
워드 임베딩
워드 임베딩: 단어를 벡터로 표현하는 방법으로, 단어를 밀집 표현으로 변환
희소 표현: 벡터 또는 행렬의 값이 대부분 0으로 표현되는 방법(원-핫 벡터, DTM)
희소 벡터의 문제점: 단어의 개수가 늘어나면 벡터의 차원이 한없이 커져 공간적 낭비를 발생시킨다
밀집 표현: 사용자가 설정한 값으로 모든 단어의 벡터 표현의 차원을 맞춘다. 이 과정에서 0과 1만 가진 값이 아닌 실수값을 가진다
워드 임베딩: 단어의 밀집 벡터의 형태로 표현하는 방법. 밀집 벡터를 워드 임베딩 과정을 통해 나온 결과 -> 임베딩 벡터
워드 임베딩 방법론: LSA, Word2Vec, FastText, Glove
Word2Vec
Word2Vec
원-핫 벡터는 단어 벡터 간 유의미한 유사도를 계산할 수 없다는 단점을 가진다
그래서 단어 벡터 간 유의미한 유사도를 반영할 수 있도록 단어의 의미를 수치화하는 방법 ->
분산 표현: 단어의 의미를 다차원 공간에 벡터화하는 방법
워드 임베딩: 분산 표현을 이용해 단어 간 의미적 유사성을 벡터화 하는 작업
Word2Vec의 학습 방식: CBOW, Skip-Gram
CBOW(Continuous Bag of Words)
주변 단어(Context word)들을 입력으로 중심 단어(Center word)들을 예측하는 방법
윈도우: 중심 단어를 예측하기 위해서 앞,뒤로 몇 개의 단어를 볼 범위
슬라이딩 윈도우: 윈도우를 옆으로 움직여서 주변 단어와 중심 단어의 선택을 변경하면서 학습을 위한 데이터 셋을 만드는 방법
입력층의 입력으로 윈도우 범위 안에 있는 주변 단어들의 원-핫 벡터
출력층에서 예측하려 하는 중심 단어의 원-핫 벡터가 레이블로 필요
Worw2Vec는 은닉층이 1개인 얕은 신경망
Word2Vec의 은닉층은 일반적인 은닉층과 달리 활성화 함수가 없고, 룩업 테이블이라는 연산을 담당하는 투사층(projection layer)이라 부르기도 한다
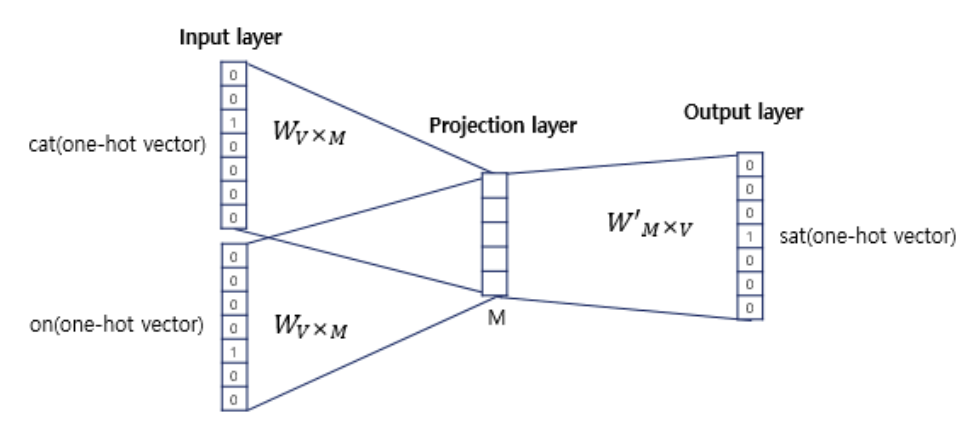
소프트맥스를 지나고 손실 함수로 크로스 엔트로피 사용
Skip-gram
Skip-gram은 중심 단어에서 주변 단어를 예측
일반적으로 Skip-gram이 CBOW보다 성능이 좋다
Doc2Vec
Doc2Vec는 Word2Vec을 변현해 문서의 임베딩을 얻을 수 있는 알고리즘
데이터 업로드 및 필요 라이브러리 로드
!pip install --upgrade --no-cache-dir gdown
# dart.csv 파일 다운로드
!gdown https://drive.google.com/uc?id=1XS0UlE8gNNTRjnL6e64sMacOhtVERIqL
# 형태소 분석기 Mecab 설치
!pip install konlpy
!pip install mecab-python
!bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)
import pandas as pd
from konlpy.tag import Mecab
from gensim.models.doc2vec import TaggedDocument
from tqdm import tqdm
code: 종목 번호에 해당하는 열
market: KOSPI, KOSDAQ인지 알려주는 열
name: 회사명
business: 학습에 필요한 사업 보고서
Doc2Vec 학습을 위해서는 문서의 "제목"과 단어 토큰화가 된 해당 문서의 "본문"이 필요
TaggedDocument의 tags에 해당 문서의 제목을, words에 해당 문서의 본문에 해당하는 단어 토큰화 결과를 리스트에 저장
mecab = Mecab()
tagged_corpus_list = []
for index, row in tqdm(df.iterrows(), total=len(df)):
text = row['business']
tag = row['name']
tagged_corpus_list.append(TaggedDocument(tags=[tag], words=mecab.morphs(text)))TaggedDocument(words=['II', '.', '사업', '의', '내용', '1', '.', '사업', '의', '개요', '가', '.', '일반', '적', '인', '사항', '기업', '회계', '기준', '서', '제', '1110', '호', '"', '연결', '재무제표', '"', '의', '의하', '여', '2018', '년', '12', '월', '17', '일', '에', '설립', '한', '동화', '크립톤', '기업가', '정신', '제일', '호', '창업', '벤처', '전문', '사모', '투자', '합자회사', '를', '종속', '회사', '에', '편입', '하', '였', '습니다', ... 중략 ... '대기', '관리', '권', '역', '의', '대기', '환경', '개선', '에', '관한', '특별법', '을', '준', '수', '하', '고', '있', '습니다', '.'], tags=['동화약품'])words에는 토큰화 된 사업 보고서, tags에는 해당 문서의 제목이 저장되있다
Doc2Vec 학습, 테스트
from gensim.models import doc2vec
model = doc2vec.Doc2Vec(vector_size=300, alpha=0.025, min_alpha=0.025, workers=8, window=8)
# Vocabulary 빌드
model.build_vocab(tagged_corpus_list)
# Doc2Vec 학습
model.train(tagged_corpus_list, total_examples=model.corpus_count, epochs=20)
# 모델 저장
model.save('dart.doc2vec')코드를 실행시키면 dart.doc2vec, dart.doc2vec.syn1neg.npy, dart.doc2vec.wv.vectors.npy 3개의 파일이 생긴다
LG이노텍과 사업보고서가 유사한 회사들 확인
similar_doc = model.dv.most_similar('LG이노텍')
print(similar_doc)[('LG전자', 0.533338725566864), ('LG', 0.523799479007721), ('삼성전기', 0.45796477794647217), ('LG디스플레이', 0.4485859274864197), ('서울반도체', 0.42762115597724915), ('루멘스', 0.42333459854125977), ('삼성SDI', 0.4111291170120239), ('큐엠씨', 0.409035325050354), ('서울바이오시스', 0.4087420105934143), ('삼성공조', 0.4040142595767975)]