(번역) 나만의 아키텍처 구성하기
원문: https://itnext.io/choose-your-own-architecture-92c56b12f7b0
이 글은 현재 Leanpub과 GitHub에서 무료로 제공되는 제 저서 '아키텍처 메타 패턴: 소프트웨어 아키텍처의 패턴 언어'의 일부입니다. 어떤 피드백도 환영합니다.
이전 글에서 패턴을 결합과 응집으로 분해해 보았으니, 이제 프로젝트의 필요에 따라 아키텍처를 재구성해 볼 수 있습니다.
프로젝트 규모
프로젝트의 예상 규모는 프로젝트 아키텍처의 주요 결정 요인 중 하나로, 지나치게 많은 컴포넌트와 과도한 파편화는 개발 및 유지 관리에 장애가 되기 때문입니다. 적당한 규모의 안전지대(zone of comport)는 적당한 크기의 컴포넌트 수를 가집니다.
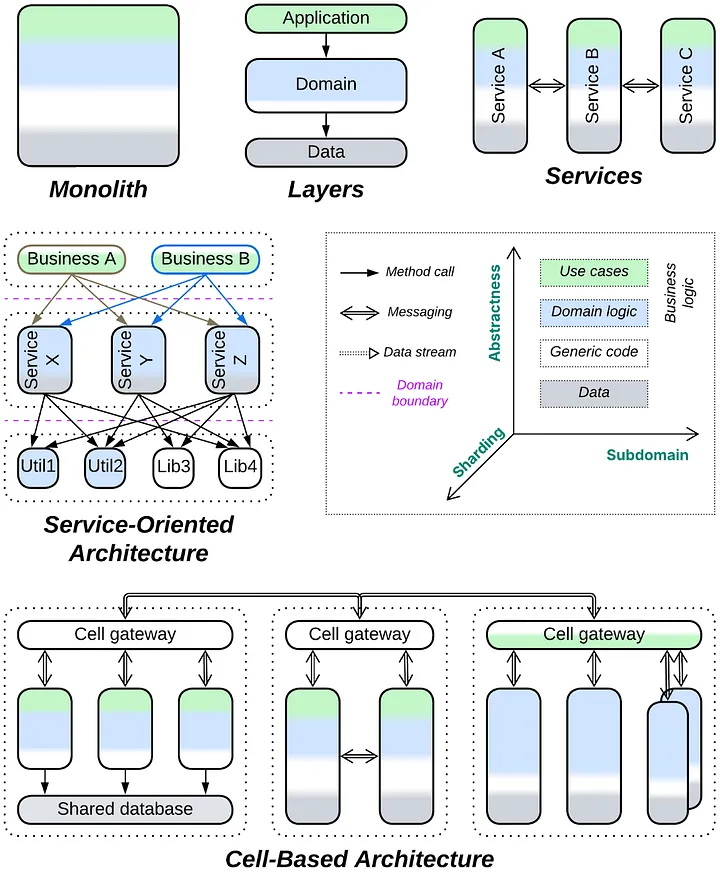
따라서 하루 만에 끝낼 수 있는 정도의 작업은 모놀리식이 될 가능성이 크고, 한 달 정도의 작업은 계층화가 필요하며, 그 이상의 작업은 적어도 부분적으로 하위 도메인 모듈이나 서비스로 분리해야 할 가능성이 높습니다. 매우 큰 프로젝트는 서비스 지향 아키텍처(SOA) 또는 셀 기반 아키텍처로 더 세분화해야 할 수도 있습니다.
초기 설계에서 고려해야 할 또 다른 요소는 도메인 내에 내재된 디커플링입니다. 예를 들어 도메인 로직이 있는 계층에는 개발 또는 런타임 비용이 거의 들지 않는 모듈이나 서비스를 자연스럽게 만드는 독립적인 하위 도메인이 포함될 가능성이 매우 높습니다. 마찬가지로 하향식 계층 구조는 계층형 도메인에 적합합니다. 데이터나 이벤트의 단계적 처리를 중심으로 구축되는 도메인은 매우 유연한 아키텍처 스타일인 파이프라인으로 모델링할 수 있습니다.
프로젝트를 시작할 때 함께하는 팀의 수도 중요합니다. 팀의 효율성을 최대한 높이려면 팀이 대부분 독립적으로 운영되는 것이 좋습니다. 각 팀에 하나 또는 두 개의 컴포넌트를 맡기고, 팀이 전문성을 가질 수 있도록 아키텍처에 충분한 모듈이나 서비스가 있어야 합니다. 공유되는 것은 병목현상이 될 수 있기 때문입니다. 예를 들어, 어떤 시스템에는 계층이 너무 많아 계층형 아키텍처에서는 3개 이상의 팀을 투입하기 어렵습니다. 따라서 팀 수가 많다는 것은 서비스, 파이프라인, SOA 또는 계층 구조 아키텍처가 적합합니다.
모든 팀이 0일부터 채용되는 것이 아니라 일부 팀이 나중에 채용되는 경우에도 이미 구현된 컴포넌트를 세분화하는 것은 끔찍한 경험이므로 예상되는 팀 수에 대한 컴포넌트 경계를 처음에 설정하는 것이 바람직합니다. 그러나 지금은 여러 컴포넌트를 단일 프로세스(모듈)로 실행하는 것이 더 쉽고 안전할 수 있으므로 분산으로 인한 오버헤드를 피하고 필요한 경우(새로운 요구 사항으로 인해 디자인에 문제가 생기는 경우가 많으므로) 코드 조각을 이동하는 데 어려움을 덜 겪을 수 있습니다. 필요하게 되면 모듈을 서비스로 만들기 위해 약간의 노력을 해야 합니다.
