
JPA를 사용하다보면 N + 1문제를 마주치는 경우가 많습니다. 이번 포스팅에서는 N + 1 문제가 무엇인지, 왜 발생하는지, 해결방법은 어떻게 되는지 정리해보는 시간을 가져보겠습니다.
N + 1 Problem?
N + 1 문제는 JPA에서 연관된 엔티티를 조회할 때 발생하는 비효율적인 쿼리 실행 패턴입니다.
하나의 쿼리로 엔티티를 조회한 뒤, 연관된 엔티티를 조회하기 위해 추가적인 쿼리가 반복적으로 실행되는 상황을 말합니다.
결과적으로 N개의 엔티티를 조회하고, 엔티티당 1개의 연관된 엔티티를 조회하는 경우 N + 1의 문제가 발생하게 되는 것입니다.
예를 들어, 학생 엔티티와 관련된 학교 엔티티를 조회할 때, 학생을 먼저 조회한 뒤 각 학생에 대해 학교를 조회하는 쿼리가 별도로 실행되면 N + 1 문제가 발생합니다.
N + 1 문제가 발생하는 이유
지연 로딩 (Lazy Loading)
N + 1 문제는 주로 지연 로딩 (Lazy Loading) 설정에서 발생합니다. JPA에서 연관관계(ex: @OneToMany , @ManyToOne 등)를 지연 로딩으로 설정하면, 연관된 엔티티는 실제로 접근할 때 조회됩니다.
해당 과정에서 각 엔티티에 대해 별도의 쿼리가 실행되며, 데이터가 많을 수록 쿼리 횟수가 증가하게 됩니다.
예제로 보는 N + 1 상황
아래는 N + 1 문제가 발생하는 예제 코드입니다.
@Entity
public class Student {
@Id
@GeneratedValue
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "school_id", nullable = false)
private School school;
}
@Entity
public class School {
@Id
@GeneratedValue
private Long id;
private String schoolName;
}
@Service
@RequiredArgsConstructor
public class StudentService {
private final StudentRepository studentRepository;
public List<Student> getStudentsWithSchool() {
List<Student> students = studentRepository.findAll();
for(Student student : students) {
// School 접근 시 매번 쿼리 실행 (N + 1 발생)
System.out.println(student.getSchool().getSchoolName())
}
}
}위 코드에서 findAll()로 Student를 조회한 뒤, 각 Student의 School을 접근할 때마다 추가 쿼리가 실행됩니다.
예를 들어, 학생이 100개라면 총 101개의 쿼리가 실행됩니다.
해결 방법
N + 1 문제를 해결하는 방법은 크게 4가지가 존재합니다.
- Fetch Join 사용
- EntityGraph 사용
- Batch Size 조절
- DTO 프로젝션을 사용한 조회
위 4가지 방법을 하나씩 알아보겠습니다.
Fetch Join
Fetch Join은 JPQL에서 연관 엔티티를 한 번의 쿼리로 함께 조회하는 방법입니다. 연관된 데이터를 즉시 로딩하여 추가 쿼리 실행을 방지하는 방법입니다.
public interface StudentRepository extends JpaRepository<Student, Long> {
@Query("SELECT stu FROM Student stu JOIN FETCH stu.school")
List<Student> findAllWithSchool();
}JOIN FETCH를 사용해 Student와 School을 하나의 SQL 쿼리로 조인하여 조회합니다.
만약 School에 Region이라는 연관관계(다중 연관관계)도 가져오고 싶다면, Region 또한 JOIN FETCH를 사용하여 한번에 조회할 수 있습니다.
주의사항
-
카테시안곱 중복 발생
카테시안 곱은 두 개 이상의 테이블을 조인할 때 발생할 수 있는 현상으로, 각각의 테이블에서 가능한 모든 조합이 생성됩니다.
예를 들어, N개의 행을 가진 테이블과 M개의 행을 가진 테이블을 조인하면 총 N * M개의 결과가 생성되어 중복된 결과가 나타날 수 있습니다.
특히,
@OneToMany같은 컬렉션 연관 매핑 필드를 Fetch Join할 때 자주 발생합니다.일반적으로 DISTINCT를 사용하면 중복된 결과를 제거할 수 있지만, Hibernate 6부터는 중복을 자동으로 처리하므로 별도로 신경 쓸 필요는 없습니다. 하지만 Hibernate 6 이전 버전을 사용하는 경우 별도로 DISTINCT를 명시하여 중복된 결과를 제거해야합니다.
-
컬렉션 2개 이상
Fetch Join을 사용할 때
@ManyToOne,@OneToOne으로 연관된 단일 필드는 여러개를 조회할 수 있지만,@ManyToMany,@OneToMany로 연관된 컬렉션 필드는 한 개만 조회할 수 있습니다. 이로 인해 두 개 이상의@OneToMany연관 매핑 필드를 동시에 Fetch Join 할 경우 MultipleBagFetchException 에러가 발생합니다.따라서 두 개 이상의 컬렉션을 사용할 경우에는 Set으로 컬렉션을 변경하여 사용해야 에러가 발생하지 않습니다.
