훈련 데이터
컬럼 설명
PassengerId : 승객 ID
HomePlanet : 출발 행성(거주지)
CryoSleep : 취침 방식 여부
Cabin : 객실 종류 및 번호 (port : 좌현, starboard : 우현)
Destination : 목적지
Age : 승객의 나이
VIP : 승객의 VIP 서비스 유무
RoomService, FoodCourt, ShoppingMall, Spa, VRDeck : 승객이 해당 서비스에 대해 지불한 금액
Name : 이름
Transported : 도착 여부
데이터 구조 - 훈련 데이터: (8693, 14), 테스트 데이터: (4277, 13)

훈련데이터 info
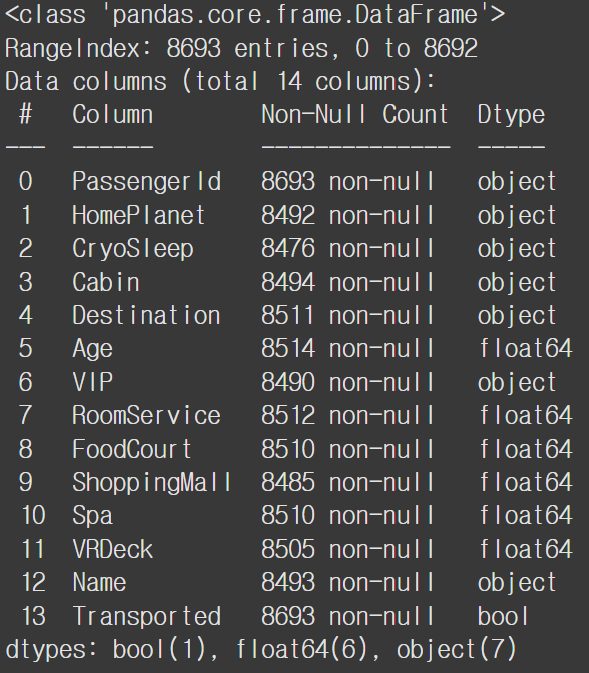
결측치 확인
이산형 변수의 EDA
전처리
범주형, 수치형에 대한 결측치 처리 다르다. 범주형(최빈값), 수치형(중앙값)으로 결측치 처리
# 범주형 데이터에 대한 NaN 처리
train_data['HomePlanet'] = train_data['HomePlanet'].fillna(train_data['HomePlanet'].mode()[0])
train_data['CryoSleep'] = train_data['CryoSleep'].fillna(train_data['CryoSleep'].mode()[0])
train_data['Cabin'] = train_data['Cabin'].fillna(train_data['Cabin'].mode()[0])
train_data['Destination'] = train_data['Destination'].fillna(train_data['Destination'].mode()[0])
train_data['VIP'] = train_data['VIP'].fillna(train_data['VIP'].mode()[0])
train_data['Name'] = train_data['Name'].fillna('Unknown')
# 수치형 데이터에 대한 NaN 처리
train_data['Age'] = train_data['Age'].fillna(train_data['Age'].median())
train_data['RoomService'] = train_data['RoomService'].fillna(train_data['RoomService'].median())
train_data['FoodCourt'] = train_data['FoodCourt'].fillna(train_data['FoodCourt'].median())
train_data['ShoppingMall'] = train_data['ShoppingMall'].fillna(train_data['ShoppingMall'].median())
train_data['Spa'] = train_data['Spa'].fillna(train_data['Spa'].median())
train_data['VRDeck'] = train_data['VRDeck'].fillna(train_data['VRDeck'].median())Cabin열은 B/0/P으로 구성 되있어서 분리할 필요 있다.
