(번역) 번들러 트리 셰이킹의 원칙과 차이점

트리 셰이킹은 현대 프런트엔드 번들링에서 매우 중요하고 필수적인 부분이 되었습니다. 다양한 번들러 간 적용 시나리오와 중점 영역의 차이로 인해 트리 셰이킹 구현 방식도 상이합니다. 예를 들어, 웹팩(webpack)은 주로 프런트엔드 애플리케이션 번들링에 사용되며 정확성을 중시합니다. 웹팩의 트리 셰이킹은 모듈 간 수준에서의 최적화에 초점을 맞춥니다. 또한, 롤업(Rollup)도 주로 라이브러리 번들링에 사용됩니다. 하지만, 롤업은 최적화 효율성을 우선시합니다. 예를들어, AST 노드 단위의 세밀한 수준에서 트리 셰이킹을 수행하여 일반적으로 결과물의 번들 크기가 더 작습니다. 그러나 특정 극단적인 경우의 실행 정확성에 대한 보장이 부족할 수 있습니다.
이 글은 다양한 번들러의 트리 셰이킹 원리와 그 차이점에 대한 간략한 개요를 제공합니다.
트리 셰이킹이란 무엇인가: 애플리케이션을 나무로 상상해 보세요. 실제로 사용하는 소스 코드와 라이브러리는 나무의 푸르고 살아있는 잎을 나타냅니다. 데드 코드는 가을에 떨어져 버려지는 갈색의 죽은 잎을 상징합니다. 죽은 잎을 제거하려면 나무를 흔들어 떨어뜨려야 합니다.
웹팩/Rspack에서의 트리 셰이킹
현재 Rspack(v1.4)은 웹팩과 동일한 트리 셰이킹 구현 방식을 따르고 있으므로, 아래 설명에서는 웹팩의 구현 방식을 예시로 사용하겠습니다. 동시에 향후 Rspack 버전에서는 더 효율적인 트리 셰이킹 전략을 적극적으로 모색 중입니다.
웹팩의 트리 셰이킹은 세 부분으로 구성됩니다.
-
모듈 수준:
optimization.sideEffects사용되지 않은 내보내기와 사이드 이펙트가 없는 모듈을 제거합니다.-
import “./module”;내보내기된 항목을 사용하지 않으며 사이드 이펙트가 없으므로./module을 안전하게 제거할 수 있습니다. -
re-exports.js(배럴 파일) 자체는 로컬 내보내기 항목이 없으며 사용되고 있고 사이드 이펙트가 없으므로 re-exports.js를 안전하게 제거할 수 있습니다.// index.js import { a } from "./re-exports"; console.log(a); // re-exports. export * from "./module"; // `index -(a)-> re-exports -(a)-> module`이 `index -(a)-> module`로 최적화되었으며, re-exports.js 자체는 로컬 내보내기가 없으며 사용되고 있고, 사이드 이펙트가 없으므로 re-exports.js는 안전하게 제거할 수 있습니다. // module.js export const a = 42;
-
-
export-level:
optimization.providedExports및optimization.usedExports를 사용하여 사용되지 않는 내보내기 항목 제거optimization.providedExports: 모듈이 제공하는 내보내기 항목 분석optimization.usedExports: 모듈 내보내기 항목 중 실제 사용되는 항목 분석. 코드 생성 시 미사용 내보내기 제거 가능.export const a = 42=>const a = 42. 이후 SWC나 Terser 같은 미니마이저가 해당 변수가 모듈 내부에서도 미사용일 경우 남은 선언을 추가로 제거할 수 있음
-
코드 레벨:
optimization.minimizeSWC나 Terser 같은 코드 압축기를 사용해 인라인 처리 및 평가 같은 기법으로 코드를 분석하고, 불필요한 코드를 제거하며 압축을 수행하여 번들 크기를 최대한 줄입니다.optimization.minimize플러그인을 통해 코드 압축기가 번들러와 통합되며, 번들러의 핵심 책임 범위를 벗어난 번들러 출력물에 대한 후처리를 수행합니다.
또한 정적 분석도 중요한 부분입니다. 모듈 레벨 및 내보내기 레벨 최적화 모두 웹팩이 코드에 대한 정적 분석을 수행하여 모듈에 사이드 이펙트가 있는지, 어떤 내보내기가 포함되어 있는지, 그리고 실제로 사용되는 내보내기가 무엇인지 판단해야 합니다. 이 정보는 최적화 단계의 입력값으로 활용됩니다.
