
최근 PlayMCP 홈페이지에 Spring 서버 진단 MCP를 배포 후 운영 관점에서 리펙토링을 진행했습니다.
작동은 잘 하지만 엣지 케이스의 경우 작동하지 않아 대비책을 만들었습니다.
어떤걸 변경했는지 기술해보겠습니다.
Forwarder 전송 오류
만약 Forwarder가 log, metrics 같은 정보를 보내다 실패할 경우 어떻게 될까요?
def send_with_retry(batch):
body = json.dumps(batch, ensure_ascii=False)
backoff = BACKOFF_INITIAL_MS / 1000.0
try:
resp = requests.post(MCP_LOG_INGEST_URL, headers=HEADERS, data=body.encode("utf-8"), timeout=HTTP_TIMEOUT_MS/1000.0)
if 200 <= resp.status_code < 300: return
print(f"[forwarder] ingest failed: {resp.status_code}")
except Exception as e:
print(f"[forwarder] ingest error: {e}")
해당 재시도 로직에서 오류가 발생할 경우 패킷을 무한 재전송합니다.
Q : 재전송 로직을 넣은 이유?
A : 만약,MCP서버의 오류로 수신이 불가할 경우 사용자의 서버에서 오류가 발생해도Forwarder의 수신은 성공하지만MCP서버의 전송에서 오류가 발생하고 해당 오류는 사라집니다.
status_code = 400 ~ 499 의 경우 토큰 유무 및 인증/인가 문제이므로 굳이 재전송 할 필요는 없습니다. 그리고 무한 재전송을 네트워크 리소스를 많이 소비할 수 있으므로 리펙토링이 필요합니다.
전송 재시도
# 배치 전송 함수
# 재전송 로직을 추가
# 1분간 재시도 후 드랍
def send_with_retry(batch):
body = json.dumps(batch, ensure_ascii=False).encode("utf-8")
backoff = BACKOFF_INITIAL_MS / 1000.0
backoff_max = BACKOFF_MAX_MS / 1000.0
timeout_s = HTTP_TIMEOUT_MS / 1000.0
deadline = time.time() + DROP_AFTER_S
while True:
now = time.time()
if now >= deadline:
print(f"[forwarder] drop batch after {DROP_AFTER_S:.0f}s retry (size={len(batch)})")
return False
try:
resp = requests.post(
MCP_LOG_INGEST_URL,
headers=HEADERS,
data=body,
timeout=timeout_s
)
if 200 <= resp.status_code < 300:
return True
# 4xx(429 제외)는 재시도 의미 없음 -> 드랍
if 400 <= resp.status_code < 500 and resp.status_code != 429:
print(f"[forwarder] rejected {resp.status_code}: {resp.text[:200]}")
return None
print(f"[forwarder] ingest failed: {resp.status_code}")
except Exception as e:
print(f"[forwarder] ingest error: {e}")
remaining = deadline - time.time()
if remaining <= 0:
print(f"[forwarder] drop batch after {DROP_AFTER_S:.0f}s retry (size={len(batch)})")
return False
# 남은 시간 안에서만 sleep
sleep_s = min(backoff, max(0.0, deadline - time.time()))
time.sleep(sleep_s * random.uniform(0.7, 1.3)) # 지터
backoff = min(backoff * 2, backoff_max)여기서 전송에 실패했다고 바로 재시도하면 과도한 리소스 낭비가 될 수 있습니다.
MCP서버 문제로 전송이 안될 경우 계속 재시도하면 리소스 낭비입니다.status_code 400 ~ 499일 경우 재시도는 의미 없습니다.
따라서 status_code에 따라 로직은 분리합니다.
또한, Jitter 값을 두어 실패 후 바로 재전송이 아닌 실패할 때 마다 더 느리게 보내는 정책을 택하며 사용자 서버의 리소스를 최소화 합니다.
초기값으로
60s동안 전송에 실패할 경우 전송 로직을 종료합니다.
(그리고 에러 로그를 버립니다.)
Queue 에 넣는 이유
MCP 서버가 복구될 때 까지 로그를 저장해야합니다.
사용자 서버에서 forwarder 가 log를 받을 경우 바로 보내는게 아닌 Queue에 넣고 Sender가 queue에서 로그를 가져와 보냅니다.
