
이전 글
- [PintOS project] 1. Part 1: Threds - Priority Donation
https://velog.io/@takealittletime/PintOS-project-1.-Part-1-Threds-Priority-Donation
00. 4.4 BSD like Scheduler
- 4.4 BSD(Berkeley Software Distribution) Scheduler는 Multilevel-Feedback-Queue의 구성으로, 여러 개의 우선순위 큐로 구성되며, 각 큐는 다른 우선순위를 가진다.
00-1. MLFQ에 대해
- 본격적인 구현에 앞서, MLFQ에 대해 요점만 간단하게 짚고 넘어가자.
MLFQ (MultiLevel-Feedback-Queue)의 구현 이유
- 짧은 작업을 먼저 실행시켜 반환 시간을 최적화
반환시간: (작업 완료 시간) - (작업 도착 시간)- 응답 시간을 최적화 (대화형 사용자가 응답을 바로 받을 수 있도록)
응답 시간: (작업 시작 시간) - (작업 도착 시간)
- 쉘과 같은 대화형 동작에서, 응답 시간이 빨라야 컴퓨터를 쓸 맛이 날 것이다.
만약, 내가 어떤 실행을 하기 위해 명령어를 입력했는데 앞의 동작들 때문에 실행을 기다려야 한다면 불편할 것이다.
MLFQ 요약
- MLFQ는 우선 순위 별로 각각의 큐를 가지고, 아래의 규칙들을 따르는 스케줄링 기법이다.
규칙 1. 우선순위 (A) > 우선순위(B) 일 경우, A가 실행, B는 실행되지 않는다.
규칙 2. 우선순위(A) = 우선순위(B), A와 B는 RR(Round-Robin) 방식으로 실행된다.
규칙 3. 작업이 시스템에 들어가면 최상위 큐에 배치된다.
규칙 4. 작업이 지정된 단계에서 배정받은 시간을 소진하면(CPU를 포기한 횟수와 상관없이), 작업의 우선순위는 감소한다. (즉, 한 단계 아래 큐로 이동한다.)
규칙 5. 일정 주기 S가 지난 후, 시스템의 모든 작업을 최상위 큐로 이동시킨다.
01. 구현에 필요한 추가 자료구조
- MLFQ를 구현한다면 결국 필요한 작업은?
- Priority에 따라 여러 개의 Ready Queue를 만든다. →"Multi-Level"
- Priority를 실시간으로 조절한다. →"Feedback"
- 우리는 여태까지 우선순위를 기준으로 스케줄링 하도록 작업 했으므로, 2번 특징(Feedback)의 구현만 추가하면 mlfq를 기능적으로 구현할 수 있다.
우선, 구현을 위해 추가해주어야 하는 자료구조들이 있다.
01-1. nice
- 해당 스레드가 다른 스레드에게 얼마나 CPU를 양보하는지 나타내는 척도
Nice한 스레드일 수록 다른 스레드에게 CPU를 많이 양도할 것! NICE_MIN = -20,NICE_DEFAULT = 0,NICE_MAX = 20(클수록 많이 양보)- 이 수치가 높으면 priority가 줄어들게 된다.
01-2. load_avg
- 모든 스레드가 공유하는 공유 변수. (실수값)
- 최근 1분 동안 수행 가능한 스레드의 평균 개수.
즉, 현재 시스템이 얼마나 혼잡한지, '부하'를 나타내는 척도! = 몇 개의 스레드가 CPU를 놓고 경쟁하고 있는가? - 해당 동작을 실행할 때 실행되고 있거나 ready 상태에 있는 스레드의 개수를 나타내는 변수
idle 스레드는 개수에서 제외한다! - 초기값은 0으로 세팅.
load_avg = (59/60) * load_avg + (1/60) * ready_threads
01-3. recent_cpu
- 해당 Thread가 CPU를 점유하고 있는 tick수.
- 이 수치가 높으면 priority가 줄어들게 된다.
위와 같은 자료 구조를 이용해 각 스레드들의 우선순위를 결정하고, 특정 tick 마다 스레드들의 우선순위를 새로 계산한다!
→ 스레드가 무한정 대기하는 상황을 방지한다.