이론적으로, 웹팩의 자바스크립트 파서가 이러한 정보를 정적으로 내보내기 할 수 있다면 트리 셰이킹은 적용 가능합니다. 본질적으로 동적인 CommonJS 및 동적 임포트에도 마찬가지입니다. 이러한 구문이 정적 패턴을 따르고 필요한 정보를 정적으로 추론할 수 있다면 트리 셰이킹은 여전히 가능합니다.
그러나 현재 웹팩은 CJS와 동적 임포트를 포함한 극히 제한된 시나리오에 대해서만 정적 분석을 수행합니다. 분석 가능한 많은 사례가 최적화되지 않은 채로 남아 있어 개선의 여지가 상당합니다.
이 세 단계가 완료되면 트리 셰이킹은 이미 기능하지만, 특정 사례에서는 여전히 문제가 발생할 수 있습니다.
-
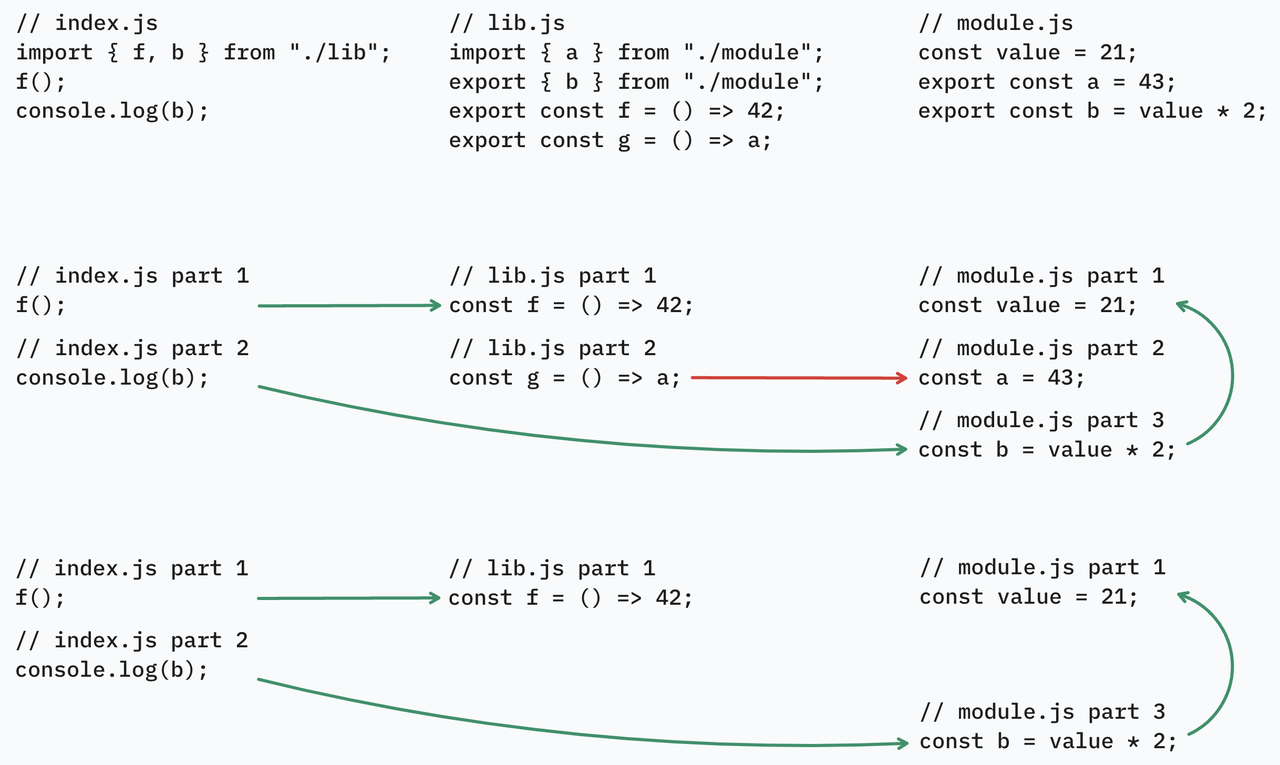
다른 모듈의 사용되지 않은 내보내기
g가 내보내기a를 참조하고 있어a가 트리 셰이킹되지 못합니다. 이 경우lib.js내 최상위 문장 간의 의존성 관계를 분석하려면optimization.innerGraph가 필요합니다.a를 포함하는 최상위 문장이 사용될 때만 내보내기a는 사용된 것으로 표시되며, 그렇지 않으면 사용되지 않은 것으로 간주됩니다.// index.js import { f } from "./lib"; f(); // lib.js import { a } from "./module"; export const f = () => 42; export const g = () => a; // `g`가 사용되지 않으므로 `const g = () => a`를 생성하면 `a`가 참조되어 `a`가 트리 셰이킹되지 못하게 됩니다. // module.js export const a = 42; -
웹팩이 각 모듈을 함수로 래핑하는 런타임 특성으로 인해, 일부 최적화 가능한 경우도 미니파이어로 최적화할 수 없습니다.
