
자바 개발자라고 말하고 다녔지만, 정작 다시 생각해보면 자바에 대해 모르는 부분이 너무 많고, 한번 정리가 필요하다고 느껴 작성해보고자 합니다.
Java
가장 먼저 JVM을 알려면 자바가 무엇이고, 왜 생겨났는지부터의 이해가 필요할 것 같습니다.
Java의 유래
자바의 창시자, 모두가 아는 제임스 고슬링은 Sun 마이크로시스템즈의 프로젝트 일환으로 자바라는 언어를 만들었습니다. 처음은 Oak라는 객체지향언어로 만들었다가, 수정을 거쳐 JAVA가 탄생하게 되었습니다.
TMI: JAVA라는 용어는?
자바는 자바 섬의 자바에서 유래하였습니다. 제임스 고슬링은 하루에 자바 커피를 10잔씩 마시는 자바 커피 중독자였다고 합니다.
자바는 처음에는 양방향 통신이 가능한 TV에 사용하기 위해 시작된 프로젝트였습니다. 하지만 언어의 수준이 너무 높아 오히려 TV에 적용을 할 수 없는 안타까운 상황이였습니다.
어찌저찌 1996년 자바는 Write Once, Run Anywhere이라는 모토로 1.0버전이 출시되었습니다. 그 당시에 만연했던 C/C++ 스타일로 개발되었기 때문에 기존의 개발자들도 사용하기 쉬웠고, 높은 안정성과 네트워크와 접근 권한을 직접 수정할 수 있어 보안성으로도 좋은 언어였습니다.
하지만 본격적으로 자바가 명성을 날리게 된 것은 1998년 자바 애플릿을 통해 웹 브라우저안에서 프로그램을 실행할 수 있게된 JAVA 2(Java 1.2)이후입니다. 자바 애플릿은 자바로 작성된 뒤 바이트코드로 컴파일되어 브라우저 상에 존재하는 JVM을 통해 실행될 수 있습니다.
우리가 아는 웹 페이지의 시작
이전에는 정적 HTML만 보여줄 수 있었는데, 자바 애플릿을 이용하여 GUI, 멀티미디어, 계산, 다른 웹 서비스나 DB와 interactive한 소통 등 우리가 요즘 웹 페이지를 생각하면 할 수 있는 모든 기능들이 가능해졌습니다.
HTML로만 동작하던 페이지에서 동영상이라니.. 당시에 얼마나 혁신적이었을까요? 그렇게 자바는 점점 몸집을 키워가며 이후 안드로이드 개발에서도 사용되면서 포브스 선정 2023년 가장 많이 사용되는 프로그래밍 언어 3위에 선정되었습니다.
현재는 JS의 발전으로 인해 더이상 자바 애플릿을 사용하지 않습니다.
-- Chat GPT --
Modern web development has shifted towards using technologies like HTML5, CSS, and JavaScript, which provide more flexibility, better performance, and improved security features. As a result, Java applets are no longer widely supported in most modern web browsers, and developers have moved towards alternative approaches for achieving similar functionality.
Java의 Design Goals
자바의 현재 주인인 Oracle에서 정의한 Java언어의 목표는 다음과 같습니다.
-
Simple, Object Oriented, and Familiar
