최적화 문제
Trello에서 멤버는 특정 키워드로 카드를 검색하거나, 프로젝트별로 카드를 필터링하고 있습니다. 하지만 데이터가 대량으로 축적됨에 따라 카드 검색 속도가 느려질 수 있습니다. 카드 검색 속도를 향상시킬 수 있는 최적화 방법을 적용해주세요.
요구사항
- 카드 검색 속도를 향상시키기 위해 적절한 인덱스를 설계해주세요.
- 자주 사용되는 조건에 맞는 컬럼에 인덱스를 적용하여 대용량 데이터에서도 빠른 검색을 지원하세요.
발표 자료 준비
- 개선 대상 쿼리와 해당 쿼리를 선택한 이유
- 인덱스 설정 DDL 쿼리
- 쿼리 속도 비교(before, after)
1. 카드 도메인의 쿼리 3가지
카드 도메인에서 발생하는 쿼리는 3가지이다.
// 1번
Card card = cardRepository.findByIdOrElseThrow(cardId);
// 2번
List<Card> cardList = cardRepository.findAllByBoardListId(listId);
// 3번
List<Card> cards = cardRepository.findAllSearchByConditions(pageable,
cardSearchRequestDto.getBoardId(),
cardSearchRequestDto.getCardTitle(),
cardSearchRequestDto.getCardExplanation(),
cardSearchRequestDto.getEndAt(),
cardSearchRequestDto.getCardManagerName()
);- 3번 쿼리 (QueryDsl)
queryFactory.selectFrom(card)
.leftJoin(card.boardList, boardList)
.leftJoin(card.cardManagers, cardManager)
.leftJoin(cardManager.user, user)
.fetchJoin()
.where(
boardIdEq(boardId),
cardTitleEq(cardTitle),
cardExplanationEq(cardExplanation),
endAtEq(endAt),
cardManagerNicknameEq(cardMangerName)
)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.orderBy(card.modifiedAt.desc())
.fetch();1번 쿼리
1번 쿼리는 PK 컬럼으로 조회하기 때문에 이미 존재하는 인덱스를 통해 검색할 것이다.
2번 쿼리
2번 쿼리는 사용자가 보드에 접속할 때마다 사용되는 쿼리로 굉장히 자주 사용될 것이다. 그리고 listId 컬럼은 card 테이블에서 중복도가 낮은 컬럼이고 수정될 가능성이 낮은 컬럼이기 때문에 인덱스를 적용하기 적합하다.
3번 쿼리
3번 쿼리는 여러 조건을 통해 부합하는 데이터를 조회하는 쿼리로 각 조건들은 null일 수도 있다.
일반적으로 카드를 조회하는 대표적인 조건으로는
1) 제목과 내용에 어떤 단어나 문장이 포함되어있는 지
2) 오늘까지 마감일인 카드가 있는 지
3) 특정 보드 안에 있는 모든 카드를 검색할 때
이라고 생각한다.
1번에서는 내용의 경우는 수정이 아주 빈번하게 발생할 가능성이 높기 때문에 오히려 성능 저하를 일으킬 수 있다. 왜냐하면 수정을 할 때 인덱스에도 추가 작업을 수행해야하기 때문이다.
그래서 1번에서는 제목에만 인덱스를 적용하면 좋을 것이다.
2번은 수정의 빈도수가 적당하고, 조건으로 자주 사용될 것이라 생각하기 때문에 인덱스를 적용하면 좋을 것이다.
3번은 어차피 보드에 진입시 볼 수 있기 때문에, 특정 보드 조건은 다른 조건과 함께 사용될 가능성이 높다.
2. 인덱스 설정 및 데이터 셋팅
1) JPA 엔티티에 설정
@Getter
@Entity
@Table(name = "card", indexes = {
@Index(name = "idx_list_Id", columnList = "list_id"),
@Index(name = "idx_endAt", columnList = "end_at"),
@Index(name = "idx_card_title", columnList = "card_title")
// @Index(name = "idx_card_title_card_explanation", columnList = "card_title, card_explanation")
})
public class Card extends BaseEntity {
...
