오늘은 Neural network에 대해 알아보겠다.
인공신경망에 대해 알아보기전에 사람의 뇌는 어떤 구조로 작동하는지에 대해 먼저 알아보겠다.
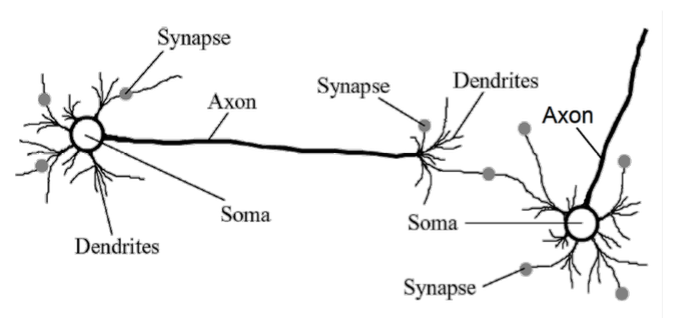
사람의 뇌은 다음과 같은 뉴런이라는 신경전달물질을 통해서 작동한다.
Hebb Rule 에서는 뉴런이 서로 영향을 줄때 이를 서로 연결을 더욱 강화 하는 식으로 학습을 진행한다고 알려져있다.
아무튼 이런 사람의 뉴런을 모방하여 만든 걸 Artificial Neural Network이라고 한다.
인공신경망에서 뉴런의 역할을 하는것이 바로 perceptron이라는 개념이다.
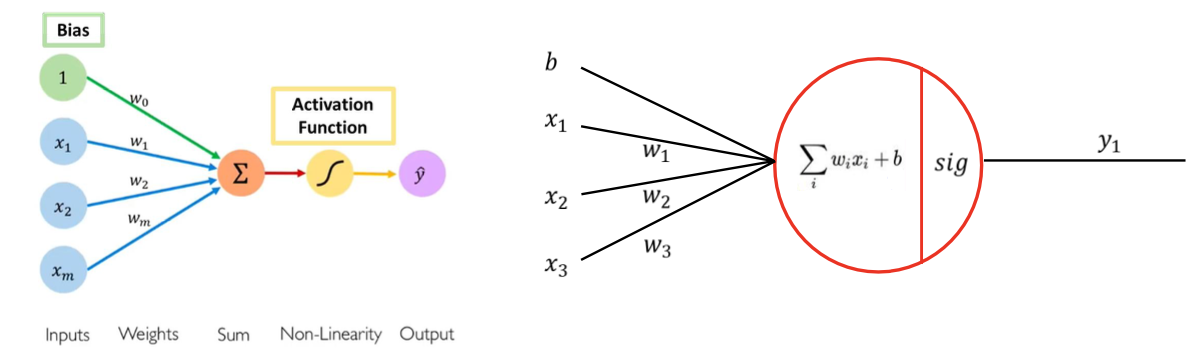
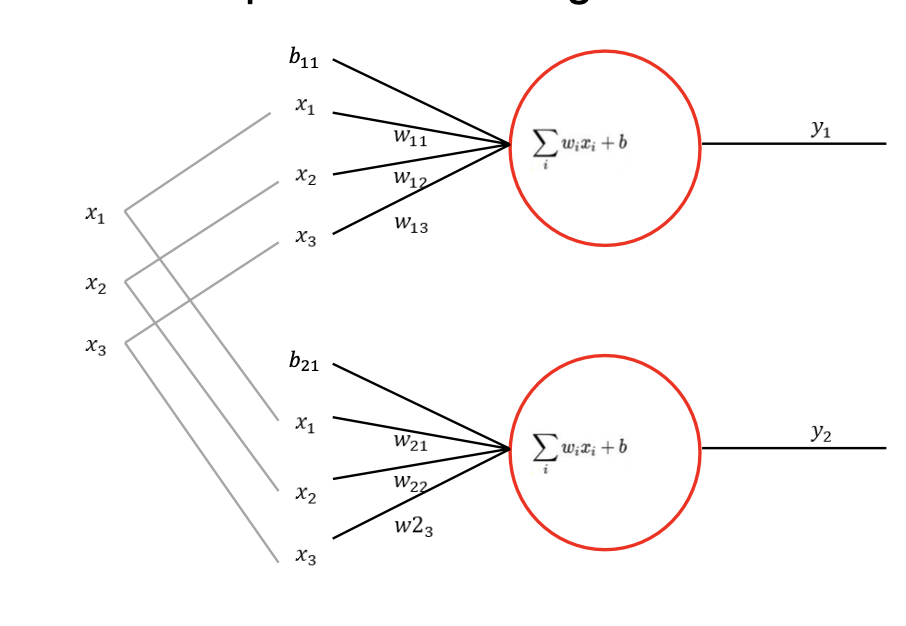
perceptron은 다음과 같은 구조를 가지고 있다.
