
push_swap은 주어진 정수 배열을 스택 2개를 이용해 정렬하는 과제다. 즉, 미루고 미루던 정렬 알고리즘에 대한 공부를 해야만 한다.
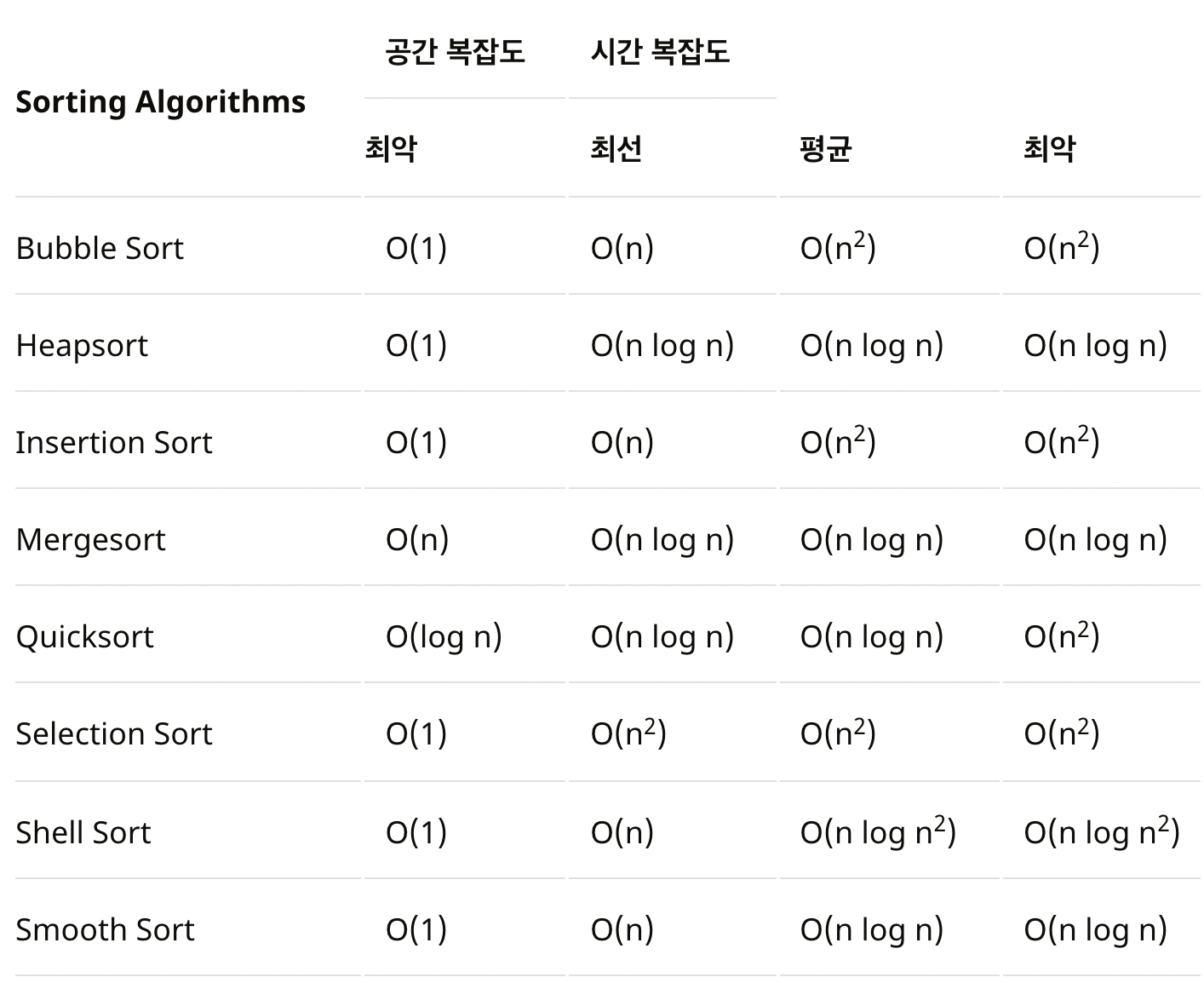
위 이미지는 정렬 알고리즘별 효율성을 따지는 표다. 효율적인 정렬을 위해서는 정렬 알고리즘의 종류와 복잡도(complexity)에 대한 이해가 필요하다.