# flush 는 재전송이 아닌 batch 를 큐에 넣기만 함
def flush_batch():
nonlocal last_flush
if not batch: return
enqueue_drop_oldest(batch.copy())
print(f"[forwarder] queued {len(batch)} events")
batch.clear()
last_flush = time.time()하나의 로그로 묶은 후 queue에 넣는 로직입니다.
로그를 생성하는
productor, 로그를 서버로 보내는sender는 각각 다른Thread에서 작동합니다.
만약 두 로직이 같은 흐름이라면 로그 재전송에 시간을 뺐겨 로그 생성을 못하게됩니다.
def sender_loop():
while not stop_event.is_set():
try:
batch = send_q.get(timeout=0.5)
except queue.Empty:
continue
try:
r = send_with_retry(batch) # 실패하면 내부에서 계속 재시도
if r is True:
print(f"[forwarder] {len(batch)} batch sent successfully")
else:
# None: 4xx 같은 영구 실패 -> 버림
pass
finally:
send_q.task_done()
def start_sender_thread():
t = threading.Thread(target=sender_loop, daemon=True)
t.start()이렇게 다른 Thread 에서 작동합니다!
Queue 의 한계
서비스가 고도화 될 경우 Queue는 이용하기 힘듭니다.
-
Queue는 메모리에 저장되며Forwarder재시작 또는 메모리 초과의 경우 더 이상 넣을 수 없습니다. -
재전송에 실패할 경우 다시
Queue에 넣도록 했는데 메모리 초과로 더 이상 넣을 수 없는 경우 맨 앞의 로그부터 삭제하는데 순서가 뒤죽박죽 될 수 있음.
가장 큰 이유는 메모리는 휘발성 이므로 메모리에 저장하는 로직은 정보를 잃기 쉽습니다.
만약 서비스를 고도화 한다면 다음의 방향성이 있습니다.
처음에 Queue에 저장 후 용량 초과 시 JSON 파일을 만들어 저장 (디스크에 저장)
이 방법으로 진행하려 했지만 로그 수집 및 전송 로직보다 파일에 저장하고 보내는 로직이 더 복잡해지며 단순화를 위해 포기했습니다.
또한, 제 서비스는 Forwarder와 사용자의 서버가 docker compose 형태로 같이 배포되는 형태이므로 배포가 잦은 초기 서비스의 경우 파일에 저장해야 할 만큼의 로그의 양이 생기지 않습니다.
테스트
2가지 테스트를 진행해보겠습니다.
- 로그 수집 서버의 500에러 -> Forwarder Queue에 로그 저장 -> 서버 복구 -> Queue 의 로그 전송
- 로그 수집 서버 중단 -> Forwarder 로그 1000개를 저장 -> 서버 복구 -> 서버에 로그 1000개 전송
1번 테스트
[가정]
MCP서버의 로그 수신Controller에서 500 에러를 가정함.MCP서버는 터널링을 통해 외부에 있다고 가정함.
// 로그 수신(PUSH): 포워더/사용자 서버가 호출
@PostMapping("/servers/{name}/ingest/logs")
public ResponseEntity<?> ingestLogs(
@PathVariable("name") String serverName,
@RequestHeader("X-MCP-TOKEN") String token,
@RequestBody List<LogEventDto> events) {
return ResponseEntity.status(
HttpStatus.INTERNAL_SERVER_ERROR).build();
}이렇게 받자마자 500에러를 반송하게 가정했습니다.
서버 시작과 동시에 인위적 에러를 발생시켰습니다.
[forwarder] queued 1 events
[forwarder] ingest failed: 500
[forwarder] ingest failed: 500
[forwarder] queued 17 events
[forwarder] ingest failed: 500
[forwarder] ingest failed: 500
[forwarder] queued 5 events
[forwarder] ingest failed: 500
[forwarder] queued 3 events
Metric 전송 완료
[forwarder] ingest failed: 500
Metric 전송 완료
...
[forwarder] drop batch after 60s retry (size=1)
...
[forwarder] drop batch after 60s retry (size=17)2분 후 재전송 로직이 2번 Drop 된 로그를 볼 수 있습니다.
여기서 MCP 서버의 로직을 복원시켜 정상화 됐다 가정해보겠습니다.
// 로그 수신(PUSH): 포워더/사용자 서버가 호출
@PostMapping("/servers/{name}/ingest/logs")
public ResponseEntity<?> ingestLogs(
@PathVariable("name") String serverName,
@RequestHeader("X-MCP-TOKEN") String token,
@RequestBody List<LogEventDto> events) {
return ResponseEntity.ok(
logService.ingestLogs(serverName, token, events));
}
MCP서버는 정상으로 바꿨지만 사용자 서버와Forwarder는 계속 실행시켰습니다.
