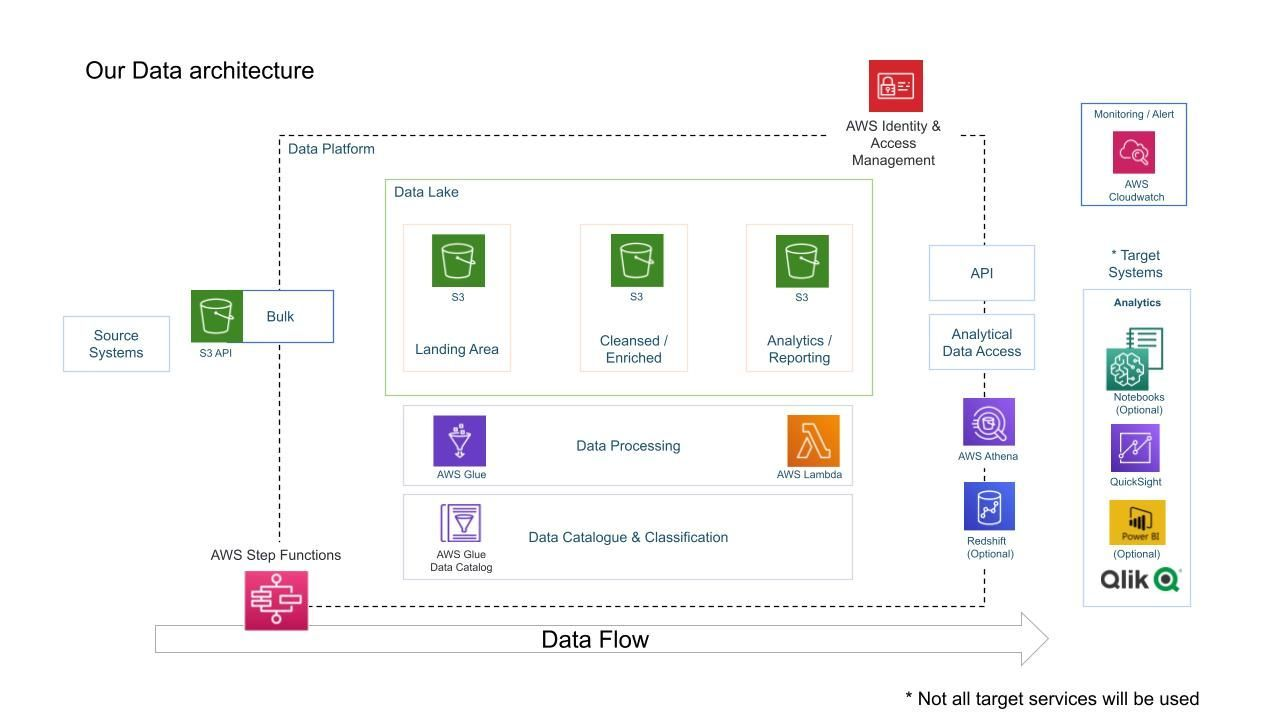
[1] Project Architecture
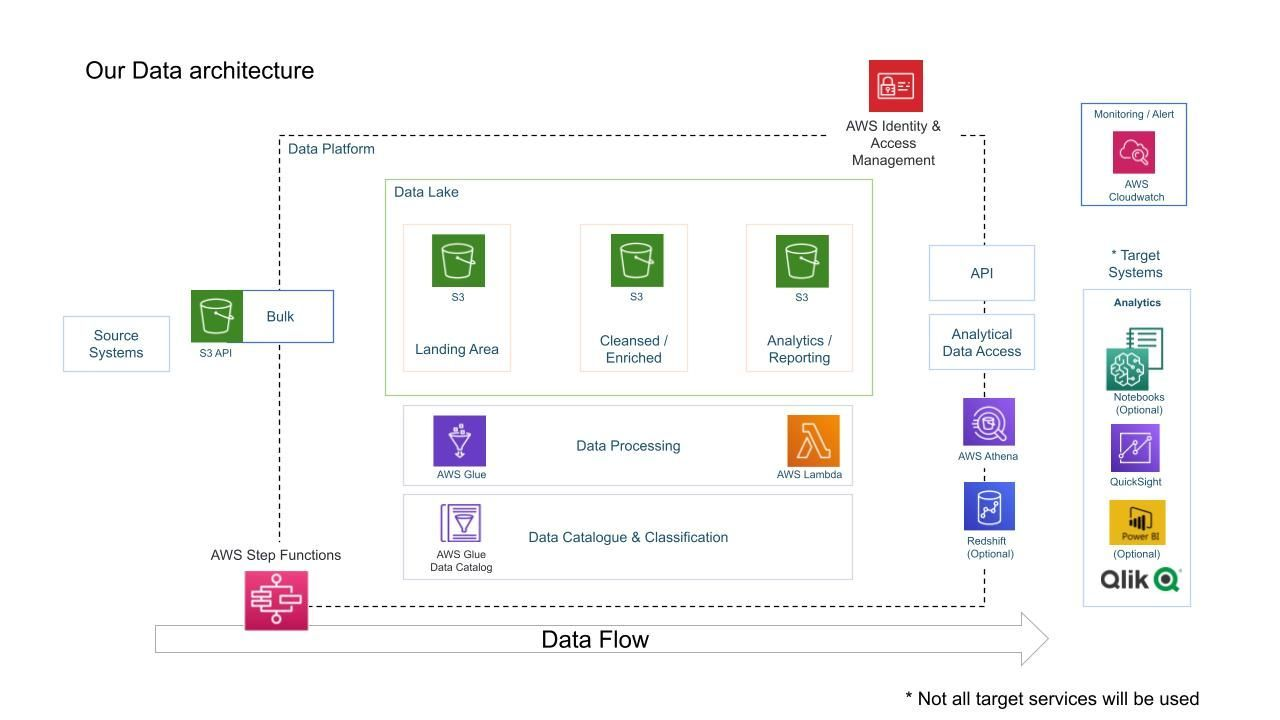
[2] 사용한 AWS 서비스
- AWS Glue
