딥러닝 감 찾을 겸, 데이콘에 있는 채무 불이행 여부 분류 해커톤에 참가한 코드를 적어 보기로 했다.
데이터 셋

데이터는 18개의 피처를 기반으로 채무불이행여부(0, 1)을 예측하는 문제이다.
전처리
우선 "현재 직장 근속 연수" 컬럼에서 근속 연수에 대한 숫자만 추출하기 위해 정규 표현식을 이용해서 숫자만 추출했다.
# 현재 직장 근속 연수 -> 숫자만 추출
def year_int(x):
return re.findall(r'\d+', x)[0]
df['현재 직장 근속 연수'] = df['현재 직장 근속 연수'].apply(year_int)
test['현재 직장 근속 연수'] = test['현재 직장 근속 연``수'].apply(year_int)범주형 변수 전처리
범주형 데이터에 포함되는 컬럼인 "주거 형태", "대출 목적", "대출 상환 기간"에 LabelEncoder, One-Hot Encoder 전부 적용해 본 결과 원-핫인코딩의 결과가 가장 좋아 최종적으로 pandas get_dummies 메서드를 이용해 원-핫 인코딩을 진행했다.
df = pd.get_dummies(df, columns=['주거 형태', '대출 목적', '대출 상환 기간'])
test = pd.get_dummies(test, columns=['주거 형태', '대출 목적', '대출 상환 기간'])소득/대출 변수 전처리
소득/대출 관련 변수에 log1p를 적용시켜 이상치 완화, 분포 정규화를 시켰다.
log_columns = ["현재 미상환 신용액", "월 상환 부채액", "현재 대출 잔액"]
for col in log_columns:
X[col] = np.log1p(X[col])
test[col] = np.log1p(test[col])스케일링
스케일링의 경우 StandardScaler, MinMaxScaler 전부 해본 결과 MinMaxScaler를 적용시켰다.
클래스 불균형을 보완하기 위해 SMOTE를 사용했는데 -> SMOTE를 사용하지 않아도 괜찮을 정도의 비율이였다.
X = df.drop('채무 불이행 여부', axis=1)
y = df['채무 불이행 여부']
mm = MinMaxScaler()
X = mm.fit_transform(X)
mm = MinMaxScaler()
test_scaled = mm.fit_transform(test)
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X, y)
X_train, X_test, y_train, y_test = train_test_split(X_resampled, y_resampled, test_size=0.3, random_state=42)모델 설계
사실 간단한 이진 분류 문제이기 때문에 처음에는 머신러닝을 이용해서 모델을 설계했지만 가장 높은 모델(LightGBM)의 점수가 0.57정도 밖에 되지 않아 딥러닝으로 모델을 설계했다.
모델은 3개의 은닉층을 가지고 활성화 함수는 출력층은 sigmoid 함수, 은닉층에는 leaky relu 함수를 사용했다.
조기 종료 옵션, 드롭아웃을 적용해 모델이 과적합을 방지했다.
model = keras.Sequential([
layers.Dense(128, activation='leaky_relu'),
layers.Dropout(0.3),
layers.Dense(64, activation='leaky_relu'),
layers.Dropout(0.3),
layers.Dense(32, activation='leaky_relu'),
layers.Dense(1, activation='sigmoid')
])
early_stopping = EarlyStopping(
monitor='val_loss',
patience=5,
min_delta=0.001,
restore_best_weights=True
)
model.compile(optimizer=keras.optimizers.Adam(learning_rate=0.0015),
loss='binary_crossentropy', metrics=['AUC'])
history = model.fit(X_train, y_train, epochs=100, validation_data=(X_test, y_test),
batch_size=32, callbacks=[early_stopping], verbose=1)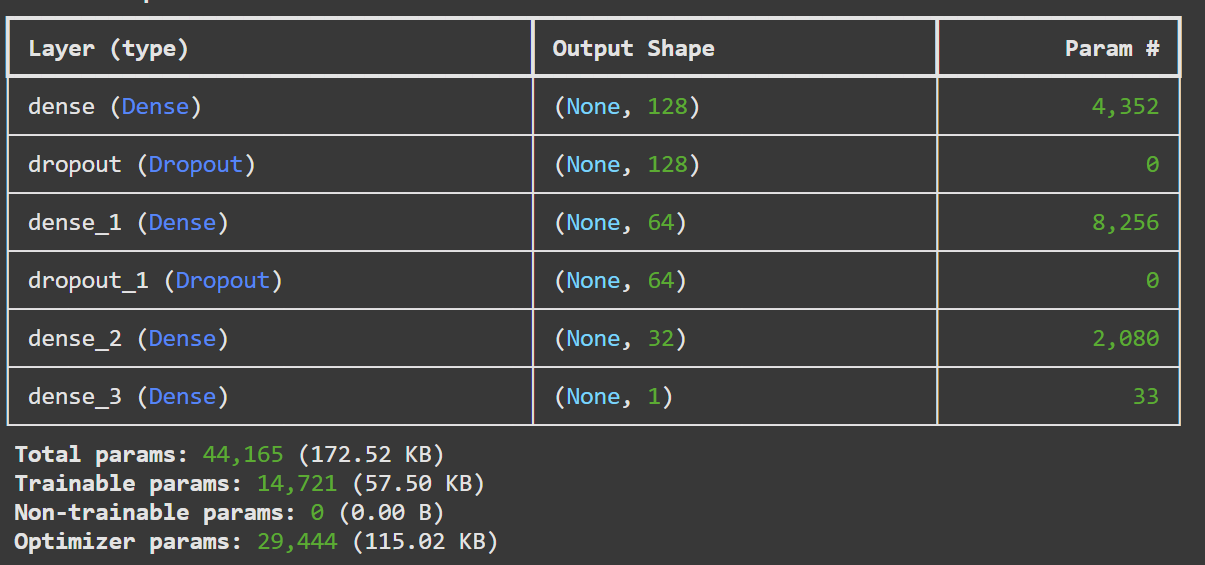
결과 변환
test_pred_prob = model.predict(test_scaled)
test_pred = (test_pred_prob >= 0.5).astype(int)
sub = pd.read_csv('sample_submission.csv')
sub['채무 불이행 확률'] = test_pred
sub.to_csv('submission.csv', index=False)데이콘 결과 상위 25%로 평가지표 ROC-AUC 점수는 약 0.6 정도 나왔다.
사실 딥러닝을 오랜만에 설계하면서 감찾는게 목표였는데 이정도면 괜찮은 것 같다.
feature engineering을 하면 더 점수가 높게 나왔을 거지만 시간이 부족해서 그렇게 까지는 하지 못했다.