어떠한 자극(input)이 들어오면 이를 처리해서 다음 뉴런으로 넘겨주는 식으로 작동을한다.
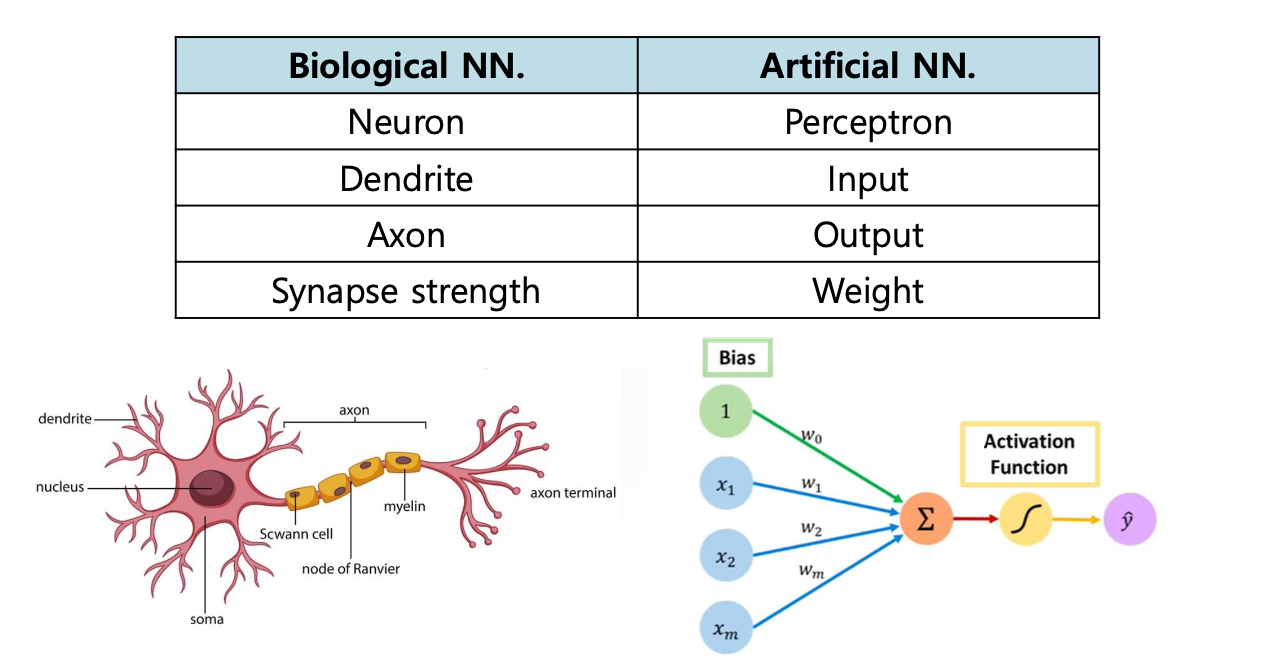
생물학적 NN과 인공NN을 비교해보면 다음과 같이 나타낼 수 있다.
