
현대 애플리케이션에서는 수십, 수백, 수천만 건의 데이터를 빠르게 효율적으로 조회해야 하는 경우가 빈번합니다.
하지만 대용량 데이터 조회는 느린 응답 시간과 서버 부하로 이어질 수 있어, 성능 최적화가 필수적입니다.
이번 포스팅에서는 Spring Boot에서 대용량 데이터 조회 속도를 높이는 방법에 대해 알아보고, 예제 프로젝트를 통해 얼마나 성능이 향상 되는지 테스트 해보는 시간을 가지겠습니다.
대용량 데이터란?
대용량 데이터란 수십만, 수백만, 수천만 건 이상의 레코드를 다루는 상황을 의미합니다.
사용자 로그, 거래 기록 등 처리가 빈번하게 일어나는 데이터의 경우 대용량 데이터로 발전할 가능성이 매우 높습니다.
Spring Boot 애플리케이션에서 이런 데이터를 조회할 때, 느린 응답 시간이나 메모리 부족 같은 성능 병목이 발생하기 쉽습니다.
따라서 데이터베이스와 애플리케이션 수준에서의 최적화는 필수적이라 할 수 있습니다.
최적화 방법
Indexing
인덱싱은 데이터베이스 조회 성능을 향상시키는 가장 기본적인 방법입니다.
안덱스는 테이블의 특정 컬럼에 대해 B-Tree 또는 Hash 구조를 생성해 데이터를 빠르게 검색할 수 있도록 합니다.
예를 들어, 사용자 이름이나 주문 날짜로 자주 조회하는 경우 해당 컬럼에 인덱스를 추가하여 성능 향상이 가능합니다.
Spring Boot에서는 JPA의 @Table 어노테이션을 통해 인덱스를 쉽게 정의할 수 있습니다.
특히, WHERE, JOIN, ORDER BY 조건이 자주 사용되는 컬럼에 인덱스를 추가하면 효과적입니다.
하지만 인ㄷ게스는 저장 공간과 쓰기 성능에 영향을 줄 수 있으므로, 적절한 설계가 중요합니다.
장단점은 다음과 같습니다.
| 장점 | 단점 |
|---|---|
| 쿼리 실행 속도 향상 가능 | 인덱스 생성 및 유지로 인해 쓰기 성능 저하 발생 가능 |
| 설정이 간단함 | 저장 공간 추가 사용 |
| 잘못된 인덱스 설계 시 오히려 성능 저하가 발생 |
적용 예시
자주 조회되는 name 컬럼에 인덱스를 추가
@Entity
@Table(indexs = @Index(name = "idx_name", columnList = "name")
public class User{
@Id
@GeneratedValue(strategy = GenerationType.IDENTIFY)
private Long id;
private String name;
}주의할 점
- 인덱스는 읽기 비율이 높은 경우에만 적용하는 것이 좋습니다.
- 쓰기 비율이 높은 경우 인덱스까지 업데이트를 해주어야하기 때문에, 오히려 성능 저하가 발생할 수 있기 때문입니다.
쿼리 최적화
쿼리 최적화는 데이터베이스에서 필요한 데이터만 효율적으로 가져오도록 쿼리를 작성하는 방법입니다.
대용량 데이터 조회 시 불필요한 컬럼이나 전체 데이터를 로드하면 메모리와 네트워크 부하가 증가하므로, 최적화된 쿼리를 작성하여 성능 향상이 가능합니다.
Spring Data JPA에서는 @Query를 사용해 특정 컬럼만 조회하거나, Pageable을 활용해 데이터를 분할 처리할 수 있습니다.
예를 들어, 사용자 목록을 조회할 때 모든 컬럼 대신 ID와 이름만 가져오게 최적화가 가능하고, 페이징을 적용해 한 번에 10건만 조회하여 성능 최적화가 가능합니다.
장단점은 다음과 같습니다.
| 장점 | 단점 |
|---|---|
| 메모리와 네트워크 부하를 줄여 시스템 성능 향상 | 최적화된 쿼리 작성을 위해 데이터베이스 구조에 대한 이해 필요 |
| 코드 수정만으로 즉시 적용 가능 | 잘못된 쿼리 설계 시 오히려 성능 저하가 발생 |
| 복잡한 쿼리에서도 유연하게 적용 가능 | 복잡한 DTO 프로젝션은 코드 유지보수를 어렵게 할 수 있음 |
필요한 컬럼만 조회
SELECT *은 모든 컬럼을 가져와 리소스를 낭비할 수 있습니다. 따라서 필요한 컬럼을 지정하여 가져와 최적화가 가능합니다.
적용 예시
@Query("SELECT new com.example.UserNameDto(u.id, u.name) FROM User u WHERE u.name = :name")
List<UserNameDto> findByName(String name);페이징 처리
대량의 데이터를 한 번에 조회하면 응답 지연 및 리소스 부하가 큽니다.
따라서 Pageable을 통하여 페이징 처리를 하여 최적화가 가능합니다.
적용 예시
public interface UserRepository extends JPARepository<User, Long> {
Page<User> findAll(Pageable pageable);
}@Service
@RequiredArgsConstructor
public class UserService {
private final UserRepository userRepository;
public Page<User> getUsers(Pageable pageable) {
return userRepository.findAll(pageable);
}
}@RestController
@RequiredArgsConstructor
public class UserController {
private final UserService userService;
@GetMapping("/users")
public Page<User> getUsers(@PageableDefault(size = 10) Pageable pageable) {
return userService.getUsers(pageable);
}
}배치 조회
배치 조회는 대량 데이터를 한 번에 가져오거나 연관 데이터를 효율적으로 조회하여 N+1문제를 해결하는 방법입니다.
N+1문제는 엔티티와 연관 데이터를 개별적으로 조회할 때 발생하는 반복 쿼리로, 대용량 데이터 환경에서 성능 저하를 초래할 수 있습니다.
Spring Data JPA에서는 IN 쿼리를 사용해 여러 ID를 묶어 조회하거나, JOIN FETCH을 사용해 연관 데이터를 한번에 가져와 불필요한 반복 쿼리를 줄여 최적화가 가능합니다.
예를 들어, 사용자의 주문 내역을 조회할 때 개별 쿼리 대신 배치 조회 쿼리를 적용하면 쿼리 실행 횟수가 줄어 응답 시간이 단축되어 성능 최적화가 가능합니다.
장단점은 다음과 같습니다.
| 장점 | 단점 |
|---|---|
| N + 1 문제 해결로 쿼리 실행 횟수 감소 | JOIN FETCH 사용 시 반환 데이터 크기가 커질 수 있음 |
| 복잡한 연관 관계 데이터 조회에 유용 | 잘못된 배치 크기 설정은 오히려 리소스 부하를 발생 |
| JPA와 통합되어 코드 구현이 간단함 | 쿼리 복잡도가 높아질 경우 유지보수가 어려움 |
적용 예시
IN절을 통해 여러 ID를 한 번에 조회
public interface UserRepository extends JPARepository<User, Long> {
List<User> findByIdIn(List<Long> ids);
}JOIN FETCH로 연관 데이터를 함께 조회
public interface UserRepository extends JPARepository<User, Long> {
@Query("SELECT u FROM User u JOIN FETCH u.orders WHERE u.name = :name")
List<User> findWithOrdersByName(String name);
}주의할 점
JOIN FETCH의 경우 연관된 엔티티의 전체 데이터를 가져오므로, 리소스가 커질 수 있음.
캐싱 활용
캐싱은 자주 조회되는 데이터를 메모리에 저장하여 데이터베이스 부하를 줄이는 방법입니다.
대용량 데이터 환경에서 동일한 조회 요청이 반복될 때, 캐싱을 통해 응답 시간을 줄여 성능 최적화가 가능합니다.
Spring Boot에서는 Redis 같은 외부 캐시 저장소를 사용하거나, Spring Cache의 @Cacheable을 통해 인메모리 캐싱(Caffeine)을 사용할 수 있습니다.
예를 들어, 사용자 프로필 데이터를 캐싱하면 매번 데이터베이스를 조회하지 않고 즉시 결과를 반환할 수 있습니다.
해당 포스팅에서는 Redis를 활용한 분산 캐싱과 Spring Cache를 통한 간단한 캐싱에 대해 알아보겠습니다.
장단점은 다음과 같습니다.
| 장점 | 단점 |
|---|---|
| 반복 조회 성능 향상 가능 | 캐시 일관성 유지를 위한 추가 로직이 필요 |
| 데이터베이스 부하 감소 | 메모리 사용량 증가 |
| Spring과의 높은 통합성 | Redis 같은 외부 캐시 시스템은 추가 설정 및 비용 발생 |
Redis
Redis를 사용하여 캐싱 활용이 가능합니다.