예를 들어, 다음과 같은 경우 아래처럼 처리할 수 있습니다.// index.js import { aVeryLongLongLongName } from "./constants.js"; console.log(aVeryLongLongLongName ? 1 : 2); // constants.js export const aVeryLongLongLongName = 42; // 웹팩 번들링 후 // output.js const __webpack_modules__ = { "./index.js": (__webpack_require__) => { const _constants__WEBPACK_MODULE__ = __webpack_require__("./constants.js"); console.log(_constants__WEBPACK_MODULE__.A ? 1 : 2); }, "./constants.js": (__webpack_require__) => { __webpack_require__.d({ A: () => A, }); const A = 42; }, };-
일반적으로
optimization.concatenateModules를 통해 해결할 수 있으나, 복잡한 시나리오에서는 연결이 가능한 모듈 수가 상당히 제한되는 경향이 있습니다.// `optimization.concatenateModules`를 활성화하면 출력이 압축 도구에 더 적합해져 더 나은 압축과 더 작은 번들 크기를 가능하게 합니다. // 연결된 모듈: ./constants.js const A = 42; // 연결된 모듈: ./index.js console.log(A ? 1 : 2); // 이제 이 코드는 압축기로 최적화할 수 있습니다.
-
-
미니파이어는 망글링을 통해 변수 이름을 효과적으로 줄일 수 있지만, 이 래퍼 함수는 내보내기 모듈 변수의 망글링을 방지합니다. 이때
optimization.mangleExports가 망글링 처리를 담당합니다.// output.js const __webpack_modules__ = { "./index.js": (__webpack_require__) => { const _module__WEBPACK_MODULE__ = __webpack_require__("./constants.js"); - console.log(_constants__WEBPACK_MODULE__.aVeryLongLongLongName ? 1 : 2); + console.log(_constants__WEBPACK_MODULE__.a ? 1 : 2); }, "./constants.js": (__webpack_require__) => { __webpack_require__.d({ - aVeryLongLongLongName: () => aVeryLongLongLongName, + a: () => aVeryLongLongLongName, }) const aVeryLongLongLongName = 42; } } -
추가적인 최적화, 예를 들어 Rspack v1.4에서 도입된
experiments.inlineConst등이 있습니다.// output.js const __webpack_modules__ = { "./index.js": (__webpack_require__) => { console.log(42 ? 1 : 2); // 이제 이 코드는 압축기로 최적화할 수 있습니다. }, };
esbuild에서의 트리 셰이킹
esbuild의 트리 셰이킹은 다음 단계를 포함합니다.
- 각 모듈을 최상위 문으로 분할하고, 각 최상위 문을 하나의 파트로 처리합니다.
- 각 파트에서 정의된 변수와 다른 파트에서 사용되는 변수를 분석한 후, 모듈 임포트(import)를 해당 내보내기에 연결합니다.
- 진입 모듈의 부분부터 상향식 탐색을 수행합니다. 다른 부분에서 사용되거나 사이드 이펙트를 가지는 부분은
IsLive = true로 표시합니다. - 코드 생성 시
IsLive = true로 표시된 부분만 포함하고, 표시되지 않은 부분은 제거합니다.
자세한 내용은 esbuild/docs/architecture/tree-shaking을 참조하십시오.
esbuild는 최상위 레벨 문장을 미리 분할함으로써 본질적으로 innerGraph 문제를 해결합니다. 분할 후 각 상위 레벨 문장은 파트로 전환되어, 모듈 레벨에서 작동하는 웹팩과 달리 파트 레벨 세분화에서 분석 및 최적화가 가능해집니다. 이 접근 방식은 다음과 같은 주요 이점을 제공합니다.
- imported/exported 변수뿐만 아니라 모듈 내 변수도 분석하여, 웹팩이 innerGraph를 통해 수행해야 하는 작업을 포괄합니다.
- 모듈 내 최상위 문장(부분 레벨)에 모듈 수준의 번들러 최적화를 적용합니다. 예를 들어, esbuild의 사이드 이펙트 최적화는 사용되지 않고 사이드 이펙트가 없는 최상위 문장을 제거할 수 있지만, 웹팩은 모듈 수준 제거만 수행할 수 있습니다.
