최근 recursive CTE를 활용한 쿼리를 작성해서 정리하려고 한다.
문제 설명
각 세대별 자식이 없는 개체의 수(COUNT)와 세대(GENERATION)를 출력하는 SQL문을 작성해주세요. 이때 결과는 세대에 대해 오름차순 정렬해주세요.
단, 모든 세대에는 자식이 없는 개체가 적어도 1개체는 존재합니다.
| 컬럼명 | 타입 | 설명 |
|---|---|---|
ID | INTEGER | 대장균 개체 ID |
PARENT_ID | INTEGER | 부모 개체 ID (NULL 가능) |
SIZE_OF_COLONY | INTEGER | 개체의 크기 |
DIFFERENTIATION_DATE | DATE | 분화된 날짜 |
GENOTYPE | INTEGER | 형질 (비트 기반 인코딩) |
이 문제에서는 generation 컬럼을 만들기 위해서는 recursive CTE 작성이 필수
RECURSIVE CTE
WITH RECURSIVE 쿼리문을 작성하고 내부에 UNION을 활용해서 재귀를 구성한다
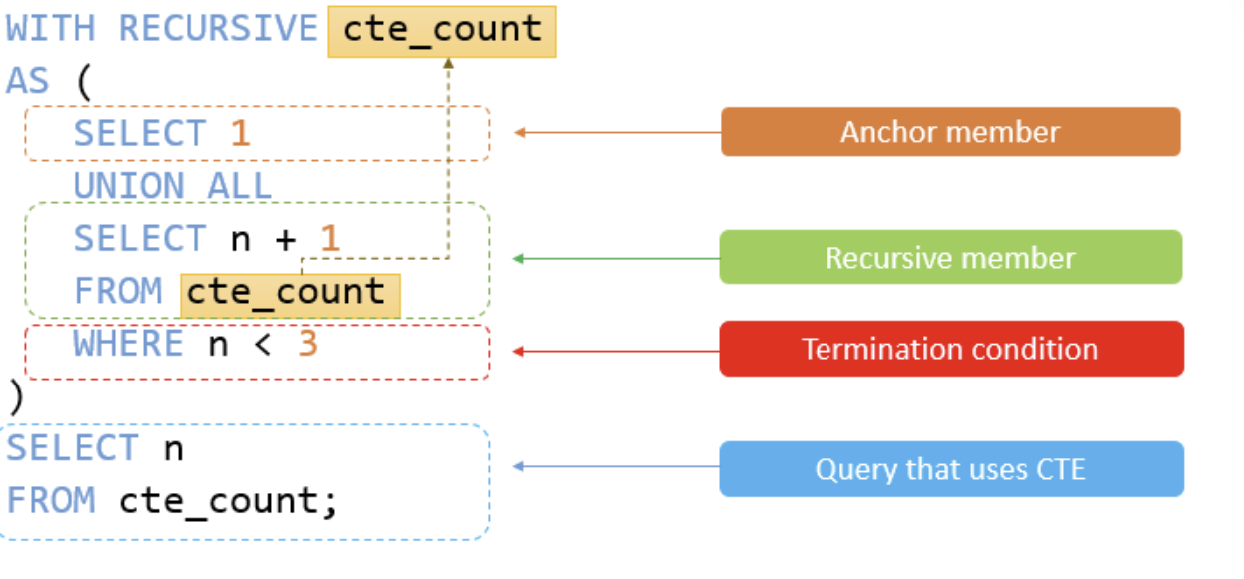
| 구성 요소 | 역할 |
|---|---|
| Anchor 쿼리 | 재귀의 시작점 (기준 노드) |
| Recursive 쿼리 | 자기 자신을 반복 호출하며 계층 확장 |
UNION ALL | 재귀 호출을 이어 붙임 (중복 허용 시 ALL) |
| 종료 조건 | 재귀 조건 안의 WHERE 또는 깊이 제한 |
주의사항
종료 조건이 없다면 무한 루프 발생 (무조건 WHERE 등으로 제한 필요)
DBMS마다 RECURSIVE 키워드를 써야 할 수도 있고 안 써도 되는 경우도 있음
(예: PostgreSQL: WITH RECURSIVE, MySQL: WITH RECURSIVE, SQL Server: WITH)
MySQL은 기본적으로 1000회 재귀 제한 (max_recursion_depth)
UNION ALL 대신 UNION을 쓰면 중복 제거되나 성능 저하 가능
정답 쿼리
WITH recursive t as (
SELECT id, 1 generation
FROM ecoli_data ed
WHERE parent_id is null
UNION ALL
SELECT ecoli_data.id, generation + 1
FROM ecoli_data
JOIN t on ecoli_data.parent_id = t.id
)
SELECT count(*) `count`, generation
FROM t
WHERE id not in (SELECT parent_id
FROM ecoli_data
WHERE parent_id is not null)
GROUP BY 2리뷰
Anchor 쿼리: 최초 대장균 개체 (parent_id가 없는 개체)를 generation 1로 시작
Recursive 쿼리: 부모 개체를 따라가며 generation을 1씩 증가시킴
마지막 조회하는 구문에서 not null 조건을 안넣으면 in 조건에서는 어떤 것도 반환하지 않음