적용 예시
설정
spring:
cache:
type: redis
redis:
host: localhost
port: 6379@Service
@RequiredArgsConstructor
public class UserService{
private final UserRepository userRepository;
@Cacheable(value = "users", key = "#name")
public User findByName(String name){
return userRepository.findByName(name);
}
}Spring Cache
Redis를 사용하지 않고 인메모리 캐시인 Caffeine을 사용하는 방법입니다.
적용 예시
spring:
cache:
type: caffeine@Service
@RequiredArgsConstructor
public class UserService{
private final UserRepository userRepository;
@Cacheable(value = "users", key = "#name")
public User findByName(String name){
return userRepository.findByName(name);
}
}주의할 점
- 데이터 쓰기 빈도가 높을 경우, 캐시 일관성 관리가 필요합니다.
비동기 처리
비동기 처리는 데이터 조회 작업을 백그라운드 쓰레드에서 실행하여 클라이언트 응답 시간을 단축하고, 서버 부하를 분산시키는 방법입니다.
대용량 데이터 조회는 시간이 오래 걸릴 수 있으므로, 비동기 처리를 통해 사용자가 즉시 응답을 받고 백그라운드에서 데이터를 처리할 수 있습니다.
Spring Boot에서는 @Async 어노테이션과 CompletedFuture를 활용해 비동기 로직을 구현할 수 있습니다.
예를 들어, 대규모 사용자 목록을 조회할 때 비동기 호출을 사용하면 클라이언트는 즉시 응답을 받고, 서버는 별도로 데이터를 준비합니다.
장단점은 다음과 같습니다.
| 장점 | 단점 |
|---|---|
| 클라이언트 응답 시간을 대폭 단축 | 비동기 코드의 복잡성이 증가 |
| 서버 리소스를 효율적으로 활용 | 스레드 풀 설정 미흡할 경우 성능 저하 |
| 대규모 조회 작업에 적합 | 비동기 결과 처리 로직 추가 필요 |
적용 예시
@SpringBootApplication
@EnableAsync
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}또는 Config 추가 파일 생성 및 적용
@EnableAsync
@Configuration
public class AsyncConfig {
}@Service
@RequiredArgsConstructor
public class UserService{
private final UserRepository userRepository;
@Async
public CompletableFuture<List<User>> findAllAsync() {
try{
return CompatableFuture.completedFuture(userRepository.findAll());
} catch(Exception e){
throw new Exception();
}
}
}@RestController
@RequiredArgsConstructor
public class UserController{
private final UserService userService;
@GetMapping("/users/async")
public CompletableFuture<List<User>> getUsersAsync() {
return userService.findAllAsync();
}
}주의할 점
- 스레드 풀 크기를 적절히 설정해주어야 합니다.
- 예외 처리를 적절히 해주어야 합니다.
예제 프로젝트로 성능 테스트 해보기
해당 포스팅에서 소개한 최적화 기법들을 테스트할 Spring Boot 프로젝트를 구성해보고. 테스트 결과를 알아보겠습니다.
환경 및 설정
프로젝트 환경
Java : 17
Gradle : 8.3
Spring Boot : 3.4.5
MySQL : 8.0
Redis : 7.0Dependency
dependencies {
// Spring Data JPA
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
// Spring Web
implementation 'org.springframework.boot:spring-boot-starter-web'
// Spring Cache
implementation 'org.springframework.boot:spring-boot-starter-cache'
// Spring Data Redis
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
// Caffeine Cache
implementation 'com.github.ben-manes.caffeine:caffeine:3.1.8'
// MySQL
runtimeOnly 'com.mysql:mysql-connector-j'
// Lombok
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
// Swagger
implementation 'org.springdoc:springdoc-openapi-starter-webmvc-ui:2.8.6'
// Jackson DataType
implementation 'com.fasterxml.jackson.datatype:jackson-datatype-jsr310'
// Test
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}application.yml
spring:
application:
name: DB_Search
#MySQL
datasource:
url: jdbc:mysql://localhost:3306/db-search-mysql?rewriteBatchedStatements=true
username: test
password: test
driver-class-name: com.mysql.cj.jdbc.Driver
hikari:
maximum-pool-size: 100
minimum-idle: 10
#JPA
jpa:
hibernate:
ddl-auto: update
show-sql: true
properties:
hibernate:
dialect: org.hibernate.dialect.MySQLDialect
format_sql: true
#Redis
data:
redis:
host: localhost
port: 6379
#Cache
cache:
type: redis
cache-names:
- redis-users
- caffeine-users
#Async
task:
execution:
pool:
max-size: 10
core-size: 5
springdoc:
swagger-ui:
tags-sorter: alphadocker-compose.yml
services:
db:
image: mysql:8.0
container_name: db-search-mysql
environment:
- "MYSQL_RANDOM_ROOT_PASSWORD=1111"
- "MYSQL_DATABASE=db-search-mysql"
- "MYSQL_USER=test"
- "MYSQL_PASSWORD=test"
ports:
- "3306:3306"
healthcheck:
test: [ "CMD-SHELL", "mysqladmin ping -h localhost -u root -p1111" ]
interval: 5s
retries: 10
restart: on-failure
redis:
image: redis:7.0
container_name: db-search-redis
ports:
- "6379:6379"
healthcheck:
test: [ "CMD", "redis-cli", "--raw", "incr", "ping" ]
interval: 5s
retries: 10
restart: on-failure테스트 설정 및 구성
유저
import com.example.db_search.common.entity.BaseEntity;
import jakarta.persistence.*;
import lombok.Getter;
import lombok.NoArgsConstructor;
@Entity
@Table(name = "users", indexes = @Index(name = "idx_email", columnList = "indexingEmail"))
@Getter
@NoArgsConstructor
public class User extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String email;
@Column(nullable = false)
private String indexingEmail;
@Column(nullable = false)
private String name;
@Column(nullable = false)
private Integer age;
private User(String email, String indexingEmail, String name, Integer age) {
this.email = email;
this.indexingEmail = indexingEmail;
this.name = name;
this.age = age;
}
public static User create(String email, String indexingEmail, String name, Integer age) {
return new User(email, indexingEmail, name, age);
}
}
주문
import com.example.db_search.common.entity.BaseEntity;
import com.example.db_search.domain.user.entity.User;
import jakarta.persistence.*;
import lombok.Getter;
import lombok.NoArgsConstructor;
@Entity
@Table(name = "orders")
@Getter
@NoArgsConstructor
public class Order extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private Long price;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id", nullable = false)
private User user;
private Order(Long price, User user) {
this.price = price;
this.user = user;
}
public static Order create(Long price, User user) {
return new Order(price, user);
}
}
데이터 초기 설정
데이터 조회를 하려면 데이터가 존재해야하기때문에, 유저와 주문 모두 100만건의 데이터를 랜덤으로 생성하여 저장하였습니다.
유저 데이터 삽입
public void initUsers() {
if (userRepository.count() != 0) {
throw new CustomException(HttpStatus.BAD_REQUEST, "이미 유저가 생성되어있습니다.");
}
List<User> users = new ArrayList<>();
for (int i = 0; i < Const.TOTAL_RECORDS; i++) {
String email = "user_" + UUID.randomUUID().toString().substring(0, 8) + "@example.com";
String name = "Name_" + ThreadLocalRandom.current().nextInt(1000);
int age = 18 + ThreadLocalRandom.current().nextInt(82);
users.add(User.create(email, email, name, age));
if (users.size() >= Const.BATCH_SIZE) {
userJdbcRepository.saveAll(users);
users.clear();
log.info("유저 생성 완료한 개수 : " + (i + 1));
}
}
if (!users.isEmpty()) {
userRepository.saveAll(users);
}
}주문 데이터 삽입
public void initOrders() {
if (orderRepository.count() != 0) {
throw new CustomException(HttpStatus.BAD_REQUEST, "이미 주문이 생성되어있습니다.");
}
if (userRepository.count() == 0) {
throw new CustomException(HttpStatus.BAD_REQUEST, "현재 유저가 존재하지 않습니다. 유저를 먼저 생성해주세요.");
}
List<User> allUsers = userQueryService.findAll();
List<Order> orders = new ArrayList<>();
for (int i = 0; i < Const.TOTAL_RECORDS; i++) {
long price = 100 + (ThreadLocalRandom.current().nextLong(999) * 100);
User user = allUsers.get(ThreadLocalRandom.current().nextInt(allUsers.size()));
orders.add(Order.create(price, user));
if (orders.size() >= Const.BATCH_SIZE) {
orderJdbcRepository.saveAll(orders);
orders.clear();
log.info("주문 생성 완료한 개수 : " + (i + 1));
}
}
if (!orders.isEmpty()) {
orderRepository.saveAll(orders);
}
}테스트 대상은 다음과 같습니다
유저 테스트
- 이메일 사용
- 기본 방식의 유저 조회
- 인덱싱 방식의 유저 조회
- 이름 사용
- 기본 방식의 유저 조회
- 필요한 컬럼만 조회 방식의 유저 조회
- 배치 조회(IN) 방식의 유저 조회
- Redis Cache 방식의 유저 조회
- Caffeine Cache 방식의 유저 조회
- 비동기 방식의 유저 조회
- 페이징 방식의 유저 조회
주문 테스트
- 기본 방식의 주문 조회
- Fetch Join을 사용한 주문 조회
테스트
Swagger를 통한 응답시간 확인
먼저 swagger를 통한 응답시간을 확인해보겠습니다.