-
페이징
Fetch Join을 사용할 때
@ManyToMany,@OneToMany로 연관된 컬렉션 필드는 페이징 API와 함께 사용할 수 없습니다.페이징 사용 시 Hibernate에서 모든 데이터를 불러온 후 메모리에서 페이징을 처리하므로, 대량 데이터에서는 메모리 사용량이 급증할 수 있습니다.
만약 BatchSize를 지정하여 페이징을 실행하거나, Fetch Join시
@ManyToOne,@OneToOne으로 연관된 단일 필드만 사용한다면 페이징과 Fetch Join을 사용할 수 있습니다.
EntityGraph
@EntityGraph는 JPA에서 연관 엔티티를 동적으로 로딩하도록 설정하는 방법입니다.
Repository 메서드에 어노테이션을 추가해 연관 데이터를 즉시 로딩하는 방법입니다.
public interface StudentRepository extends JpaRepository<Student, Long> {
@EntityGraph(attributePaths = {"school"})
List<Student> findAll();
}위의 예시처럼 JPQL 쿼리 메소드를 작성하지 않고도 하위 연관 매핑 필드를 한 번의 쿼리로 가져올 수 있어, 훨씬 간결하고 가독성이 뛰어납니다.
단, @EntityGraph는 LEFT JOIN을 기반으로 작동하기에, Fetch Join (Left)와 마찬가지로 '비어있을 수 있는' 컬렉션 연관 매핑 필드에 사용해야 합니다.
때문에 Fetch Join (Inner)보다 성능이 떨어지므로, 사용처에 맞게 신중히 선택해야 합니다.
주의사항
-
불필요한 연관 엔티티 로딩
@EntityGraph를 남용하면 필요하지 않은 연관 엔티티까지 불필요하게 메모리에 로딩될 수 있습니다.실제로 필요하지 않은 데이터까지 즉시 로딩하면 로딩되는 데이터의 양이 늘어나 오히려 성능 저하가 발생할 수 있습니다.
따라서
@EntityGraph를 사용할 때는 정확히 어떤 필드를 로딩할 것인지 신중하게 결정해야 합니다.또한
@EntityGraph는 JPA가 자동으로 최적화된 SQL을 생성하므로, 어떤 방식으로 JOIN되는지, SELECT 되는지 명확히 알기 어렵습니다.따라서 복잡한 쿼리가 필요할 경우, Fetch Join을 사용하는 것이 더 적합할 수 있습니다.
-
JPQL 쿼리와의 충돌
@EntityGraph는 기본적으로 LEFT JOIN FETCH와 같이 동작하지만, JPQL 쿼리와 함께 사용되는 경우 예상과 다른 동작을 할 가능성이 존재합니다.특히 여러개의 JOIN이나 FETCH를 사용하는 쿼리에서
@EntityGraph가 적용되지 않거나, 엔티티 간의 중복 데이터가 로딩되는 문제가 발생할 수 있습니다.따라서 JPQL 쿼리와 함꼐 사용하는 것은 지양해야 합니다.
Batch Size 조절
@BatchSize를 사용해 지연 로딩 시 한 번에 여러 엔티티를 조회하도록 설정합니다.
Hibernate가 IN 절을 사용해 여러 엔티티를 묶어서 조회하는 방법입니다.
@Entity
public class School {
@Id
@GeneratedValue
private Long id;
private String schoolName;
@OneToMany(mappedBy = "student", fetch = FetchType.LAZY)
@BatchSize(100)
private List<Student> students;
}@BatchSize 는 지정된 사이즈만큼 데이터를 한번에 조회합니다.
예를 들어, @BatchSize(10)이 지정된 경우, 10개의 데이터를 한번에 조회하여 성능 향상을 기대할 수 있습니다.
주의 사항
-
BatchSize 값 설정
BatchSize가 너무 작으면 쿼리 횟수 감소 효과가 미미할 수 있습니다.
또한 BatchSize가 너무 크면 메모리 사용량이 급증하고, DB의 IN 절 처리 부담이 증가할 수 있습니다.
따라서 데이터 크기와 DB 성능에 따라 적절한 BatchSize를 설정하여 최적하를 해야 합니다.
-
다중 연관 관계
@BatchSize는 단일 연관 관계에서는 효과적이지만, 다중 연관 관계에서는 추가 쿼리가 발생 가능합니다.중첩된 연관관계에서도
@BatchSize를 적용하여도 쿼리 수가 여전히 늘어날 수 있습니다. -
트랜잭션 범위
@BatchSize는 지연 로딩을 최적화 하지만, 연관 엔티티 로딩은 트랜잭션 내에서 발생해야 합니다.트랜잭션 외부에서 엔티티 접근시
LazyInitializationException에러가 발생 가능합니다.따라서 트랜잭션 범위를 적절히 설정해야 합니다.
DTO 프로젝션
JPQL 또는 QueryDSL을 사용하여 필요한 데이터만 선택적으로 조회합니다.
public class StudentDto {
private Long studentId;
private String schoolName;
public StudentDto(Long studentId, String schoolName) {
this.studentId = studentId;
this.schoolName = schoolName;
}
}
public interface StudentRepository extends JpaRepository<Student, Long> {
@Query("SELECT new com.example.StudentDto(stu.id, sch.schoolName) FROM Student stu JOIN FETCH stu.school sch")
List<Student> findStudentDtos();
}new 키워드로 DTO 객체를 직접 생성한 뒤 단일 쿼리로 Student와 School의 필요한 필드만 조회하는 방식입니다.