01-4. 간단한 예제 시나리오
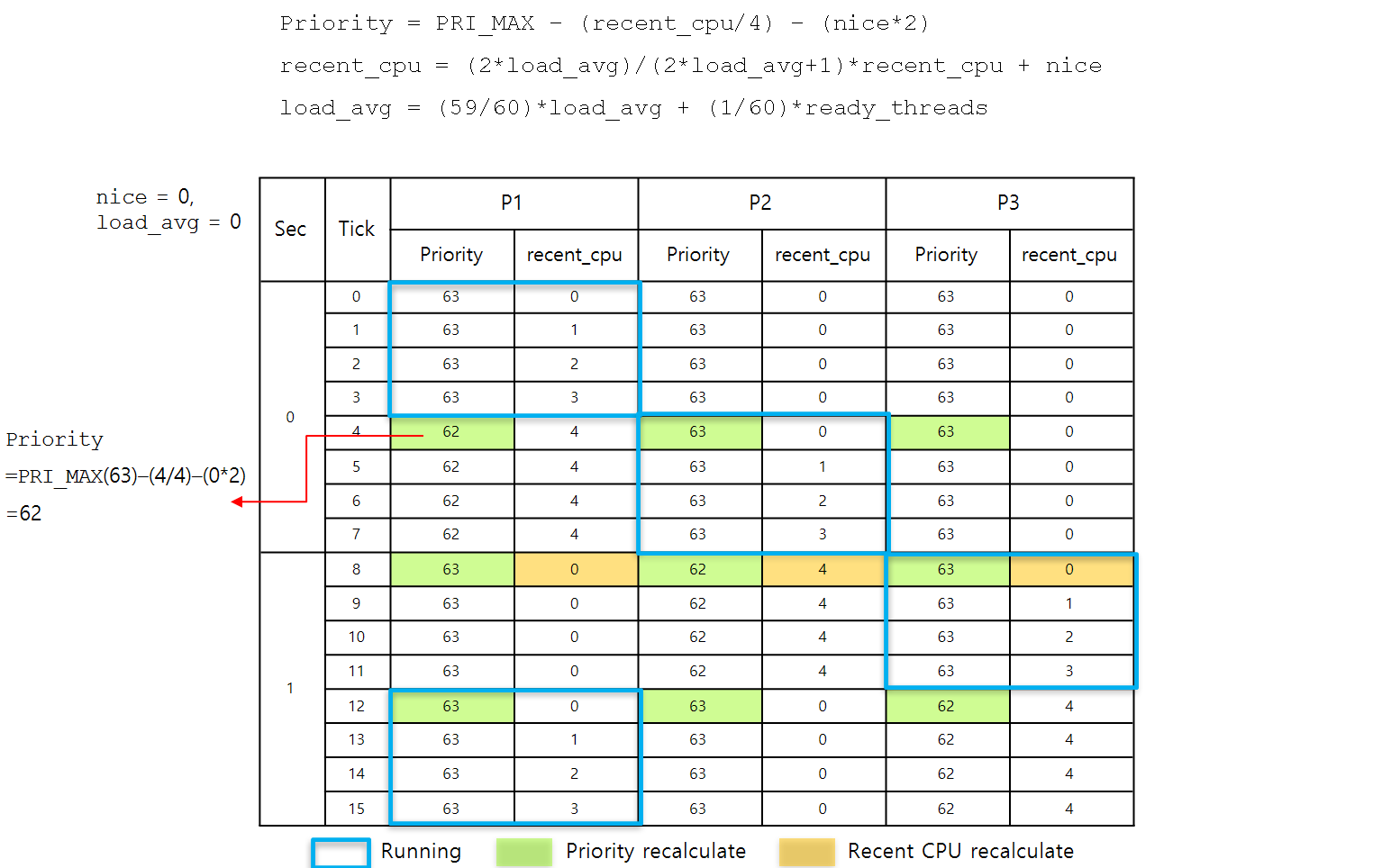
-
현재 ready_list에 P1, P2, P3 스레드가 존재한다.
-
load_avg (현재 실행되고 있거나 ready 상태에 있는 thread의 개수)는 3이다.
