Introduction
데이터 엔지니어링에 관심을 가지게 된지는 꽤 됐지만, 관련된 프로젝트는 하나도 해본 적이 없었다. 데이터 분석에 관한 프로젝트에 대한 경험조차 전무했고 어떻게 시작해야할지 고민하고 있던 중에 괜찮은 프로젝트를 하나 발견해서 실행해보았다.
Youtube Trending 비디오에 대한 데이터들을 잘 정제하고 분석까지 해볼 수 있는 프로젝트이다. 1년 전 비디오기도 하고, 영어로 진행된 프로젝트라서 사실 완벽하게 따라하기는 쉽지 않았지만, 결과를 낼 수 있어서 굉장히 뿌듯했다.
두 파트로 나누어서 포스팅 할 예정이다. 중간에 사용된 개념들에 대해서는 설명을 최대한 줄이고, 내가 어떻게 실행했는지와 데이터 엔지니어링 프로젝트를 해보고 싶어 이 글을 보러 온 사람들을 위해서 글을 써보려고 한다.
Part 1
References
https://youtu.be/yZKJFKu49Dk
https://github.com/darshilparmar/dataengineering-youtube-analysis-project
0. Our dataset from YouTube
Top Trending Videos
- Trending: 단순히 많은 조회수를 얻은 비디오를 의미하는 것이 아니라, 조회수나 공유수, 댓글과 좋아요와 같은 요소들을 전부 사용하여 선정된 비디오를 말한다.
- Data Source: Kaggle, YouTube API를 사용하면서 모은 Data
- Category: 국가(region), 채널ID, 동영상 Title 등
What is AWS?
Cloud Platform의 선두주자라고 볼 수 있다. 아래의 그림은 2021년까지 AWS가 11년 연속 "Cloud leader" 였다는 것을 보여주는 그림이다. 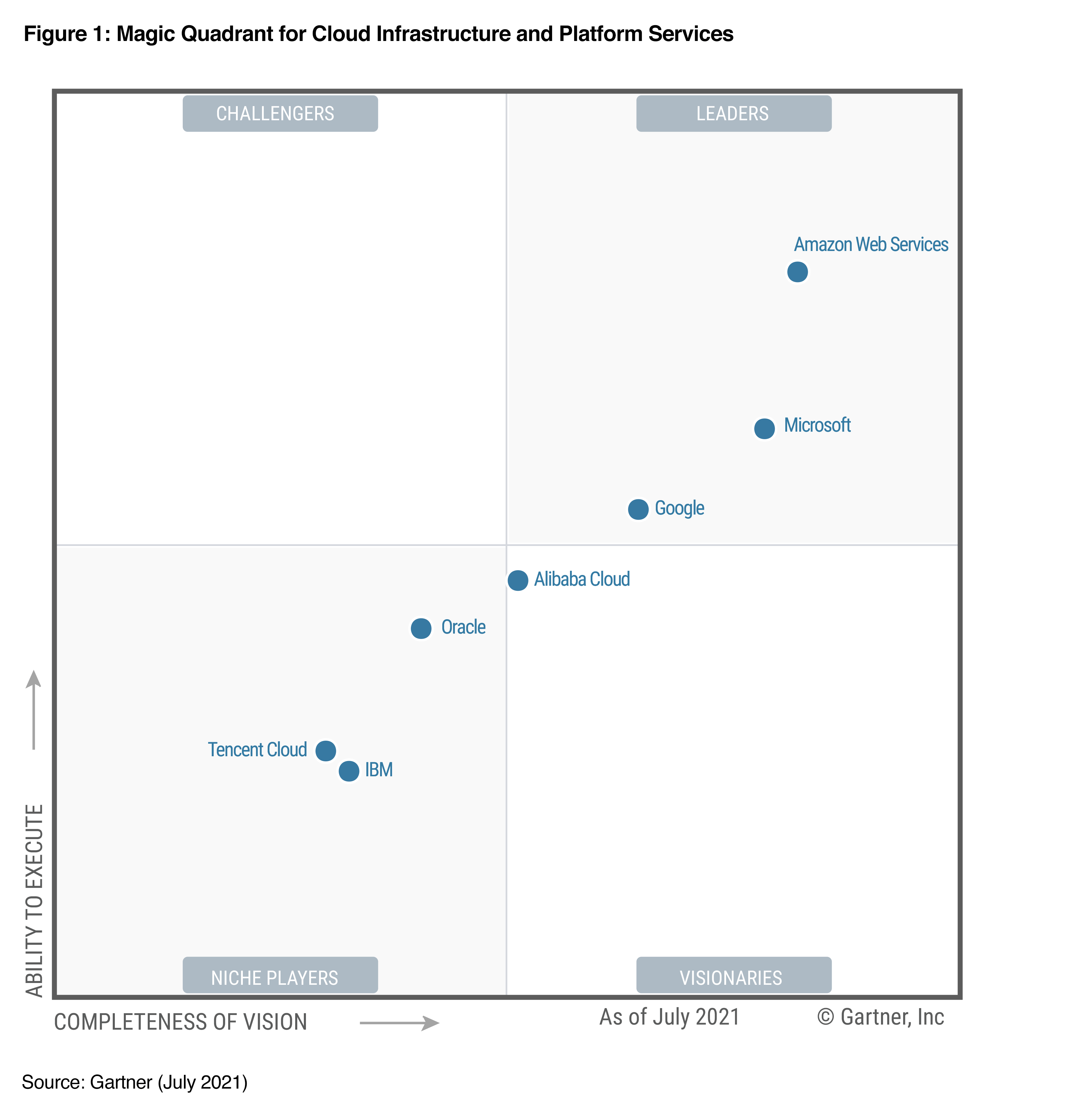
200개 이상의 서비스를 제공하며 AI, ML, Data lake, Compute, Pipeline Build 등 제공하지 않는 서비스가 없는 편이다.
이번 프로젝트는 주로 이 AWS 위에서 이루어질 예정이므로 혹시라도 계정이 없는 사람은 꼭 만들어야 한다. 대부분 무료로 이용 가능하지만, 시간이나 사용량에 따라 요금이 부과될 수 있다. 이에 대해서는 자세히 다루지 않겠지만, 나는 AWS Glue를 이용하면서 6천원 정도 청구됐다...
