
이번 포스팅에서는 Bulk Insert를 통한 Database 성능 최적화에 대해서 알아보겠습니다.
Bulk Insert
Bulk Insert는 한번에 여러 개의 데이터를 데이터베이스에 효율적으로 저장하는 방법입니다.
일반적으로 데이터를 하나씩 삽입하는 대신, 여러 데이터를 묶어서 단일 쿼리나 최소한의 트랜잭션으로 처리해 성능을 크게 향상시킵니다.
예를 들어, 10만개의 데이터를 각각 INSERT 쿼리로 Database에 삽입하면 개수만큼 네트워크 호출과 Database 부하가 커지지만, Bulk Insert를 활용하여 이를 한 번에 처리해 시간과 자원을 졀약할 수 있습니다.
Spring에서는 Hibernate의 배치 처리 설정을 활용한 saveAll() 최적화, JdbcTemplate를 이용한 batchUpdate() 등등 여러 방법을 통해 구현할 수 있습니다.
이번 포스팅에서는
- 기존 데이터를 각각 INSERT 쿼리로 처리하는 Spring Data JPA의 saveAll() 방식
- JdbcTemplate 배치 삽입을 통한 처리 방식
- Spring Data JDBC를 활용한 방식
- SimpleJdbcInsert를 활용한 방식
4가지에 대하여 각각 처리 속도에 대한 비교를 해보겠습니다.
Spring Data JPA 활용 방식
Spring Data JPA 의존성의 JpaRepository saveAll() 메서드를 사용하여 데이터를 삽입하는 방식입니다.
1개의 엔티티당 1개의 쿼리가 생성되기 때문에 10만개의 삽입 요청이 들어올 경우 10만개의 쿼리가 나가게 됩니다.
따라서 대용량 삽입 처리에 시간 및 자원 소모에 대하여 비효율적인 방식입니다.
하지만 배치 최적화 적용이 가능합니다.
spring:
jpa:
properties:
hibernate:
jdbc:
batch_size: 1000다음과 같이 application.yml 을 설정할 경우, 각 배치당 1000개의 쿼리를 묶어 하나의 쿼리로 처리를 하게 됩니다.
따라서 10만개의 데이터 삽입 요청이 들어오게 되면, 100000 / 1000 = 100개의 배치 쿼리가 나가는 구조입니다.
또한, MySQL 설정을 rewriteBatchedStatements=true와 함께 사용 시 다중 행 INSERT로 최적화가 가능합니다.
spring:
application:
name: example
datasource:
url: jdbc:mysql://localhost:3306/example?rewriteBatchedStatements=true
username: example
password: example
driver-class-name: com.mysql.cj.jdbc.DriverJdbcTemplate 배치 삽입 방식
Spring의 JdbcTemplate을 사용해 batchUpdate 메서드로 데이터를 배치 삽입하는 방식입니다.
데이터를 받아 SQL INSERT 쿼리에 바인딩하고 배치 크기를 지정해 쿼리를 묶어 실행하는 방식입니다.
예를 들어 배치 크기를 1000개로 설정하면, 10만개의 데이터 처리 경우 100개의 배치 쿼리로 삽입 처리가 가능합니다.
배치 크기는 조절 가능하므로 처리되는 양과 시간에 따라 조절 하면 되겠습니다.
Spring Data JPA와 마찬가지로 MySQL 설정을 rewriteBatchedStatements=true와 함께 사용하여 다중 행 INSERT로 최적화가 가능합니다.
spring:
application:
name: example
datasource:
url: jdbc:mysql://localhost:3306/example?rewriteBatchedStatements=true
username: example
password: example
driver-class-name: com.mysql.cj.jdbc.DriverSpring Data JDBC 활용 방식
Spring Data JDBC를 통해 CrudRepository의 saveAll() 메서드로 데이터를 삽입하는 방식입니다.
데이터를 받아 각 엔티티에 대해 INSERT 쿼리를 실행합니다.
JPA와 달리 영속성 컨텍스트 없이 직접 DB에 반영하기 때문에 JpaRepository의 saveAll() 메서드보다 속도가 빠르다는 점이 존재합니다.
배치 삽입 최적화는 아래 설정과 DB 설정에 의존합니다.
spring:
data:
jdbc:
repositories:
enabled: true하지만 Spring Data JDBC는 배치 최적화가 부족하다는 단점이 존재합니다.
SimpleJdbcInsert 활용 방식
Spring JDBC의 SimpleJdbcInsert를 활용해 배치 삽입을 하는 방식입니다.
SimpleJdbcInsert로 테이블과 컬럼을 지정하고 엔티티 데이터를 매핑합니다.
이후 배치 크기를 설정하여 해당 크기만큼 executeBatch를 호출합니다.
예를 들어 배치 크기를 1000개로 설정하면, 10만개의 데이터 처리 경우 100개의 배치 쿼리로 삽입 처리가 가능합니다.
Spring Data JPA와 마찬가지로 MySQL 설정을 rewriteBatchedStatements=true와 함께 사용하여 다중 행 INSERT로 최적화가 가능합니다.
정리 및 비교(100,000 건 기준)
| 항목 | Spring Data JPA saveAll | JdbcTemplate batchUpdate | Spring Data JDBC saveAll | SimpleJdbcInsert executeBatch |
|---|---|---|---|---|
| 사용 기술 | JPA, Hibernate, JpaRepository | Spring JDBC, JdbcTemplate | Spring Data JDBC, Crud Repository | Spring JDBC, SimpleJdbc Insert |
| 쿼리 횟수
(배치 크
기 1000 가정) | 미적용:100,000개
적용:100개 | 100개 | 미적용 : 100,000개
적용 : 100개 | 100개|
| 메모리 사용 | 높음 | 낮음 | 중간 | 낮음 |
| 장점 | 코드가 간결 | 고성능, 간단 | 경량 ORM 사용 | 고성능 |
| 단점 | 성능 낮음 | 매핑 수동, 관계 제한 | 배치 최적화 부족 | 매핑 복잡 |
| 적합 예시 | 복잡한 엔티티, 소규모 데이터 | 대량 데이터, 고성능 | 단순 CRUD | 대량 데이터, 간소화된 매핑 |
성능 비교
간단한 프로젝트를 구현하여 성능을 비교해보겠습니다.