-
Tick = 0 일 때)
- 세 스레드의 우선순위가 같으므로 RR 방식으로 스레드 P1을 실행
-
Tick = 1 ~ 4 일 때 )
- 현재 실행 중인 스레드 P1은 recent_cpu 값이 1씩 증가
-
Tick = 4 일 때)
- 전체 스레드의 우선순위 재계산
priority = PRI_MAX - (recent_cpu/4) - (nice*2)
- priority가 재계산 되어 P2의 우선순위 > P1의 우선순위 상황이 되어 P2가 실행됨.
- P1은 가장 낮은 우선순위를 가지며 ready_list에서 맨 뒤에 삽입 됨.
- 전체 스레드의 우선순위 재계산
-
Tick = 5 ~ 8 일 때 )
- 현재 실행 중인 스레드 P2는 recent_cpu 값이 1씩 증가
-
Tick = 8 일 때 )
- 전체 스레드의 우선순위 재계산
priority = PRI_MAX - (recent_cpu/4) - (nice*2)
- priority가 재계산 되어 P3의 우선순위 > P1의 우선순위 상황이 되어 P3가 실행됨.
아까 실행되었던 P1은 ready_list에서 맨 뒤에 있으므로.
- 전체 스레드의 우선순위 재계산
-
~~ 이어서 반복)
- 위와 같이 4 tick 마다 우선순위가 재계산 되며 스레드들이 스케줄링 됨.
02. 고정소수점 연산 구현

-
커널에서는 정수 연산만 지원하고, 소수 연산은 지원하지 않는다.
-
위에서
recent_cpu와load_avg는 실수값을 가지므로, 고정 소수점 연산을 따로 구현해주어야 한다.

- 아래와 같이 헤더 파일로 작성했다.
/* include/threads/fixed_point.h */
#define F (1 << 14)
#define INT_MAX ((1 << 31) - 1)
#define INT_MIN (-(1 << 31))
// int 형 정수 ->고정 소수점 형식으로 반환
int int_to_fp(int n){
return n * F;
}
// 고정 수수점 -> 정수로 변환
int fp_to_int (int x){
return x / F;
}
// 고정 소수점 -> 반올림 -> 정수로 변환
int fp_to_int_round (int x){
if (x>=0)
return (x+F/2)/F;
else
return (x-F/2)/F;
}
// 두 고정 소수점 값 더하기
int add_fp (int x, int y){
return x + y;
}
// 두 고정 소수점 값 빼기
int sub_fp (int x, int y){
return x - y;
}
// 고정 소수점 값 + 정수 값
int add_mixed (int x, int n){
return x + n * F;
}
int sub_mixed(int x, int n) {
return x - n * F;
}
// 두 고정 소수점 값 나누기
int mult_fp (int x, int y){
return ((int64_t) x) * y / F;
}
// 고정 소수점 값 * 정수 값
int mult_mixed (int x, int n){
return x * n;
}
// 두 고정 소수점 값 나누기
int div_fp (int x, int y){
return ((int64_t) x) * F / y;
}
// 고정 소수점 값 / 정수 깂
int div_mixed (int x, int n) {
return x / n;
}- 헤더 파일로 작성했으니,
thread.c에서 아래와 같이 헤더 파일을 추가해 사용해주도록 세팅한다.
/* threads/thread.c */
#include "threads/fixed_point.h"03. MLFQ 구현
03-1. all_list 추가
-
all-list? 현재 시스템에 존재하는 모든 스레드를 저장하는 전역 리스트.
-
위에서 보았듯,
load_avg등 스레드의 우선순위를 실시간으로 재계산하는데 필요한 척도들을 계산할 때, 현재 시스템에 존재하는 모든 스레드들에 대한 계산이 필요해진다.
→ 이전까지 구현했던 스케줄링에서는running중인 스레드,ready_list의 스레드,sleep_list의 스레드등 현재 시스템에 있는 스레드들이 각자 따로 놀고 있기 때문에 계산하기 복잡하다.
→all_list로 이를 한꺼번에 관리해 계산을 편학 하자! -
all_list를 다음과 같이 선언한다.