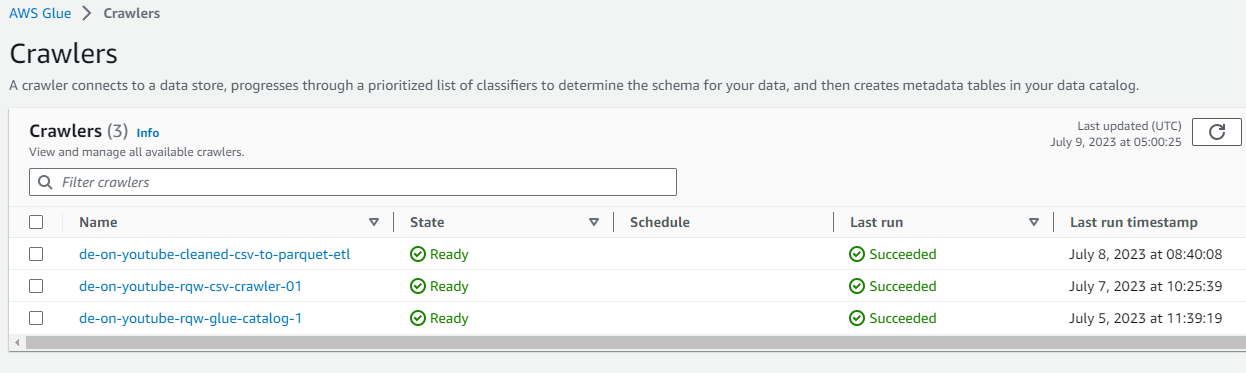
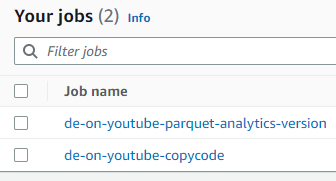
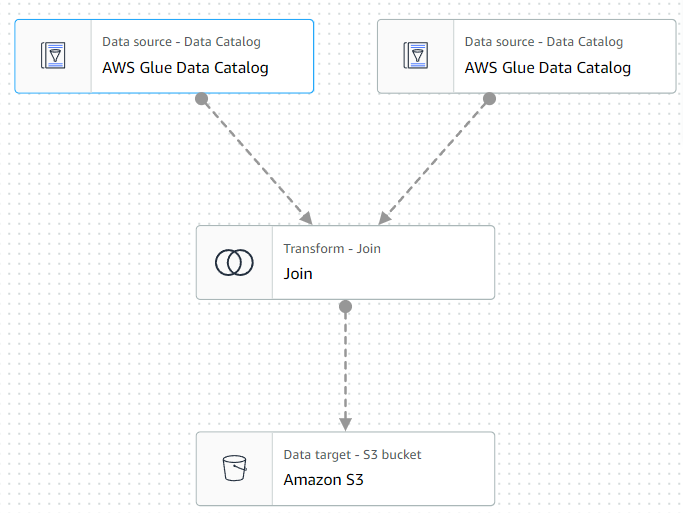
- Crawler를 통해 Data catalog 생성과 Job을 이용한 다양한 작업에 사용.