환경
Spring Boot 버전 3.4.5
Amazon Corretto 17.0.11
요청 테스트 Swagger 사용
Docker 환경 MySQL 8.4 사용build.gradle
dependencies {
// Spring Web
implementation 'org.springframework.boot:spring-boot-starter-web'
// Spring Data JDBC
implementation 'org.springframework.boot:spring-boot-starter-data-jdbc'
// Spring Data JPA
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
// Lombok
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
// MySQL
runtimeOnly 'com.mysql:mysql-connector-j'
// swagger
implementation 'org.springdoc:springdoc-openapi-starter-webmvc-ui:2.8.6'
// Test
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'org.springframework.batch:spring-batch-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}application.yml
spring:
application:
name: DB_Insert
datasource:
url: jdbc:mysql://localhost:3306/db-insert-mysql?rewriteBatchedStatements=true
username: test
password: test
driver-class-name: com.mysql.cj.jdbc.Driver
jpa:
hibernate:
ddl-auto: create
show-sql: false
properties:
hibernate:
dialect: org.hibernate.dialect.MySQLDialect
format_sql: true
jdbc:
batch_size: 1000docker-compose.yml
services:
db:
image: mysql:8.4
container_name: db-insert-mysql
environment:
- "MYSQL_RANDOM_ROOT_PASSWORD=1111"
- "MYSQL_DATABASE=db-insert-mysql"
- "MYSQL_USER=test"
- "MYSQL_PASSWORD=test"
ports:
- "3306:3306"
healthcheck:
test: [ "CMD-SHELL", "mysqladmin ping -h localhost -u root -p1111" ]
interval: 5s
retries: 10
restart: on-failure
Entity
import jakarta.persistence.*;
import lombok.AccessLevel;
import lombok.Getter;
import lombok.NoArgsConstructor;
@Entity
@Table(name = "users")
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
private User(String name) {
this.name = name;
}
public static User create(String name) {
return new User(name);
}
}
Controller
@RestController
@RequiredArgsConstructor
public class InsertController {
private final InsertService insertService;
@PostMapping("/springdatajpa")
public ResponseEntity<InsertResponse> saveUsingSpringDataJPA(@RequestBody InsertRequest insertRequest) {
return ResponseEntity.ok(insertService.saveUsingSpringDataJPA(insertRequest.getAmount()));
}
@PostMapping("/jdbc")
public ResponseEntity<InsertResponse> saveUsingJDBC(@RequestBody InsertRequest insertRequest) {
return ResponseEntity.ok(insertService.saveUsingJDBC(insertRequest.getAmount()));
}
@PostMapping("/simplejdbc")
public ResponseEntity<InsertResponse> simpleJdbcInsertBatch(@RequestBody InsertRequest insertRequest) throws Exception {
return ResponseEntity.ok(insertService.simpleJdbcInsertBatch(insertRequest.getAmount()));
}
@PostMapping("/springdatajdbc")
public ResponseEntity<InsertResponse> saveUsingSpringDataJDBC(@RequestBody InsertRequest insertRequest) {
return ResponseEntity.ok(insertService.saveUsingSpringDataJDBC(insertRequest.getAmount()));
}
}
Spring Data JPA
public InsertResponse saveUsingSpringDataJPA(Integer amount) {
double startTime = System.currentTimeMillis();
List<User> users = IntStream.range(0, amount).mapToObj(i -> "example" + LocalDateTime.now().getNano()).map(User::create).toList();
insertRepository.saveAll(users);
double endTime = System.currentTimeMillis();
return InsertResponse.of(amount, ((endTime - startTime) / 1000) + "초");
}Spring Data JDBC 사용
public InsertResponse saveUsingSpringDataJDBC(Integer amount) {
double startTime = System.currentTimeMillis();
List<User> users = IntStream.range(0, amount).mapToObj(i -> "example" + LocalDateTime.now().getNano()).map(User::create).toList();
springJdbcRepository.saveAll(users);
double endTime = System.currentTimeMillis();
return InsertResponse.of(amount, ((endTime - startTime) / 1000) + "초");
}Simple JDBC Insert 사용
Service
public InsertResponse saveUsingSimpleJdbcInsert(Integer amount) {
double startTime = System.currentTimeMillis();
List<User> users = IntStream.range(0, amount).mapToObj(i -> "example" + LocalDateTime.now().getNano()).map(User::create).toList();
jdbcRepository.saveUsingSimpleJDBC(users);
double endTime = System.currentTimeMillis();
return InsertResponse.of(amount, ((endTime - startTime) / 1000) + "초");
}Repository
public void saveUsingSimpleJDBC(List<User> users){
SimpleJdbcInsert simpleJdbcInsert = new SimpleJdbcInsert(jdbcTemplate)
.withTableName("users")
.usingColumns("name");
List<Map<String, Object>> batchParams = new ArrayList<>();
int batchSize = 1000;
for (User user : users) {
Map<String, Object> params = new HashMap<>();
params.put("name", user.getName());
batchParams.add(params);
if (batchParams.size() == batchSize || batchParams.size() == users.size()) {
simpleJdbcInsert.executeBatch(batchParams.toArray(new Map[0]));
batchParams.clear();
}
}
if (!batchParams.isEmpty()) {
simpleJdbcInsert.executeBatch(batchParams.toArray(new Map[0]));
}
}JdbcTemplate 사용
Service
public InsertResponse saveUsingJDBC(Integer amount) {
double startTime = System.currentTimeMillis();
List<User> users = IntStream.range(0, amount).mapToObj(i -> "example" + LocalDateTime.now().getNano()).map(User::create).toList();
jdbcRepository.saveUsingJDBC(users);
double endTime = System.currentTimeMillis();
return InsertResponse.of(amount, ((endTime - startTime) / 1000) + "초");
}Repository
public void saveUsingJDBC(List<User> users) {
String sql = """
INSERT INTO users(name)
VALUES(?)