초기 버전의 esbuild도 이러한 최상위 문이 코드 분할(현재 “모듈 분할”이라 부름)에 참여하도록 허용했습니다. 그러나 esbuild는 모듈 로딩과 실행을 분리하는 웹팩 출력처럼 각 모듈을 함수로 감싸지 않아 최상위 await 처리에 어려움을 겪었습니다. 결국 esbuild는 모듈 분할 지원을 중단했습니다.
현재 esbuild/docs/architecture/code-splitting은 여전히 모듈 분할을 지원하는 버전을 설명합니다. 코드 분할은 파트 레벨에서 수행되며, 공유 청크에는 두 진입점 모두에 공통된 최상위 문만 포함됩니다. esbuild 플레이그라운드의 복제본을 보면 공유 청크에 두 진입점이 공유하는 모듈이 포함되어 있으며, 코드 분할이 모듈 레벨에서 이루어짐을 확인할 수 있습니다.

| 모듈 분할을 지원하기 이전의 결과
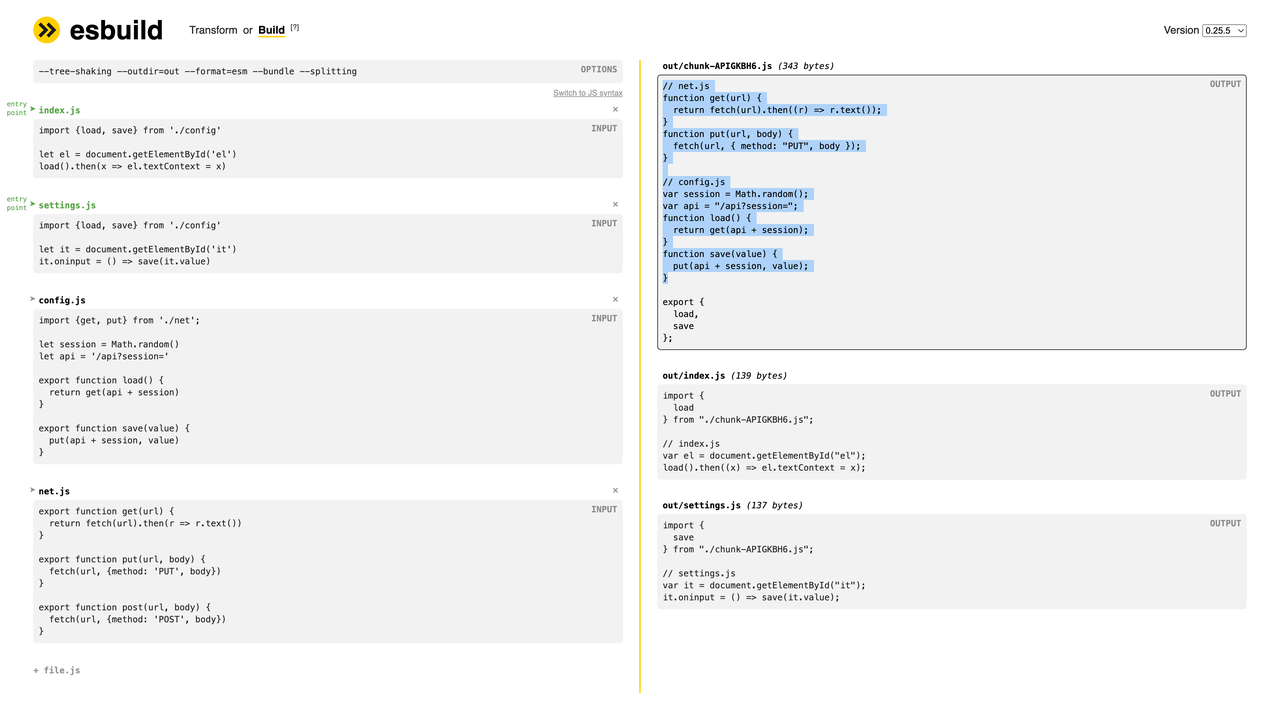
| 이제 더 이상 모듈 분할을 지원하지 않는 결과
또한 최상위 await를 제외하고, esbuild의 모듈 분할에서 발생한 또 다른 복잡성은 모듈 로딩과 실행을 분리하지 않았기 때문이었습니다. ES 모듈의 정적 임포트는 읽기 전용입니다. 이는 코드 분할 과정에서 esbuild가 변수 할당을 해당 변수 선언과 다른 청크로 이동시킬 수 없음을 의미했습니다. esbuild가 모듈 분할을 포기한 후, 이 문제는 더 이상 특별한 처리가 필요하지 않게 되었습니다.