1. 복잡도(Complexity)
복잡도는 알고리즘의 성능을 나타내는 척도로, 시간 복잡도와 공간 복잡도로 나뉜다.
공간 복잡도 📦
공간 복잡도는 프로그램의 실행과 완료를 위해 어느 정도의 공간(메모리)가 필요한지를 나타낸다. 공간 복잡도는 두 가지로 나뉜다. 총 공간 요구 = 고정 공간 요구 + 가변 공간 요구로 나타낼 수 있다.
- 고정 공간
코드, 단순 변수, 상수 등이 저장되는 공간을 뜻한다. 즉, 알고리즘과는 무관한 공간이다.- 가변 공간
코드가 실행될 때 동적으로 필요한 공간을 뜻한다. 즉, 알고리즘과 밀접한 공간이다.
시간 복잡도 🕰
주어진 입력에 대해 알고리즘이 얼마나 오래 걸리는지를 의미한다. 하지만 시간은 주어진 운영체제나 플랫폼에 따라 달라질 수 있기 때문에 알고리즘을 위한 연산의 횟수를 기준으로 한다. 이때 주어지는 입력값에 따라 최선의 경우(Best Case)와 최악의 경우(Worst Case)의 복잡도가 다르게 나타나는데, 그 사이의 여러 경우의 수를 고려하여 평균값을 계산한 경우를 평균의 경우(Average Case)라고 부른다. 하지만 알고리즘이 복잡해질수록 평균값을 구하는 것이 어려워지기 때문에 보통 최악의 경우를 기준으로 알고리즘 성능을 파악하는 경우가 많다. 여기서 시간 복잡도를 나타내는 표기 방법으로 빅오 표기법을 알아야 한다.
💡 빅오 표기법(big-O notation) 이란?
빅오는 알고리즘의 시간 복잡도를 표기할 때 가장 널리 쓰이는 수학적 표기 방법이다. 시간 복잡도를 표기하는 점근 표기법에는 빅오메가(big-Ω)와 빅세타(big-Θ) 표기법도 있다. 하지만 효율성을 상한선 기준으로 한다는 점 때문에 다른 표기법들 보다 많이 사용된다. (알고리즘 효율성은 값이 클수록 즉, 그래프가 위로 향할수록 비효율적임을 의미한다.) 빅오 표기법의 수학적 정의는 다음과 같다.
𝑛≧𝑛₀인 모든 𝑛에 대해 𝑓(𝑛)≦𝑐𝑔(𝑛)인 양수 𝑐, 𝑛₀이 존재한다면, 𝑓(𝑛)을 O(𝑔(𝑛))이라고 나타낼 수 있다.
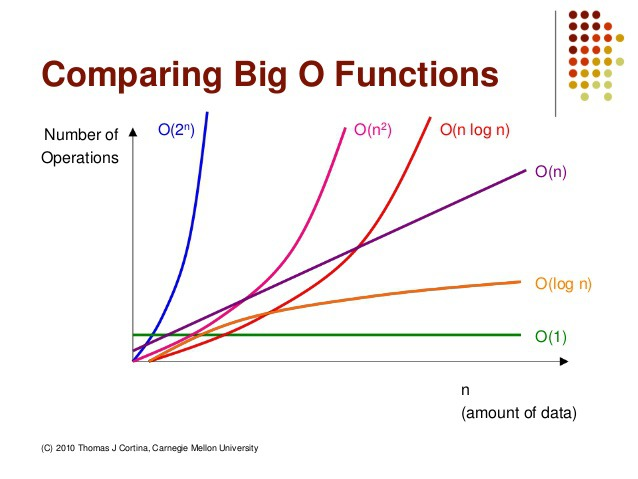
빅오 표기법에는 두 가지 법칙이 있는데, 하나는 상수항을 무시한다는 법칙이고 다른 하나는 영향력이 없는 항을 무시한다는 법칙이다. 쉽게 말하면 단순 연산들을 제외한 루프와 재귀에 대한 횟수만 확인하면 되는 것이다. 이러한 법칙에 따라 만들어지는 빅오 표기법은 다음과 같다.