""";
jdbcTemplate.batchUpdate(sql, users, 1000, (PreparedStatement ps, User user) -> {
ps.setString(1, user.getName());
});
}테스트 결과
10,000건 테스트
Spring Data JPA
Spring Data JDBC
SimpleJdbcInsert
JdbcTemplate
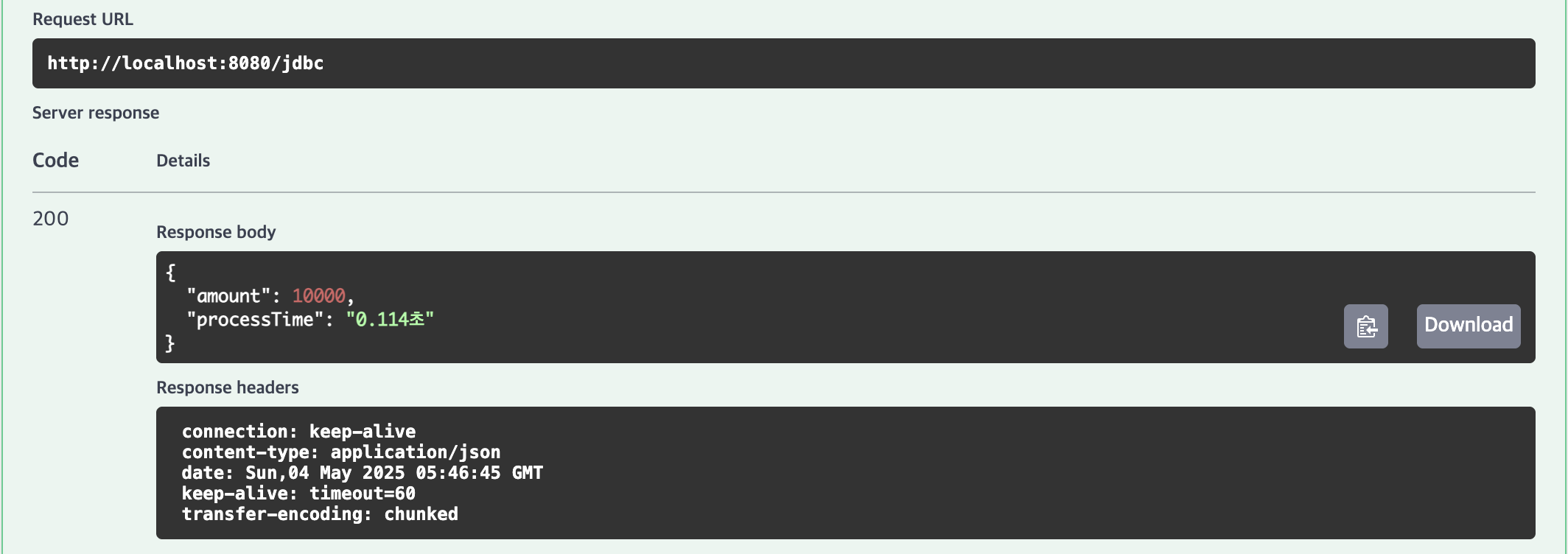
100,000건 테스트
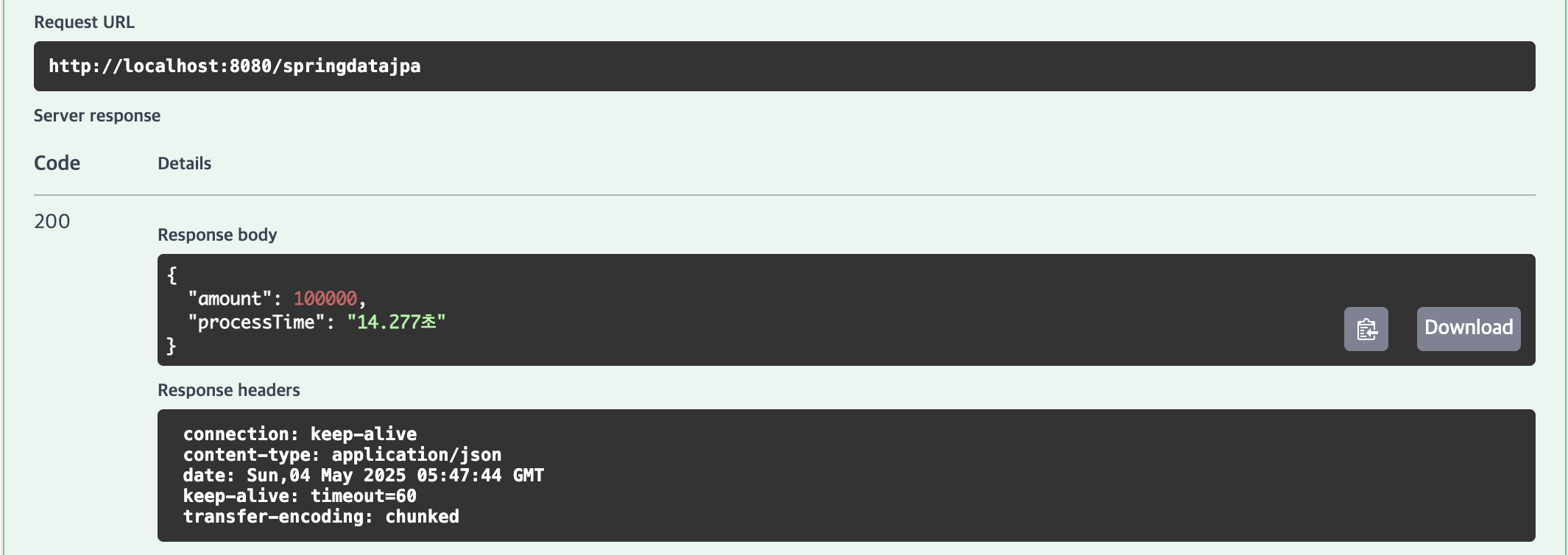
Spring Data JPA
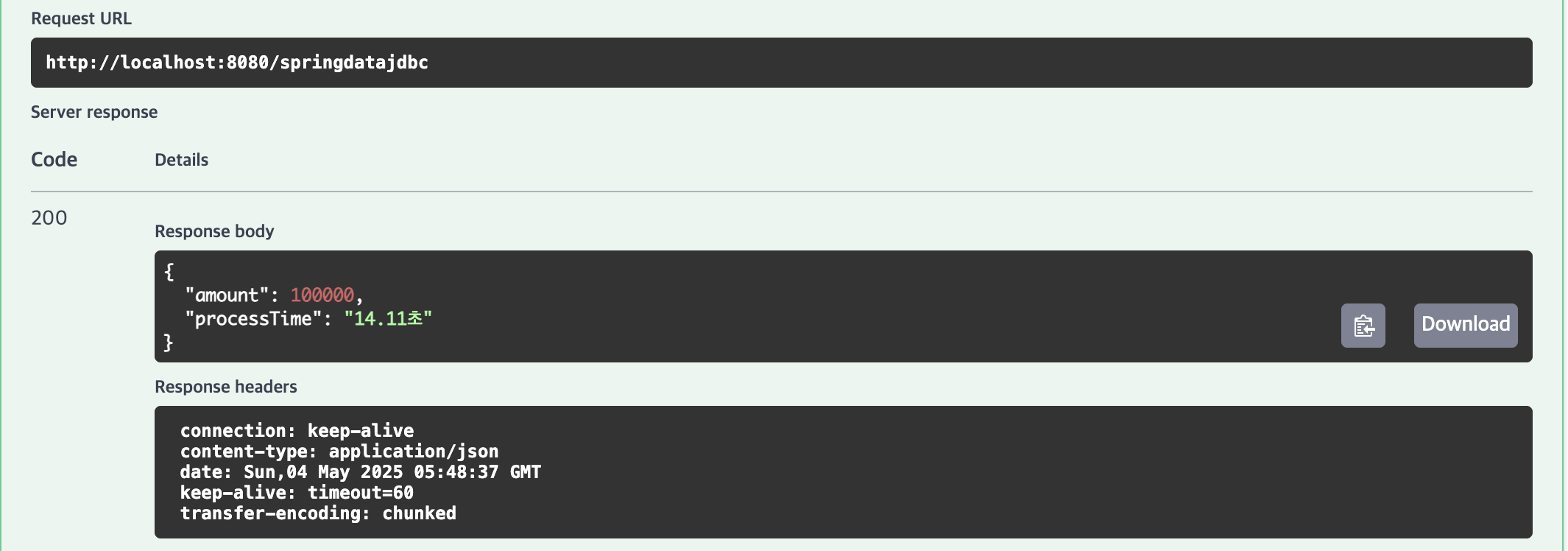
Spring Data JDBC
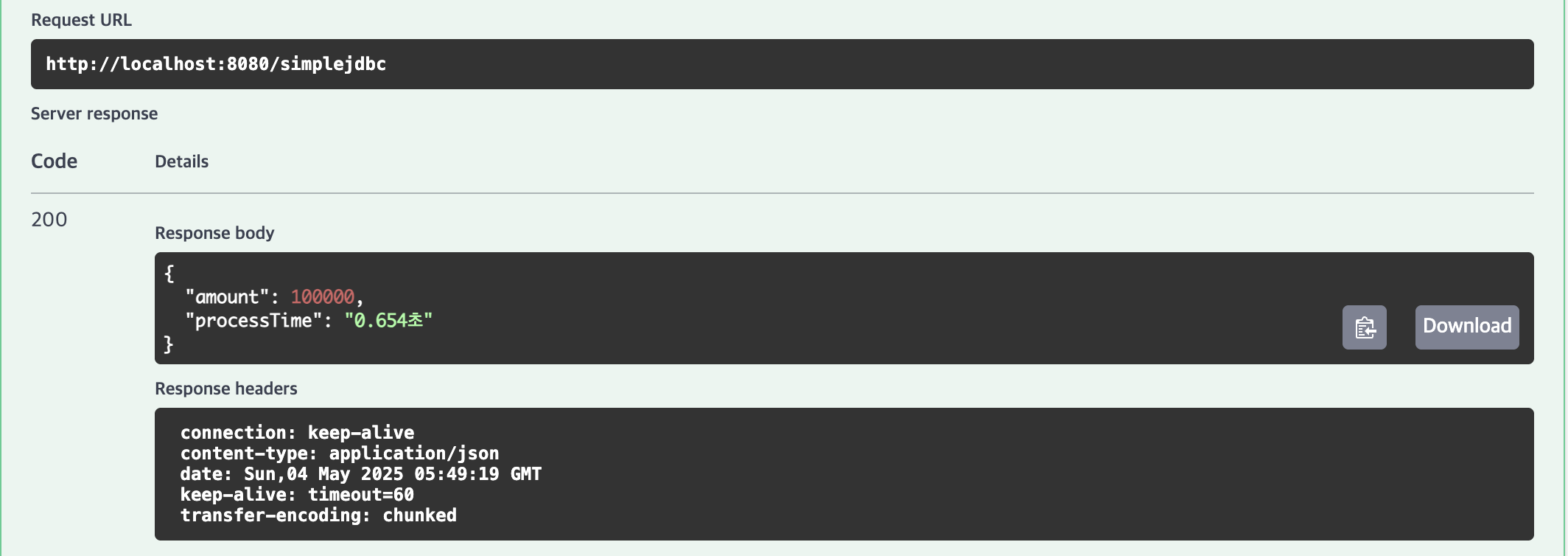
SimpleJdbcInsert
JdbcTemplate
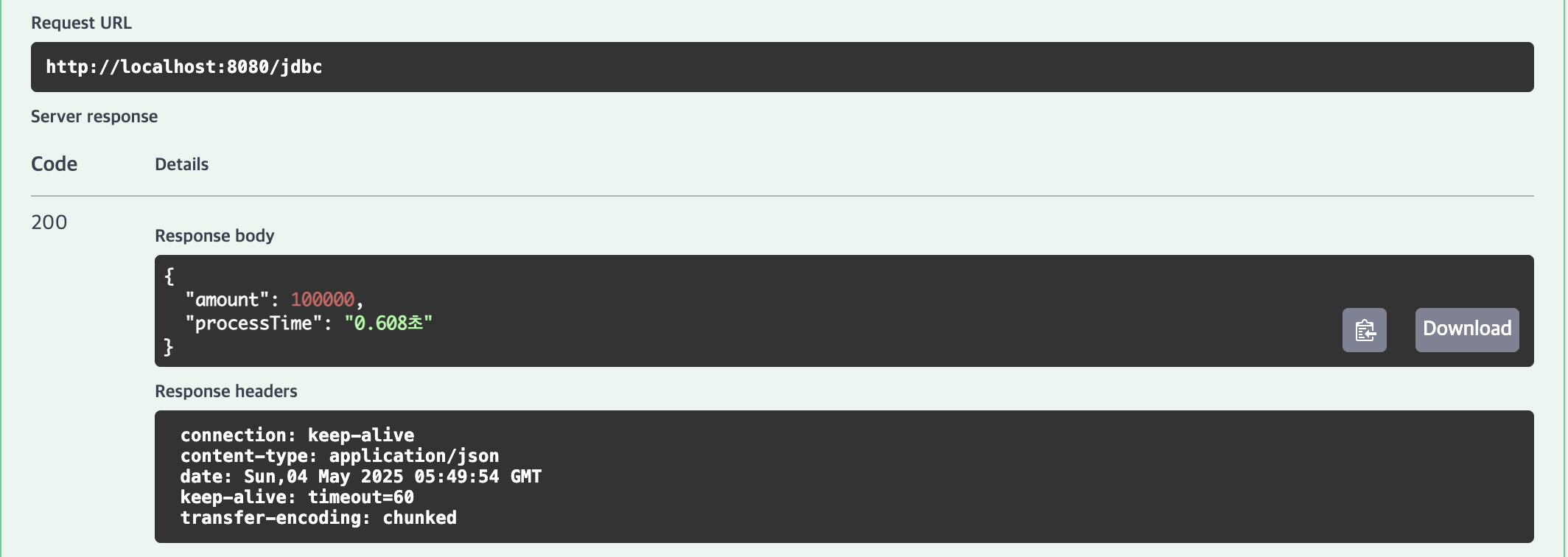