1. Create an IAM user and IAM group for this training
IAM이란 "Identity access management"의 약자로 AWS에서 제공하는 서비스의 일종이다. root 계정을 보호하기 위한 서브 계정을 생성할 수 있다. root 계정이 가지고 있는 permission보다 적은 수를 가지는 서브 계정을 만들어서 사용할 것이다.
IAM 계정 생성하기
1) AWS Console에서 "IAM"을 검색
2) "사용자 추가"로 사용자를 생성
3) "AdministratorAccess"에 대한 권한 부여
4) 생성 완료
개인 비밀번호 생성과 csv파일 다운로드까지 해야 한다. 이후 로그인된 계정에서 로그아웃하고, csv 파일을 확인해 새로 생성한 IAM 계정으로 로그인한다. 겉으로 보기엔 root계정과 다를 바가 없지만, 요금 청구서를 확인할 수 없는 등 root 계정보다는 제한적인 permission을 가지고 있다.
2. Install AWS CLI
AWS Command Line Interface(CLI)이고 이를 이용해 데이터 업로드, command 실행 등을 할 예정이므로 꼭 다운받도록 하자.
Window, MacOS, Linux 등 다양한 OS를 지원하고 있고, 나는 Window 상에서 진행했다. 다운로드한 파일의 지침을 따라서 install을 완료하고 나면 cmd에서 설치가 잘 되었는지 확인한다.
이후 CLI에 아까 생성한 IAM 계정을 이용해 로그인을 할 예정인데, 이때 Access Key라는 것이 필요하다. 이는 IAM 계정으로 콘솔에 로그인 한 후 "보안 자격 증명" 에 들어가면 발급할 수 있다. CLI 사용 목적으로 설정하고 csv파일 다운로드까지 한다.
CLI에서 IAM 로그인
1) cmd로 돌아와서 "aws configure" 실행
2) csv를 참고하여 Access Key와 Secret Access Key를 모두 입력
3) region은 "us-east-1"로 입력
4) Default output format은 아무것도 입력하지 않고 enter를 입력
region을 한국이 아닌 us-east-1으로 입력한 이유는 한국에서는 지원하지 않지만, us-east-1에서는 지원하는 설정을 사용하기 위함이다.