C의 구문과 C++의 구조와 비슷하게 개발하고자 노력한 결과로는, C++에서 불필요하게 복잡한 부분들을 줄이고, 객체지향적인 요소들을 남기면서 새로운 Java 개발자가 쉽게 언어에 친숙해질 수 있도록 노력하였습니다. -
Robust and Secure
컴파일 시점과 런타임 시점에 모두 코드 검사를 하기에 신뢰성이 높습니다. 또한 new 연산자를 통해 객체를 생성하고, 포인터를 관리할 필요가 없어 메모리를 사용하기 쉽습니다. 또한 자동으로 진행되는 Garbage Collection으로 메모리 관리가 자동적으로 진행됩니다. 분산 환경에서도 코드의 수정을 시도하고자 하여도 런타임 시점에 보안이 적용되기 때문에 secure하게 실행할 수 있습니다. -
Architecture Neutral and Portable
Java는 다양한 OS와 다양한 프로그래밍 언어 인터페이스에서 사용할 수 있도록 설계하고자 했습니다. 따라서 Java의 컴파일러는 바이트코드로 컴파일하여 다양한 하드웨어/소프트웨어 플랫폼에 지원 가능하도록 하였습니다. 하드웨어에 의존적인 JVM을 통해 JVM에서 돌아가는 Java코드는 동일하게 작동하도록 합니다. 특히 JVM은 IEEE의 POSIX 명세에 근거하여 설계되었습니다. -
High Performance
Java는 인터프리터가 런타임 환경을 체크할 필요가 없어 성능 면에서도 우수합니다. 또한 Garbage Collection을 수행하는 쓰레드는 낮은 우선순위로 운영되기 때문에 효율적으로 메모리 운영을 하게 됩니다. 특정 부분에서는 또한 native machine code로 유동적으로 대체할 수 있기 때문에 과부하가 일어날 수 있는 부분에 대한 유연한 대처도 가능합니다. -
Interpreted, Threaded, and Dynamic
앞서 자바 컴파일러가 컴파일하여 나온 결과물인 바이트코드를 JVM 내부에 있는 인터프리터가 한 줄씩 읽어 실행하기 때문에 인터프리터만 존재하는 방식보다는 속도가 빠릅니다. 또한 멀티쓰레드 방식을 통해 concurrent하게 발생하는 일들을 한번에 처리할 수 있습니다.
또한 자바의 클래스 간 연결은 사용하는 그 시점에서 연결되기 때문에 동적으로 배정된다는 특징이 있습니다. 이에 대해서는 static에 대한 개념을 이해해야 하는데, 아래에서 설명하도록 하겠습니다.
컴파일러와 인터프리터
컴파일러는 소스코드를 바이트코드로 변환합니다.(.class 파일) 컴파일러는 소스코드를 미리 분석하여 만들어두기 때문에 실행 중 속도가 매우 빠르고, 한번 변환된 바이트코드를 여러번 쓸 수 있어 효율적입니다.
하지만 컴파일러는 코드의 변경이 발생하면 다시 컴파일을 해야합니다. 인터프리터는 컴파일 없이도 각 줄을 바로 실행할 수 있어 개발이나 디버깅 시 더 유리합니다.
자바는 처음엔 인터프리터만 가지고 있었지만, 하드웨어에 독립적이기 위해서 컴파일러를 두어 둘의 장점을 모두 가지도록 하였습니다.
위에서 정말 중요한 내용들이 나왔습니다.(빨간색으로 표시된 부분들) 저도 그랬듯, 프로그래밍을 조금이라도 해보신 분들은 얼핏 알고 있겠지만 조금만 깊게 파보면 생각할 부분들이 많습니다.
코드 검사
자바는 컴파일 시점과 런타임 시점에 모두 검사를 합니다. 예시를 통해 확인해보겠습니다.