왼쪽에서 오른쪽으로 갈수록 효율성이 떨어진다. 복잡도의 예시와 해당 복잡도를 구하는 요령은 다음과 같다.
복잡도 소요 시간 설명 𝑂(1) 상수 시간 입력값에 상관없이 일정한 실행시간을 요구하는 최고의 알고리즘이다. 하지만 상수값이 상상 이상으로 클 경우 사실상 의미가 없다.
e.g.) 스택에서 push, pop𝑂(log 𝑛) 로그 시간 로그는 매우 큰 입력값에서도 크게 영향을 받지 않음으로, 매우 견고한 알고리즘이다.
e.g.) 이진 트리𝑂(𝑛) 선형 시간 알고리즘을 수행하는데 걸리는 시간은 입력값에 비례하며, 이를 선형 시간 알고리즘이라 부른다. 모든 입력값을 적어도 한 번 이상 살펴봐야 한다.
e.g.) for문𝑂(𝑛 log 𝑛) 선형 로그 시간 대부분의 효율 좋은 알고리즘이 이에 해당 한다. 아무리 좋은 알고리즘이라 할지라도 n log n 보다 빠를 수 없다.
e.g.) 퀵 정렬, 병합 정렬, 힙 정렬𝑂(𝑛²) 2차 시간 비효율적인 정렬 알고리즘이 이에 해당 한다.
e.g.) 버블 정렬, 선택 정렬, 삽입 정렬, 이중 for문𝑂(2ⁿ) 지수 시간 피보나치의 수를 재귀로 계산하는 알고리즘이 이에 해당 한다.
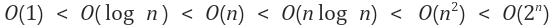
2. 정렬 알고리즘(Sorting Algorithm)
알고리즘의 복잡도에 대한 내용을 살펴봤으니, 이제 본론인 정렬 알고리즘의 종류에 대해 살펴보도록 하겠다. 사실 누군가에게는 시간 복잡도에 대한 내용이 더 중요하게 느껴질 수도 있겠지만, 나는 정렬 알고리즘에 대한 지식이 0이기 때문에 이 파트가 더 중요하다..🥲 개별적인 알고리즘을 살펴보기 전에 알고리즘의 특징에 따른 분류를 먼저 알아보자.
💡 안정 정렬(Stable Sort) vs. 불안정 정렬(Unstable Sort)
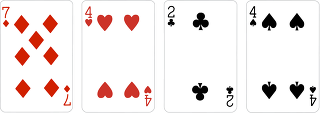
정렬의 안정적 특성은 "정렬 후에도 같은 키들의 상대적인 순서가 정렬 이전과 동일하게 유지되느냐"이다. 아래와 같은 입력값이 있다고 가정해보자. 1번 인덱스와 3번 인덱스의 키 값이4로 같은 상황임을 알 수 있다.
- 안정 정렬 : 중복된 값(
4)이 입력 순서와 동일하게 정렬된다.
e.g.) 삽입 정렬, 병합 정렬, 거품 정렬
- 불안정 정렬 : 중복된 값(
4)이 입력 순서와 다르게 정렬된다.
e.g.) 퀵 정렬, 선택 정렬, 계수 정렬


💡 제자리 정렬(In-place Sort)
주어진 공간 외에 추가적인 공간을 사용하지 않는 정렬이다. 즉, 공간 복잡도가𝑂(1)이라는 장저미 있다. 이 외에도 공간 지역성이 좋다는 장점이 있는데, 지역성에 대한 내용은 따로 다루도록 하겠다.
정렬의 기본적인 분류를 확인했으니, 복잡도가 좋지 않은 알고리즘들부터 하나씩 살펴보자. 아래의 모든 정렬은 오름차순을 기준으로 설명한다.
⏺ 거품 정렬(Bubble Sort)
두 인접한 원소를 검사하여 정렬하는 방법이다. i와 i+1의 값을 비교하여 줄 중 큰 수를 뒤로 보낸다. 피신 때 거품 정렬이라는 걸 처음 알았다. 태어나서 처음 사용해 본 정렬 알고리즘이었는데, 확실히 코드가 단순하기 때문에 배경지식이 없었음에도 금방 이해했던 것 같다.