3. Steps to get our data
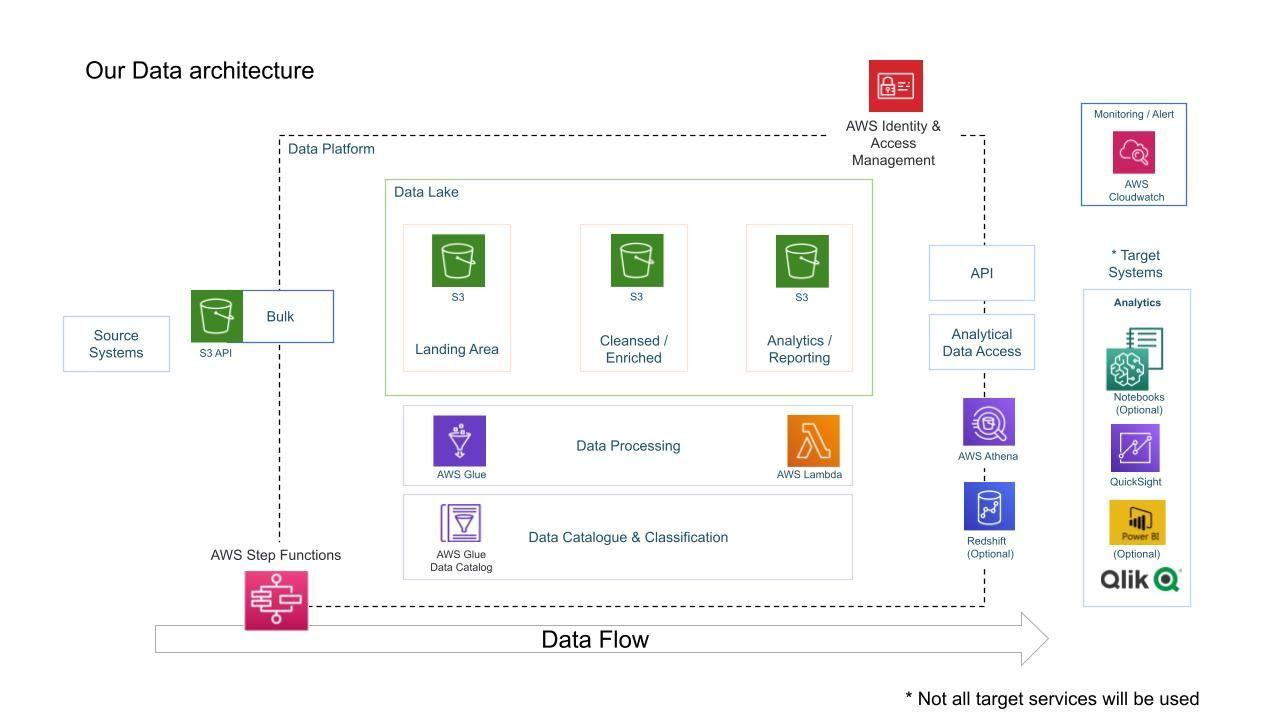
Kaggle에서 다운로드한 데이터는 CLI를 이용해 Amazon S3 bucket에 넣을 것이다. 위의 아키텍쳐 그림에서 "Landing Area"를 생성할 것이다.
S3 Bucket 생성
1) AWS Console에서 "S3" 검색
2) "버킷 만들기"
3) 적당한 이름 지어주기*
4) 다른 설정은 건드리지 않고 그대로 생성
*이때 버킷의 이름은 region 내에서 unique해야하기 때문에 자신의 이름이나 프로젝트 이름을 넣으면 좋다. 주의할 점은 지금 생성하는 버킷에 담겨있는 것은 raw data라는 것을 알 수 있게끔 이름을 지어야 한다는 것이다.
S3 Bucket에 데이터 업로드
S3 Bucket에 업로드 할 때는
1) Kaggle에서 데이터 다운로드
2) 다운로드한 데이터 압축 해제
3) cmd창에서 데이터가 존재하는 디렉토리로 이동 (cd 명령어 사용)
4) 다음의 커맨드 입력
aws s3 cp . s3://[버킷이름]/youtube/raw_statistics_reference_data/ --recursive --exclude "*" --include "*.json"눈치챘는지 모르겠지만, 위의 커맨드는 .json파일만을 업로드한다. 나머지 csv파일들은 region에 따라서 서로 다른 폴더에 저장되도록 할것이다.
