Batch란?
Batch Processing : 일괄처리.
ETL : 추출(Extract) , 변환(Transformation) , 적재(Load)
이러한 ETL 과정을 일정한 시간과 순서, 조건에 따라 수행하는 작업을 Batch라고 함.
Spring Batch란?
Spring Batch는 Job과 Step을 기준으로 배치를 수행하기 쉽게하고, 대용량 데이터를 처리하는 데에도 편리하도록 뭉텅이로 잘라 ETL 작업을 할 수 있는 Chunk 지향 처리를 제공하고 있음.
Spring Batch 이해
배치의 일반적인 3단계 시나리오
1. 읽기(read) : 데이터 저장소(일반적으로 DB)에서 특정 데이터 레코드를 읽음
2. 처리(processing) : 원하는 방식으로 데이터를 가공/처리함
3. 쓰기(write) : 수정된 데이터를 다시 저장소(DB)에 저장함
런타임 메타데이터 모델
Spring Batch는 배치 실행에 관련한 모든 정보를 DB에 저장하고, 참조하며 순차적으로 실행.
이러한 형태를 런타임 메타데이터 모델이라고 함
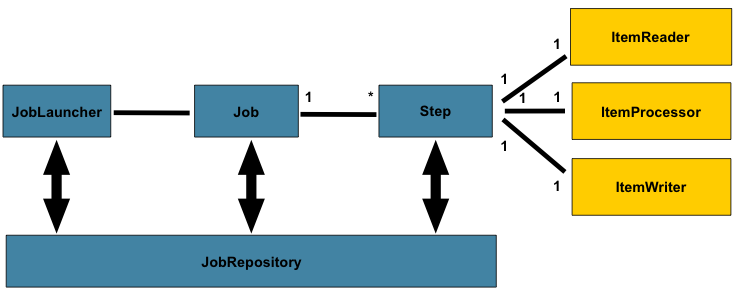
1. Job
Job = 배치 처리 작업
최소 하나의 Step을 가져야 하며, 엄청나게 복잡한 Job이 아닌 이상 2~10개의 Step을 권장.
2. Step
Step은 읽기-> 가공하기-> 쓰기의 묶음 과정 = Chunk Processing.
즉, 하나의 트랜잭션으로 이해하면 됨.
2-1. ItemReader
데이터 읽기 담당.
File, xml, DB 등 여러 타입의 데이터를 읽어올 수 있음
ItemReader 인터페이스
public interface ItemReader<T> {
T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException;
}ItemReader에서 read() 메서드의 반환 타입을 제네릭으로 구현했기 때문에 직접 타입을 지정할 수 있다.
2-2. ItemProcessor
ItemReader를 통해 읽어온 배치 데이터를 변환
ItemProcessor 인터페이스
public interface ItemProcessor<I, O> {
O process(I item) throws Exception;
}2-3. ItemWriter
배치 데이터 저장(일반적으로 DB나 파일에 저장)
ItemWriter 인터페이스
public interface ItemWriter<T> {
void write(List<? extends T> items) throws Exception;
}
📕 참조링크
https://www.fwantastic.com/2019/12/spring-batch-intro.html
https://derveljunit.tistory.com/313
https://freedeveloper.tistory.com/26