- 장점
코드가 직관적이다.
안정 정렬이다.
제자리 정렬이다.- 단점
시간 복잡도가 좋지 않다. 즉, 비효율적이다.
⏺ 삽입 정렬(Insertion Sort)
삽입 정렬은 두 번째 자료부터 시작하여 자신보다 앞에 있는 자료들과 비교 후 삽입할 위치를 지정하여 그 뒤의 자료를 한 칸씩 뒤로 옮긴 뒤 자신을 해당 위치에 삽입하여 정렬하는 알고리즘이다.
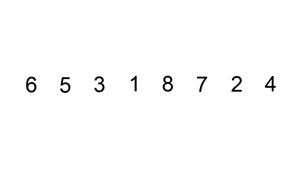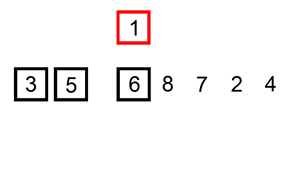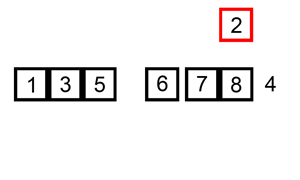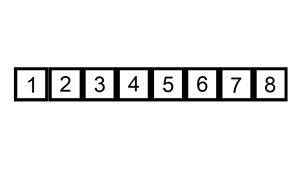
- 장점
안정 정렬이다.
제자리 정렬이다.
작은 데이터 세트에서 매우 효율적일 수 있다.- 단점
비교적 많은 레코드들의 이동이 필요하다.
자료의 크기가 클 수록 효율성이 떨어진다.
⏺ 셸 정렬(Shell Sort)
셸 정렬은 삽입 정렬의 단점을 보완한 알고리즘이다. 삽입 정렬과의 가장 큰 차이점은 전체 리스트를 한 번에 정렬하지 않는다는 것이다. 정렬 과정은 다음과 같다.
- 리스트의 값을 k 만큼의 간격으로 추출하여 부분 리스트를 만든다. 이때 k를 간격(gap)이라고 부르며, 간격의 초깃값은
{전체 요소의 수}/2이다. - 각 리스트를 삽입 정렬을 통해 정렬한다.
- 각 회전마다 k의 값을 절반으로 줄인다. 간격은 홀수로 하는 것이 좋으며, 짝수로 나오는 경우 k+1을 하여 홀수로 만들어준다.