aws s3 cp CAvideos.csv s3://[버킷이름]/youtube/raw_statistics/region=ca/
aws s3 cp DEvideos.csv s3://[버킷이름]/youtube/raw_statistics/region=de/
aws s3 cp FRvideos.csv s3://[버킷이름]/youtube/raw_statistics/region=fr/
aws s3 cp GBvideos.csv s3://[버킷이름]/youtube/raw_statistics/region=gb/
aws s3 cp INvideos.csv s3://[버킷이름]/youtube/raw_statistics/region=in/
aws s3 cp JPvideos.csv s3://[버킷이름]/youtube/raw_statistics/region=jp/
aws s3 cp KRvideos.csv s3://[버킷이름]/youtube/raw_statistics/region=kr/
aws s3 cp MXvideos.csv s3://[버킷이름]/youtube/raw_statistics/region=mx/
aws s3 cp RUvideos.csv s3://[버킷이름]/youtube/raw_statistics/region=ru/
aws s3 cp USvideos.csv s3://[버킷이름]/youtube/raw_statistics/region=us/S3에 youtube라는 폴더 아래에 모든 데이터가 업로드 되었음을 확인할 수 있다.
이제 다음 단계를 진행하기 전에 이해해두면 좋은 개념들을 잠깐만 정리해보려고 한다.
What is a Lake House architecture
Data lake란 중앙 집중화된 일종의 저장소인데, 이곳에 우리의 데이터를 업로드 할 수 있다. 음성 파일, 비디오, 텍스트등 모든 종류를 한곳에 저장할 수 있다. Data lake를 이용해서 Data warehouse도 만들고, ML model relational database 등의 다양한 것을 만들 수 있다.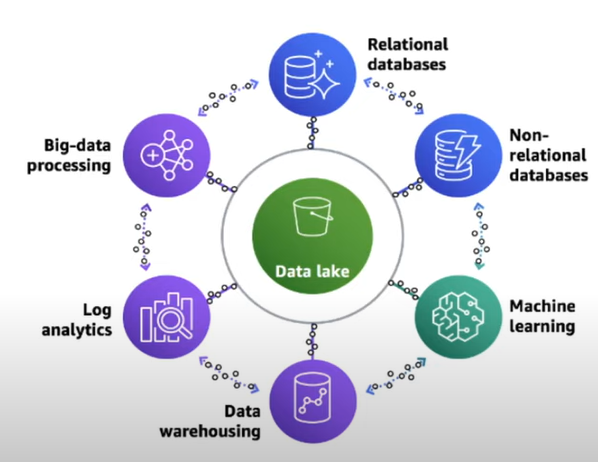
What is the AWS Glue Catalog
"Glue"는 AWS가 제공하는 서비스의 일종으로 이를 이용하면 쉽게 데이터 크롤링을 할 수 있다. 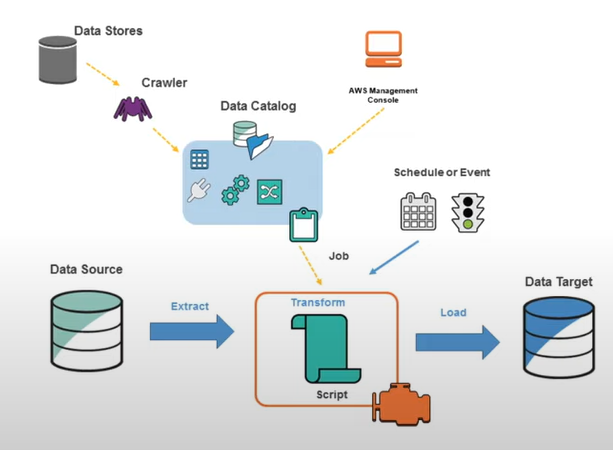
Relational Database가 있을 때 이를 crawl하고 data catalog를 생성할 수 있다. Data catalog는 데이터의 기본적인 정보들과 무엇을 포함하고 있는지를 나타낸다. 예를 들어 데이터가 15개의 columns를 가진다면, data catalog에 이 정보가 들어가는 것이다.
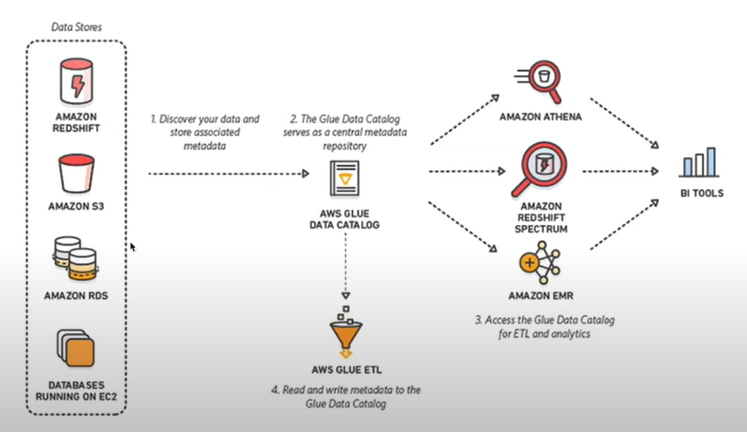
AWS Glue는 다수의 sources에서 data를 찾고, metadata를 추출하여 glue catalog를 생성한다. 이 위에서 우리는 ETL을 할 수 있게 된다.