또한, 다중 JOIN이나 집계 함수도 사용이 가능하여 상황에 따라 적절히 사용할 수 있습니다.
주의 사항
-
DTO 클래스 설계
복잡한 DTO 구조의 경우 생성자 매핑이 복잡해질 수 있습니다.
따라서 DTO를 재사용 가능하도록 일반화하여 사용할 수 있습니다.
-
성능 저하
DTO는 필요한 필드만 조회하여 네트워크 부하를 감소시키지만, 잘못된 조인은 데이터 중복이나 성능 저하를 유발할 수 있습니다.
예제 프로젝트를 통한 테스트
예제 프로젝트를 만들어 N + 1 문제가 잘 해결 되는지, 성능차이는 얼마나 나는지 알아보겠습니다.
특정 학생 이름의 학생 및 학교를 조회하는 메서드를 생성하여 테스트했습니다.
학생 이름은 Student_(UUID 8글자) 로 설정했으며, Student_000을 포함하는 이름을 가진 학생을 조회했습니다.
해당 메서드는
- 기본 메서드 (N + 1 문제 발생)
- Fetch Join 사용 메서드
@EntityGraph사용 메서드- DTO 프로젝션 사용 메서드
로 나누어 구현하겠습니다.
@BatchSize는 컬렉션 필드에서 사용 가능하므로 이번 테스트에서는 제외했습니다.
환경 및 설정
프로젝트 환경
Java : 17
Gradle : 8.14.2
Spring Boot : 3.5.0
MySQL : 8.0
Docker Compose : 3.8Dependency
dependencies {
// Spring Web
implementation 'org.springframework.boot:spring-boot-starter-web'
// Spring Data JDBC
implementation 'org.springframework.boot:spring-boot-starter-data-jdbc'
// Spring Data JPA
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
// MySQL
runtimeOnly 'com.mysql:mysql-connector-j'
// Swagger
implementation 'org.springdoc:springdoc-openapi-starter-webmvc-ui:2.8.6'
// Lombok
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
// Test
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}application.yml
spring:
application:
name: N1Problem
# MySQL
datasource:
url: jdbc:mysql://localhost:3306/n1problem-mysql?rewriteBatchedStatements=true