- 간격이 1이 될 때까지 반복한다.
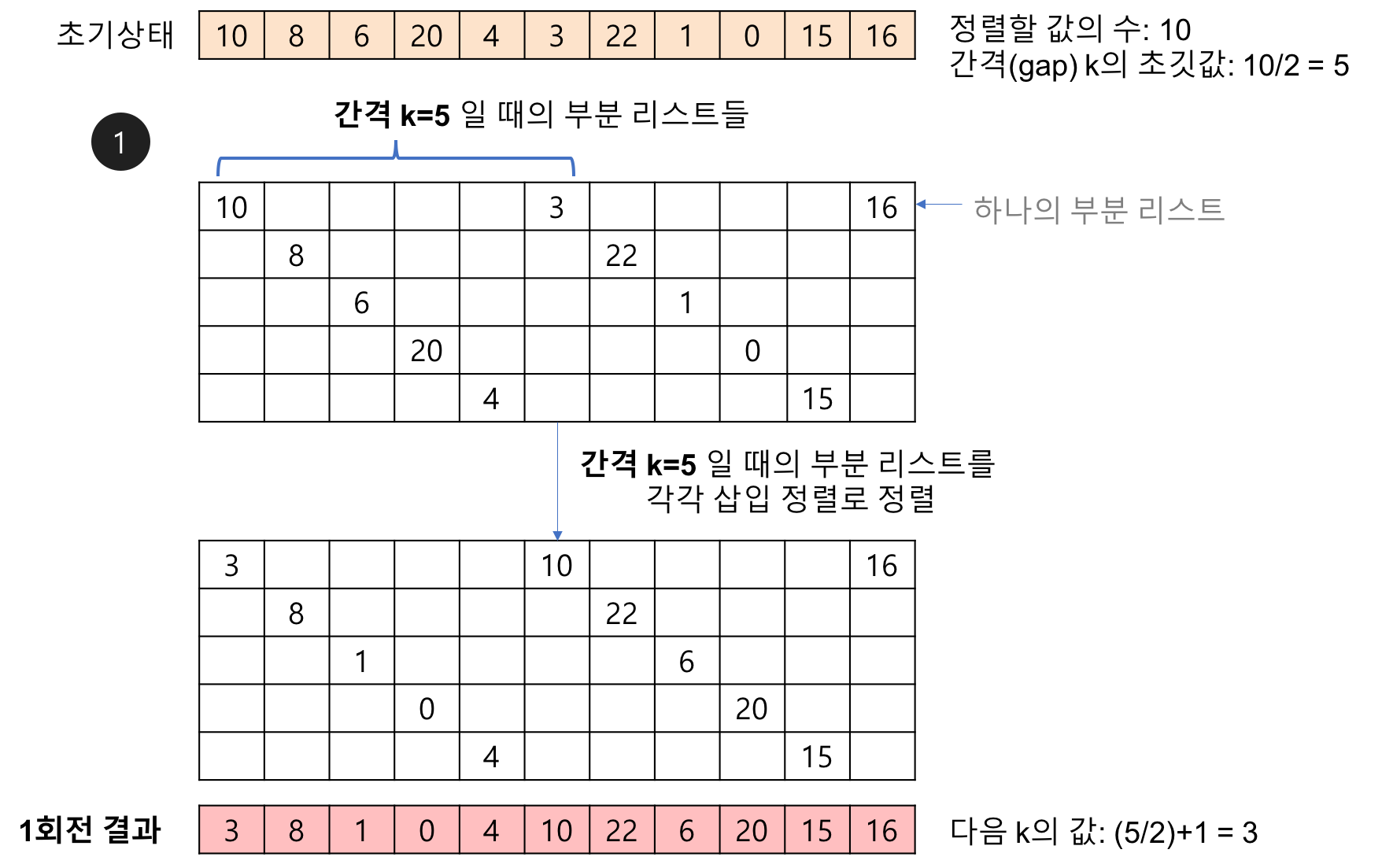
- 장점
자료 교환시 이동의 거리가 크다. 따라서 삽입 정렬보다는 최종 위치에 있을 가능성이 높아지며, 삽입 정렬보다 정렬 속도가 더 빠르다.- 단점
설정한 간격에 따라 성능 차이가 심하다.
⏺ 선택 정렬(Selection Sort)
선택 정렬은 주어진 자료의 최솟값을 찾아 맨 앞의 값과 교환한 뒤 교환된 최솟값의 위치를 제외한 나머지 리스트를 같은 방법으로 교체하는 알고리즘이다.
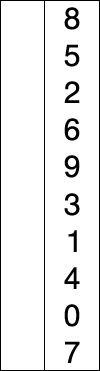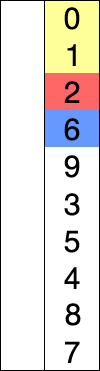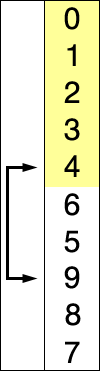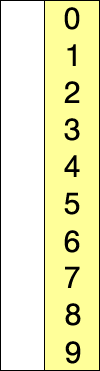
- 장점
제자리 정렬이다.
자료 이동 횟수가 미리 결정된다.- 단점
불안정 정렬이다.
거품 정렬과 삽입 정렬보다는 효율적이지만, 여전히 시간 복잡도가 좋지 않다.
⏺ 힙 정렬(Heapsort)
힙 정렬은 최대 힙 트리나 최소 힙 트리를 구성해 정렬을 하는 방법이다.(오름차순일 경우 최대 힙, 내림차순일 경우 최소 힙을 사용한다.) 힙을 구성하여 정렬하는 방법은 다음과 같다. 이거 이해하는데 진짜 오래걸렸다..😢
- n개의 노드에 대한 완전 이진 트리를 구성한다. 이때 루트 노드부터 부모노드, 왼쪽 자식노드, 오른쪽 자식노드 순으로 구성한다.