도메인 기능
위에서 계층형 또는 파이프라인 도메인을 통해 해당 아키텍처를 사용할 수 있다는 것을 이미 살펴보았습니다. 그 외에도 여러 가지가 있습니다.
모든 사용 사례가 전체 시스템에 걸쳐 여러 컴포넌트를 포함하므로 하위 도메인과 일치할 수 없는 복잡한 사용 사례가 많이 있을 수 있습니다. 일반적으로 글로벌 사용 사례로 전용 컴포넌트인 오케스트레이터로 수집합니다. 그리고 오케스트레이터가 통제할 수 없을 정도로 커지면 레이어 또는 서비스로 세분화됩니다.
다른 시스템은 데이터를 중심으로 구축됩니다. 대부분의 서비스가 전체적으로 접근해야 하므로 데이터를 개인 데이터베이스로 분할할 수 없습니다. 공유 저장 공간 또는 고성능 공간 기반 아키텍처가 필요합니다.
분산화되면 서비스 간의 통신을 중앙 집중화하기 위해 미들웨어를 사용할 겁니다. 그리고 방화벽, 리버스 프록시, 응답 캐시 등 다양한 프록시를 사용하게 될 것입니다. 클라이언트의 프로토콜이 다른 경우 클라이언트 종류별로 프록시를 배포하여 프론트엔드를 위한 백엔드를 만들 수도 있습니다.
런타임 성능
더나아가 성능이나 결함 내성과 같은 비기능적 요구 사항도 있습니다.
비즈니스 로직이나 데이터를 샤딩 또는 복제하면 높은 처리량을 달성할 수 있습니다. 또한 샤딩은 대용량 데이터 셋을 처리하는 데 도움이 되며, 복제는 내결함성을 향상시킵니다. 공간 기반 아키텍처는 전체 데이터 셋을 메모리에 복제하여 더 빠르게 접근할 수 있도록 합니다.
또는 여러 개의 특수 데이터베이스(폴리글롯 지속성(Polyglot Persistence))를 사용하거나 시스템의 부하가 높은 부분을 자체 확장 파이프라인으로 재설계할 수도 있습니다.
고르지 않은 부하에서 확장성은 서비스형 기능(나노 서비스), 서비스 메시 기반 마이크로 서비스, 더 나아가 공간 기반 아키텍처를 통해 달성할 수 있습니다.
내결함성을 위해서는 데이터베이스를 포함한 모든 컴포넌트의 복제본을 여러 데이터센터에 걸쳐 보유하는 것이 이상적입니다. 그렇게 풍부하지 않다면 액터(Actor)나 메시(Mesh)로 만족하세요.
짧은 지연 시간을 요구할 경우 입력에 가까운 곳에 간소화된 첫 번째 응답 로직을 배치할 수 있으며, 이는 다음과 같은 형태를 띱니다.
- 사용자 상호작용을 위한 MVP 또는 MVC 패턴 조합을 사용할 수 있습니다.
- 단일 하드웨어 입력을 위한 전략 주입 기법(strategy injection) 이 적용된 레이어.
- IIoT와 같은 분산 제어 시스템을 위한 계층 구조.
유연성
제품에 커스터마이징이 필요하다면 플러그인을 선택하세요.
10년 동안 살아남으려면 공급업체를 변경할 수 있는 헥사고날 아키텍처가 필요합니다.
리소스 또는 서비스 제공자와 소비자 사이를 중개하는 경우 마이크로커널을 구축합니다.
팀이 서비스를 개발하면서 상호 의존성을 줄이려면 서비스 사이에 부패 방지 계층(anticorruption layer), 오픈 호스트 서비스 또는 CQRS 뷰를 삽입합니다.
대규모 시스템을 구축하고 철저한 데이터 분석이 정말 필요한 경우, 데이터 메시를 구현하는 것을 고려하세요.
모든 도메인은 고유합니다
모든 것을 만족하는 규모는 없습니다. 임베디드 프로젝트나 싱글 플레이어 게임에는 데이터베이스가 없고 단일 프로세스에서 실행됩니다. 고빈도 트레이딩은 OS 커널을 우회하여 마이크로초를 절약합니다. 미들웨어와 분산 데이터베이스는 쿼럼과 리더 선출에 신경을 씁니다. 대규모 데이터 처리는 비트 플립을 고려해야 합니다. 의료 기기는 절대로 충돌해서는 안 됩니다. 은행은 외부 감사를 위해 기록을 영원히 보관합니다.
모든 상황에 통하는 보편적인 아키텍처는 없습니다. 만능 해결책도 없습니다. 패턴은 단순한 도구일 뿐입니다. 도구를 잘 알고 현명하게 선택해야 합니다.
체념
"Software architecture lies lifeless in my hands, devoid of its magical colors, like the dead iguana."
- 이젠 소프트웨어 아키텍처가 전처럼 설레지도 않고, 그 매력도 사라져 버렸다.

2개의 댓글

Bothbest is a FSC certified bamboo factory based in China starting the manufacturing since 2001, mainly supplying bamboo flooring, bamboo decking and bamboo plywood.
https://www.bambooindustry.com/bamboo-flooring/
이전 글에서 패턴을 결합과 응집으로 분해해 보았으니, 이제 프로젝트의 필요에 따라 아키텍처를 재구성해 볼 수 있습니다.