이메일 사용 기본 방식의 유저 조회
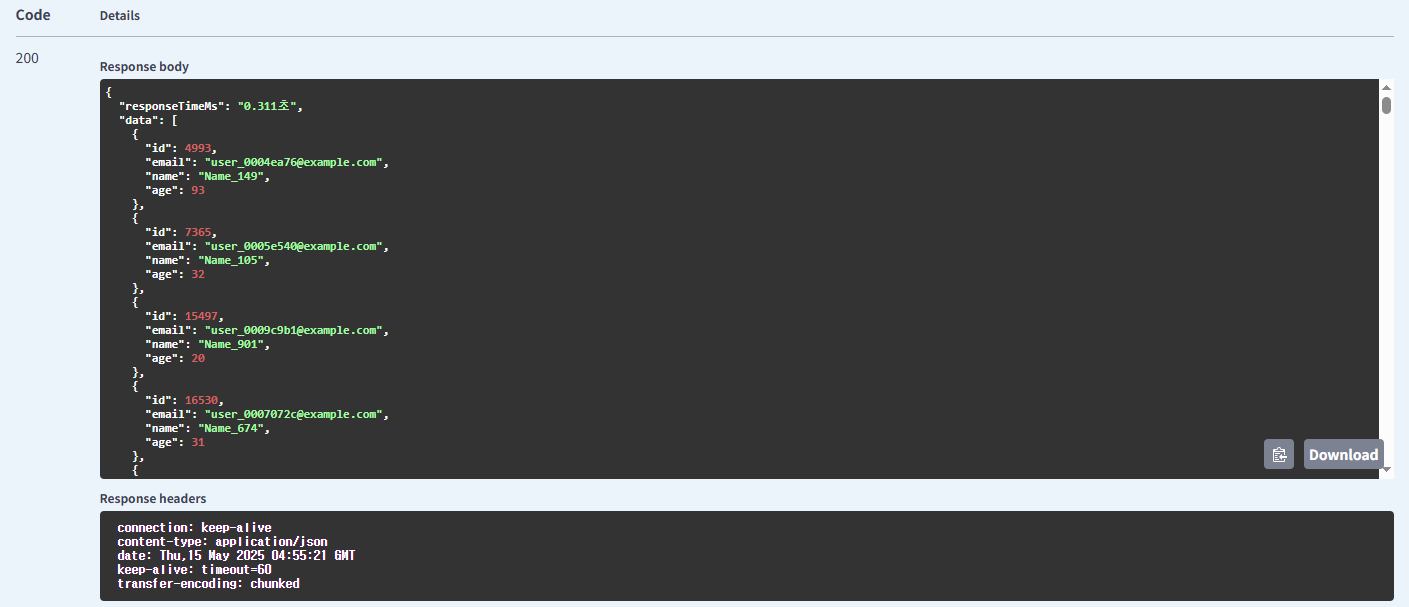
이메일 사용 인덱싱 방식의 유저 조회
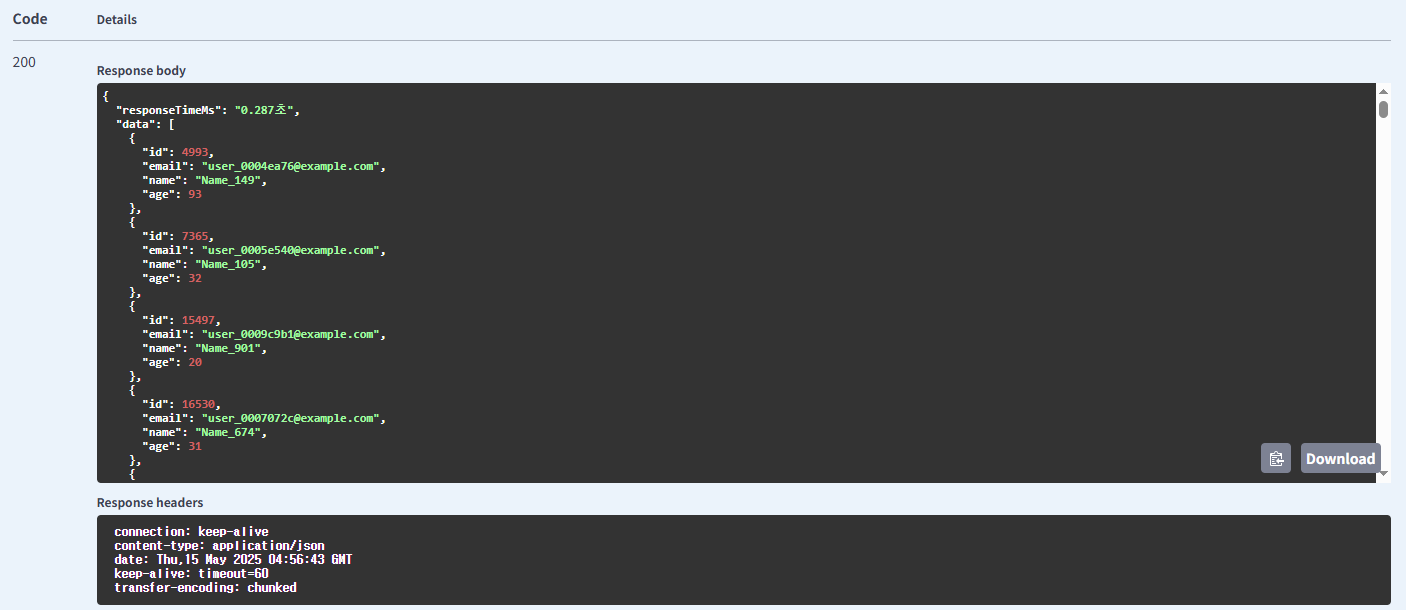
이름 사용 기본 방식의 유저 조회
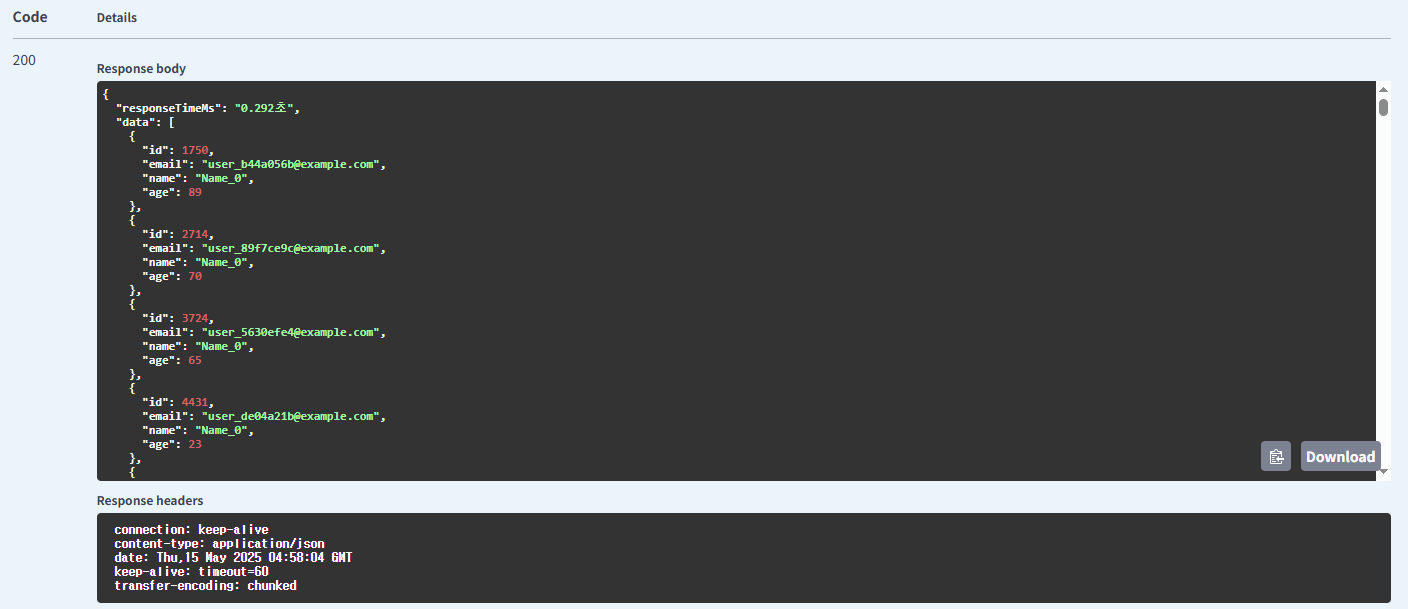
이름 사용 필요한 컬럼만 조회 방식의 유저 조회
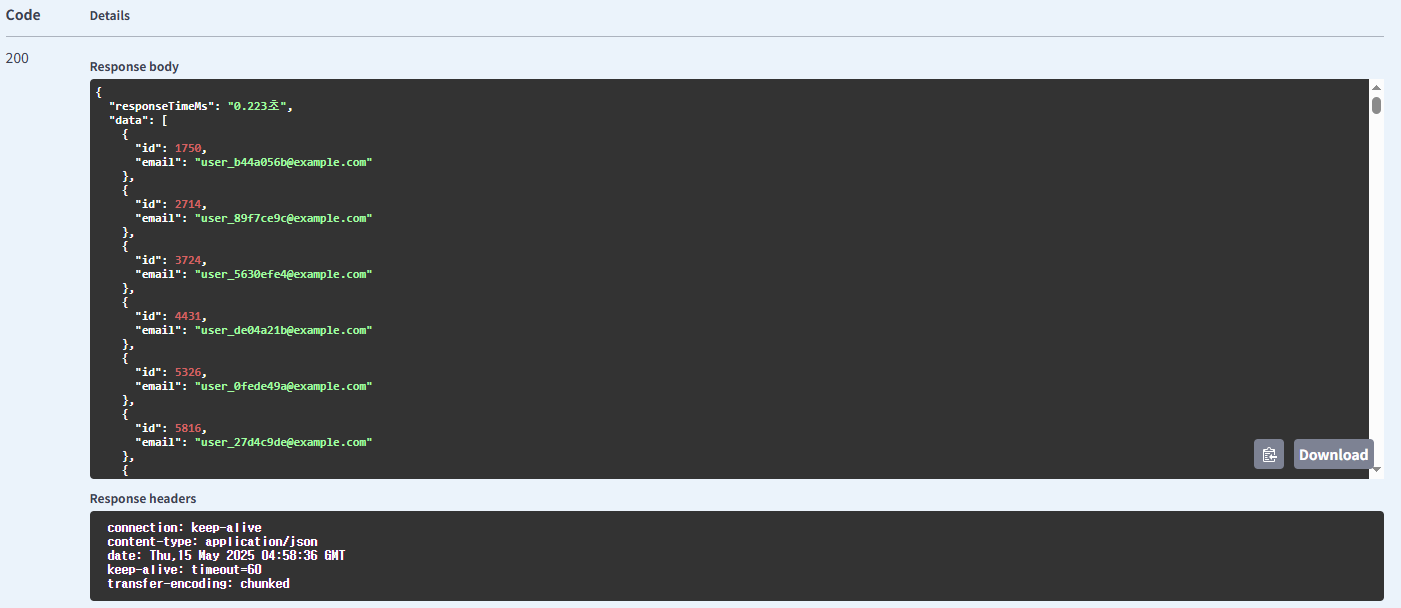
기본 방식의 다건 유저 조회
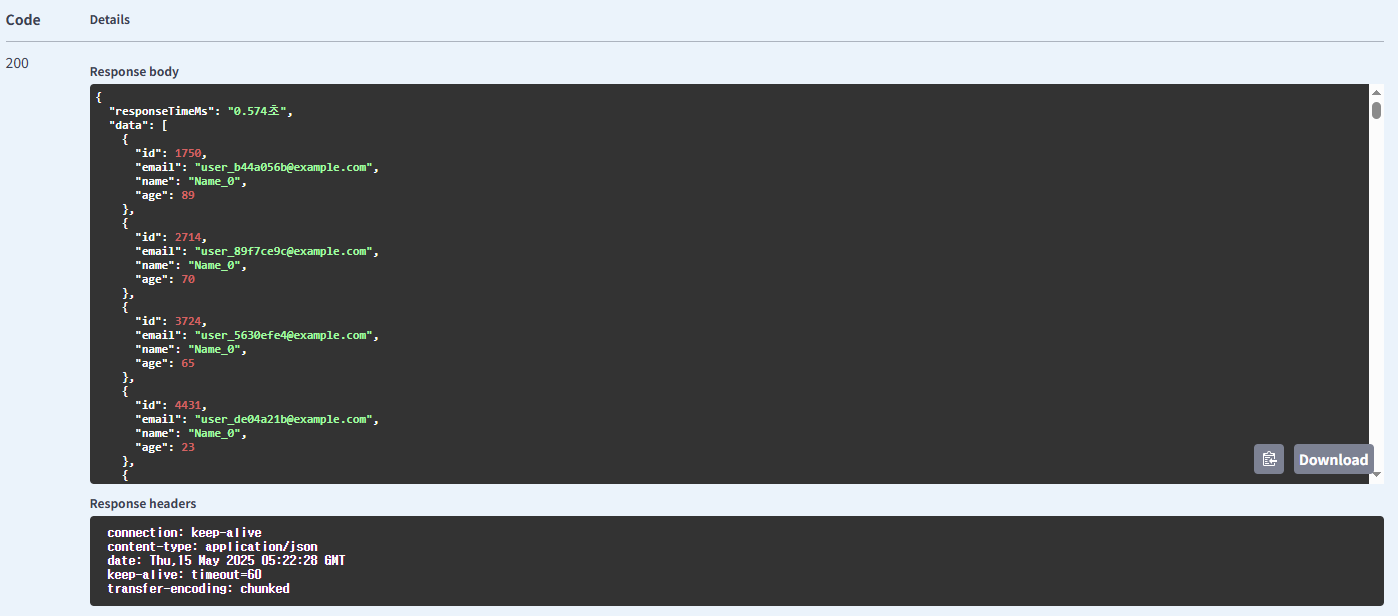
이름 사용 배치 조회(IN) 방식의 유저 조회
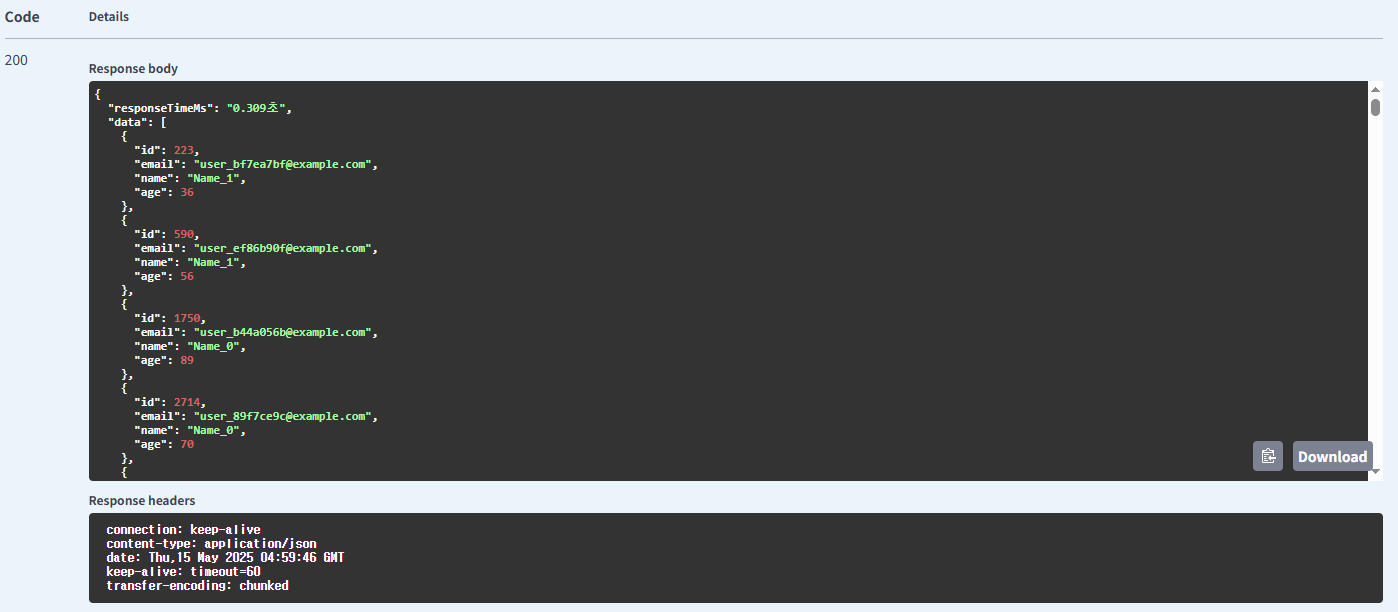
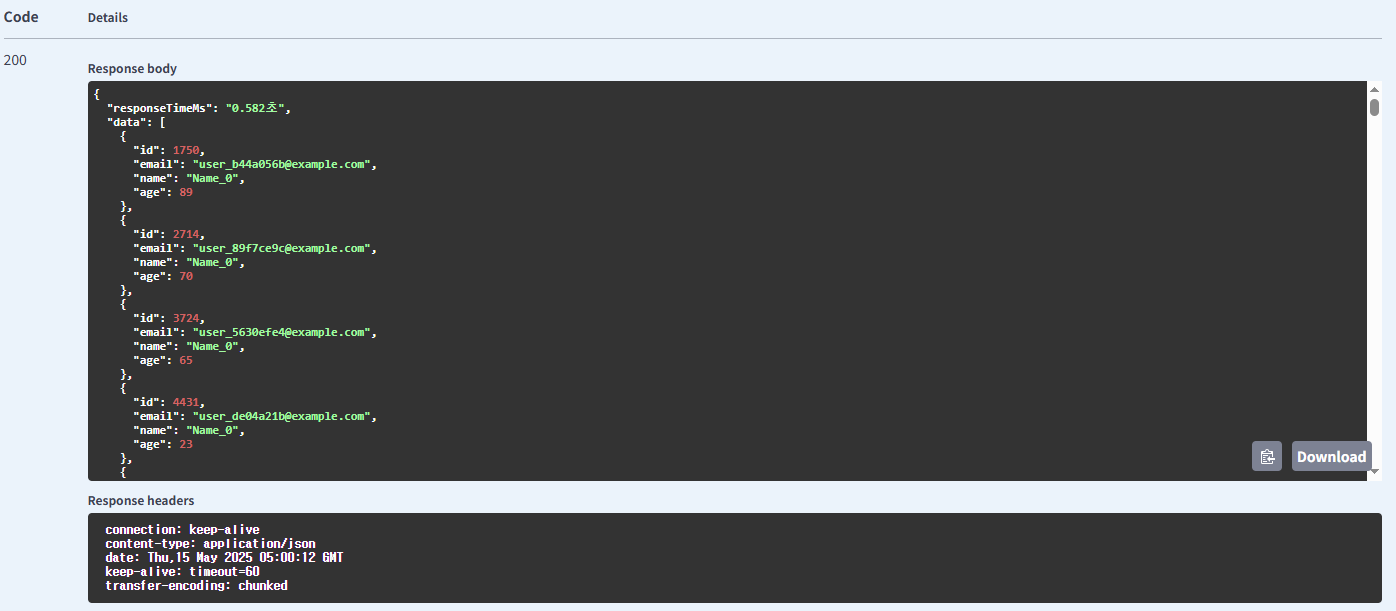
이름 사용 Redis Cache 방식의 유저 조회
처음 요청 시
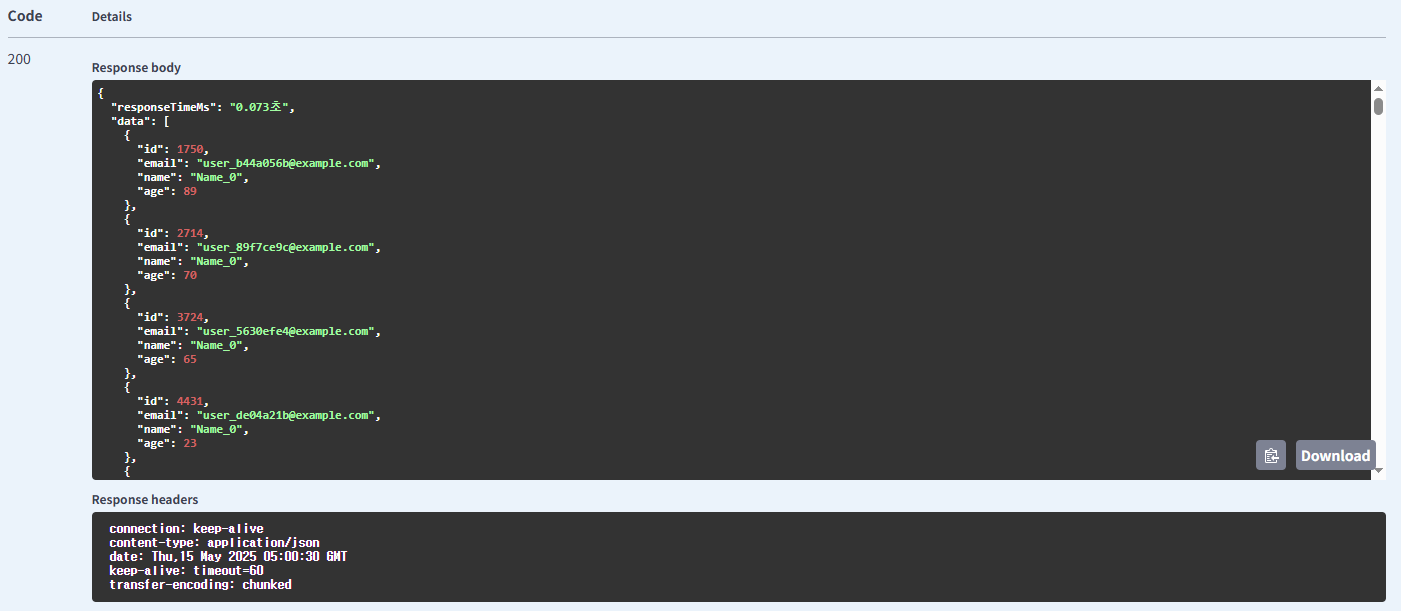
이후 요청 시
이름 사용 Caffeine Cache 방식의 유저 조회
처음 요청 시
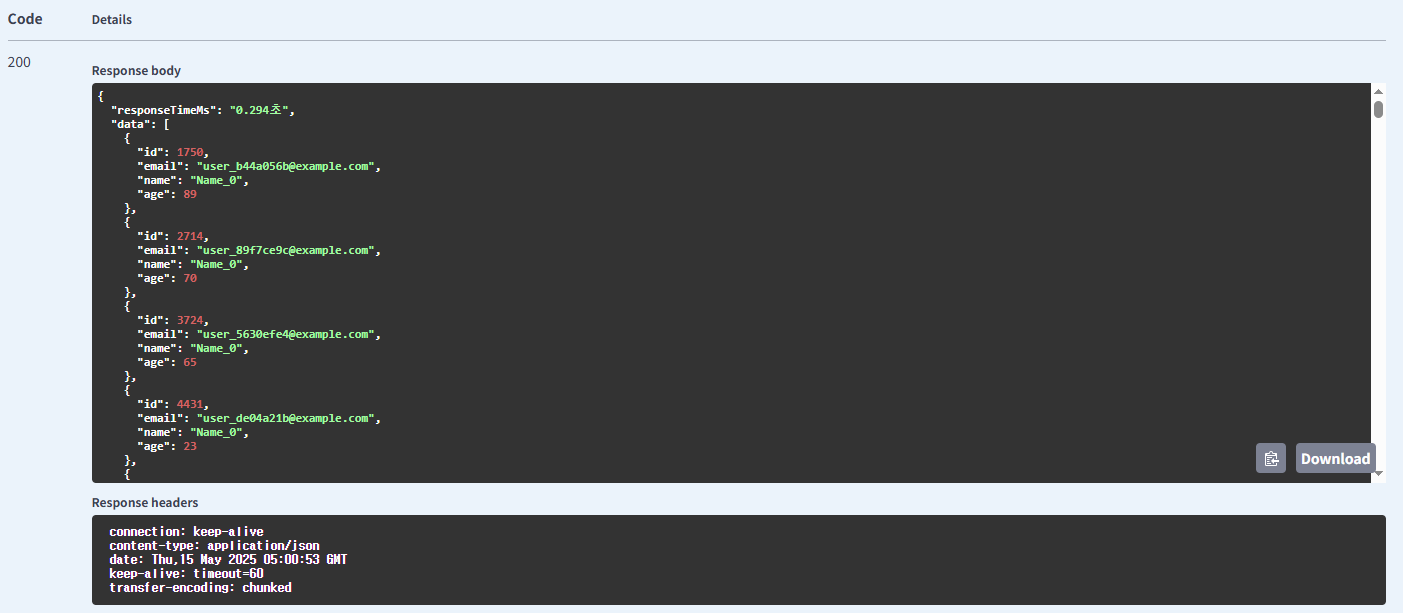
이후 요청 시
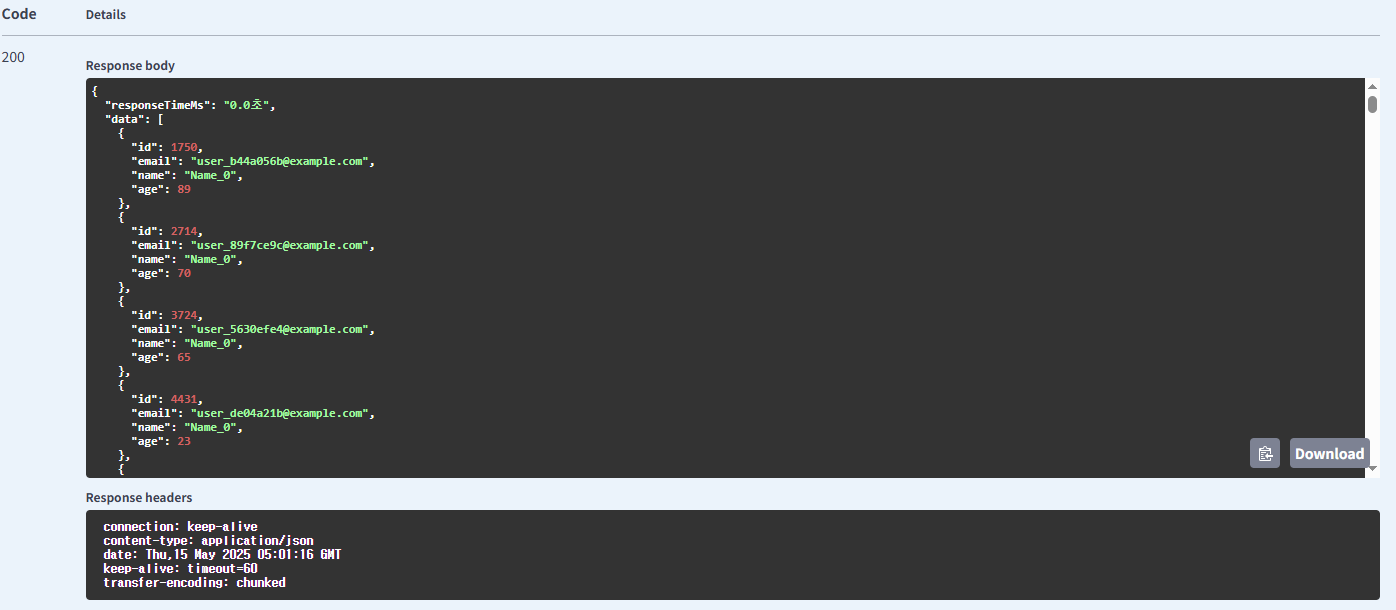
이름 사용 비동기 방식의 유저 조회
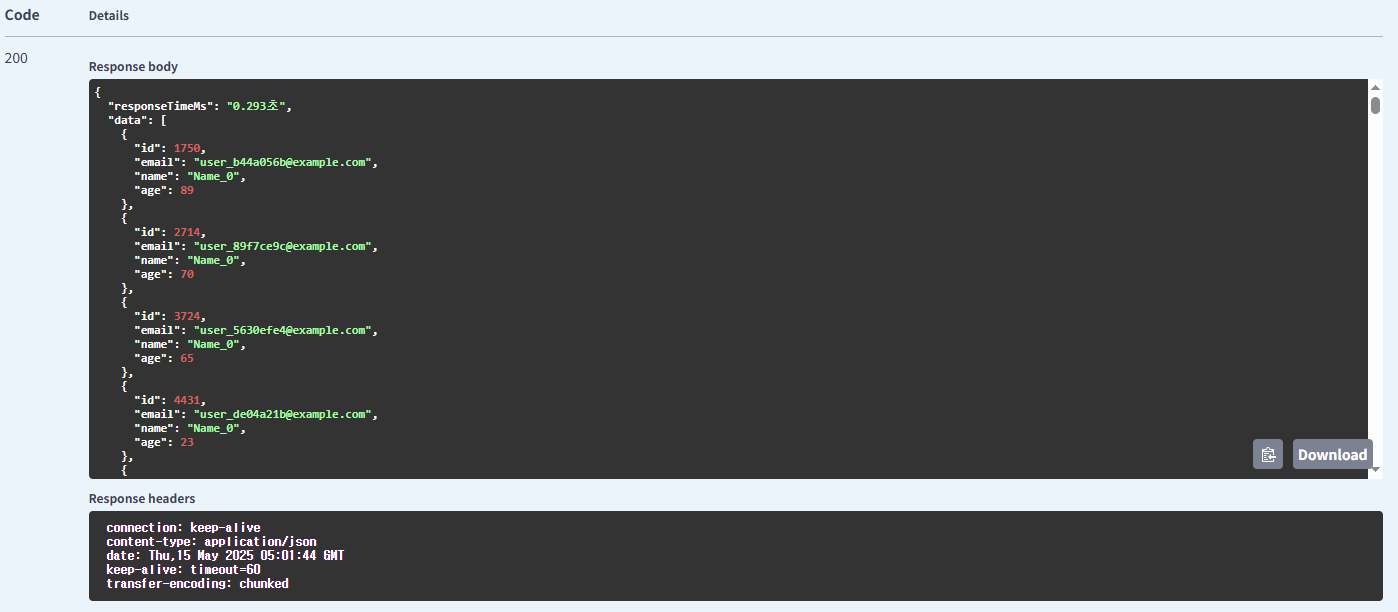
페이징 방식의 유저 조회
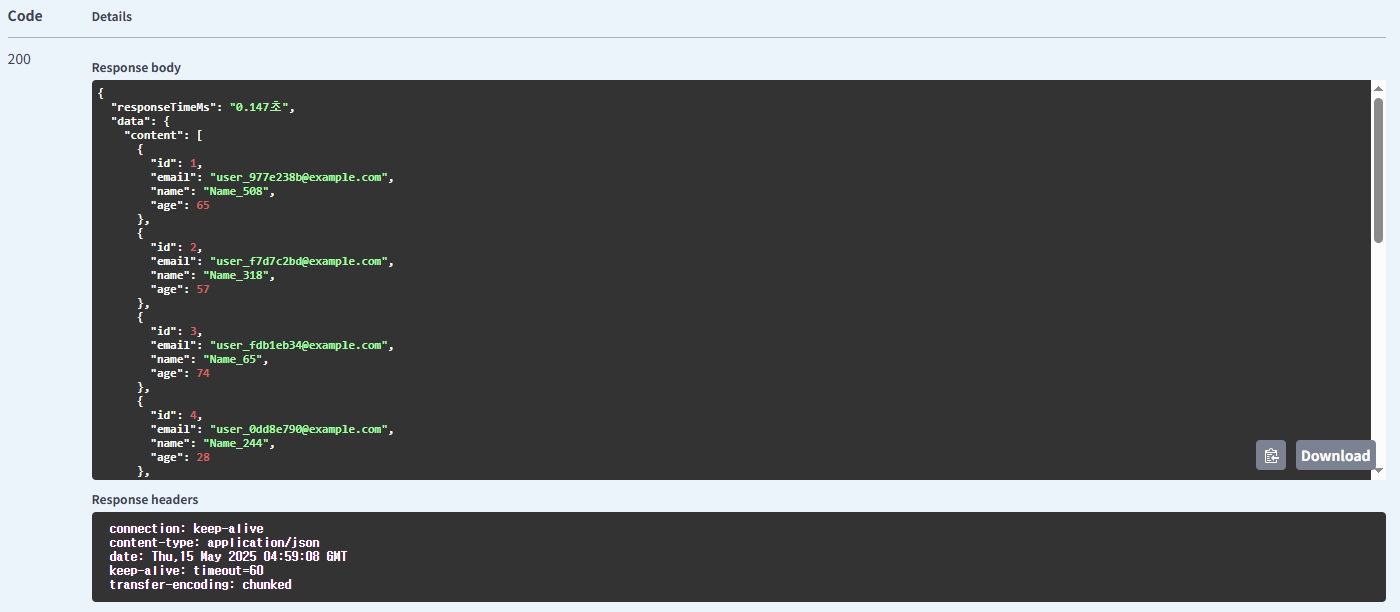
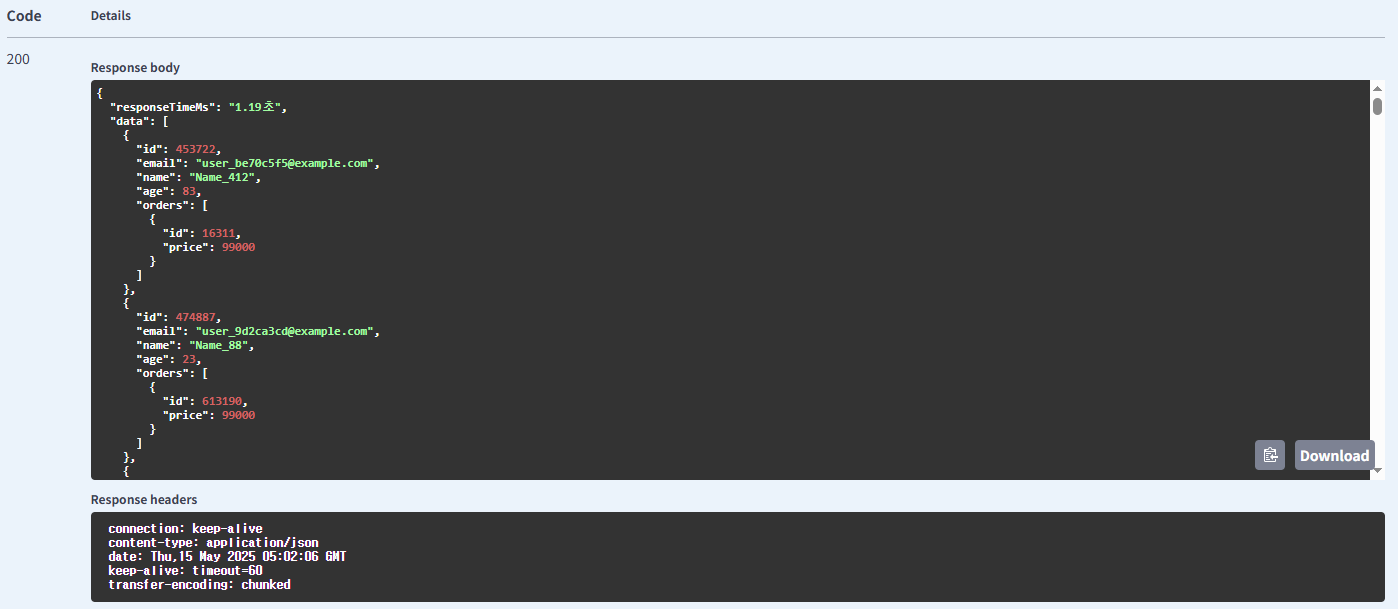
기본 방식의 주문 조회
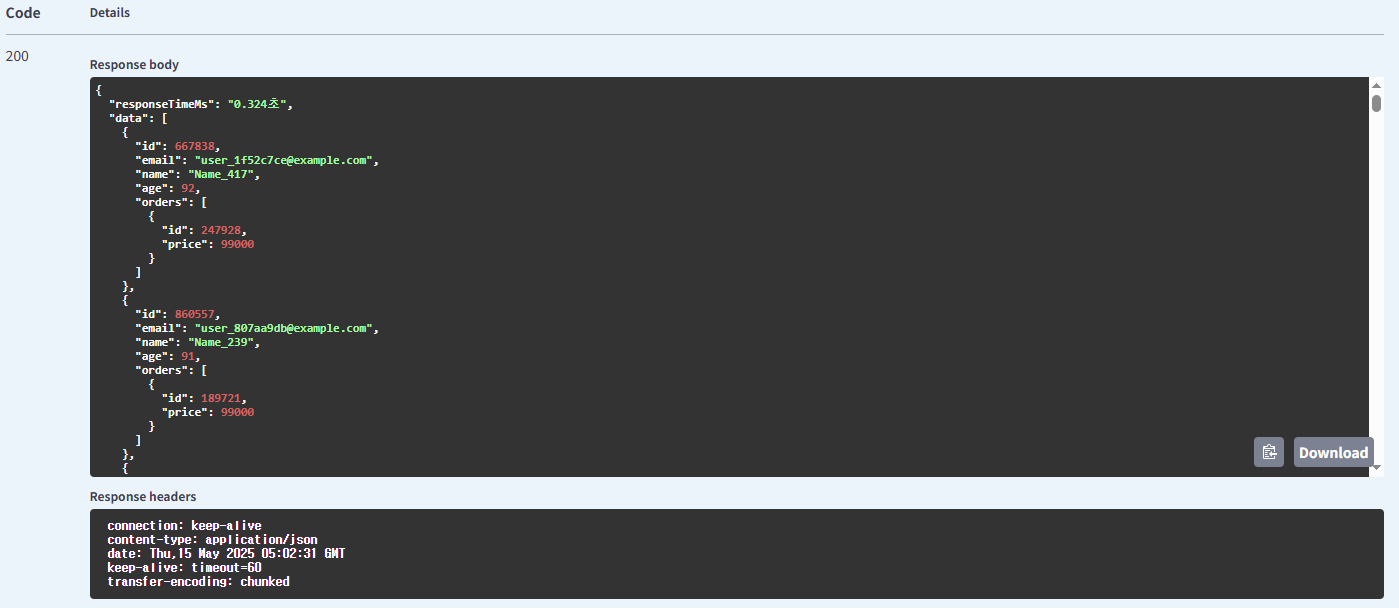
Fetch Join을 사용한 주문 조회
결과
| 조회 엔티티 | Parameter | 방식 | 응답 시간(초) |
|---|---|---|---|
| 유저 | 기본 방식 | 0.311 | |
| 유저 | 인덱싱 방식 | 0.287 | |
| 유저 | name | 기본 방식 | 0.282 |
| 유저 | name | 필요한 컬럼만 조회 | 0.223 |
| 유저 | name | 기본 방식의 다건 조회 | 0.574 |
| 유저 | name | 배치 조회(IN) | 0.309 |
