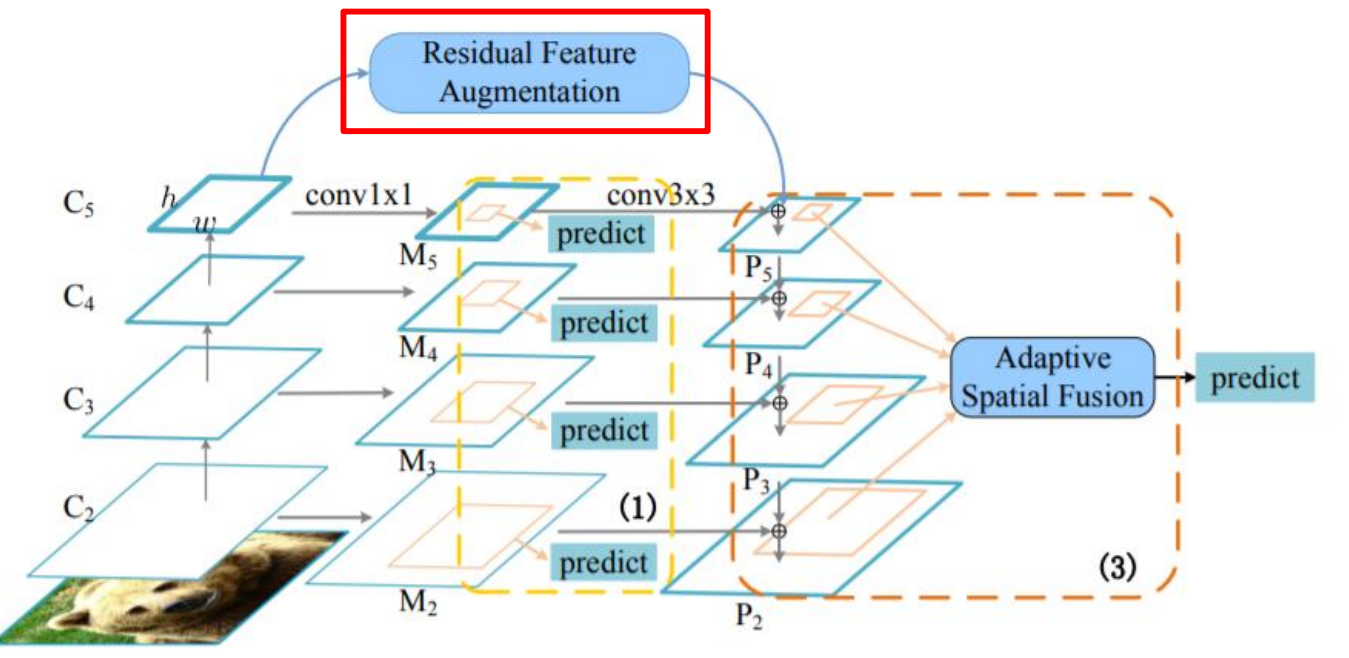
4.7 AugFPN
- FPN의 문제점, 특히 서로 다른 레벨의 feature 간의 semantic 차이, Highest feature map의 정보 손실, RoI 생성 방법 등을 개선
- Residual Feature Augmentation
- 최고층의 feature map에서 정보의 손실이 발생하는 것을 막기 위해 Residual Feature를 증강해서 새로운 feature map 생성
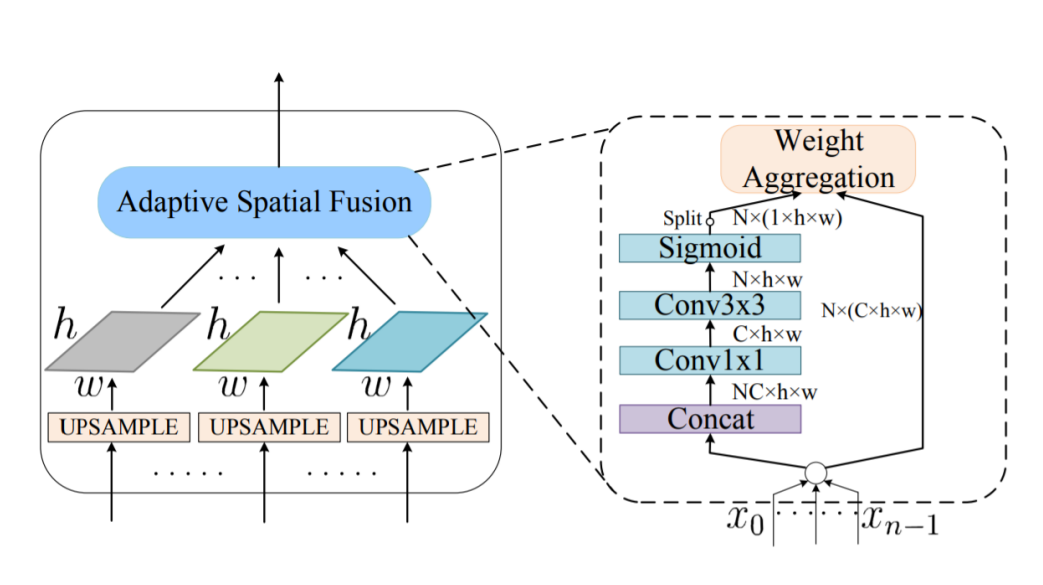
- 생성을 위해 Adaptive Spatial Fusion을 진행. 해당 과정에서 하위 feature map의 중요도를 학습하여 Weight Aggreation 진행
- Soft RoI Selection
- PANet의 max pooling시의 정보 손실을 막기 위해 시도
- 모든 scale의 feature에서 RoI projection 진행 후 RoI pooling
- Channel-wise 가중치 계산 후 가중합을 사용


Hi~