cabin=train_data['Cabin'].apply(lambda x: x.split('/'))
train_data['Cabin1']=cabin.apply(lambda x: x[0])
train_data['Cabin2']=cabin.apply(lambda x: float(x[1]))
train_data['Cabin3']=cabin.apply(lambda x: x[2])모델에 영향을 주지 않을 것 같은 'PassengerId', 'Name', 'Cabin' 열 제거
train_data.drop(['PassengerId', 'Name', 'Cabin'], axis=1, inplace=True)
불리언 컬럼인 'CryoSleep', 'VIP', 'Transported' 컬럼 int로 데이터 타입 변경
train_data['CryoSleep']=train_data['CryoSleep'].astype(int)
train_data['VIP']=train_data['VIP'].astype(int)
train_data['Tranported']=train_data['Transported'].astype(int)데이터 타입이 'int', 'float'인 컬럼만 상관계수 히트맵으로 시각화
num_feat=train_data.select_dtypes(include=['int64', 'float64'])
corr_matrix=num_feat.corr()
plt.figure(figsize=(10,8))
sns.heatmap(corr_matrix, annot=True, cmap='Blues', linewidths=0.5)
plt.show()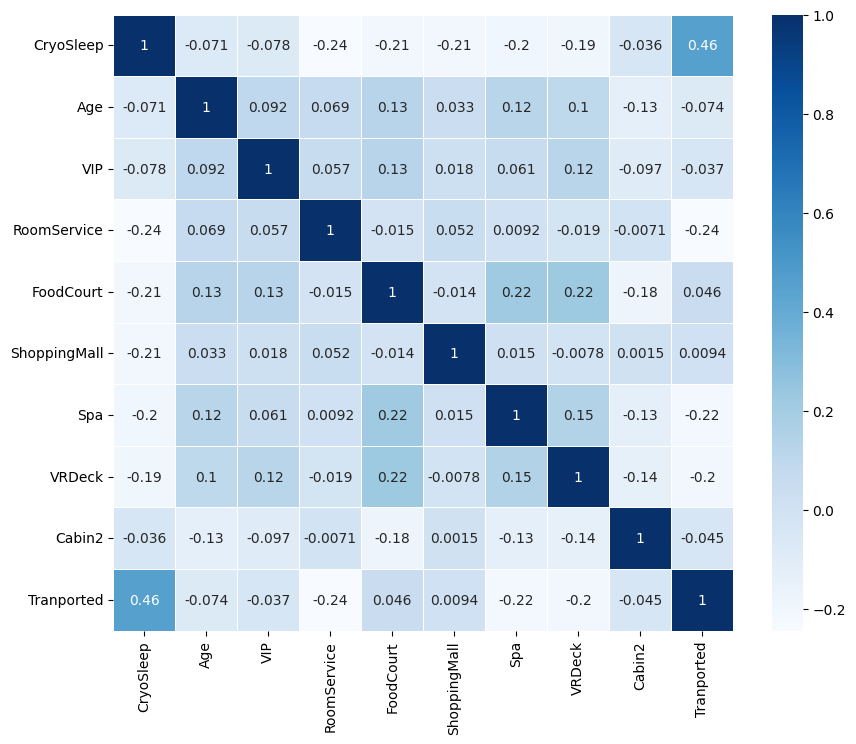
원핫인코딩을 이용해 범주형 데이터를 수치형으로 변경
encoding_df=pd.get_dummies(train_data)
encoding_df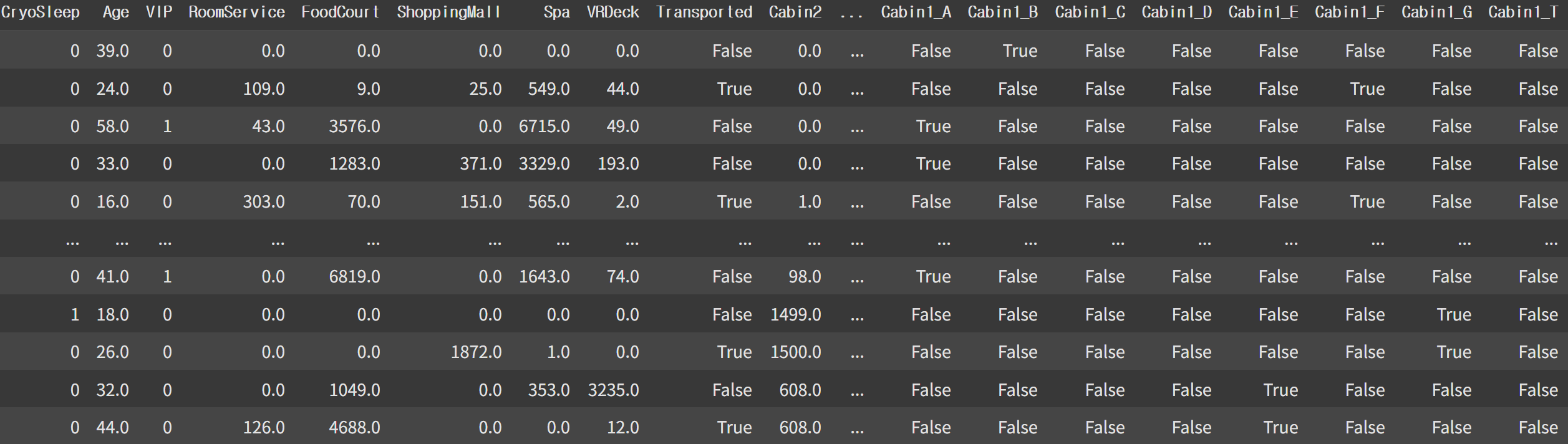
하지만 원핫인코딩을 했기 때문에 변수가 너무 많아졌다
그래서 주성분 분석(PCA)를 이용해 주요 변수 확인
from sklearn.decomposition import PCA
pca=PCA(n_components=10)
pca_df=pca.fit_transform(encoding_df)
col=['pca'+str(i) for i in range(10)]
pca_df=pd.DataFrame(pca_df, columns=col)
pca_df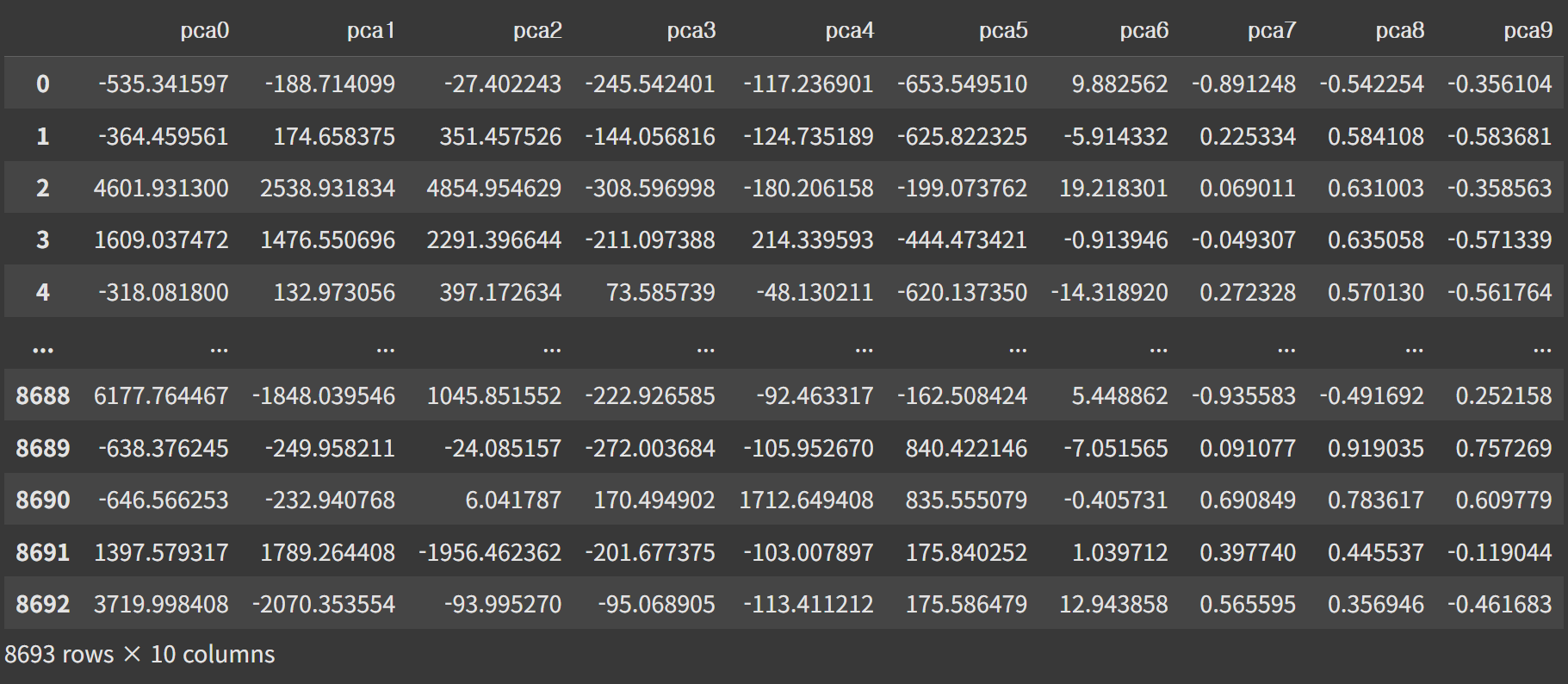
