Likelihood Function
-
입력으로 주어진 확률분포가 데이터를 얼마나 잘 설명하는지 나타내는 값(Likelihood)를 출력하는 함수
- 입력 : 확률 분포를 표현하는 파라미터
- 출력 : 데이터를 설명하는 정도
-
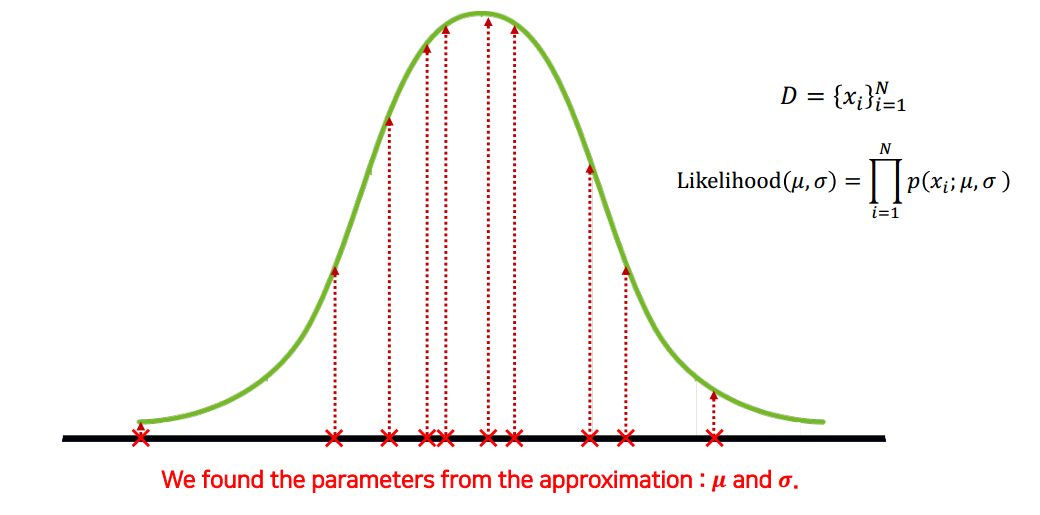
임의의 μ,σ를 따르는 가우시안 분포가 주어졌을 때, 우리가 가진 데이터의 probability density들의 곱을 Likelihood 함수로 정의한다.
-
이러한 시행을 무수히 반복하다 보면, Likelihood 함수 값을 최대로 하는 분포를 얻을 수 있고, 우리가 얻은 데이터가 해당 분포를 따른다고 추정 할 수 있다.
-
즉, Likelihood값을 통해 데이터를 얼마나 잘 설명하는지 알 수 있고 이를 최대로하는 파라미터(θ)를 찾는 것이 목적이다. Gradient Ascent방법을 이용하여 찾을 수 있다.
Log Likelihood
- Likelihood는 확률 값의 곱으로 표현되기 때문에 Underflow의 가능성이 있음.
- 따라서 Log를 취하여 곱셈을 덧셈으로 바꾸고 문제를 해결한다. (연산도 빠름)
Deep Neural Network with MLE
-
분포 P(x)로부터 샘플링한 데이터x가 주어졌을 때 파라미터 θ를 갖는 DNN은 조건부 확률 분포를 나타낸다.
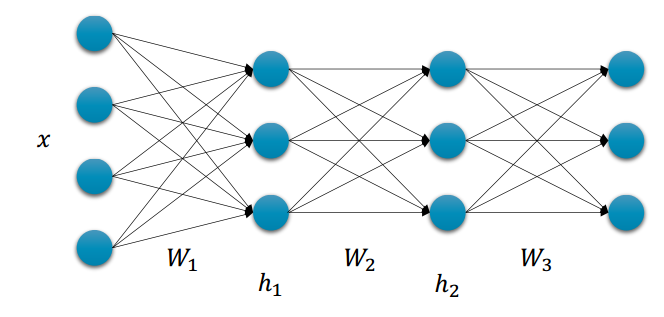
- 데이터셋
- DNN의 파라미터
- Gradient Ascent 방법으로 Likelihood를 최대화 하는 파라미터(θ)를 찾을 수 있다.
-
딥러닝 프레임워크들은 Gradient Descent만 지원하기에 Negative Log Likelihood(NLL)을 최소화하는 θ를 찾도록 한다.
-
다음의 Cross Entropy Loss 정의에 의해 결국 NLL을 최소화하는 것과 Cross Entropy를 최소화하는 것이 같은 개념임을 알 수 있다.

Hi