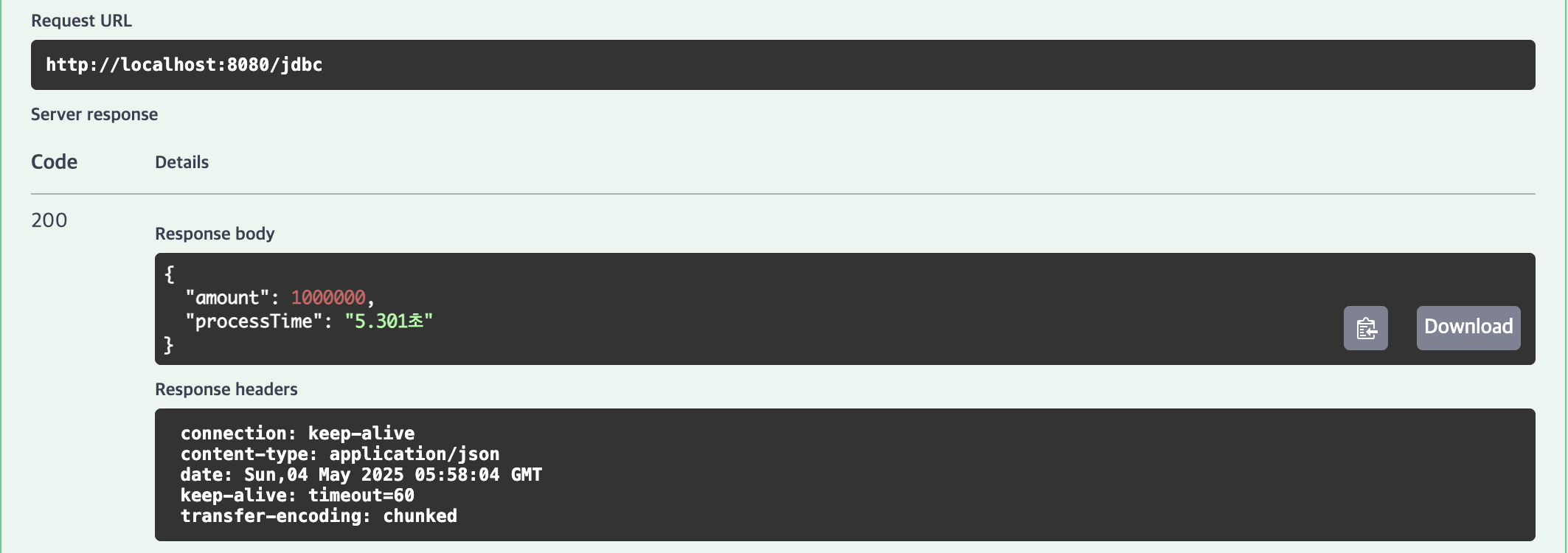
1,000,000건 테스트
Spring Data JPA
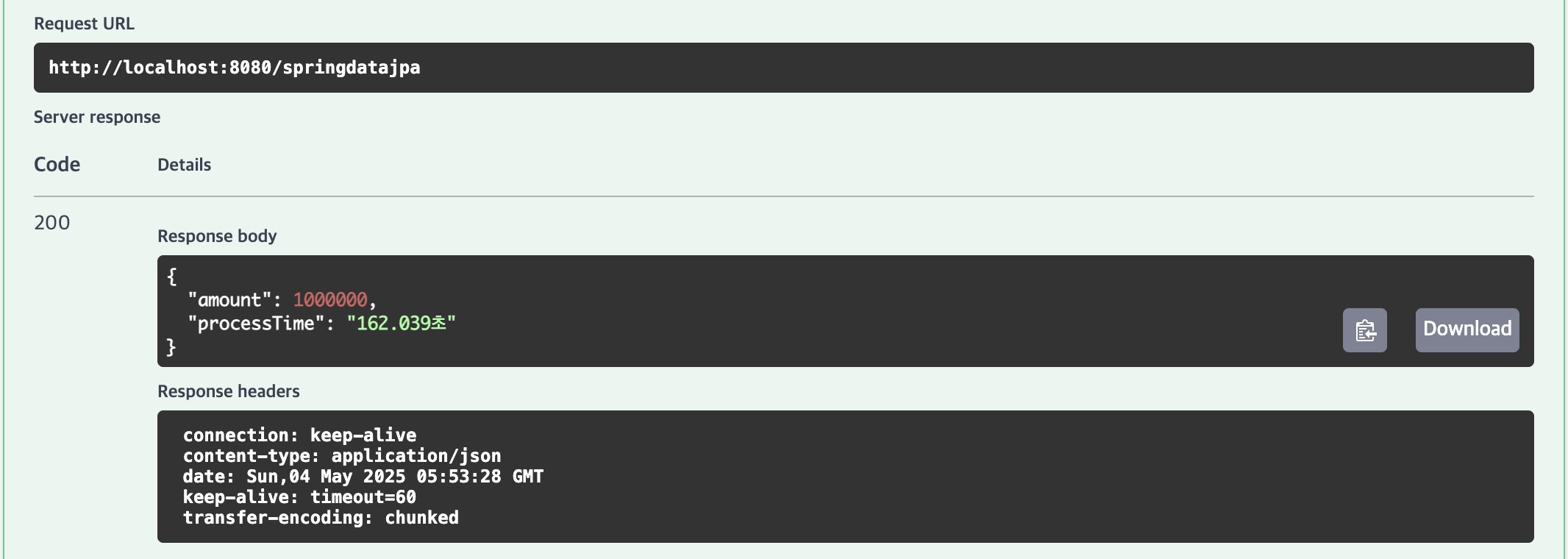
Spring Data JDBC
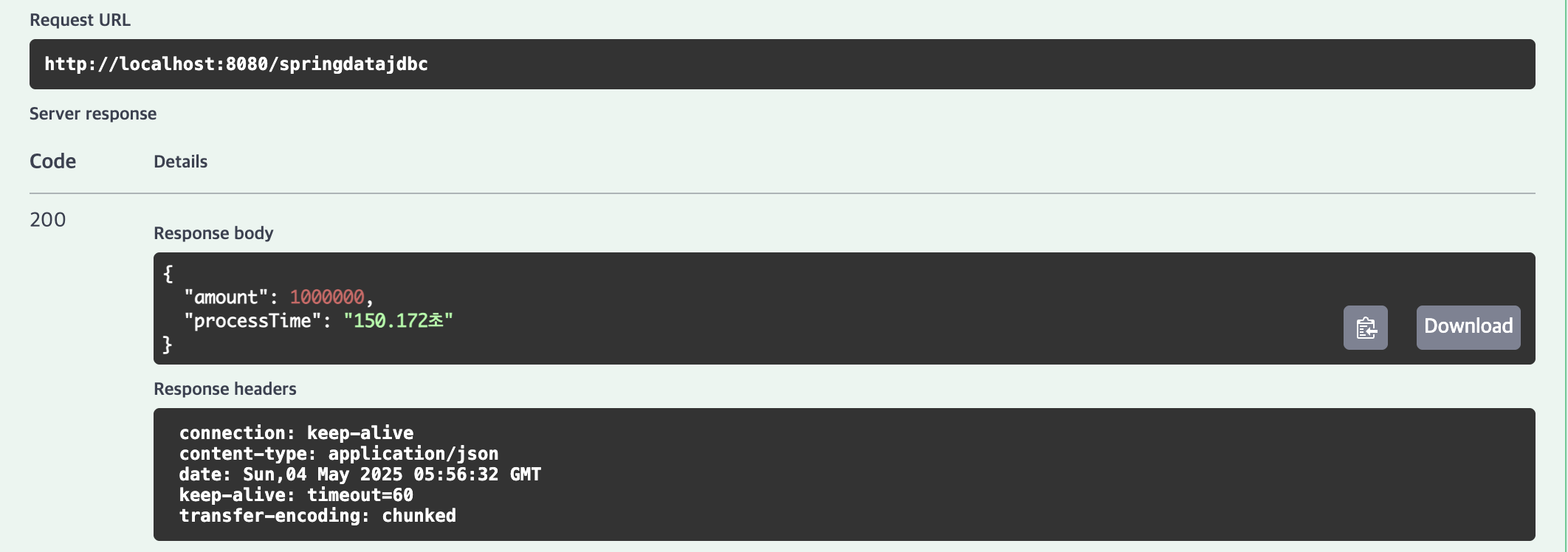
SimpleJdbcInsert
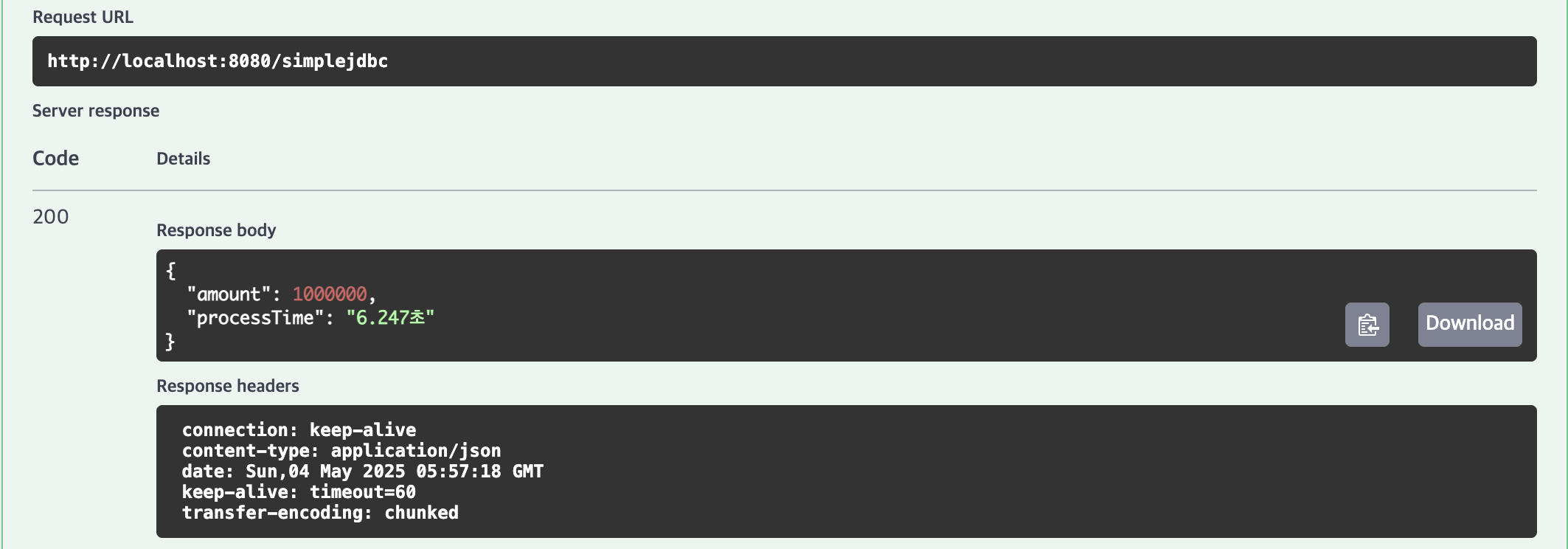
JdbcTemplate
결과
| 항목 | Spring Data JPA saveAll | Spring Data JDBC saveAll | SimpleJdbcInsert executeBatch | JdbcTemplate batchUpdate |
|---|---|---|---|---|
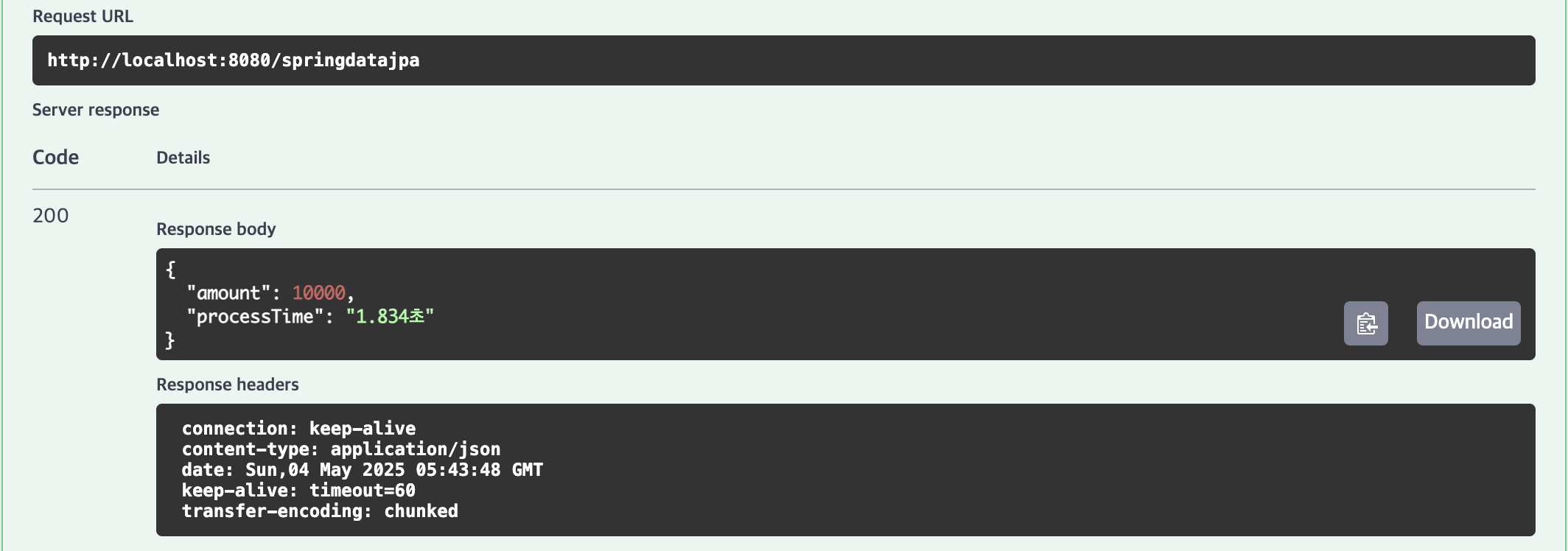
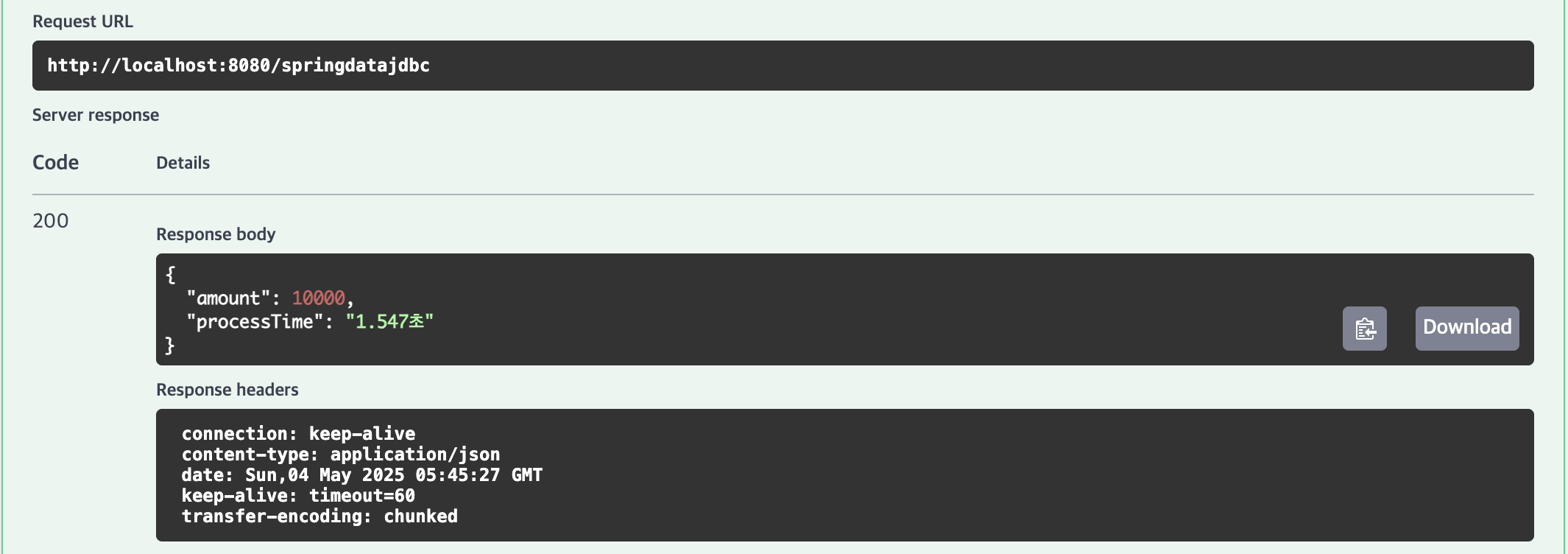
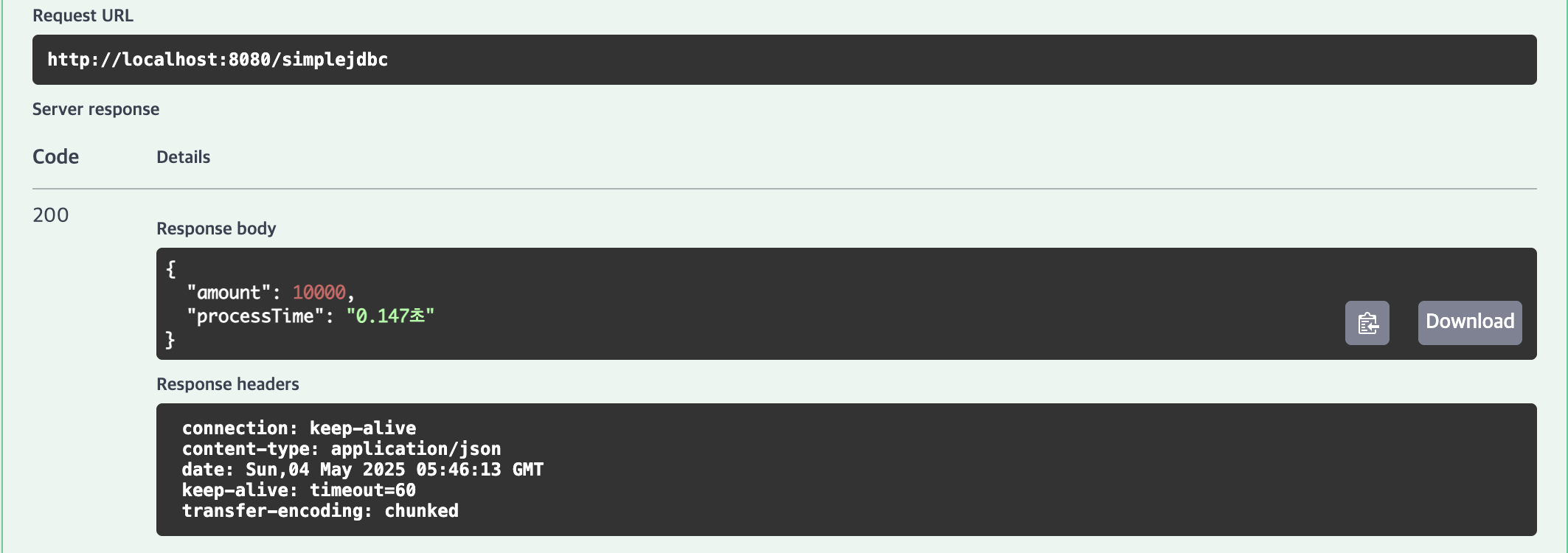