4. Get ready for Glue
AWS Glue의 Crawler를 이용해서 Data catalog를 생성할 것이다.
1) Console에서 "Glue" 검색
2) Crawlers 선택
3) Data source는 reference 폴더를 선택
이후 IAM role을 선택하라고 나오는데, 우리는 생성해둔 IAM role이 없기 떄문에 (생성한 것은 IAM 사용자 뿐이다) Glue 권한을 가지는 role을 새로 하나 만들어 줘야 한다. 여기에서 role을 지정해주는 이유는 glue가 s3에 대한 직접적인 권한이 없기 때문이다. 정리하자면 Glue에게 S3에게 접근할 수 있는 권한을 주기 위함이다.
IAM 메뉴로 돌아가서 역할(혹은 role)로 들어가 새로 하나 생성해준다. 이때 사용 목적은 Glue고, 권한에는 S3FullAccess를 선택하고 생성을 완료한다. 생성 완료된 새로운 role에 들어가서 한 가지 permission을 추가해줄 것이다. 바로 AWSGlueServiceRole이다. 최종적으로 우리가 생성하는(사용할) role은 AWSGlueServiceRole과 AmazonS3FullAccess 2개에 대한 권한을 가지고 있어야 한다.
이후 지침을 따라 다음을 선택하다 보면 DB를 선택해야 한다. 우리는 아직 생성해둔 것이 없으므로 ADD DB로 새로 생성할 것이다. 적당히 이름을 지어 한 개 생성하고 선택해준다. 이제 Glue Crawler 생성이 끝났다.
Crawler 선택 화면에서 생성한 Crawler를 선택하고 RUN 시켜준다. 이제 크롤러는 우리의 S3에 저장되어있는 정보들에 접근해 Glue catalog를 만들어 줄 것이다. 작업이 다 끝나면 크롤러는 자동적으로 STOP된다. 이후 Tables added라는 속성이 1이 된 것을 확인할 수 있다. 왼쪽의 Tables를 선택해 방금생성된 테이블을 살펴보면 kind, etag, item과 함께 catalog가 생성된 것을 알 수 있다.
5. AWS Athena?
테이블을 선택하고 view data를 클릭하면 AWS Athena로 연결된다. AWS Athena는 ad hoc query tool이다. SQL query를 통해서 우리가 가진 데이터에 어떤 일이 일어나고 있는지 확인할 수 있다.
이 athena를 사용하기 위해서는 결과값이 어디에 저장될지를 지정해줘야 한다. 경고문 오른쪽의 "설정 편집"을 눌러 수정할 수 있다. 이때 우리는 새로운 S3 bucket을 생성해 결과를 받을 예정이다. 적당한 이름을 붙여 새로운 버킷을 생성하고 athena의 결과를 받도록 설정해준다. 이제 athena를 실행할 준비가 끝났다.
결과를 받을 버킷도 설정 했는데, 미리 설정되어진 쿼리를 실행하면 오류가 뜬다. 오류를 뜯어 보면 요점은 json 데이터를 이해할 수 없다는 뜻이다.
Our query against our JSON failed
앞의 테이블에서 살펴봤듯이, 우리는 kind, etag, items라는 세가지 구분을 사용한다. 이때 kind, etag는 string이지만 items는 array이다. 우리는 string인 kind와 etag가 아니라 array인 items라는 key를 사용하고 싶은 것이다. 하지만 AWS catalog는 이를 자동적으로 분류하고 읽을 능력이 없다. AWS가 JSON 파일을 읽기 위해서는 "key:value" 한 줄에 들어있어야 한다.