/* threads/thread.c */
// ready_list, sleep_list 총괄 리스트
struct list all_list;- thread 구조체에도 위에서 필요했던 변수들과 함께
all_elem을 선언해준다.
/* threads/thread.c */
struct thread {
...
/* nice값: 클수록 CPU 양보 ↑ */
int nice;
/* 해당 스레드가 최근 얼마나 많은 CPU time을 사용 했는지 */
int recent_cpu;
...
/* all_list에서 사용할 list_elem */
struct list_elem allelem;
...
};
- 위의 요소들을 새로 만들어 주었으니, 각
init함수에서 초기화를 해주어야 할 것이다.
/* threads/thread.c*/
void
thread_init (void) {
/* Init the globla thread context */
...
list_init(&all_list);
...
}
- 우선,
thread_init함수에서 위와 같이all_list를 초기화 한다.
/* threads/thread.c */
static void
init_thread (struct thread *t, const char *name, int priority) {
...
// advanced_scheduler의 구현을 위해 아래 코드들 추가
t->nice = NICE_DEFAULT;
t->recent_cpu = RECENT_CPU_DEFAULT;
...
list_push_back(&all_list, &t->allelem);
}init_thread()함수에도 위와 같이 초기화 하는 내용을 추가한다. 스레드의 초기화가 끝나면 해당 스레드를all_list에 삽입한다.
※ 주의
-
all_list는 현재 실행 중 스레드, ready 중인 스레드, blocked 상태인 스레드들을 포함하는 리스트이기 때문에, 하나의 스레드가 종료되었다면all_list에서 삭제처리를 해주어야 한다. -
이는
thread_exit()함수에 다음과 같이 추가해준다.
/* threads/thread.c */
void
thread_exit (void) {
ASSERT (!intr_context ());
#ifdef USERPROG
process_exit ();
#endif
/* Just set our status to dying and schedule another process.
We will be destroyed during the call to schedule_tail(). */
intr_disable ();
list_remove(&thread_current()->allelem);
do_schedule (THREAD_DYING);
NOT_REACHED ();
}- 필자는 이 과정을 생각지 못해서 몇 시간을 날려가며 Trouble Shooting을 했다.
03-2. priority, recent_cpu, load_avg에 대한 계산 함수 작성
- 위에서 개념적으로 설명했던 자료구조들에 대해 계산해주는 함수를 구현해주면 된다.
/* threads/thread.c */
// mlfqs:: 스레드의 priority를 계산하는 함수
void
mlfqs_calc_priority (struct thread *t)
{
if ( t == idle_thread)
return;
t->priority = fp_to_int (add_mixed (div_mixed(t->recent_cpu, -4), PRI_MAX - t->nice * 2));
if (t->priority > PRI_MAX) t->priority = PRI_MAX;
if (t->priority < PRI_MIN) t->priority = PRI_MIN;
}
// mlfqs:: 스레드의 recent_cpu 값을 계산하는 함수
void
mlfqs_calc_recent_cpu (struct thread *t)
{
if (t == idle_thread)
return;
t->recent_cpu = add_mixed (mult_fp (div_fp (mult_mixed (load_avg,2),add_mixed(mult_mixed(load_avg, 2),1)),t->recent_cpu),t->nice);
}
// load_avg 값을 계산하는 함수
void
mlfqs_calc_load_avg ()
{
int ready_threads;
if (thread_current() == idle_thread)
ready_threads= list_size (&ready_list);
else
ready_threads = list_size (&ready_list) + 1;
load_avg = add_fp(mult_fp(div_fp(int_to_fp(59), int_to_fp(60)),load_avg), mult_mixed(div_fp(int_to_fp(1), int_to_fp(60)), ready_threads));
}
// 1 tick 마다 running 스레드의 recent_cpu 값 + 1
void
mlfqs_incr_recent_cpu ()
{
if (thread_current() != idle_thread)
thread_current()->recent_cpu = add_mixed (thread_current()->recent_cpu, 1);
}
// 4 tick 마다 모든 스레드의 recent_cpu 값 재계산
void
mlfqs_recalc_recent_cpu()
{
struct list_elem *e;
for ( e = list_begin(&all_list); e!=list_end(&all_list); e = list_next(e)) {
struct thread * t = list_entry(e,struct thread, allelem);
mlfqs_calc_recent_cpu(t);
}
}
// 4 tick 마다 모든 스레드의 load_avg 값 재계산
void
mlfqs_recalc_priority ()
{
ASSERT(intr_context());
struct list_elem *e;
bool need_yield = false;
for (e = list_begin(&all_list); e != list_end (&all_list); e = list_next(e)) {
struct thread *t = list_entry(e, struct thread, allelem);
mlfqs_calc_priority(t);
}
// priority의 변화가 일어났으므로, ready_list를 정렬하고, 재스케줄링함.
