정규화
간단 정리
정규화란 데이터를 안전하게 관리하기 위한 설계 방법이다.
제1 정규화는 한 컬럼에 하나의 데이터만 존재하도록 만드는 것이다.
제2 정규화는 제1 정규화 + 현재 테이블의 주제와 관련이 없는 컬럼을 분리(다른 테이블)하는 것이다.
제3 정규화는 제2 정규화 + 일반 컬럼에만 종속된 컬럼을 분리(다른 테이블)하는 것이다.
DB 정규화
데이터베이스 설계에서 정규화(Normalization) 는 데이터 중복을 제거하고, 데이터 무결성을 유지하며, 이상 현상(anomaly)을 방지하기 위해 사용되는 기법입니다. 이 글에서는 정규화의 기본 개념과 주요 정규형(1NF, 2NF, 3NF, BCNF 등)을 살펴보고, 실제 예제를 통해 정규화가 어떻게 적용되는지 확인해보겠습니다.
1. 정규화의 기본 개념
정규화의 주요 목적은 다음과 같습니다
데이터 중복 제거: 동일한 정보를 여러 테이블에 반복 저장하지 않아 데이터 불일치를 방지합니다.
데이터 무결성 유지: 삽입, 갱신, 삭제 작업 시 발생할 수 있는 이상 현상을 최소화합니다.
효율적인 관리: 관련 데이터를 논리적으로 분리하여 유지보수와 쿼리 성능을 개선합니다.
2. 정규형의 단계
[ 제1 정규화 ]
제1 정규화란 테이블의 컬럼이 원자값(Atomic Value, 하나의 값)을 갖도록 테이블을 분해하는 것이다. 예를 들어 아래와 같은 고객 취미 테이블이 존재한다고 하자.
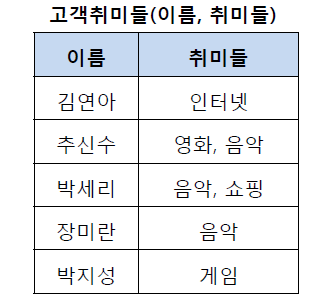
위의 테이블에서 추신수와 박세리는 여러 개의 취미를 가지고 있기 때문에 제1 정규형을 만족하지 못하고 있다. 그렇기 때문에 이를 제1 정규화하여 분해할 수 있다. 제1 정규화를 진행한 테이블은 아래와 같다.
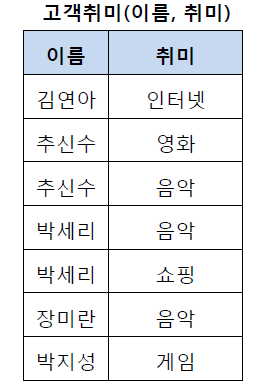
[ 제2 정규화 ]
제2 정규화란 제1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해하는 것이다. 여기서 완전 함수 종속이라는 것은 기본키의 부분집합이 결정자가 되어선 안된다는 것을 의미한다. 예를 들어 아래와 같은 수강 강좌 테이블을 살펴보자.
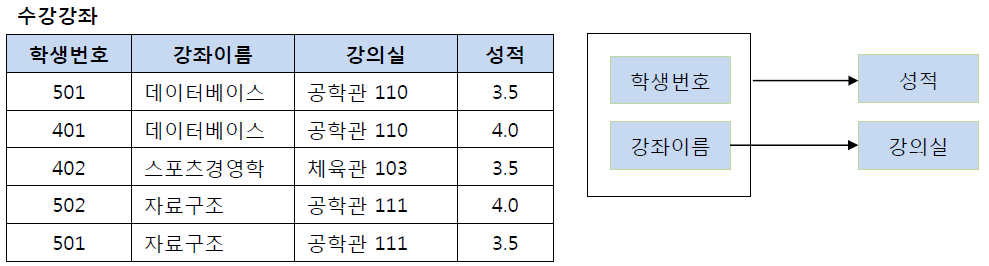
이 테이블에서 기본키는 (학생번호, 강좌이름)으로 복합키이다. 그리고 (학생번호, 강좌이름)인 기본키는 성적을 결정하고 있다. (학생번호, 강좌이름) --> (성적) 그런데 여기서 강의실이라는 컬럼은 기본키의 부분집합인 강좌이름에 의해 결정될 수 있다. (강좌이름) --> (강의실)즉, 기본키(학생번호, 강좌이름)의 부분키인 강좌이름이 결정자이기 때문에 위의 테이블의 경우 다음과 같이 기존의 테이블에서 강의실을 분해하여 별도의 테이블로 관리하여 제2 정규형을 만족시킬 수 있다.