- 최대 힙을 구성한다. 최대 힙이란 부모노드가 자식노드보다 큰 트리를 말하는데, 아래부터 루트까지 올라오며 순차적으로 만들어 갈 수 있다.
- 가장 큰 수(루트에 위치)를 가장 작은 수와 교환한다.
- 2와 3을 반복한다.

- 장점
시간 복잡도가 좋은 편이다.
가장 큰 값 몇 개만 필요할 때 가장 유용하다.- 단점
같은 시간 복잡도를 가진 다른 알고리즘과 비교하면 느린 편이다.
⏺ 병합 정렬(Mergesort)
병합 정렬은 배열을 작은 단위로 쪼개어 정렬한 결과를 합치면서 전체를 정렬하는 방법이다. 분할 정복(divide and conquer)방법을 통해 리스트를 정렬하며, 흔히 쓰이는 하향식 2-way 합병 정렬은 다음과 같이 작동한다.
- 리스트의 길이가 1 이하이면 이미 정렬된 것으로 본다. 그렇지 않다면
- 분할(divide): 리스트를 절반으로 잘라 비슷한 크기의 리스트 두 개를 만든다.
- 정복(conquer): 각 리스트를 재귀적 합병 정렬로 정렬한다.
- 결합(combine): 각 리스트를 하나의 정렬된 리스트로 합병한다. 이때 정렬 결과가 임시배열에 저장된다.
- 복사(copy): 임시 배열에 저장된 결과를 원래 배열에 복사한다.
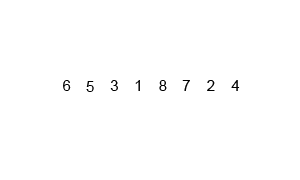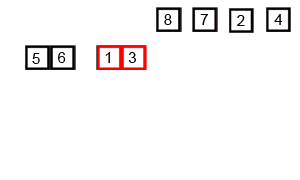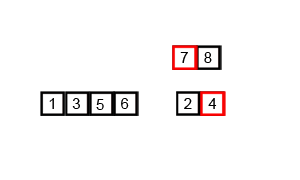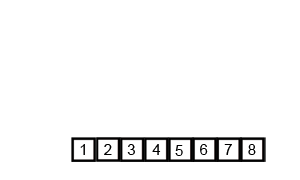
- 장점
일반적인 방법으로 구현했을 때 안정 정렬에 속한다.
항상 일정한 시간 복잡도를 가진다.
레코드를 연결 리스트로 구성한다면 링크의 인덱스만 변경되므로 제자리 정렬로 구현할 수 있다.- 단점
제자리 정렬이 아니다. 즉, 추가적인 메모리가 필요하다.
레코드들의 크기가 큰 경우 이동 횟수가 많아짐으로 큰 시간 낭비를 초래한다.
⏺ 퀵 정렬(Quicksort)
퀵 정렬은 하나의 축(pivot)을 기준으로 작은 값은 왼쪽에, 큰 값은 오른쪽에 위치시키며 정렬하는 방법이다. 병합 정렬과 마찬가지로 분할 정복(divide and conquer) 방법을 통해 리스트를 정렬한다.
- 리스트 가운데에서 하나의 원소를 고른다. 이를 축이라고 부른다.
- 분할(divide): 축의 왼쪽에는 축보다 작은 값, 오른쪽에는 큰 값이 오도록 리스트를 둘로 나눈다. 분할을 마친 뒤 축은 더 이상 움직이지 않는다.
- 가장 왼쪽의 값을 left, 가장 오른쪽의 값을 right로 설정한다. left는 축보다 큰 수를 만나거나 축을 만나면 멈추고, right은 축보다 작은 수를 만나거나 축을 만나면 멈춘다.
- left와 right이 멈췄을 때 left가 right보다 왼쪽에 있다면 둘의 값을 교환한다. 이 과정을 left가 right보다 오른쪽에 위치할 때까지 반복한다.