list_sort(&ready_list, cmp_thread_priority, NULL);
if (!list_empty(&ready_list) && thread_current()->priority<list_entry(list_front(&ready_list),struct thread, elem)->priority)
{
intr_yield_on_return();
}
}03-3. timer_interrupt() 수정
- 위에서 개념론적으로 설명했던 바와 같이,
priority,recent_cpu,load_avg값을 특정 tick 마다 계산하도록 수정한다.
/* devices/timer.c */
/* Timer interrupt handler. */
static void
timer_interrupt (struct intr_frame *args UNUSED) {
ticks++;
thread_tick ();
if (thread_mlfqs) {
mlfqs_incr_recent_cpu();
if (ticks % 4 == 0){
mlfqs_recalc_priority();
if (ticks % TIMER_FREQ == 0){
mlfqs_recalc_recent_cpu();
mlfqs_calc_load_avg();
}
}
}
// 매 timer_interrupt 마다 대기 중인 스레드 깨우기
thread_awake(ticks);
}
03-4. priority donation 기능 비활성화
- mlfq에서는 priority donation 기능을 사용하지 않기 때문에, 각 함수에서 donation에 대한 핸들링을 하지 않도록 수정해야 한다.
/* threads/synch.c */
void
lock_acquire (struct lock *lock)
{
if (thread_mlfqs) {
sema_down (&lock->semaphore);
lock->holder = thread_current ();
return ;
}
...
}
void
lock_release (struct lock *lock)
{
lock->holder = NULL;
if (thread_mlfqs) {
sema_up (&lock->semaphore);
return ;
}
...
}thread_set_priority ()함수도 비활성화 해준다.
/* threads/thread.c */
void
thread_set_priority (int new_priority)
{
if (thread_mlfqs)
return;
...
