메모리 관리
메인 메모리
- 컴퓨터 시스템 운영을 담당하기 때문에 운영체제 측에서 관리할 수 있어야 한다.
- 다만 운영체제가 메인 메모리를 직접 제어하면 성능 저하가 발생한다.
- 명령어는 크게 피연산자, 연산자로 나뉘게 된다.
- 메모리 주소에 있는 그대로 데이터를 읽고 쓰기만 한다.
- CPU 클록 1 사이클 범위 이내로 레지스터에 접근할 수 있다.
- Stall 현상 (CPU 측에 필요한 데이터가 없어지는 현상) 때문에 고속 기억 장치인 캐시를 같이 사용하기도 한다.
주소 할당
- 프로그램은 대개 binary 파일로 저장이 되어 있다.
- 프로그램 실행 과정은 메모리에 적재된 이후 CPU 레지스터에 옮겨지게 되면서 진행되는 것이다.
- 프로그램의 메모리의 구성은 Stack, Heap, Data, Code 4 가지로 나뉜다.
- Stack 은 지역 변수 등 임시로 할당되는 곳에서 생성되는 공간이다.
- Heap 은 객체 인스턴스 등 동적으로 할당되는 공간이다. (C 계열은 메모리 해제를 직접 해줘야 하지만, Java 는 GC 가 자동으로 처리해준다. 그러니 이에 대한 원리를 깨달아야 할 것이다.)
- Data 는 static 변수 등 정적으로 할당되는 공간이다. 프로그램 종료 시 사라진다.
- Code 는 프로그램 동작에 필요한 명령어 및 상수 데이터 등이 저장된다.
- 운영체제에서 프로세스를 물리 메모리에 적재하는 과정은 크게 3 가지로 나뉠 수 있다.
- 컴파일 시간 바인딩 : 프로세스가 메모리 내에서 들어갈 위치를 알 수 있을 때 절대 코드를 생성하는 과정이다.
- 적재 시간 바인딩 : 메모리 내에서 어디로 올라오는지 컴파일 시점에서 판단 불가능할 시, 재배치 가능 코드를 만들어야 한다.
- 실행 시간 바인딩 : 메모리 내에서 세그먼트 이동이 발생하면 실행 시간으로 카운팅 되는 것이다.
- 메모리 측에 주소를 할당하기 위한 기법은 크게 2 가지 방법이 있다.
- 논리 주소 : CPU 가 일반적으로 생성하는 주소. (가상 주소)
- 물리 주소 : MAR (Memory Address Register) 에서 주어지는 주소.
- 프로그램 실행 중에는 MMU (Memory Management Unit) 에 의해 논리 -> 물리 주소로 바꾸는 작업을 반드시 거친다.
동적 로딩
- 프로세스 용량이 메모리보다 큰 경우에 전체를 올리지 않고 재배치 상태로 변환하여 적재 (링킹) 를 동적으로 진쟁하는 기법.
- 각 루틴 별로 필요한 라이브러리 코드가 생기는 경우에 CPU 의 호출을 통해 적재 (링킹) 시킨다.
- 운영체제 측에서는 동적 로딩 기능을 반드시 제공해야 한다.
- 동적 연결 라이브러리 (DLL, Dynamic Link Library)
- 프로그램 실행 시, 사용자 프로그램에 연동되는 라이브러리의 일종.
- 이들은 C 계열 언어에서 주로 사용되고 있다.
- 라이브러리를 각 여러 프로세스 간 공유가 가능한 것이 장점이다.
- 묵시적 링킹, 명시적 링킹 2 가지 방법으로 불러와 사용할 수 있다.
메모리 보호
- 디스페쳐 (Dispatcher)
- 재배치 레지스터, 상한 레지스터에서 가져온 주소들을 토대로 코드들을 취합하여 적재를 진행한다.
- 이 과정에서는 문맥 교환을 사용할 수 밖에 없다.
- 재배치 레지스터 : 가용 가능한 물리 주소 중에서 가장 작은 값을 저장한다.
- 상한 레지스터 : 논리 주소의 범위 값을 저장한다. 실행을 위한 논리 주소는 반드시 이 범위 이내에 존재해야 한다.
- 운영체제의 실행 중의 용량은 동적으로 변할 수 있다. (ex. 버퍼 공간 등)
메모리 할당
- 가변 파티션 : 운영체제가 사용 가능 메모리 및 사용 중인 메모리 공간을 조사해 테이블에 기록.
- 구멍 (hole) 이 사용 가능한 메모리 공간으로 크기가 다양하기 때문에 동적 메모리 할당 문제가 발생할 수 밖에 없다.
- 최초 적합 (1st-Fit) : 첫 번째로 사용 가능한 가용 공간에 할당한다.
- 최적 적합 (Best-Fit) : 사용 가능 공간 중 가장 작은 것 부터 선택을 한다.