데이터셋 분리
from sklearn.model_selection import train_test_split
target=train_data['Tranported']
x_train, x_test, y_train, y_test=train_test_split(pca_df, target, test_size=0.2, random_state=42)모델 설계
랜덤 서치를 사용해 최적의 하이퍼파라미터 조합 확인
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
model=RandomForestClassifier(n_jobs=-1, random_state=42)
params = { 'n_estimators' : [50, 100, 200, 300, 400],
'max_depth' : [4, 6, 8, 10, 12, 16],
'min_samples_leaf' : [4, 8, 12, 16, 20], #과적합 제어
'min_samples_split' : [4, 8, 12, 16, 20] #과적합 제어
}
from sklearn.model_selection import RandomizedSearchCV
import numpy as np
random_model = RandomizedSearchCV(
model, param_distributions=params, n_iter=10, cv=5, n_jobs=-1, random_state=42
)
random_model.fit(x_train, y_train)
print(random_model.best_params_)
print(random_model.best_score_)
{'n_estimators': 100, 'min_samples_split': 8, 'min_samples_leaf': 4, 'max_depth': 12}
0.9876330366332384모델 평가
rf_model=RandomForestClassifier(n_estimators=100, min_samples_split=8, min_samples_leaf=4,
oob_score=True, max_depth=12)
rf_model.fit(x_train, y_train)
rf_model.predict(x_test)
print('훈련 세트 점수:', rf_model.score(x_train, y_train))
print('테스트 세트 점수:', rf_model.score(x_test, y_test))
print('OOB 점수:', rf_model.oob_score_)