| 유저 | name | Redis Cache | 0.582(처음), 0.073(이후) |
| 유저 | name | Caffeine Cache | 0.294(처음), 0.0미만(이후) |
| 유저 | name | Async | 0.293 |
| 유저 | page & size | 페이징 방식 | 0.147 |
| 주문 | price | 기본 방식 | 1.19 |
| 주문 | price | Fetch Join 사용 방식 | 0.324 |
표와 같이 결과가 나왔습니다.
전체 방식 모두 기본 방식을 사용하는 것 보다 응답시간이 빠른 결과를 알 수 있습니다.
해당 테스트는 1회 요청을 보내는 단일 테스트였으므로, K6를 사용하여 동시에 요청을 보내보는 테스트를 해보겠습니다.
K6 Test(유저 관련)
import http from 'k6/http';
import { check, sleep } from 'k6';
export const options = {
stages: [
{ duration: '10s', target: 50 }, // 50명
{ duration: '20s', target: 50 }, // 유지
{ duration: '10s', target: 100 }, // 100명
{ duration: '20s', target: 100 }, // 유지
{ duration: '10s', target: 0 }, // 종료
],
summaryTrendStats: ['avg', 'min', 'med', 'max', 'p(90)', 'p(95)'],
thresholds: {
'http_req_duration{endpoint:email_default}': ['p(95)<1000'],
'http_req_duration{endpoint:email_indexing}': ['p(95)<1000'],
'http_req_duration{endpoint:name_default}': ['p(95)<1000'],
'http_req_duration{endpoint:query_optimize}': ['p(95)<1000'],
'http_req_duration{endpoint:paging}': ['p(95)<1000'],
'http_req_duration{endpoint:user_list_default}': ['p(95)<1000'],