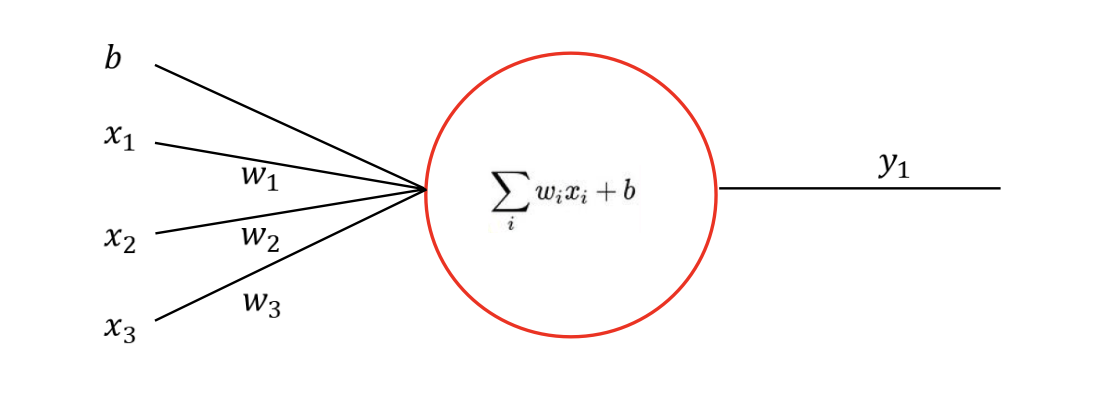
perceptron은 다음과 같이 작동합니다.
각각의 input들과 input을 이어주는 w로 연결되어 있고, 각각의 계산은 x1w1 + x2w2 ... 이런식으로 이루어집니다.
이는 우리가 이전에 배웠던 Multiple Linear Regression 과 유사하다.
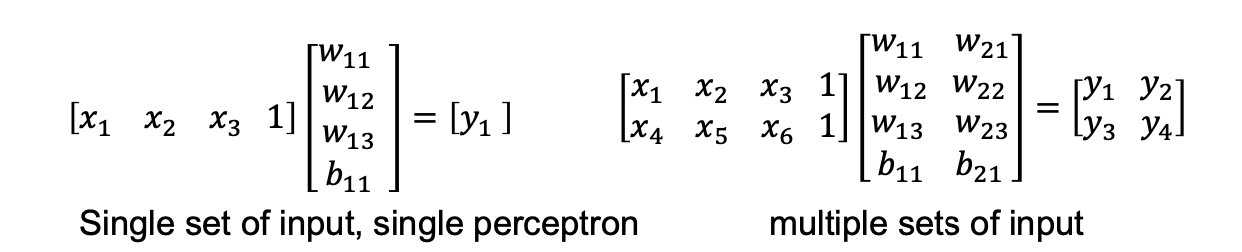
인공신경망의 작동 과정은 다음과 같이 정의된다.
1. 가중치들을 초기화 한다.
2. 입력값과 가중치를 토대로 Hypothesis function의 답을 구한다.
3. cost function을 정의한다.
4. loss를 구한다.
5. backpropagation을 통해서 w들을 update 한다.
여기서는 우리가 Multiple Classification 문제를 예시로 NN에 대해 알아보도록 하겠습니다.
예시로 x값들이 각각 몸무게, 신발 사이즈, 칼로리 소모량을 나타내고, 결과 레이블이 각각의 동물을 나타낸다고 가정해봅시다.
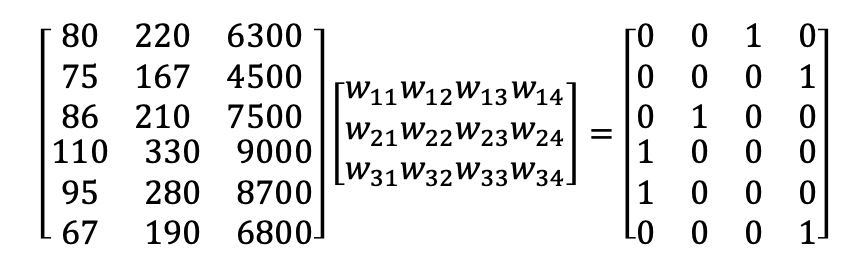
[one hot encoding ]
여기서 결과를 우리는 0 혹은 1로만 나타낸다.
이를 one-hot encoding이라고 한다. 이는 classificatino에서 주로 사용되는 기법이다.
만약에 우리가 각각의 동물에 1, 2, 3, 4라고 레이블을 제공한다면 어떨까?
이는 cost function을 구할때 문제가 나타난다. MSE로 오차를 나타내 본다고 가정해보자.
만약 정답이 1인 경우 2와의 오차는 (2-1)^2 = 1이 된다.
하지만 4와의 오차는 (4-1)^2 = 9가 된다.
