
그림과 같은 코드를 작성하던 중, 이런 의문이 들었다.
내가 만든 기준모델이 회귀 모델의 최소 기능을 수행한다고 확신할 수 있는 근거는 무엇일까?
내가 틀린 모델을 만든거면 어떻게 해? 이 불안을 해소할 수 있을 만큼의 지식은 필요해!
그래서 회귀 모델의 원리와 '최소 성립 요건'이 무엇인지를 얕게 공부했다.
이 글은 머신러닝 5일차 병아리가 작성했다. 따라서 나보다는 잘하는 듯 보이는 이분의 글을 거의 리믹스 수준으로 많이 참고했다. https://brunch.co.kr/@gimmesilver/65
아래의 글은 공부한 내용을 내가 이해한 흐름대로 정리한 것으로, 원래의 뜻에서 왜곡된 내용들이 있을 가능성이 매우 높다. '정제된 지식'보다는 '초보의 필기 노트'로 봐주시기를.
🤨 그래서, 회귀모델이 뭔데?
회귀 분석은 평균이 전체를 대표할 수 있는 상황이라고 가정 하고, 조건부 평균을 구하는 기법입니다. 따라서, 회귀 모델이 적절한 대푯값이 되려면 대상 데이터의 분포가 종 모양이어야 합니다.(평균이 전체를 대표하는 값이 되려면 평균과 중앙값, 최빈값이 서로 거의 일치해야 하는데, 그렇게 되는 분포는 종 모양 분포니까요.)
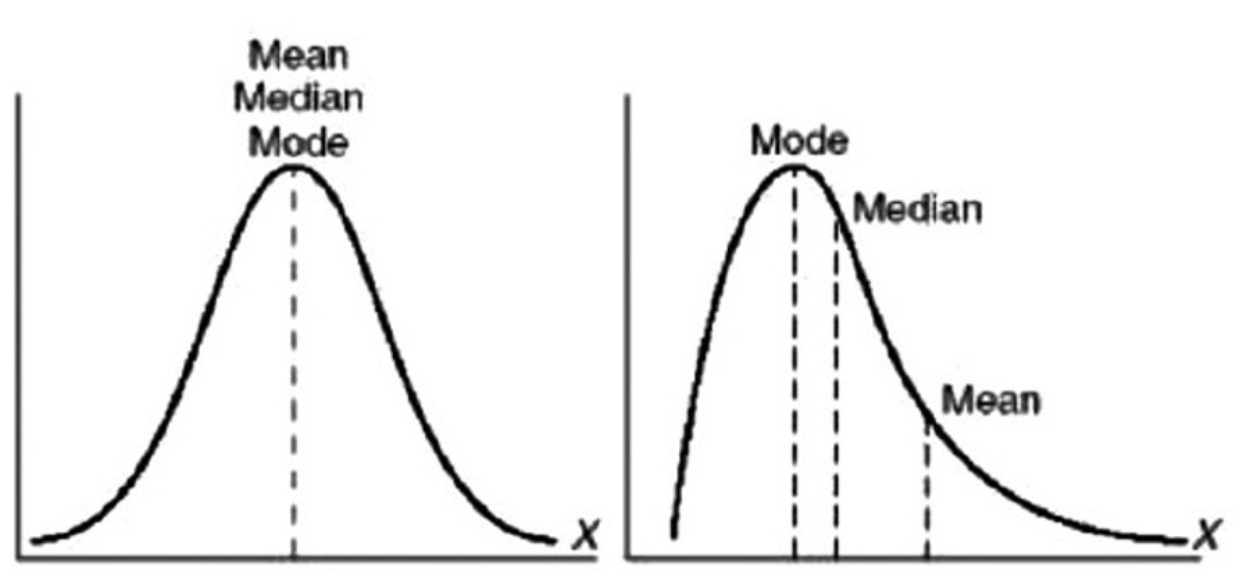 출처: https://brunch.co.kr/@gimmesilver/65
출처: https://brunch.co.kr/@gimmesilver/65
🙄 그럼, 회귀모델은 그냥 평균을 구하면 나오는거야?
그런데 회귀 모형은 그냥 전체 집단의 평균이 아니라 조건부 평균이기 때문에 분포를 확인할 때도 전체 분포가 아닌 조건별 분포를 확인해야 합니다. 왜 조건부 평균이냐면, 회귀 분석을 통해 얻게 되는 회귀 모형이 의미하는 것은 x(예컨대 Speed) 에 따라 달라지는 y(예컨대 Distance)의 조건별(x값별) 평균이기 때문입니다. 즉, 같은 x를 갖는 y들끼리만 모여 만들어진 분포가 각각의 x값마다 존재하는 모습입니다. 때문에 회귀 모형에서 구한 평균이 적절한지 확인하려면 같은 조건(x혹은 speed)을 갖는 값(y 혹은 distance)들의 분포가 모두 종형 분포인지를 봐야 하는 것이죠.