}03-5. 마지막으로, pintOS에 미리 정의되어 있는 함수들을 채워주자.
/* threads/thread.c */
void thread_set_nice (int);
int thread_get_nice (void);
int thread_get_load_avg (void);
int thread_get_recent_cpu (void);- 주의해야 할 점은, 각 함수 내에서 값을 핸들링 할 때 인터럽트를
disable해 준 상태에서 실행해야 한다는 것이다.
/* threads/thread.c */
void
thread_set_nice (int nice UNUSED)
{ // 현재 스레드의 nice 값을 새 값으로 설정
enum intr_level old_level = intr_disable ();
thread_current ()->nice = nice;
mlfqs_calculate_priority (thread_current ());
thread_test_preemption ();
intr_set_level (old_level);
}
int
thread_get_nice (void)
{ // 현재 스레드의 nice 값을 반환
enum intr_level old_level = intr_disable ();
int nice = thread_current ()-> nice;
intr_set_level (old_level);
return nice;
}
int
thread_get_load_avg (void)
{ // 현재 시스템의 load_avg * 100 값을 반환
enum intr_level old_level = intr_disable ();
int load_avg_value = fp_to_int_round (mult_mixed (load_avg, 100));
intr_set_level (old_level);
return load_avg_value;
}
int
thread_get_recent_cpu (void)
{ // 현재 스레드의 recent_cpu * 100 값을 반환
enum intr_level old_level = intr_disable ();
int recent_cpu= fp_to_int_round (mult_mixed (thread_current ()->recent_cpu, 100));
intr_set_level (old_level);
return recent_cpu;
}04. 실행 결과
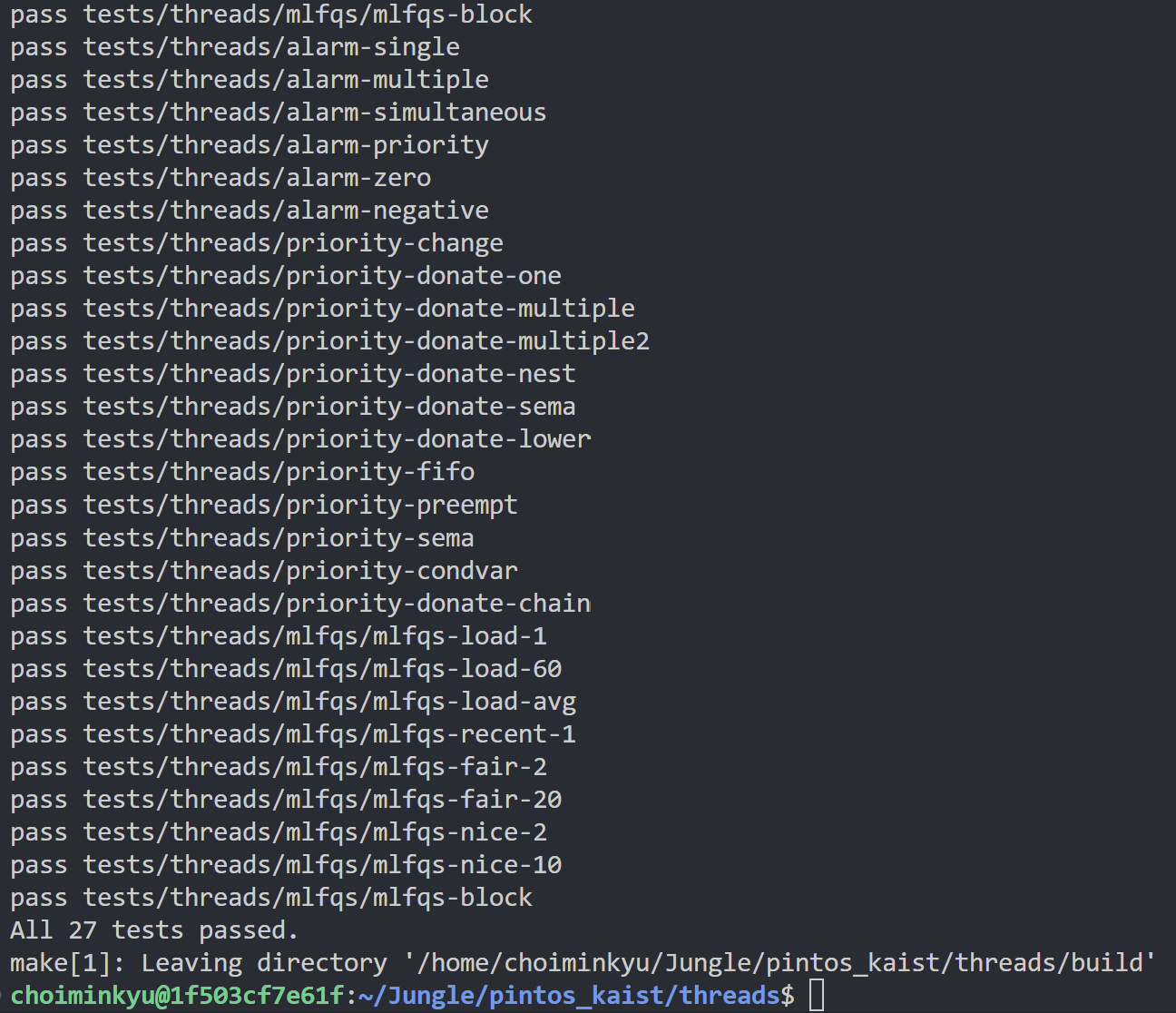
threads상에 있는 모든 테스트 케이스들에 대해pass를 확인할 수 있다!