훈련 세트 점수: 0.996836353178027
테스트 세트 점수: 0.9856239217941346
OOB 점수: 0.9874892148403797주성분 분석의 결과 시각화
importances_feat=rf_model.feature_importances_
feat_importance=pd.Series(importances_feat, index=x_train.columns)
sorted_feat=feat_importance.sort_values(ascending=False)
plt.figure(figsize=(12,10))
plt.title('Feature Importances')
sns.barplot(x=sorted_feat, y=sorted_feat.index)
plt.show()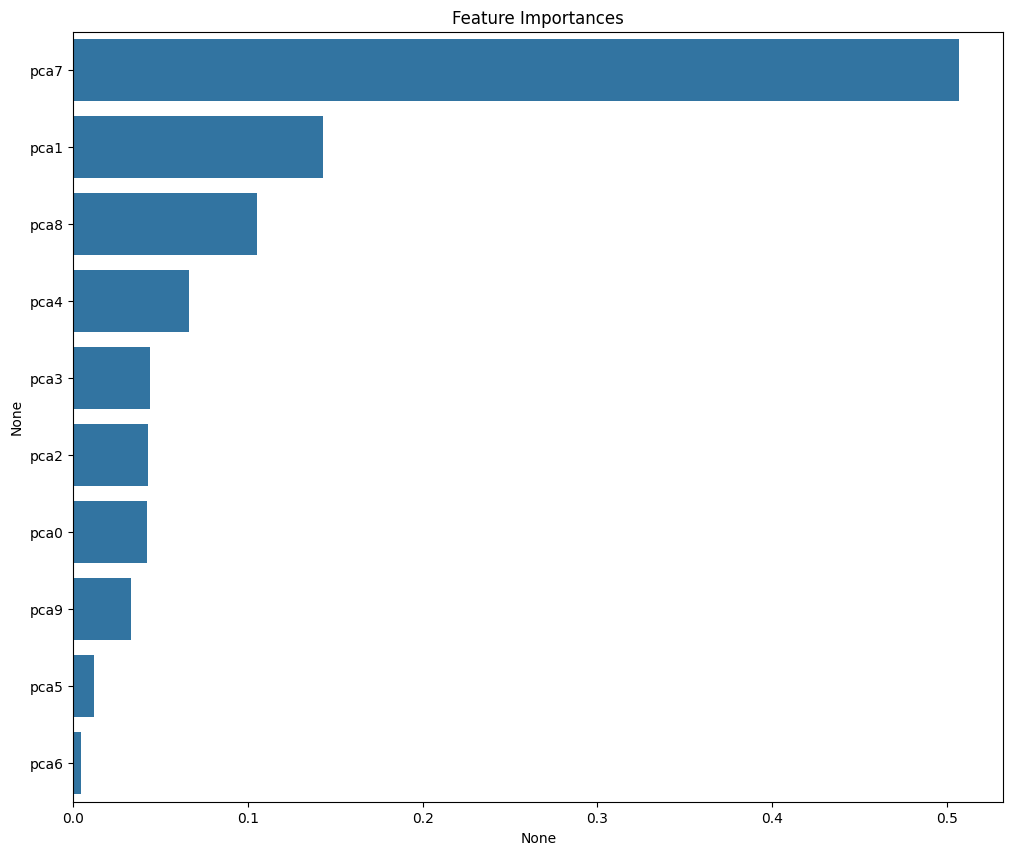
테스트 데이터
테스트 데이터에도 같은 전처리 수행
# 범주형 데이터에 대한 NaN 처리
test_data['HomePlanet'] = test_data['HomePlanet'].fillna(test_data['HomePlanet'].mode()[0])
test_data['CryoSleep'] = test_data['CryoSleep'].fillna(test_data['CryoSleep'].mode()[0])
test_data['Cabin'] = test_data['Cabin'].fillna(test_data['Cabin'].mode()[0])
test_data['Destination'] = test_data['Destination'].fillna(test_data['Destination'].mode()[0])
test_data['VIP'] = test_data['VIP'].fillna(test_data['VIP'].mode()[0])
test_data['Name'] = test_data['Name'].fillna('Unknown')
# 수치형 데이터에 대한 NaN 처리
test_data['Age'] = test_data['Age'].fillna(test_data['Age'].median())
test_data['RoomService'] = test_data['RoomService'].fillna(test_data['RoomService'].median())
test_data['FoodCourt'] = test_data['FoodCourt'].fillna(test_data['FoodCourt'].median())