'http_req_duration{endpoint:batch_in}': ['p(95)<1000'],
'http_req_duration{endpoint:redis_cache}': ['p(95)<1000'],
'http_req_duration{endpoint:caffeine_cache}': ['p(95)<1000'],
'http_req_duration{endpoint:async}': ['p(95)<1000'],
},
};
export default function () {
// 엔드포인트별 요청 정의
const endpoints = [
{
name: 'email_default',
url: 'http://localhost:8080/users/email/default?email=user_000',
checkName: 'email default',
},
{
name: 'email_indexing',
url: 'http://localhost:8080/users/email/indexing?email=user_000',
checkName: 'email indexing',
},
{
name: 'name_default',
url: 'http://localhost:8080/users/name/default?name=Name_0',
checkName: 'name default',
},
{
name: 'query_optimize',
url: 'http://localhost:8080/users/name/query?name=Name_0',
checkName: 'query optimize',
},
{
name: 'paging',
url: 'http://localhost:8080/users/name/paging?page=0&size=10',
checkName: 'paging',
},
{
name: 'user_list_default',
url: 'http://localhost:8080/users/name/usersList?name=Name_0,Name_1',
checkName: 'user list default',
},
{
name: 'batch_in',
url: 'http://localhost:8080/users/name/batchWithIn?name=Name_0,Name_1',