Data Clensing
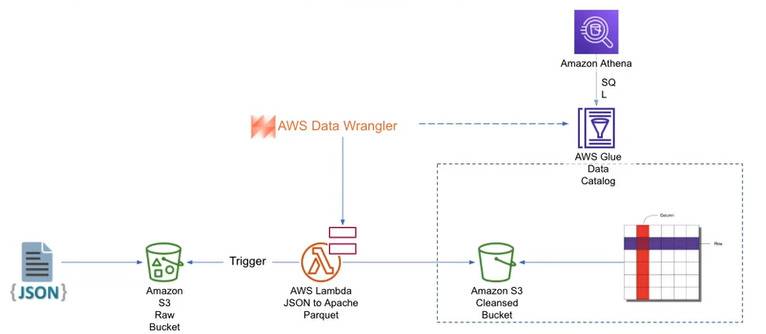
목표는 Data cleansing이다. 위의 구조에 따라 JSON 파일을 Apache Parquet format으로 변환할 것이다. 현재 S3에 JSON 데이터가 들어있고, AWS lambda를 이용해 transformation을 진행한 뒤 cleansed bucket에 데이터를 저장한다. 이후에는 AWS Athena를 활용한 쿼리들을 진행할 수 있을 것이다.
정돈된 데이터를 받을 버킷을 생성하는 것은 생략한다.
AWS Lambda
Lambda는 AWS에서 제공하는 compute service이다.
AWS Lambda에 들어가서 새로운 함수를 생성한다. Python 3.8을 이용하게끔 설정한다. 기본 실행 역할 부분에서는 lambda가 S3에 접근할 수 있도록 새로운 role을 만들어서 설정해주면 된다. 위와 비슷하게 S3FullAccess 권한을 주고 적당한 이름을 붙여 지정하면 함수 생성이 끝난다. 이 lambda로 실행할 python code는 가장 위의 reference의 github에 들어있다. 코드를 넣은 다음에는 deploy 버튼을 눌러주자.
생성한 함수를 선택하고 구성 > 환경 변수 > 환경 변수 편집으로 들어가 환경 변수를 추가해준다.
glue_catalog_db_name : db_youtube_cleaned
glue_catalog_table_name : cleaned_statistics_reference_data
s3_cleansed_layer : s3://[새로 생성한 버킷 이름]/youtube
write_data_operation : append
생성한 함수로 돌아가 code 부분을 채우고 Configure Test Event로 코드를 테스트한다. 템플릿을 s3-put으로 설정하고 코드 중 example-bucket은 데이터가 있는 버킷의 이름을, test%2Fkey에는 버킷의 이름을 제외한 한 가지 json파일의 경로를 넣어준다. youtube/~/~.json과 같은 식으로 입력될 것이다. 저장하고 다시 TEST를 눌러 코드를 돌린다.
-
테스트를 돌려보면 No module named 'awswrangler' 라는 오류가 뜬다. 사실 awswrangler는 현재 사용되지 않는 애플리케이션이다. lambda layer로 추가하려고 해도 선택할 수조차 없다. 대신에 AWSSDKPandas-Python38 layer을 추가하면 된다. 다시 테스트를 돌려보면 아까와 같은 오류는 생기지 않는다.
-
다음은 time out 오류가 생성된다. 이를 해결하기 위해서는 함수의 기본 설정에서 timeout 시간을 바꿔주면 된다. 구성 > 일반 구성에서 대충 5분 정도로 주었다. 그러면 time out 오류는 해결된다.
-
다음으로 생기는 오류는 glue에 대한 permission이 없어서 생기는 오류다. 생성해두었던 lambda 전용 역할에 GlueServiceRole permission을 추가해주면 된다.
-
위의 오류 해결 방법 이후에도 오류가 생긴다면 다음 방법들을 추천한다.
1) time out: 3분이 아니라 10분으로도 설정해보고, 그래도 오류가 난다면 같은 설정에서 메모리를 256으로 늘려보는 걸 추천한다. 아니면 Python 3.8이 아닌 상위 버전을 사용해도 좋다.
2) DB: db_youtube_cleaned가 없어서 생기는 문제일수도 있다. Glue에서 같은 이름의 데이터베이스를 하나 생성해주면 된다.
모든 오류를 해결하고 나면 cleansed data들이 저장된 paths가 나온다. S3에서 해당 경로로 들어가보면 파일이 하나 생성되어있는 것을 알 수 있다. Glue의 tables를 확인하면 클렌징이 완료된 데이터에 대한 테이블이 있다. 새로 생성된 "cleaned_statistics_reference_data" 테이블에 들어가보면 items 대신에 다양한 컬럼이 생긴 것을 확인할 수 있다. 해당 테이블을 선택하고 "View data"를 하면 자동적으로 Athena로 연결되며 클렌징 전과 다르게 기본적으로 입력되어있는 쿼리를 실행할 수 있다.