test_data['ShoppingMall'] = test_data['ShoppingMall'].fillna(test_data['ShoppingMall'].median())
test_data['Spa'] = test_data['Spa'].fillna(test_data['Spa'].median())
test_data['VRDeck'] = test_data['VRDeck'].fillna(test_data['VRDeck'].median())cab = test_data["Cabin"].apply(lambda x: x.split("/"))
test_data["Cab_1"] = cab.apply(lambda x: x[0])
test_data["Cab_3"] = cab.apply(lambda x: x[2])
test_data["Cab_2"] = cab.apply(lambda x: float(x[1]))
test_data.drop(['PassengerId', 'Name', 'Cabin'], axis = 1, inplace = True)
test_data["VIP"] = test_data["VIP"].astype(int)
test_data["CryoSleep"] = test_data["CryoSleep"].astype(int)
encoded_test_data = pd.get_dummies(test_data)
test_data = encoded_test_data.drop(['Cab_1_A', 'Cab_1_G', 'Cab_1_T', 'Cab_1_D', 'Cab_1_C', 'VIP', 'HomePlanet_Mars', 'Destination_PSO J318.5-22'], axis = 1)pca=PCA(n_components=10)
pca_test=pca.fit_transform(encoded_test_data)
pca_col=[]
for i in range(0, 10):
x='pca'+str(i)
pca_col.append(x)
pca_df=pd.DataFrame(pca_test, columns=pca_col)
pca_rf = rf_model.predict(pca_df)
sample_submission = pd.read_csv('sample_submission.csv')
sample_submission['Transported'] = pca_rf.astype(bool)
sample_submission.to_csv('submission.csv',index = False)
sample_submission.head()테스트 데이터 예측 결과