터보팩(Turbopack)에서의 트리 셰이킹
모듈 분할은 실제로 웹팩과 같은 번들러에 더 적합합니다. 웹팩은 모듈 로딩과 실행을 분리할 수 있어, 모듈 내 변수 선언 및 사용에 대한 추가 처리 없이도 모듈 실행의 정확성을 본질적으로 보장합니다.
또한 모듈 내 최상위 문장에 더 많은 모듈 레벨 최적화를 적용할 수 있게 합니다. 예를 들어 esbuild가 지원하지 않거나 성능이 떨어지는 최적화들. 코드 분할, 런타임 최적화, 청크 분할 등, 이를 통해 추가적인 최적화가 가능해집니다.
그렇다면 웹팩과 유사한 런타임(모듈 로딩과 실행 분리)과 모듈 분할 지원을 결합한 번들러가 있을까요? 바로 터보팩(Turbopack)입니다.
먼저, 터보팩의 출력 형식이 어떻게 챕터 간 변수 할당 및 선언을 허용하지 않는 문제를 해결하는지, esbuild 번들링 결과 예시를 통해 살펴보겠습니다.
// 추신: 터보팩의 관련 코드는 단순화 및 수정되었습니다. 현재 터보팩은 청크 분할 결과를 세밀하게 제어할 수 있는 구성을 아직 제공하지 않습니다.
// chunk for entry1.js
module.exports = {
"entry1.js": (`__turbopack_context__`) => {
var _data_1__TURBOPACK_MODULE__ =
__turbopack_context__.i("data.js <part 1>");
console.log(_data_1__TURBOPACK_MODULE__.data);
},
};
// chunk for entry2.js
module.exports = {
"entry2.js": (__turbopack_context__) => {
var _data_2__TURBOPACK_MODULE__ =
__turbopack_context__.i("data.js <part 2>");
_data_2__TURBOPACK_MODULE__.setData(123);
},
"data.js <part 2>": (__turbopack_context__) => {
__turbopack_context__.s({
setData: () => setData,
});
var _data_1__TURBOPACK_MODULE__ =
__turbopack_context__.i("data.js <part 1>");
function setData(value) {
_data_1__TURBOPACK_MODULE__.data = value; // <--- 여기서 setter 트리거
}
},
};
// 공유 코드용 청크
module.exports = {
"data.js <part 1>": (__turbopack_context__) => {
__turbopack_context__.s({
data: [
() => data, // <--- getter
(new_data) => (data = new_data), // <--- setter
],
});
let data;
},
};터보팩은 웹팩과 유사한 출력 형식을 사용하며, 각 모듈을 함수로 감싸 모듈 로딩과 실행을 분리합니다. 그러나 웹팩과 달리 모듈 내보내기를 정의하는 런타임 __turbopack_context__.s는 내보내기 값을 가져오는 getter뿐만 아니라 추가적인 setter도 포함합니다. 모듈의 다른 부분에서 이러한 변수에 할당 작업을 수행하면 해당 setter가 트리거 되어 값을 업데이트함으로써 올바른 실행을 보장합니다.
최상위 await의 경우, 웹팩과 마찬가지로 터보팩은 런타임을 활용하여 최상위 await를 포함하는 모듈과 그 의존성 모듈의 올바른 실행 순서를 보장합니다. 예를 들어, data.js의 첫 번째 줄에 await 1;을 추가하면 번들링 된 출력은 다음과 같습니다.
// 공유 코드용 청크
module.exports = {
// ...
"data.js <part 0>": (__turbopack_context__) => {
__turbopack_context__.a(
async (
__turbopack_handle_async_dependencies__,
__turbopack_async_result__
) => {
try {
await 1; // <--- 추가된 `await 1;`은 최상위 await가 올바르게 실행되도록 보장하기 위해 __turbopack_context__.a 런타임에 의해 감싸집니다.
__turbopack_async_result__();
} catch (e) {
__turbopack_async_result__(e);
}
},
true
);
},
// ...
};물론 모듈 분할에도 단점이 존재합니다. 분할 후 출력물의 최상위 문장 각각은 함수로 감싸집니다. 이는 올바른 실행을 보장하지만, 이러한 래핑 방식의 단점을 증폭시킵니다.
- 이러한 래퍼 함수의 과도한 중복은 번들 크기를 증가시킵니다(gzip으로 이 오버헤드를 효과적으로 줄일 수 있음).