먼저 2개의 파일 test.java와 move.java를 생성했습니다.
Move.java
public class Move {
public void print() {
System.out.println("this is move");
}
}Test.java
public class Test {
public static void main(String[] args) {
Move move = new Move();
System.out.println("hello, test");
move.print();
}
}TMI. 컴파일 의존성
이제 두 파일을 컴파일 해보겠습니다.

먼저 javac Move.java만 실행한다면 Move.java 파일에 대해서만 컴파일된 바이트코드가 생성된 것을 확인할 수 있습니다.
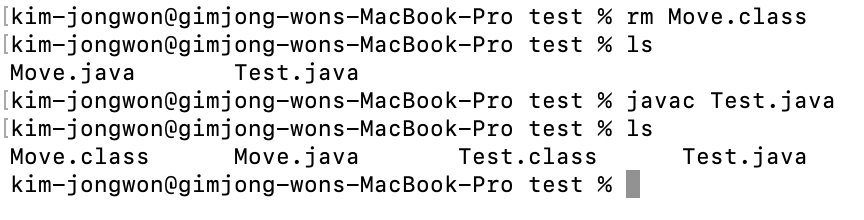
하지만 Test.java파일을 컴파일하여 javac Test.java를 실행하면 Move.class와 Test.class파일이 모두 생성되는 것을 확인할 수 있습니다.
컴파일러의 동작 과정 중 Semantic Check 단계에서 클래스 의존성을 검사하고 그 클래스의 바이트코드 파일이 존재하지 않는다면 컴파일하여 오류 발생을 없앱니다.
보통의 컴파일러의 동작 순서는 아래와 같습니다.
각각을 번역하면 어휘분석, 구문분석, 중간코드 생성, 코드 최적화, 목적코드 생성(기계어, 바이트코드)라 할 수 있습니다.
하지만 Java는 앞서 말했듯이 인터프리터와 컴파일러가 모두 존재하는 프로그램이기 때문에 중간 코드 생성 단계에서 나온 결과인 바이트코드(.class파일)을 JVM에서 읽어 인터프리터나 JIT 컴파일러로 바로 실행하여 기계어를 만듭니다.

하지만 설계의 측면에서 컴파일 타임에 의존성이 생기는 것은 객체지향적인 설계에서 지양해야 하는 부분입니다. 망나니개발자님의 블로그를 참고해주세요.
...
TMI. javac를 사용하지 않고 컴파일(Launch Single-File Source-Code Programs)
Java 11이후부터 javac를 이용하여 컴파일하지 않고 바로 java Test.java를 실행해도 자동적으로 컴파일을 하고 실행해줍니다.

그 이유는 공식문서에서 확인할 수 있습니다. JVM이 자동적으로 실행하고자 하는 파일을 메모리에 컴파일해두고, 가장 첫번째로 만나는 main() 메서드에 대해 실행을 합니다. 물론 이 방식의 단점은 아래와 같습니다.
-
컴파일 의존성을 가진 클래스가 컴파일되어있지 않다면 실패합니다. Single File이 더이상 아니기 때문입니다.

-
클래스명과 파일명이 달라도 컴파일됩니다. 클래스명과 관계없이 파일의 가장 첫번째 main()을 찾는 방식이기 때문입니다.

단점도 있지만 단일 파일에 대해서 빠른 테스트를 진행할 수 있다는 점에서 획기적입니다.
본론으로
본론으로 돌아와서 Main.java 클래스를 새로 만들어보겠습니다.
Main.java
public class Main {
public static void main(String[] args) {
System.out.println("hello, main");
int x = 0;
for(int i = 0; i < 10; i++) {
x++;
}
System.out.println("x=" + x);
Move move = new Move();
System.out.println("bye Main");
move.print();
}
}그리고 컴파일한 뒤 Move 클래스파일을 지워보겠습니다.

처음부터 에러를 반환할까 런타임에서 에러를 반환할까?

잘보면 Main의 코드를 실행하다가, Move move = new Move(); 이 Line을 실행할 때 에러가 난 것을 확인할 수 있습니다.
🔥 자바는 컴파일 시점에 1번 검사를 하고, 이후 나온 바이트코드를 신뢰하여 JVM이 실행하는데, 이때 런타임 시점에 오류가 있는지 인터프리터가 검사를 한다. 🔥
new 연산자, static 연산자, 그리고 메모리구조
new 연산자는 객체를 생성하고, static 연산자는 전역적으로 접근할 수 있는 것을 만드는 거 아니야?
맞는 말이긴 하지만 좀 더 구체적으로 파헤쳐 보겠습니다.
Java Data Area 메모리 구조