username: test
password: test
driver-class-name: com.mysql.cj.jdbc.Driver
# JPA
jpa:
hibernate:
ddl-auto: create
show-sql: false
properties:
hibernate:
dialect: org.hibernate.dialect.MySQLDialect
format_sql: true
docker-compose.yml
version: '3.8'
services:
db:
image: mysql:8.0
container_name: n1problem-mysql
environment:
- "MYSQL_RANDOM_ROOT_PASSWORD=1111"
- "MYSQL_DATABASE=n1problem-mysql"
- "MYSQL_USER=test"
- "MYSQL_PASSWORD=test"
ports:
- "3306:3306"
healthcheck:
test: [ "CMD-SHELL", "mysqladmin ping -h localhost -u root -p1111" ]
interval: 5s
retries: 10
restart: on-failure
테스트 설정 및 구성
학생
@Entity
@Table(name = "students")
@Getter
@NoArgsConstructor
public class Student extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
@Column(nullable = false)
private Integer age;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "school_id", nullable = false)
private School school;
private Student(String name, Integer age, School school) {
this.name = name;
this.age = age;
this.school = school;
}
public static Student create(String name, Integer age, School school) {
return new Student(name, age, school);
}
}
학교
@Entity
@Table(name = "schools")
@Getter
@NoArgsConstructor
public class School extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