즉, 레이블의 순서에 오차값이 영향을 준다는 것이다.
이는 정확한 학습을 할수 없게된다.
정답이 코끼리인데, 호랑이와의 차이가 9, 사자와의 차이가 1이라는 식으로 잘못된 학습을 할 수 있기 때문이다.
그래서 one-hot encoding을 통해서 모든 레이블에 동등한 오차를 제공하여 안정적인 학습을 하는데 도움을 준다.
[ SoftMax ]
그리고 우리가 학습을 통해서 나온 값들은 제각각으로 나오게 된다.
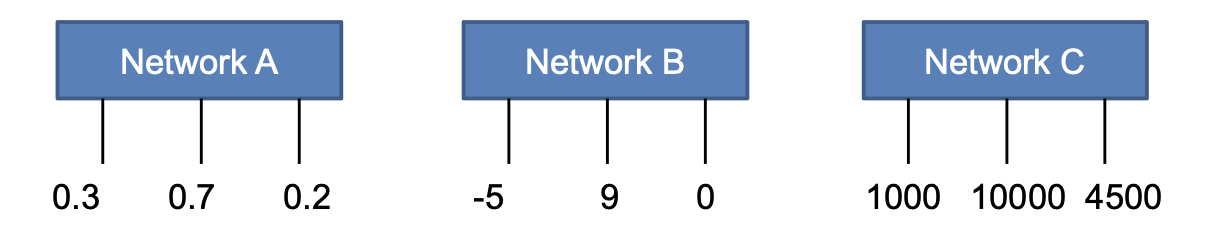
여기서 우리는 각각의 결과들을 확률적으로 나타냅니다.
확률적으로 나타내는 이유는, 우선 0과1 사이로 나타냄으로써 각각의 변수들이 경쟁하도록 한다. 하나의 변수가 확률이 높아지면 자동으로 다른 변수의 확률이 낮아지기 때문이다.
그리고 총합이 1이 되므로 하나의 변수가 여러 클래스에 속하는 것을 방지합니다. 그리고 최종적으로 softmax를 통해서 모든 구간에서 미분 가능하도록 해줍니다.
이는 이후 gradient Descent를 구할때 중요하게 동작합니다.
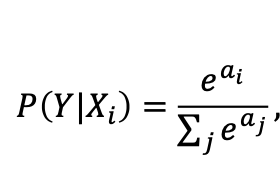
위의 식이 바로 softmax 식입니다.
softmax에서 exponention e를 사용하는 이유는 다양한 이유가 있겠지만, 큰 값은 크게, 작은 값은 작게 만들어 상대적으로 차이를 만들어 보다 확실하게 학습을 시킵니다.그리고 또한 지수 함수 특성상 모든 값을 양수로 만들고, 아무리 작은 값이라도 0으로 만들지않습니다. 이는 수치적으로 안정성을 보장하게 됩니다.
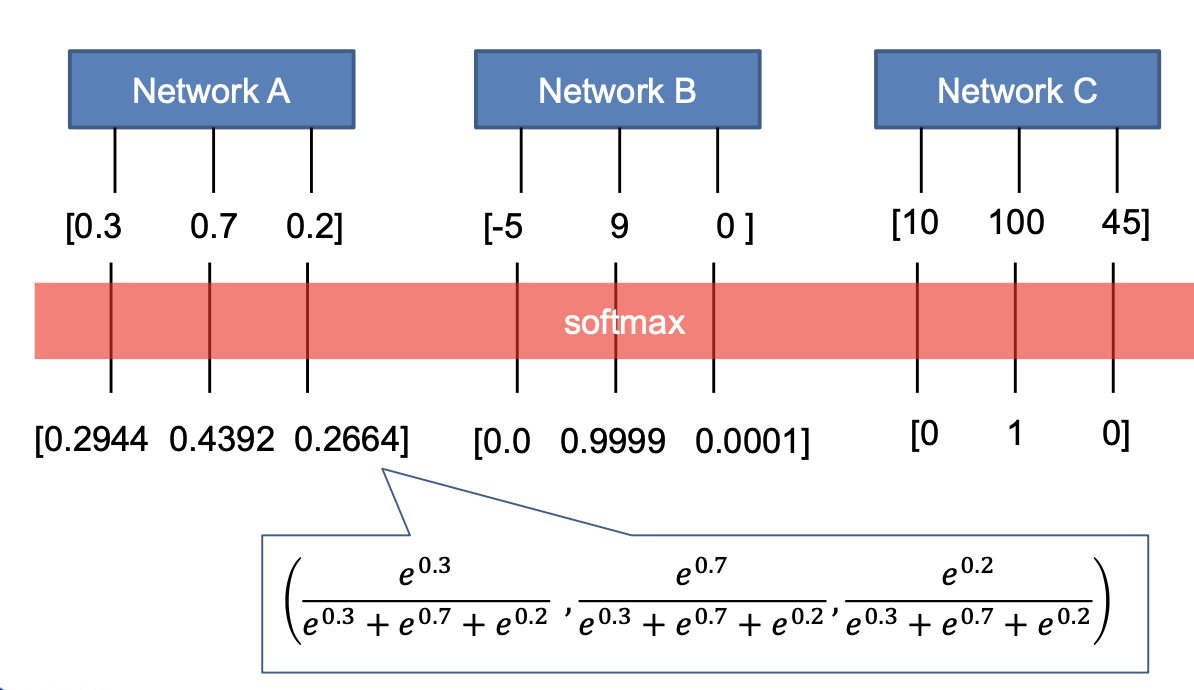
다음은 softmax함수를 이용하여 값들을 정규화 한 결과입니다.
