날짜 다루기
문자형을 날짜형으로 변경
날짜가 문자형으로 되어있다면 날짜형으로 변경해야 날짜 계산 가능
pd.to_datetime(컬럼, format='날짜 형식')
ex
df['Date1'] = pd.to_datetime(df['Date'], format='%Y-%m-%d')날짜를 원하는 형식으로 변경
데이터컬럼.dt.strftime(날짜형식)
df['Date1'].dt.strftime('%m-%d %H:%M')dt 연산자
| 연산자 | 설명 |
|---|---|
| year | 연도 |
| month | 월 |
| day | 일 |
| dayofweek | 요일(0-월요일, 6-일요일) |
| day_name() | 요일을 문자열로 |
날짜 계산
day 연산: pd.Timedelta(*days*=숫자)
month 연산: DateOffset(months=숫자)
year 연산: DateOffset(years=숫자)
df['plus day1'] = df['Date1'] + pd.Timedelta(days=1)
df['minus month3'] = df['Date1'] - DateOffset(months=3)
df['minus year3'] = df['Date1'] - DateOffset(years=3)날짜 구간 데이터 만들기
pd.date_range(start=시작일자, end=종료일자, periods=기간수, freq=주기)
| 형식 | 설명 |
|---|---|
| D | 일별 |
| W | 주별 |
| M | 월별 말일 |
| MS | 월별 시작일 |
| A | 연도별 말일 |
| AS | 연도별 시작일 |
pd.date_range(start='2020-01-01', end='2023-06-30', freq='AS')기간 이동 계산
컬럼.rolling().집계함수
#7일 이동평균
df1['ma7'] = df1['Temp'].rolling(7).mean()apply, map, 문자열 다루기
apply
사용자 정의 함수를 데이터에 적용하고 싶을 때 사용
.apply(함수, axis=0/1
def pclass_sibsp(x):
if x['Pclass'] == 1 and x['SibSp'] == 1:
return 1
else:
return 0
df1['pcalss_sibsp_filter'] = df1.apply(pclass_sibsp, axis=1)
# 간단한 함수는 lambda로 구현
df1['pclass_sibsp_lambda'] = df.apply(lambda x: 1 if x['Pclass']==1 and x['SibSp']==1 else 0, axis=1)map
값을 특정 값으로 치환할 때 사용
데이터명[컬럼명].map(매핑 딕서너리)
gender_map = {'male':'남자', 'female':'여자'}
df1['Sex_kr'] = df1['Sex'].map(gender_map)문자열 다루기
| 메소드 | 설명 |
|---|---|
.str.contains(문자열) | 문자열을 포함하고 있는지 유무 |
.str.replace(기존문자열, 대치문자열) | 문자열 대치 |
.str.split(문자열, expand=True/False, n=개수) | 특정 문자열을 기준으로 쪼개기 |
.str.lower() | 소문자로 바꾸기 |
.str.upper() | 대문자로 바꾸기 |
df2[df2['Name'].str.contains('Mrs')]데이터 결합
두 개의 데이터를 특정 컬럼을 기준으로 합친다
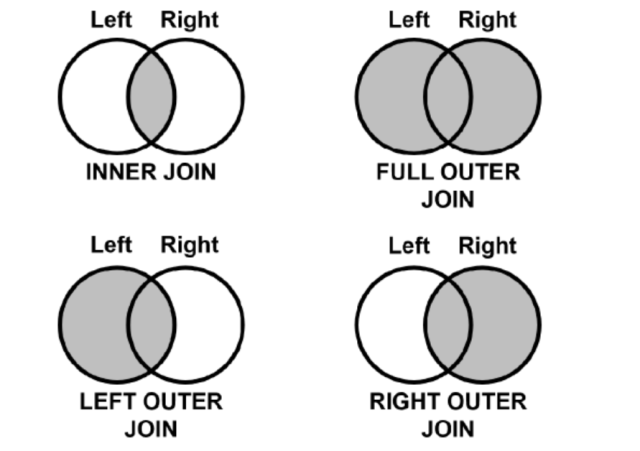
pd.merge(데이터1, 데이터2, on=기준컬럼, how=결합방법)
pd.merge(customer, orders, on='id', how='inner')두 데이터의 기준 컬럼명이 다를 경우
pd.merge(데이터1, 데이터2, left_on=데이터1의 기준컬럼, right_on=데이터2의 기준컬럼, how=결합방법
pd.merge(customer, orders, left_on='id', right_on='customer_id', how='inner')데이터 집계(groupby)
같은 값을 한 그룹으로 묶어서 여러 가지 연산 및 통계를 구할 수 있다
데이터.groupby(컬럼명).연산및통계함수
단일 그룹
| 함수 | 설명 |
|---|---|
| count() | 행의 갯수 |
| nunique() | 행의 유니크한 갯수 |
| sum() | 합 |
| mean() | 평균 |
| min() | 최솟값 |
| max() | 최댓값 |
| std() | 표준편차 |
| var() | 분산 |
df.groupby('Pclass').var(numeric_only=True)다중 그룹
df.groupby(['Sex','Pclass']).mean(numeric_only=True)
df.groupby(['Sex','Pclass'])[['Survived','Age','SibSp','Parch','Fare']].aggregate([np.mean, np.min, np.max])crosstab
범주형 데이터를 비교분석할 때 유용
pd.crosstab(index=행, columns=열, margins=True/False, normalize=True/False)
범주별 갯수 구하기
pd.crosstab(행, 열)
pd.crosstab(df['Sex'], df['Survived'])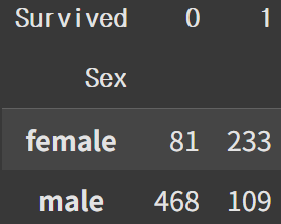
범주별 비율 구하기
normalize = 'all': 전체 합이 100%
normalize = 'index': 행별 합이 100%
normalize = 'columns': 열별 합이 100%
pd.crosstab(df['Sex'], df['Survived'], normalize='all')pd.crosstab(df['Sex'], df['Survived'], normalize='all', margins=True)
# margins=True 전체합도 볼 수 있다다중 인덱스, 다중 컬럼의 범주표 구하기
pd.crosstab(index=[df['Sex'], df['Pclass']], columns=df['Survived'], normalize='all')피벗테이블
인덱스별 컬럼별 값의 연산을 할 수 있다
pd.pivot_table(데이터명, index=, columns=, values=, aggfunc=)
단일 인덱스, 단일 컬럼, 단일 값
pd.pivot_table(df, index='Sex', columns='Pclass', values='Survived', aggfunc='mean')다중 인덱스, 다중 컬럼, 다중 값
pd.pivot_table(df, index=['Sex','Pclass'], columns='Survived', values='Age', aggfunc='mean')stack, unstack, melt
stack, unstack
stack: 컬럼 레벨에서 인덱스 레벨로 데이터프레임을 변경
unstack: 인덱스 레벨에서 컬럼 레벨로 데이터프레임 변경
pivot.stack(0) #컬럼의 첫번째 레벨을 인덱스로 내립니다.
pivot.stack(1) #컬럼의 두번째 레벨을 인덱스로 내립니다.
pivot.unstack(0) #인덱스의 첫번째 레벨을 컬럼으로 쌓아 올립니다
pivot.unstack(1) #인덱스의 두번째 레벨을 컬럼으로 쌓아 올립니다melt
pd.melt(데이터명, id_vars=기준 컬럼)
pd.melt(data, id_vars=['name'], var_name='type', value_name='val')