@Column(nullable = false)
@Enumerated(EnumType.STRING)
private Region region;
private School(String name, Region region) {
this.name = name;
this.region = region;
}
public static School create(String name, Region region) {
return new School(name, region);
}
}
default
@Query("SELECT s FROM Student s WHERE s.name LIKE '%' || :name || '%'")
List<Student> findAllByUsingDefault(@Param("name") String name);fetch join
@Query("SELECT s FROM Student s JOIN FETCH s.school WHERE s.name LIKE '%' || :name || '%'")
List<Student> findAllByAgeUsingFetchJoin(@Param("name") String name);entitygraph
@EntityGraph(
attributePaths = {"school"}
)
@Query("SELECT s FROM Student s WHERE s.name LIKE '%' || :name || '%'")
List<Student> findAllByAgeUsingEntityGraph(@Param("name") String name);dto projection
@Query("SELECT new com.example.n1problem.domain.student.dto.response.StudentWithSchoolResponse(s.id, s.name, s.age, sch.id, sch.name, sch.region) FROM Student s JOIN s.school sch WHERE s.name LIKE '%' || :name || '%'")
List<StudentWithSchoolResponse> findAllByAgeUsingDtoProjection(@Param("name") String name);테스트 결과(Swagger를 통한 테스트)
default
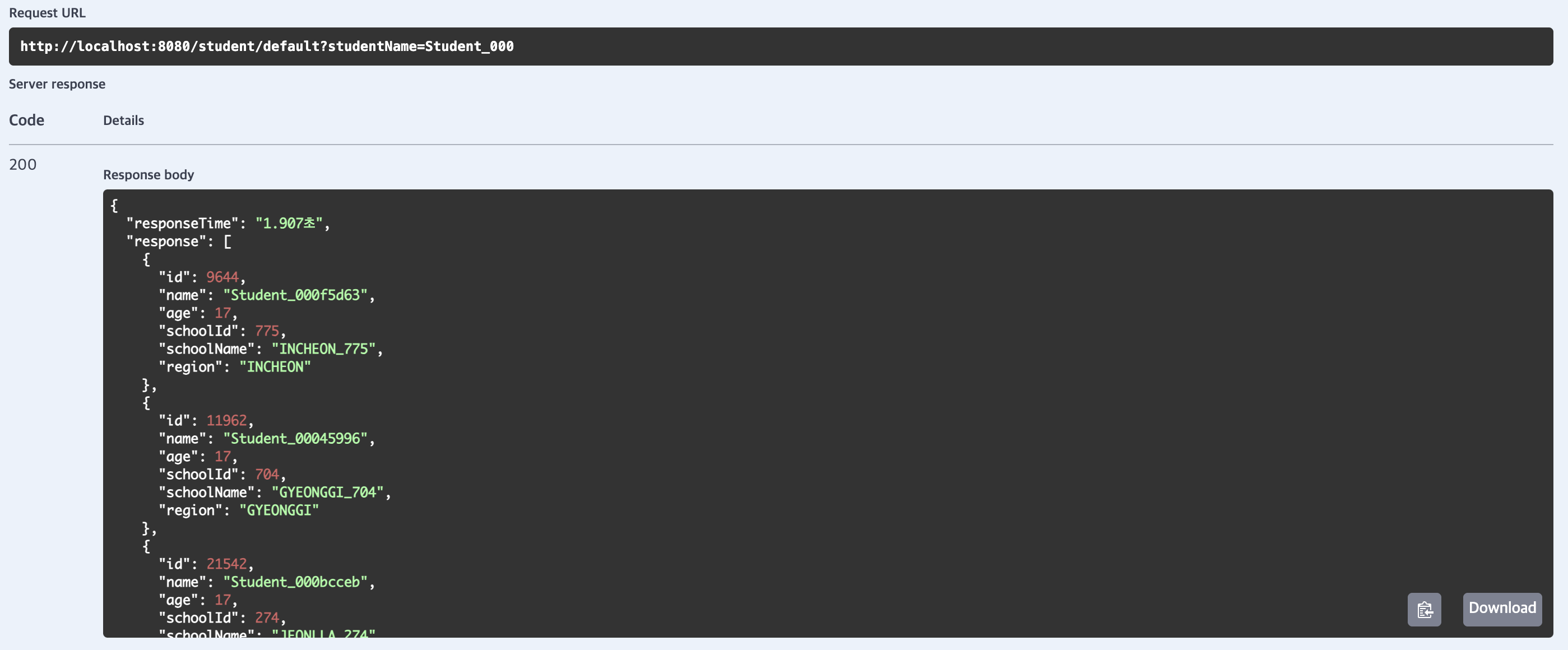
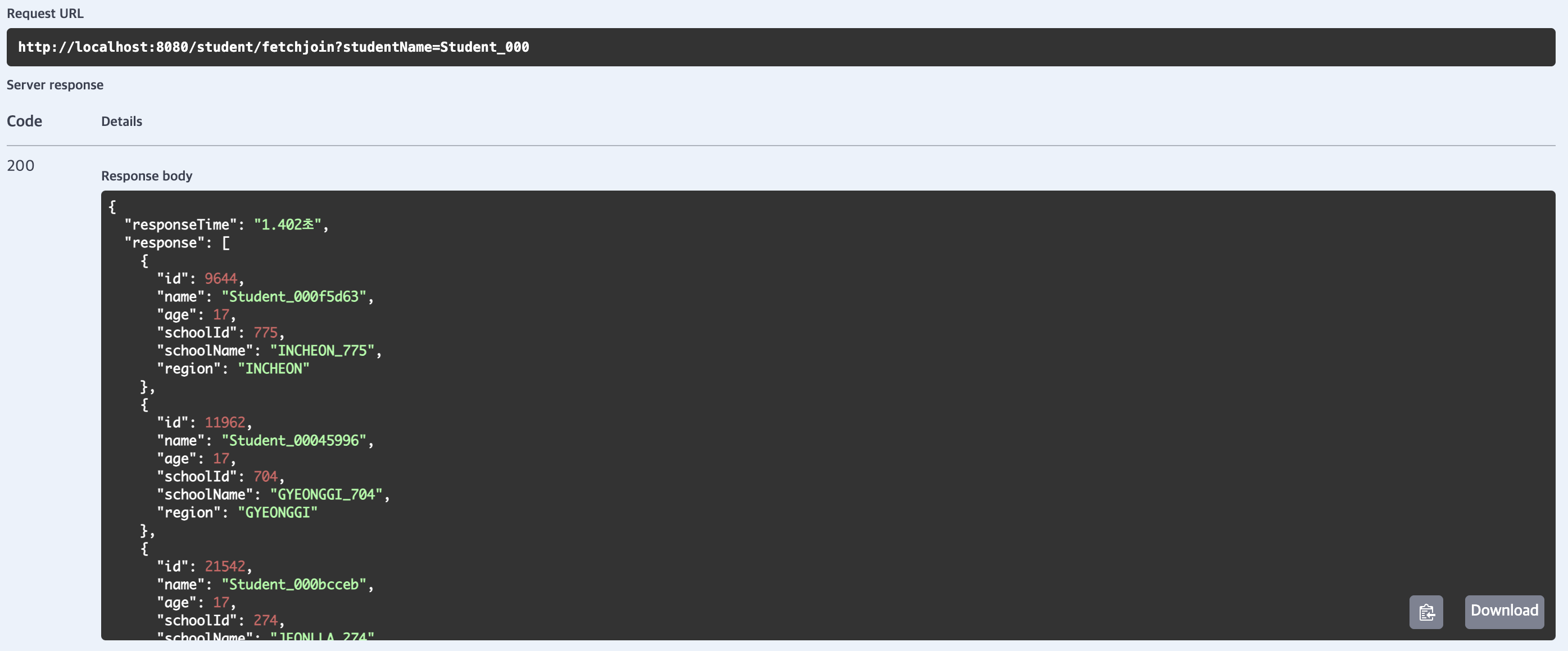
fetch join
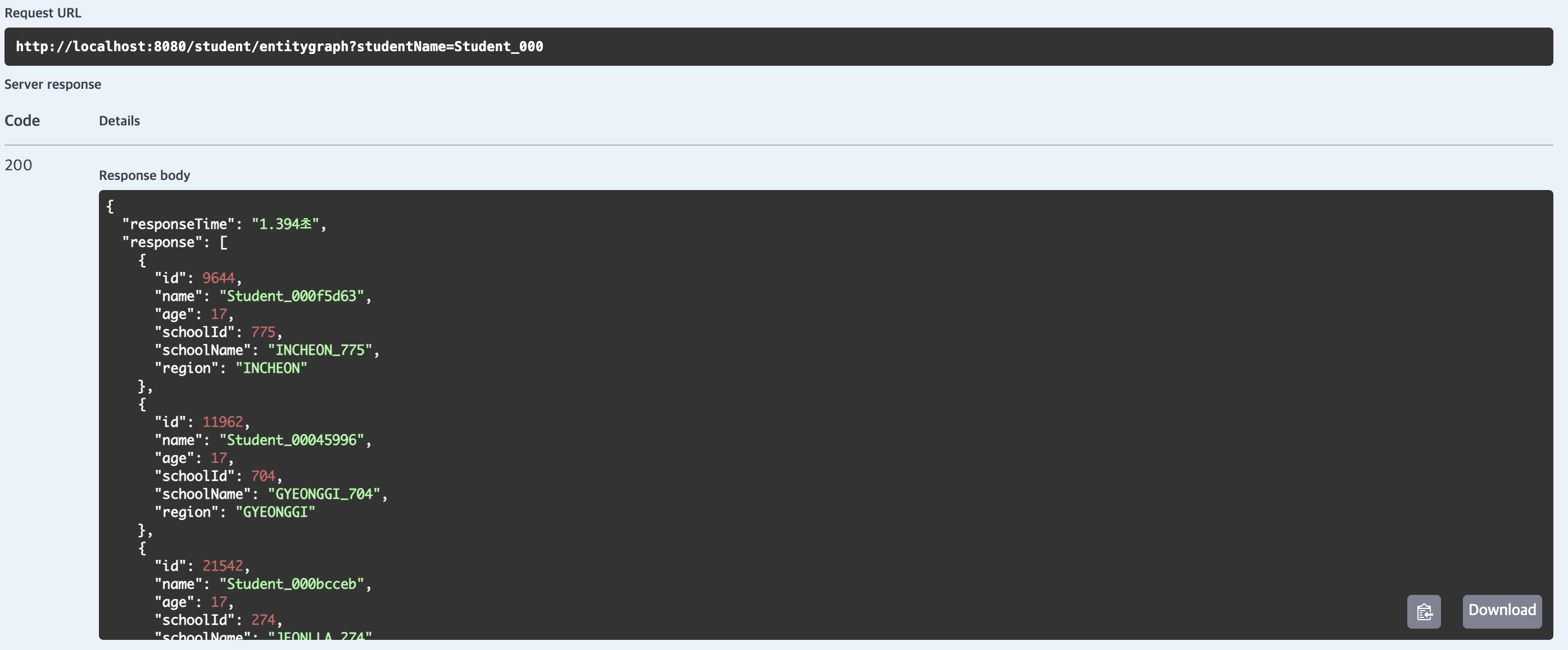
entitygraph
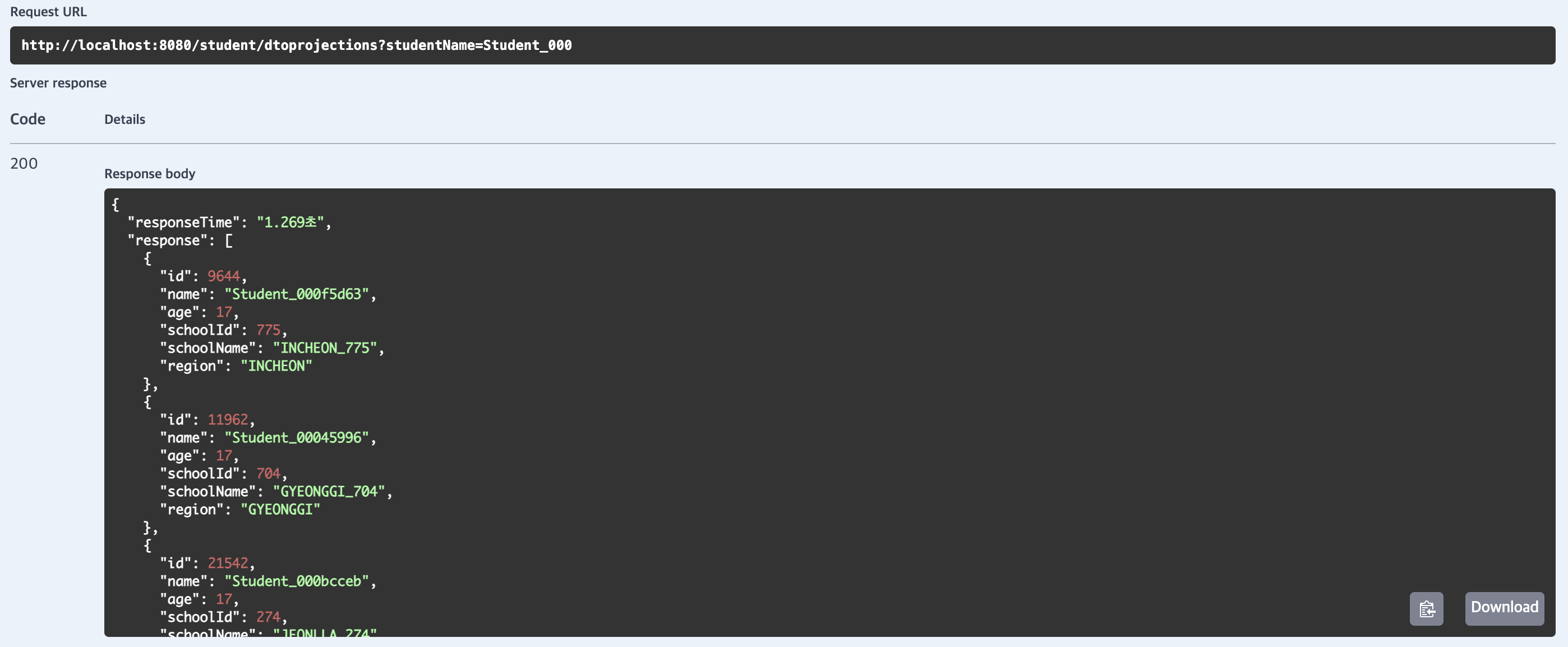