checkName: 'batch with IN',
},
{
name: 'redis_cache',
url: 'http://localhost:8080/users/name/rediscache?name=Name_0',
checkName: 'redis cache',
},
{
name: 'caffeine_cache',
url: 'http://localhost:8080/users/name/caffeine?name=Name_0',
checkName: 'caffeine cache',
},
{
name: 'async',
url: 'http://localhost:8080/users/name/async?name=Name_0',
checkName: 'async',
},
];
// VU ID에 따라 하나의 엔드포인트 선택
const vuId = __VU; // 현재 VU의 ID (0부터 시작)
const endpointIndex = vuId % endpoints.length; // VU ID를 엔드포인트 수로 모듈러 연산
const selectedEndpoint = endpoints[endpointIndex];
// 선택된 엔드포인트 요청 실행
let res = http.get(selectedEndpoint.url, {
tags: { endpoint: selectedEndpoint.name },
});
check(res, {
[`${selectedEndpoint.checkName} status is 200`]: (r) => r.status === 200,
[`${selectedEndpoint.checkName} response time < 1000ms`]: (r) => r.timings.duration < 1000,
});
sleep(2); // 요청 간 2초 대기
}K6 Test(주문 관련)
import http from 'k6/http';
import { check, sleep } from 'k6';
export const options = {
stages: [
{ duration: '10s', target: 50 }, // 50명
{ duration: '20s', target: 50 }, // 유지
{ duration: '10s', target: 100 }, // 100명