- Glue Job을 통한 S3 버킷에서 버킷으로 데이터 형식 변환과 이동을 동시에 진행.
- Athena 없이 테이블을 JOIN하여 분석을 위한 데이터를 생성하는 ETL 작업.
- AWS S3
- Data Lake
- raw data, cleansed data, data for analytics로 세개의 버킷을 생성해 사용.
- AWS IAM
- 프로젝트 전용 사용자 생성 및 Glue, Lambda등을 위한 role 생성
- AWS Lambda
- 람다 함수의 trigger 기능을 이용한 데이터 적재 자동화
- QuickSight
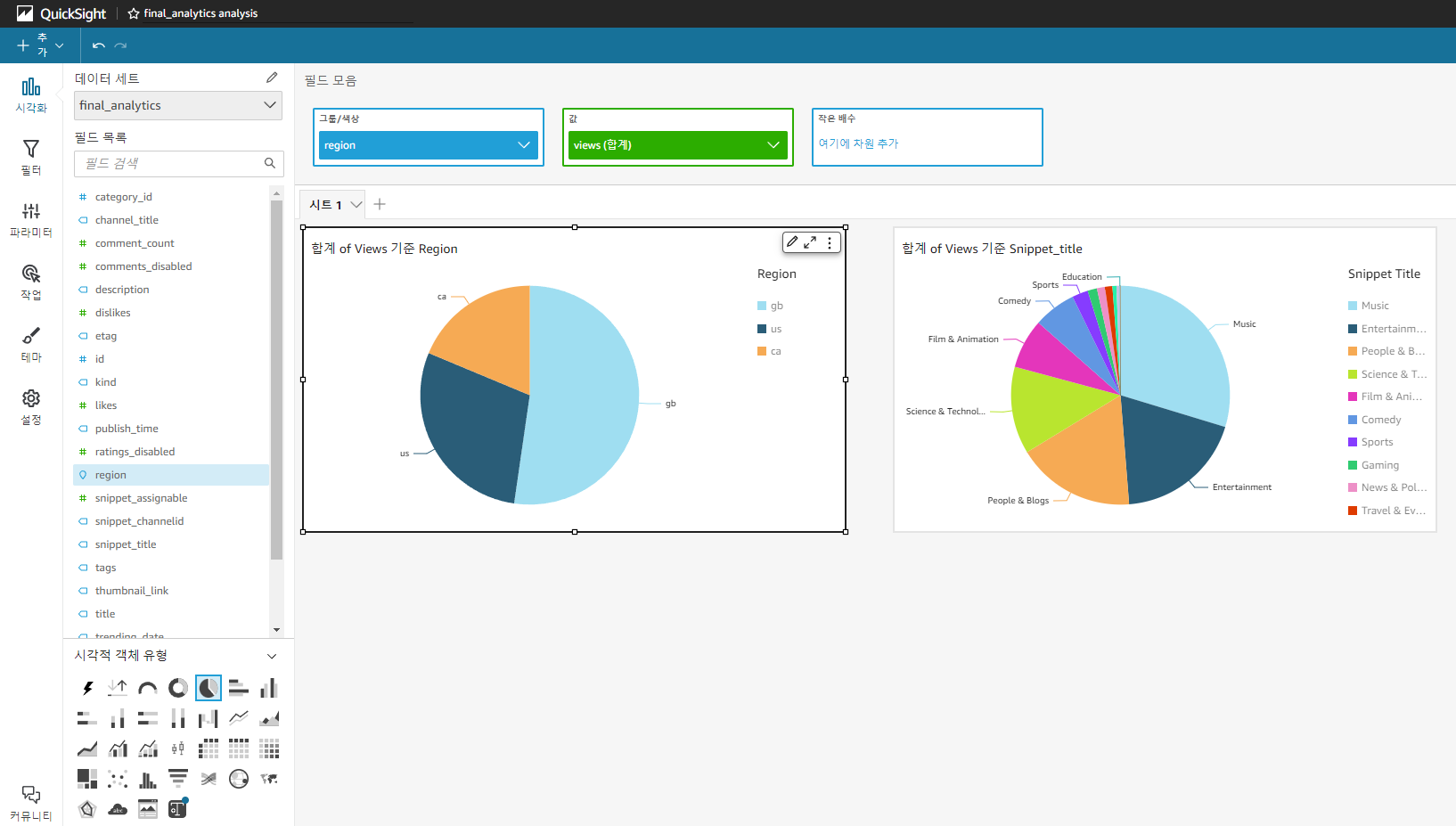
- 최종적인 데이터 분석을 위한 그래프 생성
- AWS Athena
- 데이터베이스 생성 및 내부 테이블 데이터 확인
[3] Trouble Shooting
-
Lambda - no module named 'awswrangler'
lambda layer에 AWSSDKPandas를 추가하여 해결 -
Lambda - timeout
구성 > 일반 구성에서 시간 변경(3초 > 5분)
구성 > 일반 구성에서 메모리 변경(128 > 256) -
Lambda - glue에 대한 permission 부족
IAM에서 lambda용으로 생성한 role에 GlueServiceRole permission 추가 -
Glue Job - AccessDenied 403 Error
존재하지 않는 폴더에 write dynamic dataframe했다. S3에서 폴더를 생성 -
Glue Job - Cannot phrase JP.csv
데이터에 한자, 히라가나, 한글 등 machine level로 분해할 수 없는 데이터가 포함되어있음.
1) sys.setdefaultencoding("utf-8")
Python 3에서는 더이상 지원하지 않음
2) #-- coding: utf-8 --
해결되지 않음