dto projection
k6를 이용한 테스트 결과
k6를 이용해 부하 테스트를 진행했습니다. 테스트는 최대 10명의 가상 사용자(VU)로 60초 동안 진행되었으며, Student_000을 포함하는 이름을 가진 학생을 조회했습니다.
import http from 'k6/http';
import { check, sleep } from 'k6';
import { Trend } from 'k6/metrics';
// Define custom metrics for each endpoint
const DefaultTrend = new Trend('default_response_time');
const FetchJoinTrend = new Trend('fetchjoin_response_time');
const EntityGraphTrend = new Trend('entitygraph_response_time');
const DtoProjectionsTrend = new Trend('dtoprojections_response_time');
// Test configuration
export const options = {
stages: [
{ duration: '10s', target: 10 },
{ duration: '40s', target: 10 },
{ duration: '10s', target: 0 },
],
thresholds: {
'default_response_time': ['avg<100000'],
'fetchjoin_response_time': ['avg<100000'],
'entitygraph_response_time': ['avg<100000'],
'dtoprojections_response_time': ['avg<100000'],
'http_req_failed': ['rate<0.01'],
},
};
const BASE_URL = 'http://localhost:8080/student';
const STUDENT_NAME = "Student_000";
export default function () {
// Test /default
let defaultRes = http.get(`${BASE_URL}/default?studentName=${STUDENT_NAME}`, {
tags: { name: 'default' },
});
check(defaultRes, {
'default status is 200': (r) => r.status === 200,
});
DefaultTrend.add(defaultRes.timings.duration);
// Test /fetchjoin