Multiple classification 문제에서 cost function은 주로 cross entropy를 사용합니다.
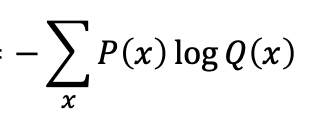
cross entropy는 다음과 같이 정의됩니다.
예를들어 결과가 [01, 0,2,0.8] 이거 GT(정답)이 [0,0,1] 인경우 loss = - (log(0.8))이 됩니다.
최종적으로 Multiple classification 과정에 대해 설명해보겠습니다.
1. Hypothesis function정의하기.
2. 가중치 초기화 하기.
3. Forwarding 하기.
4. Softmax로 결과값들 정규화 하기.
이는 보통 마지막 activation function으로 softmax로 활용한다.
5. 정답 GT를 one-hot encoding으로 나타내기.
6. Cost function 정의하기.
7. cost function을 가지고 최적화 하기
Activation function
Deep NN에서는 주로 activation function들을 사용한다.
이는 함수에서의 비선형성을 추가 하기 위함이다.
즉, 데이터를 보다더 잘 설명하기 위해서는 직선보다는 구불구불하게 설명하는게 더 정확도가 높기 때문이다.
그래서 우리는 Activiation function이라는 함수를 중간 중간에 넣어준다.
앞에서 배운 softmax도 activation funciton의 일종이다.
Activation function의 종류들은 다음과 같다.
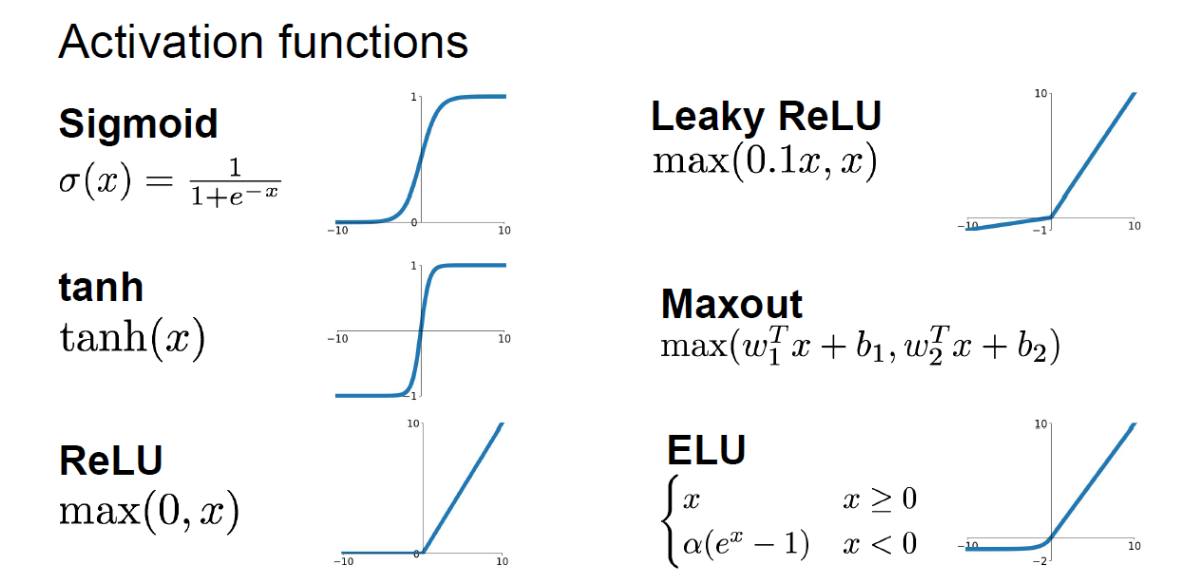
1) Sigmoid
가장 처음에 널리 사용된 활성화 함수이다. 하지만 현재는 단점이 많아 사용하지 않는다.