}2) 인덱스 설정 DDL 쿼리
-- 리스트 식별자(list_id)에 대한 인덱스 생성
CREATE INDEX idx_list_Id ON card (list_id);
-- 마감일(end_at)에 대한 인덱스 생성
CREATE INDEX idx_endAt ON card (end_at);
-- 카드 제목(card_title)에 대한 인덱스 생성
CREATE INDEX idx_card_title ON card (card_title);
-- 카드 제목(card_title)과 카드 설명(card_explanation)에 대한 복합 인덱스
-- CREATE INDEX idx_card_title_card_explanation ON card (card_title, card_explanation);
3) 데이터 셋팅
-데이터 10만 건을 셋팅한다.
@Component
public class CardInitConfig {
private final String[] array1 = {"바나나", "사과", "귤", "포도", "키위", "멜론", "두리안", "배", "감", "망고"};
private final String[] array2 = {"하나", "둘", "셋", "넷", "다섯", "여섯", "일곱", "여덟", "아홉", "열"};
private final String[] colors = {"빨강", "주황", "노랑", "초록", "파랑", "남색", "보라", "검정", "흰색", "회색"};
private final WorkspaceRepository workspaceRepository;
private final BoardRepository boardRepository;
private final BoardListRepository boardListRepository;
private final CardRepository cardRepository;
public CardInitConfig(WorkspaceRepository workspaceRepository, BoardRepository boardRepository, BoardListRepository boardListRepository, CardRepository cardRepository) {
this.workspaceRepository = workspaceRepository;
this.boardRepository = boardRepository;
this.boardListRepository = boardListRepository;
this.cardRepository = cardRepository;
}
@PostConstruct
@Transactional
public void init() {
// 워크스페이스 생성
Workspace workspace = workspaceRepository.save(new Workspace("워크스페이스1", "환영"));
// 리스트 생성
List<Board> boards = new ArrayList<>();
for (int i=0; i<1000; i++){
for (int j=0; j<10; j++){
Board board = new Board(workspace, "보드", "#000000", "image.jpg");
boards.add(board);
}
}
boardRepository.saveAll(boards);
// 리스트 생성
List<BoardList> boardLists = new ArrayList<>();
for (int i=0; i<100; i++){
for (int j=0; j<10; j++){
BoardList boardList = new BoardList(boards.get(i*10+j), "리스트"+i+array1[j]);
boardList.addArrayNumber(i);
boardLists.add(boardList);
}
}
boardListRepository.saveAll(boardLists);
// 카드 생성
List<Card> cardList = new ArrayList<>();
for(int i=0; i<10; i++){
for (int j=0; j<10; j++){
for(int k=0; k<100; k++){
for (int j2=0; j2<10; j2++){
// 카드 생성
Card card = new Card("제목 "+ array1[i] + array2[j]+colors[j2],
"내용 "+ array1[i] + array2[j],
LocalDate.parse("2024-01-01").plusYears(i).plusMonths(j).plusDays(j2)
);
card.addBoardList(boardLists.get(k*10+j2));
// 카드 리스트에 추가
cardList.add(card);
}
}
}
}
cardRepository.saveAll(cardList);
}
}3. 최적화 시도
1) FK도 자동 인덱스 적용
2번 쿼리와 3번 쿼리의 3) 조건은 각 테이블의 FK로 설정되어있는 컬럼을 조건으로 조회하는데 FK는 mysql에서 기본적으로 인덱스를 적용하기 때문에 최적화가 이미 되어있다고 할 수 있다.