let fetchJoinRes = http.get(`${BASE_URL}/fetchjoin?studentName=${STUDENT_NAME}`, {
tags: { name: 'fetchjoin' },
});
check(fetchJoinRes, {
'fetchjoin status is 200': (r) => r.status === 200,
});
FetchJoinTrend.add(fetchJoinRes.timings.duration);
// Test /entitygraph
let entityGraphRes = http.get(`${BASE_URL}/entitygraph?studentName=${STUDENT_NAME}`, {
tags: { name: 'entitygraph' },
});
check(entityGraphRes, {
'entitygraph status is 200': (r) => r.status === 200,
});
EntityGraphTrend.add(entityGraphRes.timings.duration);
// Test /dtoprojections
let dtoProjectionsRes = http.get(`${BASE_URL}/dtoprojections?studentName=${STUDENT_NAME}`, {
tags: { name: 'dtoprojections' },
});
check(dtoProjectionsRes, {
'dtoprojections status is 200': (r) => r.status === 200,
});
DtoProjectionsTrend.add(dtoProjectionsRes.timings.duration);
sleep(1);
}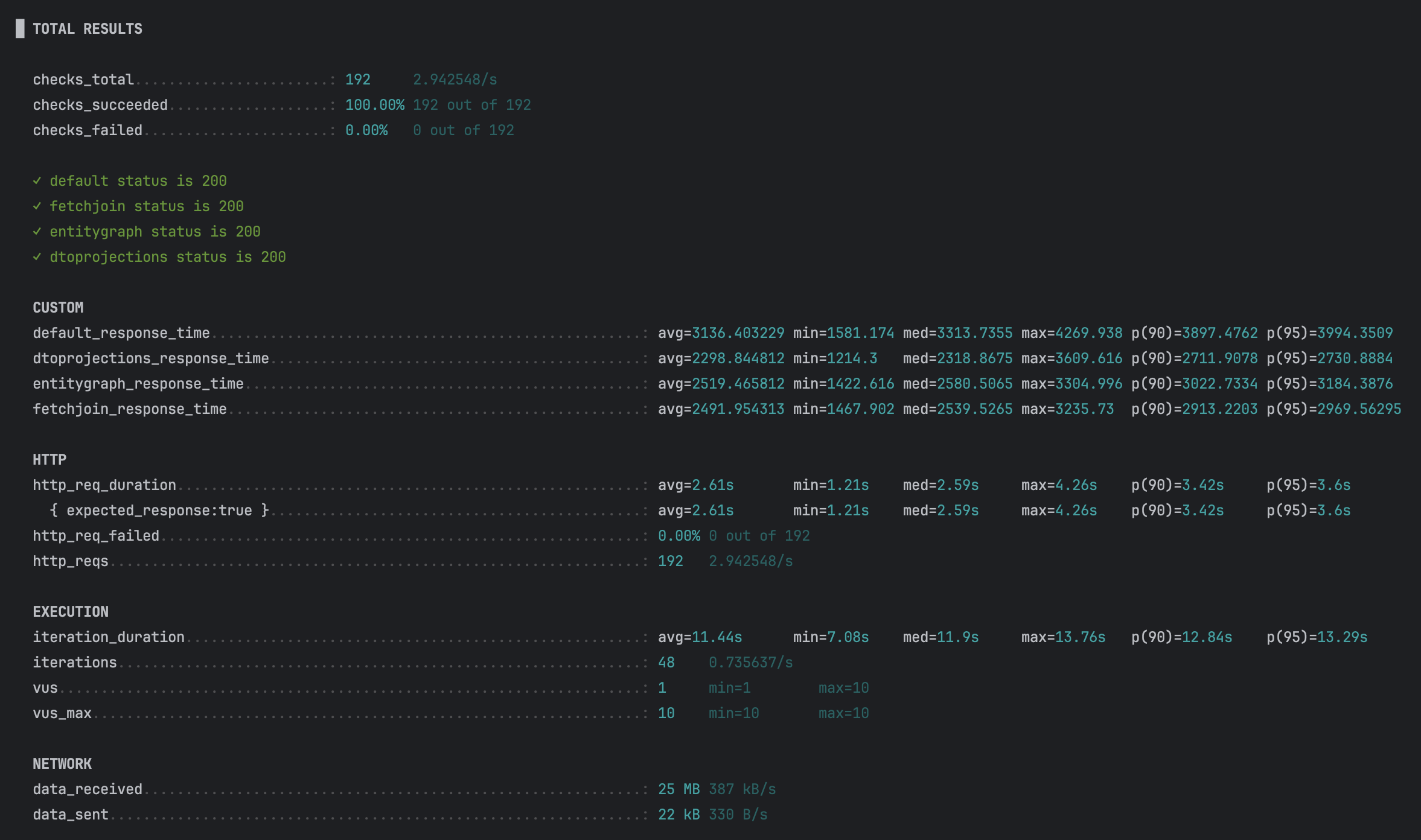
| method | Avg Response Time (ms) | Min (ms) | Max (ms) |
|---|---|---|---|
| default | 3136.4 | 1581.1 | 4269.9 |
| fetch join | 2491.9 | 1467.9 | 3235.7 |
| entitygraph | 2519.4 | 1422.6 | 3304.9 |
| dto projection | 2298.8 | 1214.3 | 3609.6 |
결과 분석
k6 테스트 결과는 각 메서드의 성능 차이를 보여주고 있습니다.
아래에서 각 메서드의 평균 응답 시간, 쿼리 실행 패턴, 데이터 크기, 테스트 환경 등을 분석하여 성능 차이의 원인을 심층적으로 살펴보겠습니다.
default method
평균 응답 시간이 3136.4ms(약 3.14초)로 가장 느렸습니다.