static과 new의 방식을 이해하려면 자바의 런타임 메모리 구조에 대해 먼저 알고 있어야 합니다.
자바를 실행시키는 JVM은 런타임에 위의 그림과 같이 데이터를 저장할 수 있는 공간을 나누어 관리합니다. 그중에서 Heap과 Method Area는 쓰레드 간 공유가 가능하고, 나머지 Stack, PC 레지스터, Native Method Stack는 쓰레드 내에서 관리합니다.
이중에서 new 연산자와 static 연산자와 밀접한 관련이 있는 부분은 바로 Heap영역입니다.
Heap
힙 영역은 객체가 할당되는 메모리 영역입니다. 자바의 객체와 JRE는 힙 영역에 저장되고, 객체에 대한 주소는 stack 영역에 저장됩니다. 힙 영역의 데이터는 new 연산자로 생성된 변수나 클래스입니다. 이를테면 어떤 메서드에서 new 연산자로 배열을 선언했다면, 이 주소를 이용하여 다른 메서드에서도 사용할 수 있습니다.
이러한 이유로 힙 영역은 여러 메서드에서 공유하는 데이터이며, 소멸의 시점은 메서드 종료 시점이 아닌, 사용하지 않는 시점입니다. 때문에 여기서 GC(Garbage Collection)의 역할이 필요해집니다.
힙 영역
가비지 컬렉션에 대한 이야기는 좀 더 아래에서 진행하기로 하고, 먼저 GC의 대상이 될 영역에 대해 언급하고자 합니다.
힙 영역은 크게 2가지로 나눌 수 있습니다.
- Young Generation
- Eden Space: 새로 생성된 객체가 배정되는 공간입니다.
- Survivor Space: 에덴 영역에 있는 객체 중 일부 객체가 살아남아야 하는 경우 이 공간으로 이동합니다. 2개의 영역으로 나뉘며, 한쪽만 사용합니다. GC를 통해 살아남아야 하는 객체를 빈 공간에 배정합니다.
- Old or Tenured Generation: 일정 시간이상 살아남은 객체를 이곳에 저장하여, 좀 더 긴 주기의 GC 대상으로 분리합니다.
어떤 글에서는 Permanent Generation도 힙 영역의 일부로 보고 있지만, 대부분의 경우 이는 힙과는 별도의 영역이라고 보고있기 때문에 참고하시면 좋을 것 같습니다.
Method Area
메소드 영역에는 클래스 정보, 메소드 코드, 필드, 메소드 데이터가 저장됩니다. 즉, 컴파일의 결과로 나온 클래스 파일의 바이트코드가 로드되는 영역입니다. 처음 프로그램을 실행한다면 main메서드와 이와 연관된 static 변수들이 있는 클래스가 메서드 영역으로 올라올 것입니다.
이렇게 클래스파일이 메서드 영역에 올라가는 것을 Class Loading이라고 합니다. 이때, 클래스가 다른 클래스를 호출한다면, 호출하는 시점에서 다른 클래스파일이 메서드 영역으로 올라가게 될 것이고, 이것을 클래스 로딩이라고 합니다.
이때 위에서 언급한 런타임 시점에서의 컴파일 오류 검증이 진행됩니다. 다른 클래스의 메서드를 호출하는 시점에서 Class Loading시, 바이트코드 검증을 진행하는 것입니다.
Stack Area