// 2번 쿼리
SELECT * FROM card WHERE list_id = 2;
// 3번의 3번째 조건 쿼리
SELECT * FROM card c JOIN board_list bl on c.list_id = bl.id WHERE bl.board_id = 93;2) 제목과 내용 기준 최적화
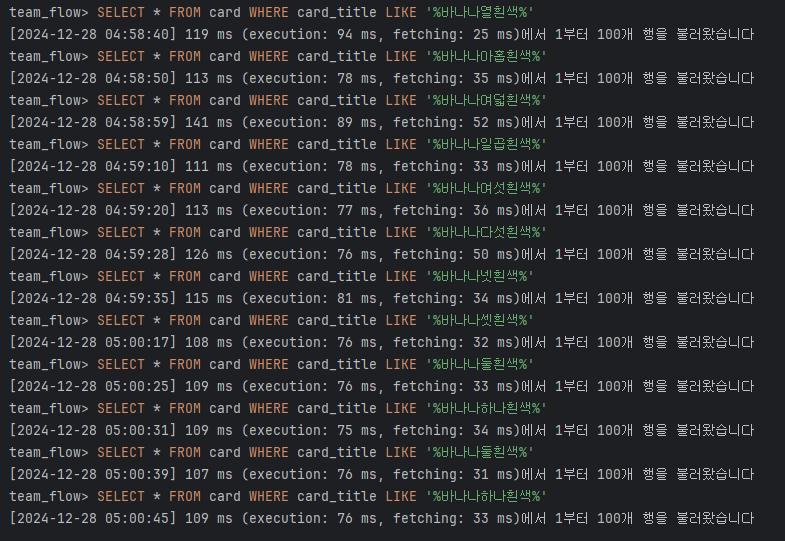
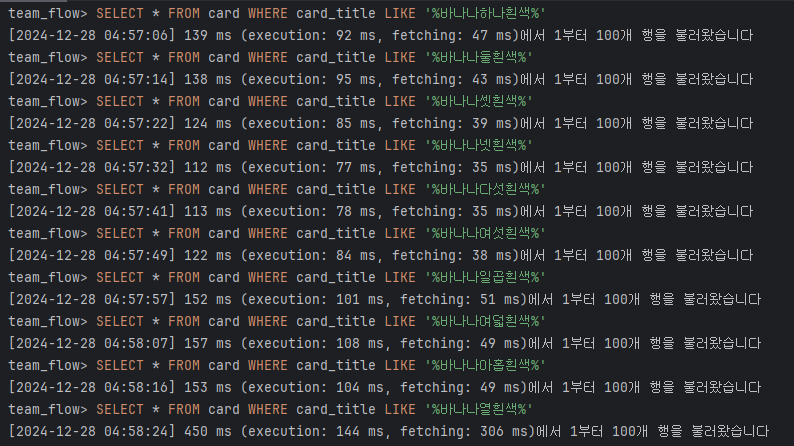
SELECT * FROM card WHERE card_title LIKE '%바나나하나회색%';위의 쿼리를 통해 조회했을 때 인덱스가 있을 때와 차이가 나지 않았고 어떤 경우에는 더 많은 시간이 소요되기도 했다. 이는 내용이 많고 수정이 자주 일어나는 컬럼이고 LIKE 문으로 조건을 확인하기 때문이라 생각된다.
-
제목 인덱스 적용 전
-
제목 인덱스 적용 후
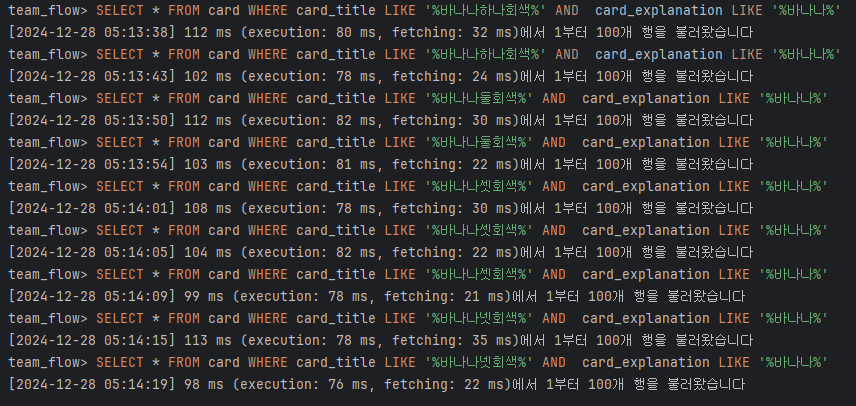
SELECT * FROM card WHERE card_title LIKE '%바나나둘회색%' AND card_explanation LIKE '%바나나%';마찬가지로 제목과 내용을 조건으로 적용해도 차이가 발생하지 않았다.