해당 메서드는 Student 엔티티를 조회한 후 School 엔티티를 지연 로딩으로 접근하는 구조를 가지고 있습니다.
실행되는 쿼리는 학생 데이터를 조회하는 SELECT 쿼리와 각 학생의 School 정보를 조회하는 추가 쿼리로 구성됩니다.
Student 엔티티의 School 관계가 FetchType.LAZY로 설정되어 있어, StudentWithSchoolResponse DTO 매핑 시 School 속성(name, region)에 접근할 때마다 추가 쿼리가 발생합니다.
학생들이 서로 다른 학교를 참조하면 학생 수(N)만큼 학교 쿼리가 실행될 수 있기 때문에 N + 1 문제가 발생하였고, 따라서 응답 시간이 느린 결과를 보여주었습니다.
fetch join
평균 응답 시간이 2491.9ms(약 2.49초)로 default 대비 성능이 약 26% 증가하였습니다.
해당 메서드는 단일 쿼리로 학생과 학교 데이터를 조회합니다.
실행되는 쿼리는 students와 schools 테이블을 JOIN하여 모든 필요한 데이터를 한 번에 가져옵니다.
따라서 N+1 문제를 해결하여 추가 쿼리가 발생하지 않았기 때문에 기존 방식에 비교하여 빠른 결과를 보여주었습니다.
entitygraph
평균 응답 시간이 2519.4ms(약 2.52초)로 default 대비 성능이 약 25% 증가하였습니다.
해당 메서드는 @EntityGraph를 사용해 LEFT JOIN 기반으로 단일 쿼리를 실행하며, fetch join과 유사한 쿼리를 생성합니다.
따라서 N+1 문제를 해결하여 추가 쿼리가 발생하지 않습니다.
fetch join과 성능이 거의 동일(2.49초 vs 2.52초)하며, 미세한 차이는 LEFT JOIN과 INNER JOIN의 차이에서 나타난것으로 생각 됩니다.
결과적으로 entitygraph는 fetch join과 유사한 성능을 보였고 기존 방식에 비교하여 빠른 결과를 보여주었습니다.
dto projection
평균 응답 시간이 2298.8ms(약 2.30초)로 default 대비 성능이 약 36% 증가하였고, 테스트된 메서드 중 가장 빠른 결과가 나타났습니다.
해당 메서드는 필요한 필드(id, name, age, school.id, school.name, school.region)만 조회하여 데이터 크기를 최소화하였기 때문입니다.
실행되는 쿼리는 students와 schools 테이블을 JOIN하여 단일 쿼리로 처리하였습니다.
따라서 N+1 문제를 해결하고, created_at, modified_at 같은 불필요한 필드를 제외하여 데이터 전송량을 줄여 높은 성능이 나타난 것으로 생각됩니다.
추가
추가로, 전체 응답 시간이 2.3~3.1초로 실서비스에서는 부적합한 수준으로 나왔습니다.
해당 문제는 여러 문제가 있을 수 있는데, 가장 주요한 원인으로는 LIKE '%Student_000%' 쿼리로 생각됩니다.
LIKE 쿼리는 인덱스 활용이 제한되어 풀 테이블 스캔을 유발할 가능성이 높기 때문입니다.
따라서 해당 LIKE 쿼리를 CONCAT이나 다른 대안으로 변경한다면 더욱 성능을 높일 수 있을 것이라 생각됩니다.
결론
N+1 문제는 JPA에서 연관 엔티티 조회 시 성능 저하를 유발하는 주요 원인입니다.
이번 테스트에서 default 메서드는 N+1 문제로 인해 평균 응답 시간이 3.14초로 가장 느렸으며, fetch join은 2.49초, entitygraph는 2.52초, dto projection은 2.30초로 각각 20.5%, 19.7%, 26.7% 빠른 성능을 보였습니다.
fetch join은 단일 쿼리로 N+1 문제를 해결하며 명시적 쿼리 작성으로 예측 가능하지만, 컬렉션 페이징 제한과 카테시안곱 문제가 존재합니다.
entitygraph는 코드가 간결하고 동적 로딩이 가능하나, LEFT JOIN 기반으로 약간의 오버헤드가 발생할 수 있습니다.
dto projection은 데이터 크기를 최소화하여 최고 성능을 달성했으나, DTO 설계와 유지보수 부담이 존재합니다.
batch size는 지연 로딩을 유지하며 설정이 간단하지만, 쿼리 수 감소가 제한적이고 트랜잭션 관리가 필요합니다.
실무에서는 데이터 크기가 크거나 필드의 개수가 많고 응답 시간이 중요한 경우 dto projection을 고려할 수 있을 것이라 생각합니다.
간단한 쿼리에는 fetch join 또는 entitygraph를 사용할 수 있습니다.
조회하고자 하는 엔티티의 개수가 많다면 Pageable을 사용한 페이징과 컬럼에 인덱스 추가를 하여 성능을 높일 수 있습니다.
또한 LIKE '%keyword%' 대신 keyword% 또는 풀텍스트 검색을 활용하면 쿼리 효율성을 높일 수 있을 것이라 생각합니다.
해당 프로젝트는 N + 1 Problem에 정리해 두었으니, 참고하셔도 좋을 것 같습니다.