05. Trouble Shooting과 회고
05-1. Trouble Shooting
- 위에서도 언급했듯,
mlfq의 구현 도중 스레드들의 개수를 용이하게 핸들링하기 위해all_list라는 자료구조를 이용한다. 이 때, '스레드가 종료되면 리스트에서 삭제해 주어야 한다'는 것을 잊으면mlfq와 관련된 테스트 케이스를 통과할 수가 없다.
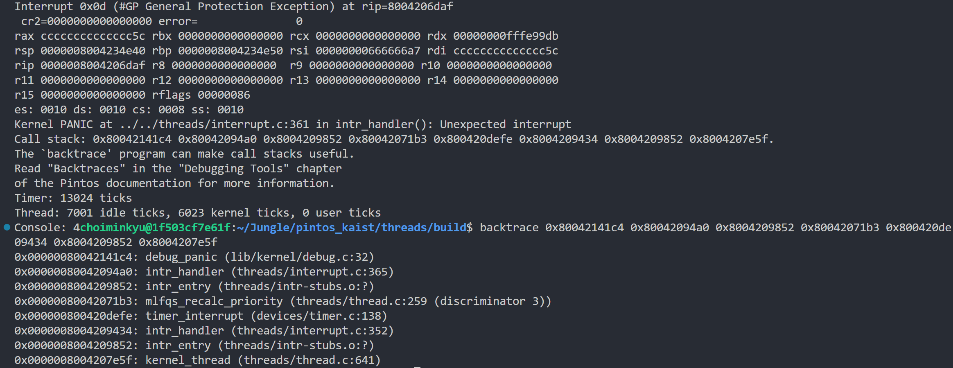
-
절망적인 것은, 마치
interrupt상에서 오류가 발생한 것처럼 보여지기 때문에, 출력을 보고 디버깅을 하게 되면 애먼 곳만 수정하게 된다. -
backtrace로 이전 콜스택을 확인해서도mlfqs_recalc_priority()함수 부분에서 문제가 발생한 것을 확인하고, 이 부분만 내내 붙잡고 있었다. 🥲 -
어떠한 자료구조나 자원을 새로 정의하고 이용할 때는 해당하는 자원의 flow에 대해 한 번 더 고민하고 코드를 작성할 필요가 있는 것 같다.
05-2. PintOS 1주차 회고
-
처음에는 그저 막막하기만 했던 PintOS의 1주차가 지나갔다. 새벽 2시 이전에 잠 든 날이 없는 것 같다.
그만큼 애도 먹었지만, 굉장히 뿌듯하고 재밌었던 경험이 아닐 수 없다. -
OS라는 것은 마치 우리가 숨을 쉬며 살지만 '공기'라는 것을 크게 인식하지 못하고 살 듯 컴퓨터를 사용하면서 어쩌면 당연하게만 느꼈던 것 같다.
이러한 OS를 직접 다뤄본다니.
사람이 숨을 쉬면서 공기를 직접 다뤄봐야겠다는 생각은 잘 안하지 않는가? 나에게는 그 정도의 생소함 이었다.
스레드, 프로세스, 우선순위, 선점, 스케줄링... 학부 때 개념론적으로만 학습하고 '아, 이런 것들이 있구나.' 하고 넘어갔을 때와 지금은 그 이해의 깊이 자체가 달라진 기분이다.
- 이렇게 거대한 프로젝트를 받아서, 어떤 부분 부분들을 수정해가며 기능을 구현한다는 것 자체가 처음 해 보는 경험이었다. 마치 무인도에 갑자기 표류되었는데, 무엇부터 해야할지 모르겠고 막막했다.
하지만 1주차가 지나가는 현 시점에는 이를 헤쳐나갈 자신감이 생겼다.
이런 경험이 나중에 개발자 생활을 하는데에 있어 어떤 생소한 프로젝트를 핸들링 할 때 도움이 되지 않을까, 싶다.
참고 자료 / 이미지 출처
-
KAIST:OSLAB:Pintos Slides
-
(KraftonJungle Day61) MLFQS
https://scientific-string-9e5.notion.site/KraftonJungle-Day61-MLFQS-13863eaa993080b693e3d6a9fde76702
-
[Pintos] Project 1 : Thread(스레드) - Advanced Scheduler (mlfqs)
https://poalim.tistory.com/36
