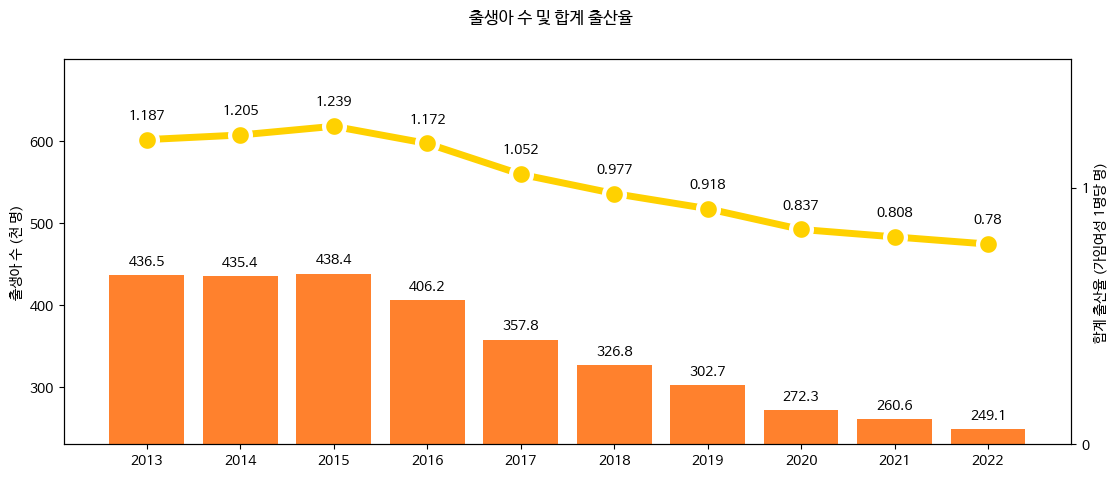
나도코딩 데이터 분석편 프로젝트 활용
import pandas as pd
df=pd.read_excel('142801_20240131145645553_excel.xlsx', skiprows=2, nrows=2, index_col=0)
df인덱스를 적용이 안돼서 확인했는데 띄어쓰기 때문에 이상한 값이 들어 가 있음
df.index.valuesarray(['출생아 수', '합계 출산율'], dtype=object)
T를 활용하여 시각화 할 때 편하게 설정했음
df=df.T
df처음 그래프를 그렸을 때 단순 수치상으로 차이가 많이 나기 때문에 그래프가 좋지 않음
plt.plot(df.index, df['출생아 수'])
plt.plot(df.index, df['합계 출산율'])
plt.show()
그래서 twinx를 활용하여 이를 보완했음
fig, ax1=plt.subplots(figsize=(15,10))
ax1.plot(df.index, df['출생아 수'], color='#ff812d')
ax2=ax1.twinx() # x 축을 공유하는 쌍둥이 axis
ax2.plot(df.index, df['합계 출산율'], color='#ffd100')
fig.show()
비교를 편하게하기 위해 막대그래프 활용
fig, ax1=plt.subplots(figsize=(10,7))
ax1.set_ylabel('출생아 수 (천 명)')
ax1.bar(df.index, df['출생아 수'], color='#ff812d')
ax2=ax1.twinx() # x 축을 공유하는 쌍둥이 axis
ax2.set_ylabel('합계 출산율 (가임여성 1명당 명)')
ax2.plot(df.index, df['합계 출산율'], color='#ffd100')
fig.show()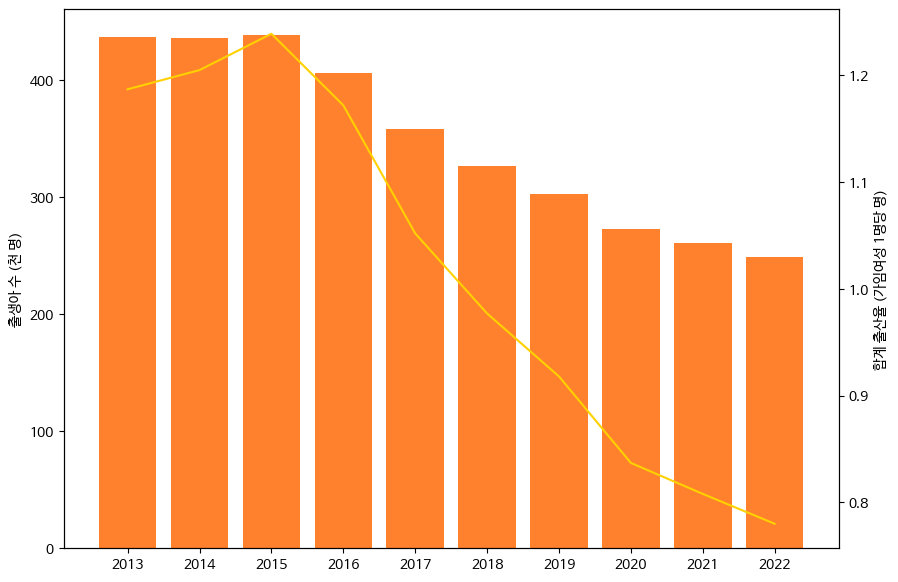
그래프 가독성을 위해 범례추가와 정확한 수치를 표시하고 ylim을 활용해 y축에 제한을 두었다
fig, ax1=plt.subplots(figsize=(13,5))
fig.suptitle('출생아 수 및 합계 출산율')
ax1.set_ylabel('출생아 수 (천 명)')
ax1.set_ylim(230,700)
ax1.set_yticks([300,400,500,600])
ax1.bar(df.index, df['출생아 수'], color='#ff812d')
for idx, val in enumerate(df['출생아 수']):
ax1.text(idx, val+12, val,ha='center')
ax2=ax1.twinx() # x 축을 공유하는 쌍둥이 axis
ax2.set_ylabel('합계 출산율 (가임여성 1명당 명)')
ax2.plot(df.index, df['합계 출산율'], color='#ffd100', marker='o', markersize=15, linewidth=5,mec='w',mew=3)
ax2.set_ylim(0,1.5)
ax2.set_yticks([0,1])
for idx, val in enumerate(df['합계 출산율']):
ax2.text(idx, val+0.08, val, ha='center')
fig.show()최종 시각화