스택 영역은 말그대로 알고리즘에서 들은 스택과 동일한 동작을 합니다. 이곳에는 지역변수와 매개변수, 클래스의 주소값이 저장이 됩니다. 메서드 블록 내에서 필요한 지역변수들을 저장하고 있으며, 다른 메서드를 호출할 때 전달할 매개변수와 리턴값을 스택에 쌓아두고 메서드를 호출합니다. 실행이 끝나면 pop을 통해 리턴할 메서드의 주소를 찾아내고, 프로그램을 이어가게 됩니다.
다른 영역과의 차이는 스택 영역의 데이터는 메서드 호출이 끝났다면 데이터는 사라진다는 것입니다. 쉽게 생각하면, 지역변수와 같은 경우에는 메서드 호출이 끝나면 더이상 쓸 일이 없는 주소이기 때문에 저장할 필요가 없습니다.
Garbage Collection(GC)
가비지 컬렉션에서 Garbage는 더이상 사용되지 않는 메모리입니다. 어떤 주소를 가리키고 있는 변수가 다른 주소를 가리키게 된다면, 이전의 주소 위치에 해당하는 메모리는 어떤 변수도 참조할 수 없게 됩니다. 이를 쓰레기값(Garbage)라고 하는데, JVM에서는 이런 더이상 사용하지 않는 메모리를 찾아 회수하는 GC 작업을 하게 됩니다.
GC의 대상은 Heap 영역의 메모리입니다. 앞서 Heap영역은 크게 Young Generation과 Old Generation으로 나눌 수 있다고 했는데, 가비지 컬렉션도 크게 2가지로 나눌 수 있습니다.
1. Minor GC
Young Generation공간의 메모리 GC로 Eden Space의 공간이 가득 차게되면 실행됩니다. 이때 살아남은 대상은 Survivor영역으로 이동합니다.
Survivor 영역은 2개인데, 이는 모두 사용하는 것이 아니라, Survivor영역에서 GC가 발생했을 때 살아남은 대상들을 모두 빈 Survivor로 옮기고, 새로 채워진 Survivor영역으로만 Eden Space에 있던 데이터들을 넣는, 이동을 위해서만 존재하는 영역입니다.
(출처: 네이버D2)
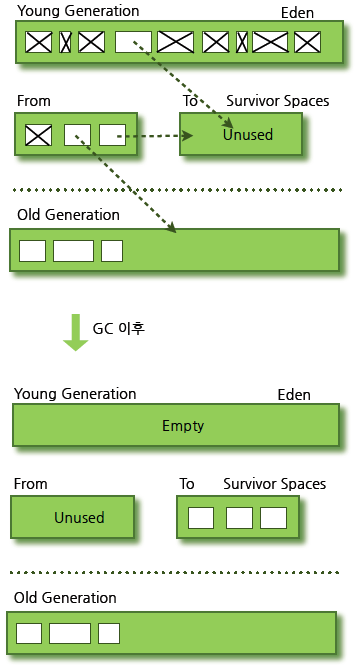
2. Major GC
Old Generation 공간의 메모리 GC입니다. 이 역시 Old Generation 영역이 가득 찼을 때 동작합니다.
현재는 여러 GC 알고리즘 중 G1(Garbage First) GC를 사용하고 있습니다.
G1 GC
G1 GC는 물리적인 Heap을 Region으로 분리한 것입니다.
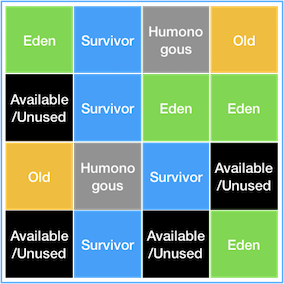
이렇게 Region으로 나눔으로써 장점은 Eden Space 전체, Survivor Space전체가 아닌 조그마한 region만 GC의 대상으로 되기 때문에 속도가 빨라집니다. 또한 연속적인 공간을 가진 것이 아니기 때문에 거대한 힙 영역을 관리하기에 효율적입니다.
참고자료
https://en.wikipedia.org/wiki/Java_(programming_language)
컴파일러와 인터프리터: https://sunrise-min.tistory.com/entry/컴파일-언어와-인터프리터-언어의-차이-Java는-어떤-언어인가
힙 영역 구조: https://www.baeldung.com/java-stack-heap
static storage: https://www.baeldung.com/jvm-static-storage