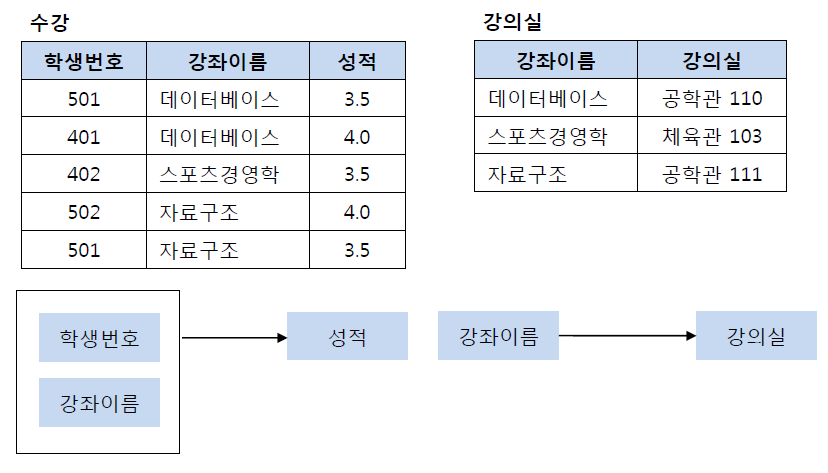
[ 제3 정규화 ]
제3 정규화란 제2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해하는 것이다. 여기서 이행적 종속이라는 것은 A -> B, B -> C가 성립할 때 A -> C가 성립되는 것을 의미한다. 예를 들어 아래와 같은 계절 학기 테이블을 살펴보자.
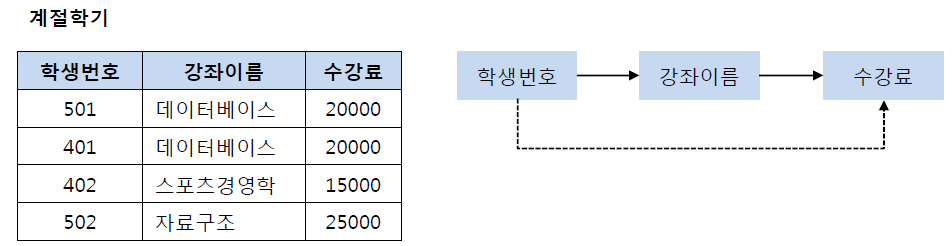
기존의 테이블에서 학생 번호는 강좌 이름을 결정하고 있고, 강좌 이름은 수강료를 결정하고 있다. 그렇기 때문에 이를 (학생 번호, 강좌 이름) 테이블과 (강좌 이름, 수강료) 테이블로 분해해야 한다.
이행적 종속을 제거하는 이유는 비교적 간단하다. 예를 들어 501번 학생이 수강하는 강좌가 스포츠경영학으로 변경되었다고 하자. 이행적 종속이 존재한다면 501번의 학생은 스포츠경영학이라는 수업을 20000원이라는 수강료로 듣게 된다. 물론 강좌 이름에 맞게 수강료를 다시 변경할 수 있지만, 이러한 번거로움을 해결하기 위해 제3 정규화를 하는 것이다. 즉, 학생 번호를 통해 강좌 이름을 참조하고, 강좌 이름으로 수강료를 참조하도록 테이블을 분해해야 하며 그 결과는 다음의 그림과 같다.
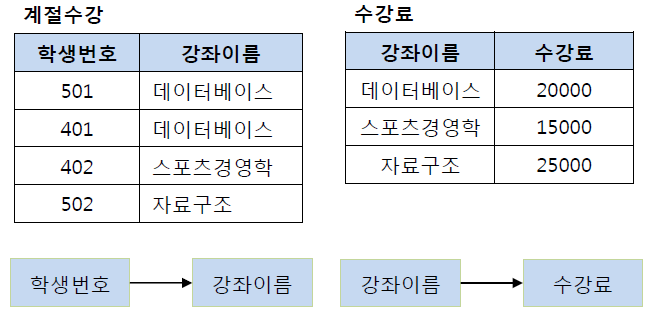
[ BCNF 정규화 ]
BCNF 정규화란 제3 정규화를 진행한 테이블에 대해 모든 결정자가 후보키가 되도록 테이블을 분해하는 것이다. 예를 들어 다음과 같은 특강수강 테이블이 존재한다고 하자.