{ duration: '20s', target: 100 }, // 유지
{ duration: '10s', target: 0 }, // 종료
],
summaryTrendStats: ['avg', 'min', 'med', 'max', 'p(90)', 'p(95)'],
thresholds: {
'http_req_duration{endpoint:price_default}': ['p(95)<1000'],
'http_req_duration{endpoint:join_fetch}': ['p(95)<1000'],
},
};
export default function () {
const endpoints = [
{
name: 'price_default',
url: 'http://localhost:8080/orders/price/default?price=99000',
checkName: 'price default',
},
{
name: 'join_fetch',
url: 'http://localhost:8080/orders/price/joinfetch?price=99000',
checkName: 'join fetch',
},
];
// VU ID에 따라 하나의 엔드포인트 선택
const vuId = __VU; // 현재 VU의 ID (0부터 시작)
const endpointIndex = vuId % endpoints.length; // VU ID를 엔드포인트 수로 모듈러 연산
const selectedEndpoint = endpoints[endpointIndex];
// 선택된 엔드포인트 요청 실행
let res = http.get(selectedEndpoint.url, {
tags: { endpoint: selectedEndpoint.name },
});
check(res, {
[`${selectedEndpoint.checkName} status is 200`]: (r) => r.status === 200,
[`${selectedEndpoint.checkName} response time < 1000ms`]: (r) => r.timings.duration < 1000,
});
sleep(2); // 요청 간 2초 대기
}코드와 같이 동시 사용자가 100명까지 늘어나 요청을 보내는 테스트를 진행해보겠습니다.