_data_0__TURBOPACK_MODULE__.data와 같은 객체 속성을 통해 접근해야 하는 변수가 증가하여 런타임 성능이 저하될 수 있습니다(이는 여전히 최신 브라우저 벤치마크를 통한 검증이 필요합니다).
두 문제 모두 최적화를 위해 스코프 호이스팅에 대한 의존도를 높여야 합니다.
롤업(Rollup)에서의 트리 셰이킹
웹팩이 내보내기 문과 모듈에 대해 트리 셰이킹을 수행하고, esbuild가 최상위 문에 대해 이를 수행한다면, 롤업은 모든 문과 더 세분화된 AST 노드에 대해 상위에서 하위로 트리 셰이킹을 수행하며, 더 정밀한 사이드 이펙트 감지 기능을 제공합니다.

| Rollup은 문장과 일부 더 세분화된 AST 노드에 대해 트리 셰이킹을 수행합니다.
Rollup의 트리 셰이킹은 esbuild와 유사하지만 약간의 차이가 있습니다. 프로세스는 다음과 같이 진행됩니다.
-
모듈에
include()를 호출하여 시작합니다. -
최상위 AST 노드부터 시작합니다.
a. AST 노드에 사이드 이펙트가 있는지 판단합니다.
b. 있다면include()를 호출합니다.
c. 관련 AST 노드에 대해 사이드 이펙트 확인과include()를 계속 수행합니다(a, b 단계 반복). -
탐색 후, new AST 노드가
include()된 경우 새 탐색을 트리거합니다(1, 2단계).
2.c 단계에서 “관련 노드”란 다음을 의미합니다. 특정 노드의 자식 노드, 변수 사용에 대응하는 변수 선언 노드, 그리고 객체
obj의 선언 및 속성a와b에 접근할 때obj.a.b와 같은 속성에 대한 노드.
롤업은 다음과 같은 이유로 다른 번들러에 비해 더 우수한 트리 셰이킹 결과를 달성합니다.
- 더 세분화된 분석: 롤업은 AST 노드 레벨에서 코드를 분석하고 제거하는 반면, 다른 번들러는 일반적으로 최상위 문 레벨 또는 더 거친 세분성으로 작동하여 더 세분화된 불필요한 코드 제거(DCE)는 미니파이어에 맡깁니다.
- 보다 정밀한 사이드 이펙트 분석: 사이드 이펙트는 컨텍스트를 인식하며 AST 노드 레벨에서 평가됩니다. 반면 다른 번들러들은 더 거친 수준에서 컨텍스트와 무관하게 사이드 이펙트를 분석합니다.
롤업의 세분화된 접근 방식은 본질적으로 내보내기 및 최상위 문에 대한 거친 분석을 포함합니다. 결과적으로 Rollup은 모듈 간 미사용 내보내기를 제거할 뿐만 아니라 모듈 내 DCE도 처리할 수 있습니다. 다음 논의는 모듈 내 DCE에 초점을 맞추며, 구체적인 사례를 통해 이 두 가지 점을 설명하겠습니다.
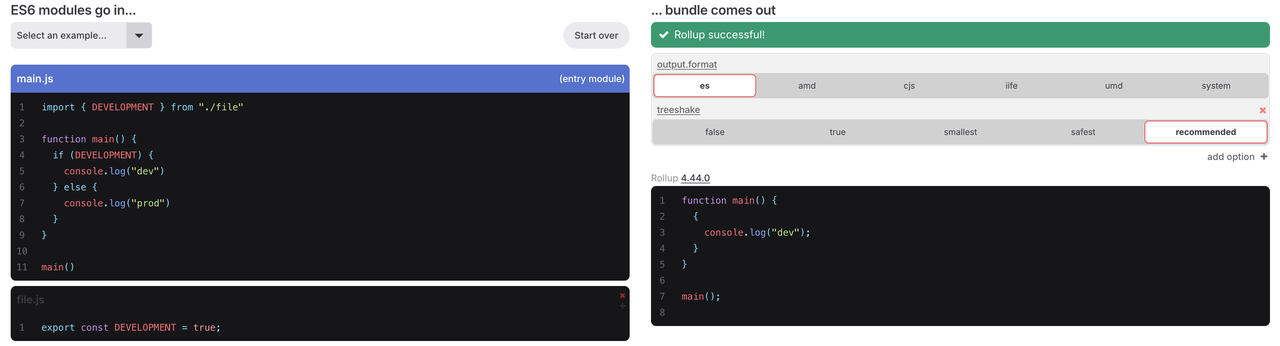
Rollup의 Define 기능은 다른 번들러와 다르게 구현됩니다. rollup-plugin-replace는 변환 단계에서 일치하는 Define 노드만 대체하는 반면, 웹팩과 esbuild는 파싱 단계에서 대체를 수행하며 죽은 분기도 분석합니다. 죽은 분기의 코드는 분석 과정에서 제외되며, 이 분기에 포함된 종속성은 모듈 그래프에 포함되지 않습니다. 그러나 파싱 단계에서의 이 죽은 분기 분석은 모듈 간에 걸쳐 수행될 수 없습니다.