sigmoid의 단점.
1. 0과 1 부근에서 미분값이 0이 되어버리는 Vanishing Gradient문제.
2. None zero centered 문제 (zigzag)
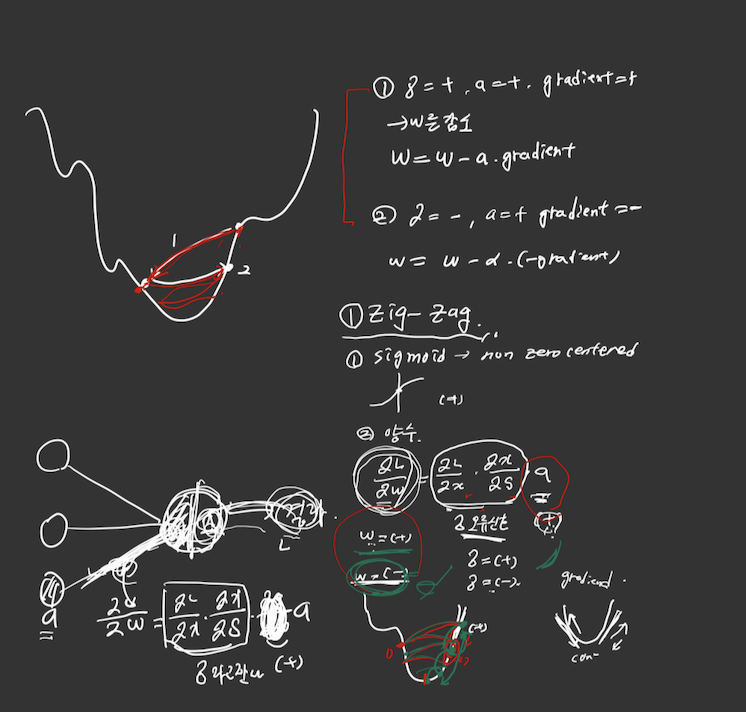
정리를 하지 않아서 더럽지만 위의 1,2, 식만 보면된다.
우리가 gradient를 구할때 오류신호 * 값 이렇게 해서 구하는데, sigmoid의 값이 모두 양수라는게 문제다!!!
그래서 오류신호가 -, + 가 번갈아서 나오게 된다면, gradient를 더했다, 뺐다 하면서 계속 왔다갔다하면서 지그재그로 수렴한다는 문제점이 있다.
2) tanh
tanh는 sigmoid의 none zero centered문제를 해결하였다.
3) ReLU
현재 가장 많이 사용되고 있는 활성화 함수입니다.
하지만 음수 부분에서 모든 미분값이 0 이 된다는 단점이 존재하여 이를 보강하기 위해서 Leaky ReLU가 나왔습니다.
SUMMARY
오늘 배운내용을 정리해 보겠습니다.
Multiple Classification 문제에서 각각의 hidden layer에 다양한 활성화 함수들이 들어있고, 마지막 활성화 함수에서는 softmax를 사용한다.
그리고 GT는 (ground Truth (정답)) one-hot encoding으로 나타내고 cross entropy 손실함수를 사용해서 loss를 구하고 이를 backpropagation을 통해서 w,b를 최적화 한다.