- 정복(conquer): 분할된 각각의 리스트에 대해 재귀(Recursion)적으로 이 과정을 반복한다.
- 장점
평균 실행시간이 빠르다.(시간 복잡도가 같은 다른 알고리즘과 비교했을 때도 가장 빠르다.)
추가적인 메모리 공간을 필요로 하지 않는다.(공간 복잡도가 𝑂(㏒ 𝑛)이다.)- 단점
축을 어떻게 설정하느냐에 따라 성능 차이가 심하다.
불안정 정렬이다.
⏺ 부드러운 정렬(Smooth Sort)
힙 정렬의 변형 중 하나이며 Leonardo Number 라는 개념을 적용시킨 알고리즘이다. 레오나르도 수의 식은 다음과 같다.
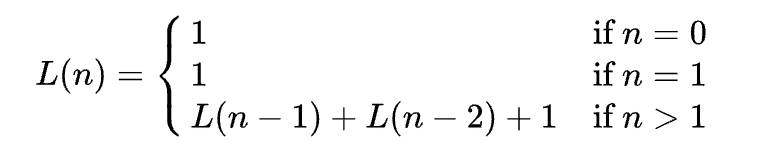
값은 다음과 같다.
1, 1, 3, 5, 9, 15, 25, 41, 67, 109, 177, 287, 465, 753, 1219, 1973, 3193, 5167, 8361, ... 영 뭔지 모르겠다... 그냥 위의 수를 이용하여 힙을 만들면 되는 것 같다. 힙 정렬에서는 root값이 하나인 하나의 이진 트리만 만들면 됐지만, 부드러운 정렬에서는 아래 이미지처럼 1, 3, 9... 의 레오나르도 수로 이루어진 이진 트리를 구성해야 한다. 이렇게 레오나르도 수로 만든 힙을 레오나르도 힙이라고 부른다.
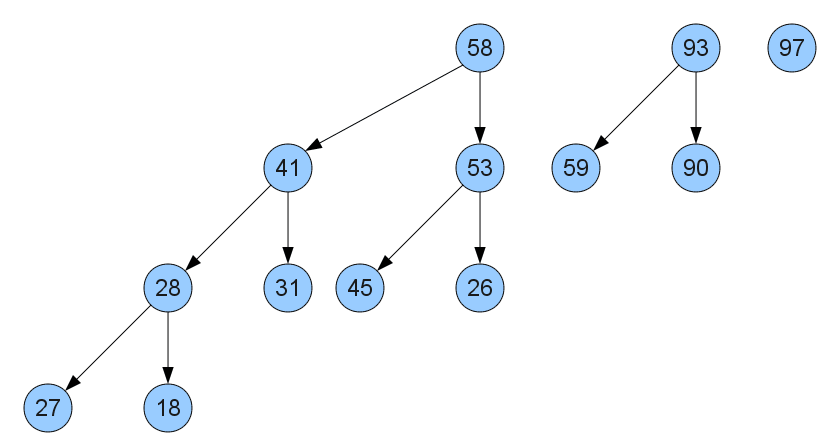
정렬 순서는 다음과 같다.
- 레오나르도 최대 힙을 구성한다. 모든 트리는 각자 다른 크기를 가지고 있어야 한다.
- 힙에서 가장 큰 수를 가장 작은 수와 교환한다.
- 1과 2를 반복한다. 힙에서 최댓값이 제거될 때 남은 요소들로 다시 레오나르도 힙을 구성해야 한다.
- 장점
제자리 정렬이다.- 단점
불안정 정렬이다.
나에게는 너무 어렵다..!
참고
https://ko.wikipedia.org/wiki/%EA%B1%B0%ED%92%88_%EC%A0%95%EB%A0%AC
https://en.wikipedia.org/wiki/Sorting_algorithm#Comparison_of_algorithms
https://en.wikipedia.org/wiki/Insertion_sort
https://jbhs7014.tistory.com/180
https://ko.wikipedia.org/wiki/%ED%95%A9%EB%B3%91_%EC%A0%95%EB%A0%AC
https://ko.wikipedia.org/wiki/%EC%85%B8_%EC%A0%95%EB%A0%AC
https://www.keithschwarz.com/smoothsort/