Rollup의 트리 셰이킹은 AST 노드 레벨에서 작동하므로 함수 내부의 문장 노드도 트리 셰이킹 분석 대상이 될 수 있습니다. 따라서 Rollup은 분석의 일부를 트리 셰이킹 단계로 위임하며, 죽은 분기 제거 역시 트리 셰이킹에 의존합니다.
이 예시에서는 if (DEVELOPMENT) 내 DEVELOPMENT 변수에 대해 컴파일 시 평가를 시도합니다. 그 결과는 상수이므로 else 분기는 죽은 분기로 제거될 수 있습니다. 또한 file.js의 DEVELOPMENT 변수는 사용된 것으로 표시되지 않아 최종 트리 셰이킹에서 export const DEVELOPMENT 선언과 file.js 모듈을 제거할 수 있습니다.
이 접근 방식의 단점은, 죽은(branch가 타지 않는) 분기 안에서 도입된 의존성들도 여전히 모듈 그래프에 포함된다는 점입니다. 그 결과 더 많은 모듈이 끌려오고, Rollup이 처리해야 할 일이 늘어나 성능이 떨어지게 됩니다.
반면, 장점은 모듈을 가로지르는(cross-module) 분석과 죽은 분기 제거가 가능해진다는 것입니다. 이를 통해, 더 많은 미사용 코드를 제거하고 결과적으로 더 작은 출력 번들을 생성한다는 점입니다. 다른 번들러들은 스코프 호이스팅을 통해 모듈을 단일 스코프로 병합하고, 이러한 크로스 모듈 죽은 분기를 제거하기 위해 미니파이어에 의존합니다. 그러나 올바른 실행을 보장하기 위해 스코프 호이스팅을 포기해야 하는 모듈의 경우, 이러한 모듈을 최적화할 좋은 해결책이 없습니다. 이를 해결하기 위해서는 향후 최적화가 필요할 수 있습니다.
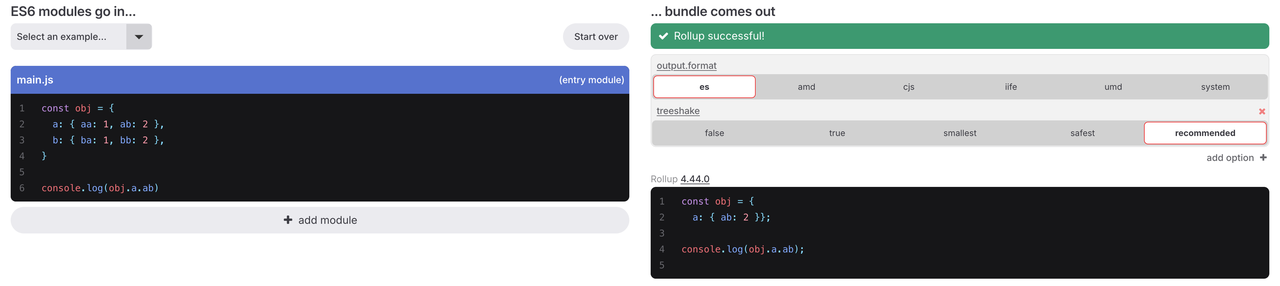
console.log(obj.a.ab)를 분석할 때 Rollup은 이 문장이 사이드 이펙트를 일으키므로 include() 대상으로 표시합니다. include(obj.a.ab) 실행 시 obj 선언 노드, a: 속성 노드, ab: 속성 노드 등 관련 노드들의 include()를 트리거합니다. AST 노드 레벨 트리 셰이킹 덕분에 Rollup은 사용된 a: 및 ab: 속성만 유지하고 다른 미사용 속성은 제거하여 더 작은 출력 번들을 생성할 수 있습니다.