[forwarder] 5 batch sent successfully
[forwarder] 3 batch sent successfully
[forwarder] 1 batch sent successfully
[forwarder] 17 batch sent successfullyMCP 서버가 정상화 된 후 바로 이전 로그가 전송된 모습입니다.
2번 테스트
import time
from datetime import datetime, timezone, timedelta
KST = timezone(timedelta(hours=9))
log_file_path = '/app/logs/application.log'
total_logs = 1000 # 로그 1000개 저장
for i in range(1, total_logs + 1):
now = datetime.now(KST)
timestamp = now.strftime('%Y-%m-%dT%H:%M:%S.%f')[:-3] + '+09:00'
log_message = f"{timestamp} ERROR [QueueTest] Dummy log sequence: {i}\n"
with open(log_file_path, 'a') as f:
f.write(log_message)
time.sleep(0.01)
print(f"✅ 총 {total_logs}개의 로그가 {log_file_path}에 생성되었습니다!")- 로그 수집 서버 중단
- 사용자 서버에 해당 스크립트를 적용하여 테스트 로그 1000개를 저장
- 로그 수집 서버 복구 후 로그 1000개가 정확히 오는지 테스트
이 순서로 진행했습니다.
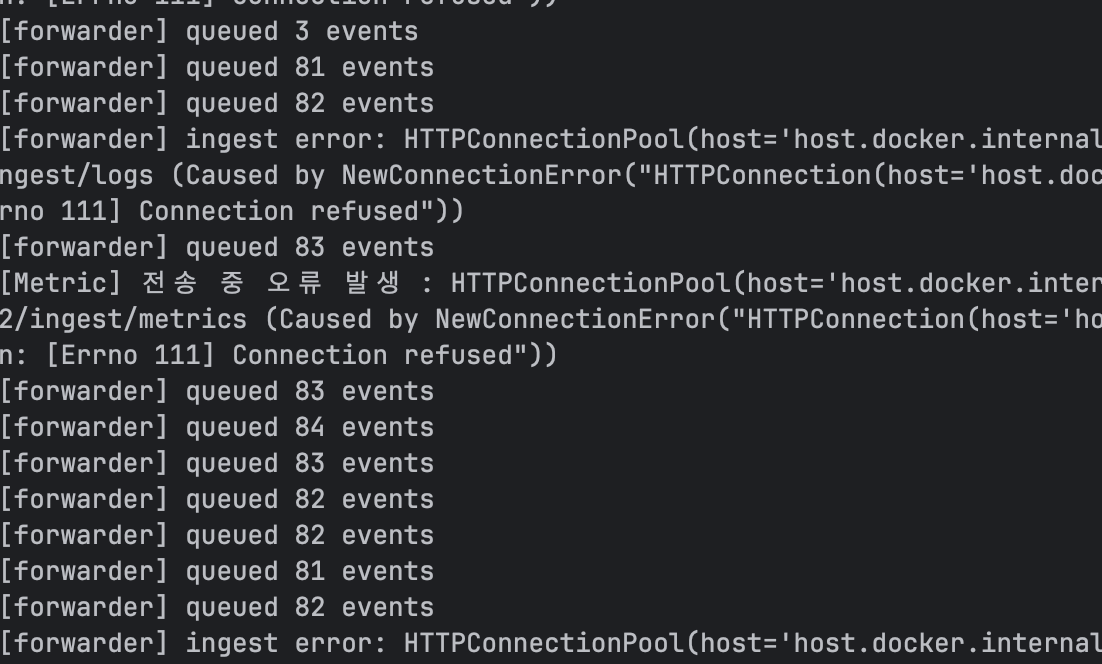
로그 수집 서버에 문제가 생기자 전부 Queue에 넣고 대기합니다.