결과는 다음과 같습니다.
K6 주문 테스트
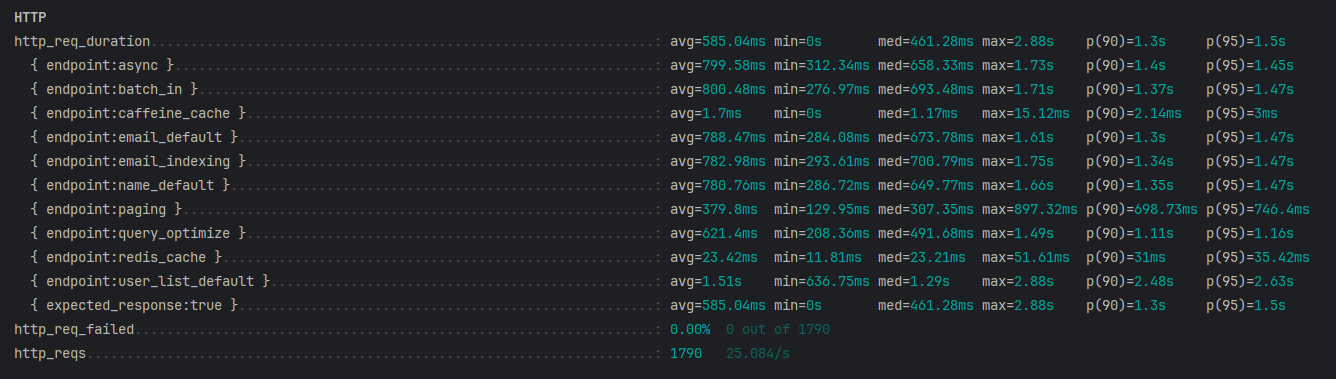
| 엔드포인트 | Parameter | 평균 (avg) | 최소 (min) | 중앙값 (med) | 최대 (max) | 90% (p90) | 95% (p95) |
|---|---|---|---|---|---|---|---|
| 기본 방식 | 788.47ms | 284.08ms | 673.78ms | 1.61s | 1.3s | 1.47s | |
| 인덱싱 방식 | 782.98ms | 293.61ms | 700.79ms | 1.75s | 1.34s | 1.47s | |
| 기본 방식 | name | 780.76ms | 286.72ms | 649.77ms | 1.66s | 1.35s | 1.47s |
| 필요한 컬럼만 조회 | name | 621.4ms | 208.36ms | 491.68ms | 1.49s | 1.11s | 1.16s |
| Redis Cache | name | 23.42ms | 11.81ms | 23.21ms | 51.61ms | 31ms | 35.42ms |
| Caffeine Cache | name | 1.7ms | 0ms | 1.17ms | 15.12ms | 2.14ms | 3ms |
| Async | name | 799.58ms | 312.34ms | 658.33ms | 1.73s | 1.4s | 1.45s |
| 페이징 방식 | page & size | 379.8ms | 129.95ms | 307.35ms | 897.32ms | 698.73ms | 746.4ms |
| 기본 방식의 다건 조회 | name | 1.51s | 636.75ms | 1.29s | 2.88s | 2.48s | 2.63s |
| 배치 조회(IN) | name | 800.48ms | 276.97ms | 693.48ms | 1.71s | 1.37s | 1.47s |
K6 주문 테스트

| 엔드포인트 | 평균 (avg) | 최소 (min) | 중앙값 (med) | 최대 (max) | 90% (p90) | 95% (p95) |
|---|---|---|---|---|---|---|
| 기본 방식 | 4.03s | 1.03s | 3.88s | 7.92s | 6.27s | 7.29s |
| Fetch Join 사용 방식 | 898.07ms | 246.36ms | 780.01ms | 2.53s | 1.71s | 1.96s |
테스트 결과
유저 테스트
- 기본 이메일 조회
- 평균 응답 시간이 788.47ms로, 최대 1.61초까지 걸렸습니다.
- 인덱스 미사용으로 풀 스캔이 발생했기 때문입니다.
- 인덱싱 활용 이메일 조회
- 평균 782.98ms로 email_default와 큰 차이가 없습니다.
- 캐시 영향으로 인덱싱 효과가 미미했던 것으로 판단 됩니다.
- 기본 이름 조회
- 평균 780.76ms로 이메일 조회와 유사합니다.
- 이름 필드에도 인덱스가 없어 풀 스캔이 발생했습니다.
- 필요한 컬럼만 조회
- 평균 621.4ms로 다른 조회 엔드포인트보다 빨랐습니다.
- 쿼리 최적화가 효과를 발휘하였습니다.
- Redis Cache
- 평균 23.42ms로 매우 빨랐습니다.
- Redis 캐시가 데이터베이스 조회를 줄여 성능을 크게 개선한 것으로 나타났습니다.
- Caffeine Cache
- 평균 1.7ms로 테스트 중 가장 빨랐습니다.
- Caffeine 캐시의 메모리 기반 조회가 매우 효율적인 것으로 판단됩니다.
- Async
- 평균 799.58ms로 동기 조회와 비슷한 결과가 나타났습니다.
- 페이징 조회
- 평균 379.8ms로 비교적 빨랐습니다.
- 페이징을 통해 데이터 조회량이 제한되어 성능이 개선되었습니다.
- 기본 방식의 다건 조회
- 평균 1.51s로 가장 느린 결과를 나타냈습니다.
- 이름과 일치하는 유저들을 하나씩 저장하다보니 시간이 오래걸린 것으로 나타났습니다.
- 배치 조회(IN)
- 평균 800.48ms로 다른 조회 엔드포인트와 유사한 결과가 나타났습니다.
- 하지만 IN 절로 인해 쿼리 한 번에 처리하여 기본 방식의 다건 조회보다 약 2배 빠른 성능을 보여줬습니다.
주문 테스트
- 기본 가격 조회
- 평균 4.03s로 매우 느렸습니다.
- 또한 N + 1 문제가 발생하여 쿼리가 과도하게 나간다는 단점이 존재했습니다.
- 조인 최적화 조회
- 평균 898.07ms로 기본 조회보다 약 4배 빨랐습니다.
- N + 1 문제를 JOIN FETCH로 해결함으로써 그만큼 성능이 향상되었다고 생각합니다.
결론
이번 포스팅에서는 대용량 데이터 조회 시 최적화 하는 방식들을 알아보았습니다.
각 방식은 사용 용도에 따라 적합성이 다릅니다.
예를 들어, 초고속 응답이 필요한 경우 Caffeine 또는 Redis Cache를 사용을 할 수 있습니다.
대량 데이터 조회에는 paging 처리나 Indexing을 사용할 수 있습니다.
또한 전체 컬럼이 필요하지 않을 경우, 필요한 컬럼만 뽑아 사용하는 쿼리 최적화 방식을 사용할 수 있습니다.
N + 1 문제를 해결하기 위해서 FETCH JOIN을 통한 배치 최적화 방식을 사용할 수 있습니다.
각 데이터의 특성을 이해하고 사용 용도에 맞게 선택하면 성능 최적화를 달성할 수 있을 것이라 생각합니다.