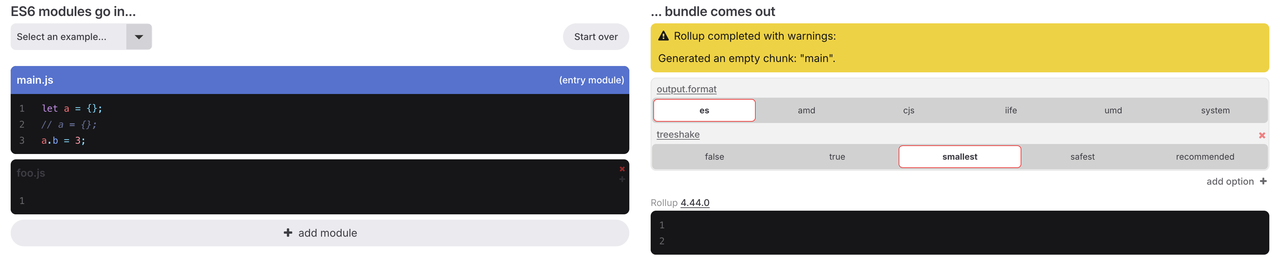
이 경우 a = {}를 주석 처리하면 모든 코드가 트리 셰이킹되는 것을 확인할 수 있습니다. 그러나 주석을 해제하면 트리 셰이킹이 더 이상 발생하지 않습니다. 이는 Rollup이 변수 a가 재할당되는지 여부에 따라 a.b = 3이 사이드 이펙트를 가지는지 판단하기 때문입니다. 이는 Rollup이 문맥 인식형 사이드 이펙트 분석을 수행할 수 있음을 보여줍니다. 다만 문맥 독립형 사이드 이펙트 분석에 비해 일정한 성능 오버헤드가 발생합니다.
그러나 이러한 문맥 인식형 사이드 이펙트 분석은 비교적 단순하며 일반적으로 특정 단순한 시나리오에서만 작동합니다. 예를 들어 위 사례에서는 재할당이 발생하는지만 확인하고, 재할당이 실제로 의미 있는 변화를 유발하는지 분석하지 않습니다. 즉 지나치게 깊거나 세부적인 분석을 피한다는 의미입니다.
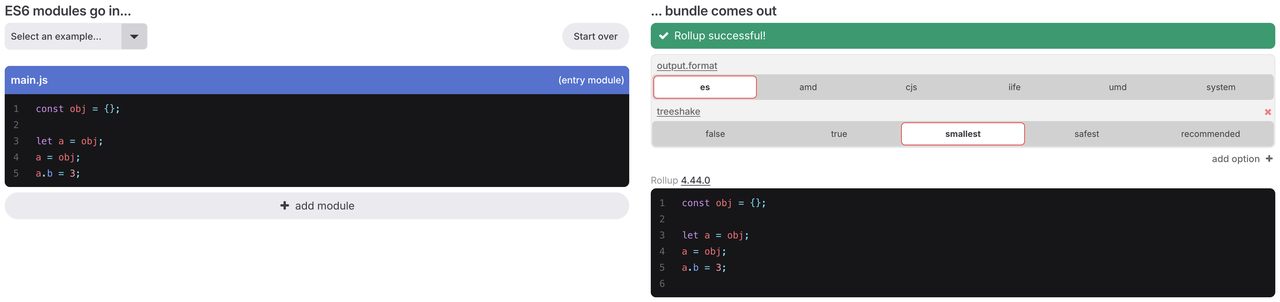
| 동일한 변수를 실제 변경 없이 재할당하더라도 a.b = 3은 여전히 사이드 이펙트를 가진 것으로 간주됩니다.
롤업 v3은 문장 수준 트리 셰이킹만 지원했지만, v4부터는 더 세분화된 AST 노드 레벨 트리 셰이킹(위에서 언급한 객체 속성 트리 셰이킹 등)을 실험하기 시작했으며, 특정 시나리오에서 사용되지 않는 노드 추적을 최적화하기 시작했습니다. 예를 들어봅시다.
- 트리 셰이킹 기능의 기본 매개변수, 다만 이후 너무 많은 예외 처리 시나리오로 인해 이 기능은 되돌려졌습니다.
- "상수 매개변수"를 기반으로 함수 내부의 죽은 분기를 제거하는 트리 셰이킹. 이 기능은 함수 기본 매개변수 트리 셰이킹에서 발전되었습니다. 동일한 변수를 사용하여 매개변수가 변경되지 않은 상태로 함수가 한 번 또는 여러 번 호출될 때, 매개변수에 사용된 변수를 분석하고 이를 기반으로 특정 최적화를 적용합니다.
이를 통해 더 많은 시나리오에서 트리 셰이킹이 가능해집니다.

이미지들이 깨져있습니다.