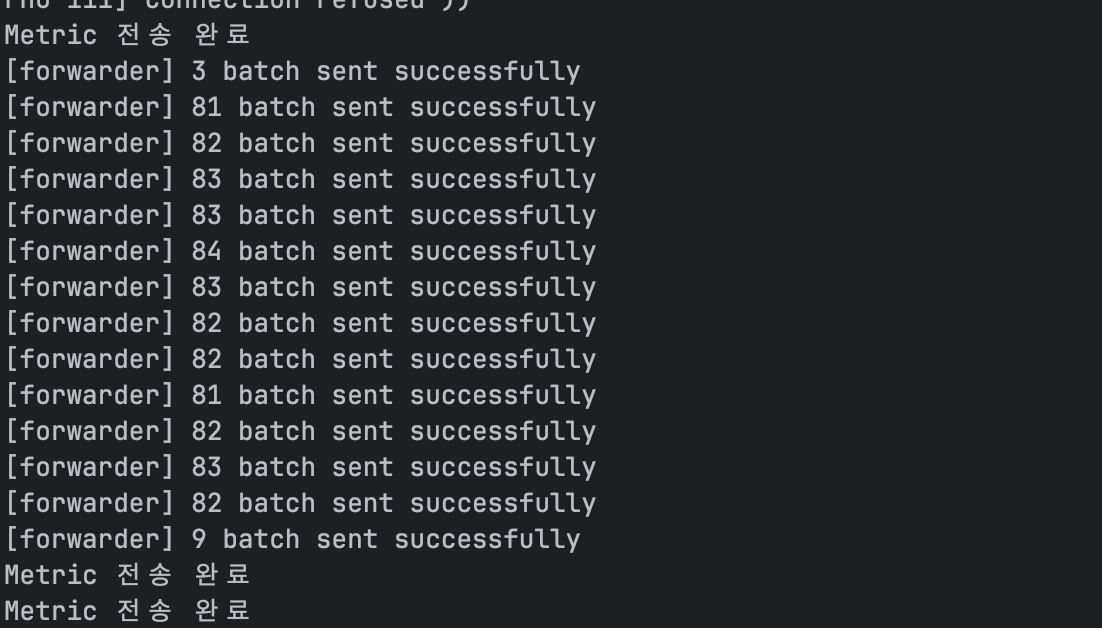
서버가 복구되자 전부 전송했습니다.
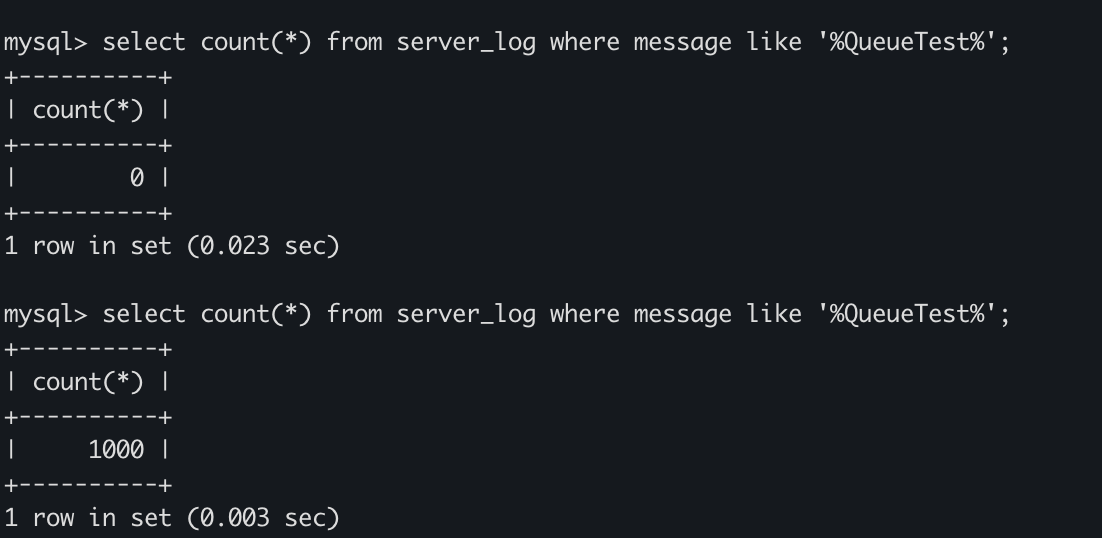
서버 복구 전에 0개였지만 복구 후 정확히 1000개가 도착했습니다.
마무리
이번에는 MCP 서버의 오류로 전송하지 못하게 될 경우를 처리했습니다.
하지만, 재전송 로직을 만들 경우 MCP 서버에 중복된 로그가 저장될 수 있습니다.
다음 시간에는 MCP 서버에 중복 로그를 막도록 리펙토링한 결과를 기술해보겠습니다!