3) 영어 데이터만 존재하는 region으로 pushdown하여 진행
Visual ETL로 Job을 생성하면 사용 불가. 대신 Spark Script Editor로 생성하면 됨! -
Glue Job - EntityNotFoundException
데이터베이스 / 테이블 / S3 버킷 이름 등을 다시 확인, 오타 수정
[4] 간단 회고
-
Glue Job을 진행할 때 phrase문제로 인해 3개의 region에 대해서만 데이터를 준비하고, 분석한 것이 아쉽다. 한자, 러시아어, 히라가나 등의 데이터에 대해 인코딩이 되지 않을 땐 많이 막막했지만, 직접 pyspark 스크립트를 짜보는 경험을 할 수 있었다.
-
1년 전 프로젝트를 따라한 것이라 AWS에 편리한 기능이 있음에도 사용하지 않은 부분이 아쉽다. 처음 S3에 데이터를 업로드 할때도 AWS CLI 없이이 S3 버킷에 PC파일을 직접적으로 업로드 할 수 있는데 tutorial을 따라한다고 굳이 CLI에 명령어를 사용해서 비효율적으로 진행한 것 같아 아쉽다.
-
AWS 서비스만 사용해서 아쉬웠다. 한 곳에서 해결된다는 장점도 있지만, 한 곳에 갇혀있는 것 같다는 느낌도 들었다. 데이터도 Kaggle에서 데려와 그대로 사용한 것 뿐이라 다음에는 다른 방식으로 데이터를 얻어와 사용해보고 싶다.
-
사소하긴 한데, S3 버킷을 생성할 때 region-unique한 이름을 지으려다가 오타를 낸 것이 아쉽다. 나중에는 raw와 rqw를 헷갈려서 비효율적인 시간낭비가 많았던 것 같다..
Reference List
https://youtu.be/yZKJFKu49Dk
https://youtu.be/qFaaKme5eDE
https://www.kaggle.com/datasets/datasnaek/youtube-new
https://github.com/darshilparmar/dataengineering-youtube-analysis-project