- 제목과 내용 인덱스 적용 전
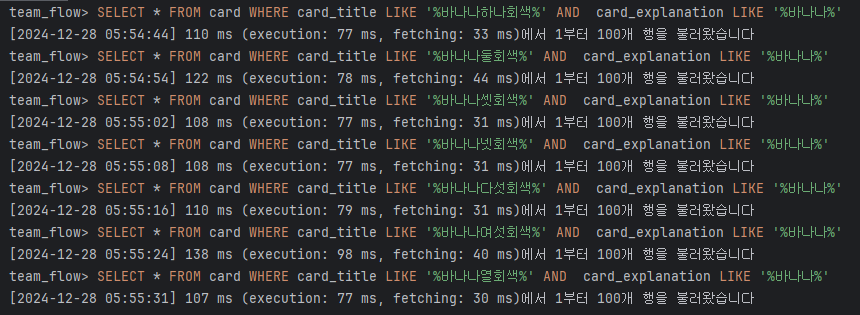
- 제목과 내용 인덱스 적용 후
3) 마감일 기준 최적화
SELECT * FROM card WHERE end_at = '2024-08-01';위의 쿼리를 통해 조회했을 때는 인덱스의 유무에 따라 엄청난 차이가 발생했다.
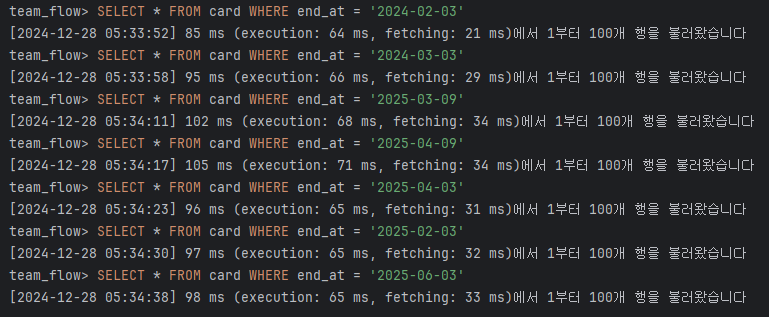
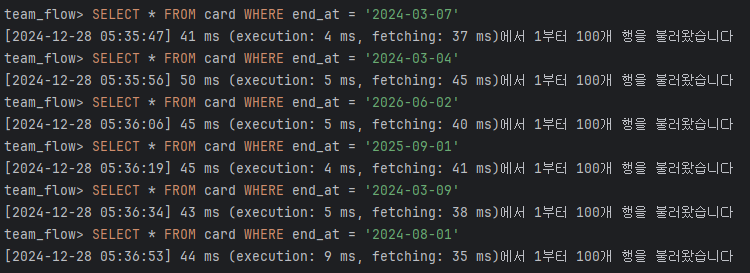
4. 결론
PK와 FK는 mysql 에서 자동으로 인덱스를 적용하여 최적화한다.
내용이 길고 수정이 많은 문자열로 이루어진 컬럼에 LIKE 문을 적용하면 오히려 성능저하가 올 수 있다.
딱 떨어지는 문자나 특정 타입의 컬럼에 인덱스를 적용하면 최적화를 할 수 있다.
오히려 많은 수의 컬럼을 인덱스에 적용하려고 하면 인덱스 테이블이 거대해져서 많은 저장공간을 차지한다.
그리고 성능도 떨어진다.
인덱스가 적용된 컬럼에 INSERT, UPDATE, DELETE가 수행된다면 원본 테이블 뿐만 아니라
인덱스에도 다음과 같이 추가 작업을 수행해줘야 하기 때문에 3가지 쿼리가 자주 발생하는 컬럼은 적용하면 안된다.