| 10,000건 | 1.834초 | 1.547초 | 0.147초 | 0.114초 |
| 100,000건 | 14.227초 | 14.11초 | 0.654초 | 0.608초 |
| 1,000,000건 | 162.039초 | 150.172초 | 6.247초 | 5.301초 |
다음과 같이
- JdbcTemplate을 사용한 방식
- SimpleJdbcInsert를 사용한 방식
- Spring Data JDBC를 사용한 방식
- Spring Data JPA를 사용한 방식
순으로 성능에 대한 결과가 나타났습니다.
결론
이번 테스트를 통해 Spring Data JPA의 saveAll, Spring Data JDBC의 saveAll, SimpleJdbcInsert의 executeBatch, JdbcTemplate의 batchUpdate 방식으로 10,000건, 100,000건, 1,000,000건의 데이터를 삽입한 성능을 비교한 결과, 다음과 같은 결론을 도출할 수 있습니다.
1위 | JdbcTemplate (batchUpdate)
10,000건(0.114초), 100,000건(0.608초), 1,000,000건(5.301초)으로 가장 빠른 성능을 기록했습니다.
O/R 매핑 없이 직접 SQL을 실행하며, rewriteBatchedStatements=true로 다중 행 INSERT를 최적화하여 대량 데이터 처리에 강점을 보였습니다.
2위 | SimpleJdbcInsert (executeBatch)
10,000건(0.147초), 100,000건(0.654초), 1,000,000건(6.247초)으로 JdbcTemplate과 유사한 고성능을 보였습니다.
Map 기반 매핑으로 코드가 약간 복잡하지만, 테이블-컬럼 매핑을 간소화하며 성능은 우수한 결과가 나타났습니다.
3위 | Spring Data JDBC (saveAll)
10,000건(1.547초), 100,000건(14.11초), 1,000,000건(150.172초)의 결과가 나타났습니다.