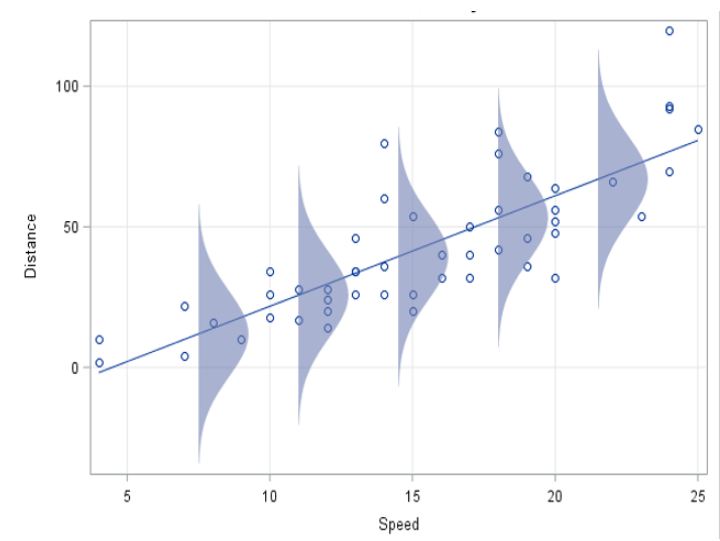
출처:https://blogs.sas.com/content/iml/2015/09/10/plot-distrib-reg-model.html
😣 좀 더 풀어서 설명해줘!
Y축에 있는 Distance 는 평균 측정이 되는 타겟 변수이고, X축에 있는 Speed는 Distance의 변화에 영향을 주는 요인 변수입니다. 따라서 회귀 분석을 통해 얻게 되는 회귀 모형이 의미하는 것은 Speed 에 따라 달라지는 Distance의 조건별 평균입니다. 때문에 이 평균이 적절한지 확인하려면 같은 speed 조건을 갖는 distance 값들의 분포가 종형 분포인지를 봐야 하는 것이죠.
😶 그걸 어떻게 봐?
그걸 다 보는 것은 때로는 비효율적입니다. 그래서 일단 먼저 회귀 모형을 만든 후 이 모형을 통해 계산한 평균값과 실제 관측값 사이의 차이값에 대한 분포를 확인합니다.. 이 차이값의 분포는 중심이 평균이냐 아니면 0이냐의 차이만 있을 뿐 원래 데이터의 조건별 분포와 형태가 비슷하기 때문입니다 (좀 더 엄밀히 얘기하자면, 조건별 분포들이 모두 '정규 분포' 인 경우에 그렇습니다).
"그러니 이 차이값의 분포가 종형 분포라면, 우리가 만든 회귀 모형의 평균값들은 원래 데이터를 잘 대표할 것이라고 생각할 수 있습니다. "
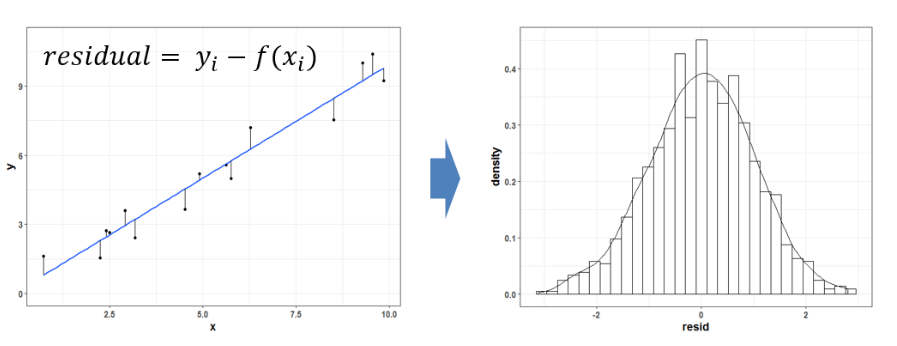
출처: https://brunch.co.kr/@gimmesilver/65
💡 그럼, 기준모델은 잔차 분포가 종형 분포로 나오면 되는거야?
저는 그렇게 봅니다. 그런 의미에서 맨 처음에 보았던 코드를 다시 볼까요?
#회귀 모델을 위한 기준 모델을 만들기 위해 작성한 코드
y_target = homes[target]
mean = y_target.mean()
baseline = [mean] * len(homes)
mae = mean_absolute_error(y_target, baseline)타겟 시리즈(실측치)와 타겟 시리즈의 평균값만으로 채운 시리즈(회귀 모델의 예측치 역할)간의 차이(잔차)는 정규분포가 될테니까..아마도! 기준 모델로 사용하기에 적합할 것 같군요.
✍ 그래도! 꼭 기억할 것.
잔차에 대한 가정들을 만족하지 못한다고 해서 회귀 분석이 불가능한 것은 아님! 실제 데이터 분석을 해보면 위 가정들을 만족시키기가 대단히 어렵고, 그러한 가정들을 모두 만족하는 모델은 거의 없다.
여러 가정들을 만족하지 못하더라도 회귀 분석을 할 수 있으며, 다만 그렇게 해서 구한 회귀 모델의 신뢰도는 다소 낮을 수 있을 뿐이다. 때문에 내가 분석한 결과가 얼마나 신뢰할만한 수준인지를 파악하기 위해 위 가정을 잘 만족하는지 확인하는 과정(모델 검정)이 꼭 필요하다.
나름대로 열심히 썼지만 사실 이 글에서 맞는 설명이 몇 퍼센트가 될지는 확신하지 못하겠다.
하지만 이렇게 7개월 공부하다보면 점점 사실에 가까운 글을 쓰게 되지 않을까?
현재의 나에게 가장 와닿았던 문장으로 마무리!
'잔차가 정규 분포가 되도록 회귀 모형을 만들어야 모형이 데이터에 잘 적합한 것이다'