- 최악 적합 (Worst-Fit) : 사용 가능 공간 중 가장 큰 것 부터 선택을 한다.
- 성능은 최초, 최적은 비스무리. 최악은 당연히 안 좋게 나온다.
단편화
- 외부 단편화 : 티끌 모아 결국에 티끌
- 최초 및 최적 적합은 작은 메모리 공간으로 부터 차곡차곡 쌓으면서 큰 메모리에 대해 해결 못 하는 현상이 발생한다.
- 위는 hole 공간들을 합치면 어떻게 적재는 가능한데 큰 메모리를 찢기 불가능해져서 발생하는 현상이다.
- 내부 단편화 : 선견지명의 대실패
- 운영체제가 미리 할당해 둔 공간 에 비해 작은 메모리가 들어오는 현상이다.
- 위는 hole 공간이 원래 사용하려 했던 공간 중 나머지 공간이 더 크게 나왔다고 보면 된다.
- 초기에 메모리 할당 알고리즘의 선견지명이 잘 못 된 현상이라 보면 된다.
- 단편화 현상을 해결하기 위해 압축, 페이징, 세그멘테이션 기법 등이 있다.
- 사실 압축 기법은 관리 비용이 더 들어 비효율적일 수도 있다.
페이징
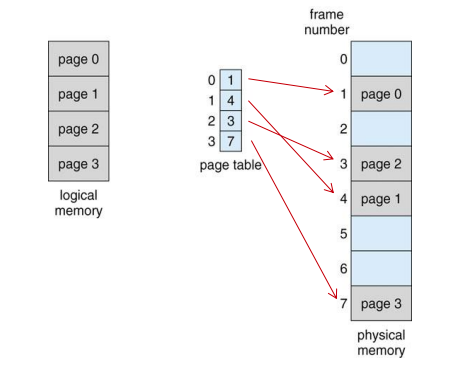
- 프로세스의 물리 주소 공간이 반드시 연속적으로 이뤄지는 보장을 깨주는 역할을 한다.
- 물리 메모리 공간에 블록 단위로 나뉜 공간은 프레임이다.
- 논리 (가상) 메모리 공간에 블록 단위로 나뉜 공간은 페이지이다.
- CPU 에서는 페이지 번호 (p), 페이지 오프셋 (d) 값을 저장하게 된다.
- 이후 MMU 를 사용하여 논리 -> 물리 주소로 바꿔준다.
- 페이징 기법은 외부 단편화 문제를 어느 정도 해결을 해 준다.
- 그렇지만 페이지 크기가 적절하지 않은 경우에도 내부 단편화는 발생할 수 밖에 없다.
- 대부분 사용하는 운영체제의 페이지 크기는 4 ~ 8 KB 이다.
- 물론 문맥 교환의 횟수는 증가할 수 있는 단점이 있지만 수행 시간을 줄일 수 있는 역할은 보장한다.
- TLB (Translation Lookaside Buffer) : 가상 메모리 주소를 물리 메모리 주소로 변환하기 위한 속도를 향상 시켜주는 캐시와 같은 역할을 한다.
- JPA 의 2차 캐시와 비슷한 원리라 보면 된다.
- 페이지 테이블의 종류는 다양하다.
- 계층적 페이징 : 2단계 페이징 기법을 사례로 페이징의 또 다른 페이징 기법. 주소 매핑 작업이 클 것이다.
- 해시 페이지 테이블 : 가상 주소를 해시로 사용하여 해시 테이블에서 가져오는 기법이다. 동적 페이징 및 주소 할당 속도가 빠를 것이다.
- 역 페이지 테이블 : 각 페이지의 크기가 무지막하게 클 수도 있다. 프로세스 ID 와 페이지 번호를 기반으로 페이징 기법을 적용한다. 다만 공유 메모리 측에서 사용하긴 힘들 것이다.
스와핑
- 프로세스 실행 시에는 명령어의 접근 메모리가 있어야 실행이 가능하다.
- 물리 주소 공간의 크기가 현저히 낮을 때 백업 물리 주소 공간을 사용하여 옮긴 뒤에 실행을 하는 기법이다.
- Swap Out : 원래 사용하던 프로세스를 백업 물리 주소 공간으로 이동 시킨다.
- Swap In : 백업 물리 주소 공간에서 사용된 프로세스를 다시 가져오는 현상이다.
- 페이징에서도 스와핑 현상을 실행할 수 있다. 페이지 내용을 백업 물리 주소 공간에 저장을 하여 실행하는 것이다.
- VMM (Virtual Memory Management) 와 유사할 수 있음. (가용 중인 디스크를 메모리로 융합하여 사용하게끔 도와주는 역할을 한다.)
- 다만 VMM 은 프로세스 단위로 Swaping 이 이뤄지지 않는 것이 다르다.

Back-End Developer