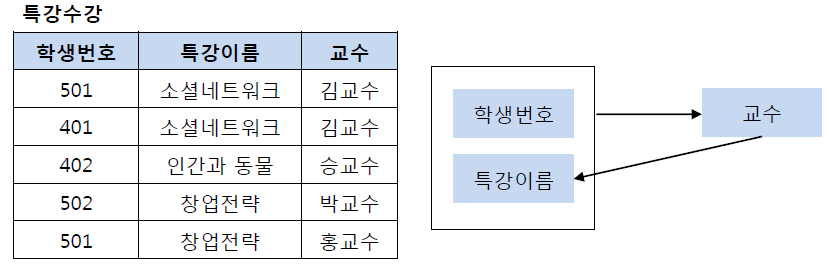
특강수강 테이블에서 기본키는 (학생번호, 특강이름)이다. 그리고 기본키 (학생번호, 특강이름)는 교수를 결정하고 있다. 또한 여기서 교수는 특강이름을 결정하고 있다. 그런데 문제는 교수가 특강이름을 결정하는 결정자이지만, 후보키가 아니라는 점이다. 그렇기 때문에 BCNF 정규화를 만족시키기 위해서 위의 테이블을 분해해야 하는데, 다음과 같이 특강신청 테이블과 특강교수 테이블로 분해할 수 있다.
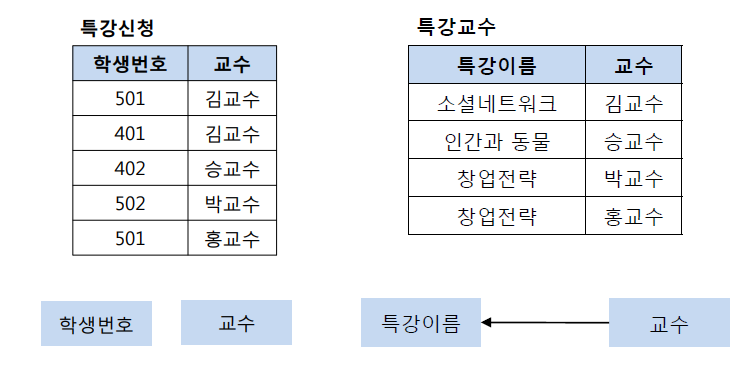
3. 실무 적용 예제: 주문 관리 시스템
아래는 주문 관리 시스템에서의 비정규화된 테이블을 정규화하는 과정을 보여주는 예제입니다.
3.1 비정규화된 테이블 구조
CREATE TABLE Orders (
OrderID INT,
CustomerName VARCHAR(100),
ProductID INT,
ProductName VARCHAR(100),
Quantity INT,
PRIMARY KEY (OrderID, ProductID)
);이 구조에서는 고객 정보와 상품 정보가 하나의 테이블에 함께 저장되어 데이터 중복 및 업데이트 이상 현상이 발생할 수 있습니다.
3.2 정규화된 테이블 구조
고객과 상품 정보를 별도의 테이블로 분리하여 2NF와 3NF를 만족시키는 예제입니다.
고객 테이블
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
CustomerName VARCHAR(100)
);상품 테이블
CREATE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(100)
);주문 및 주문 상세 테이블
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
OrderDate DATE,
FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID)
);
CREATE TABLE OrderDetails (
OrderID INT,
ProductID INT,
Quantity INT,
PRIMARY KEY (OrderID, ProductID),
FOREIGN KEY (OrderID) REFERENCES Orders(OrderID),
FOREIGN KEY (ProductID) REFERENCES Products(ProductID)
);이 구조를 통해 고객 정보와 상품 정보가 별도의 테이블로 분리되며, 데이터의 중복 저장을 방지하고, 각 테이블의 수정 및 유지보수가 용이해집니다.
4. 정규화의 장단점
장점
데이터 무결성 보장
업데이트 이상(삽입, 삭제, 갱신) 최소화
효율적인 데이터 관리
단점
조인(Join) 연산 증가로 인한 성능 저하 가능성
복잡한 쿼리로 인한 관리 어려움
과도한 정규화 시 오히려 성능 저하 우려
장점: 데이터의 중복을 제거하여 무결성을 높이고, 변경 시 발생할 수 있는 이상 현상을 줄입니다.
단점: 여러 테이블로 분리되어 데이터를 조회할 때 조인이 많이 필요하므로 성능 저하가 발생할 수 있으며, 상황에 따라 일부 의도적인 비정규화(Denormalization)가 필요할 수 있습니다.
결론
데이터베이스 정규화는 데이터 중복 제거와 무결성 유지를 위한 핵심 설계 기법입니다.
실무에서는 정규화와 비정규화 사이의 균형을 잘 맞추어 최적의 데이터베이스 성능을 확보하는 것이 중요합니다.
위의 예제와 같이, 비정규화된 데이터를 정규화하면 데이터의 일관성과 관리 효율성이 향상됩니다.
필요에 따라 SQL 코드와 마크다운 표 예시를 참고하여 자신의 시스템에 맞는 최적의 구조를 설계해 보시기 바랍니다.
출처: https://mangkyu.tistory.com/110 [MangKyu's Diary:티스토리]