영속성 컨텍스트 없이 경량 ORM을 사용하지만, 배치 최적화 부족으로 대량 데이터 처리에서 성능 저하가 발생했습니다.
4위 | Spring Data JPA (saveAll)
10,000건(1.834초), 100,000건(14.227초), 1,000,000건(162.039초)의 결과가 나타났습니다.
hibernate.jdbc.batch_size=1000과 rewriteBatchedStatements=true로 최적화했으나, 영속성 컨텍스트와 O/R 매핑 오버헤드로 가장 느린 모습을 보여주었습니다.
주요 원인
JdbcTemplate과 SimpleJdbcInsert는 영속성 컨텍스트 없이 직접 SQL을 실행하고, 배치 크기(1000)로 쿼리를 묶어 네트워크 호출을 최소화하며, MySQL의 다중 행 INSERT 최적화를 활용하였기 때문에 성능이 높게나왔습니다.
Spring Data JDBC는 경량 ORM으로 JPA보다 메모리 사용이 적지만, 내부적으로 배치 처리가 미흡해 개별 쿼리 실행이 많아 성능이 저하되어 나왔습니다.
Spring Data JPA는 영속성 컨텍스트 관리와 객체-관계 매핑으로 인해 메모리와 처리 시간이 많이 소요되며, 대량 데이터 처리에 비효율적인 모습을 보였습니다.
정리
해당 포스팅에서는 Bulk Insert가 무엇인지, DB에 INSERT하는 4가지 방법에 대하여 알아보았습니다.
또한, 직접 프로젝트 예제를 구현해보고 성능 비교를 통해 결과를 도출해보았습니다.
성능 비교 결과, 대용량 데이터를 효과적으로 처리하기 위해 JdbcTemplate을 사용한 batchUpdate 방식이 사용 가능하다면 사용하는 것이 좋습니다.
관계가 복잡하더라도, 다른 방식을 사용하여 INSERT 쿼리를 처리하는 것 보다, 직접 batchUpdate 쿼리를 구현하여 처리하는 것이 최적화에 더 도움이 됩니다.
해당 프로젝트는 spring_docs의 DB_Insert에 구현해놓았으니, 로컬환경에서 직접 테스트를 원하는 분들은 참고하셔도 좋을 것 같습니다.
