TIL | Milvus & Attu & RAG
milvus 백터 db를 사용해 RAG 작업을 해봄.
작업순서
1) milvus docs 참조해 도커컴포즈로 milvus를 띄운다.
2) GUI로 보고 싶으니까 attu를 함께 띄운다.
3) 전처리한 데이터셋에서 question을 기준으로 모델에 임베딩 시킨다.
4) column= id, embedding, question , answer ...
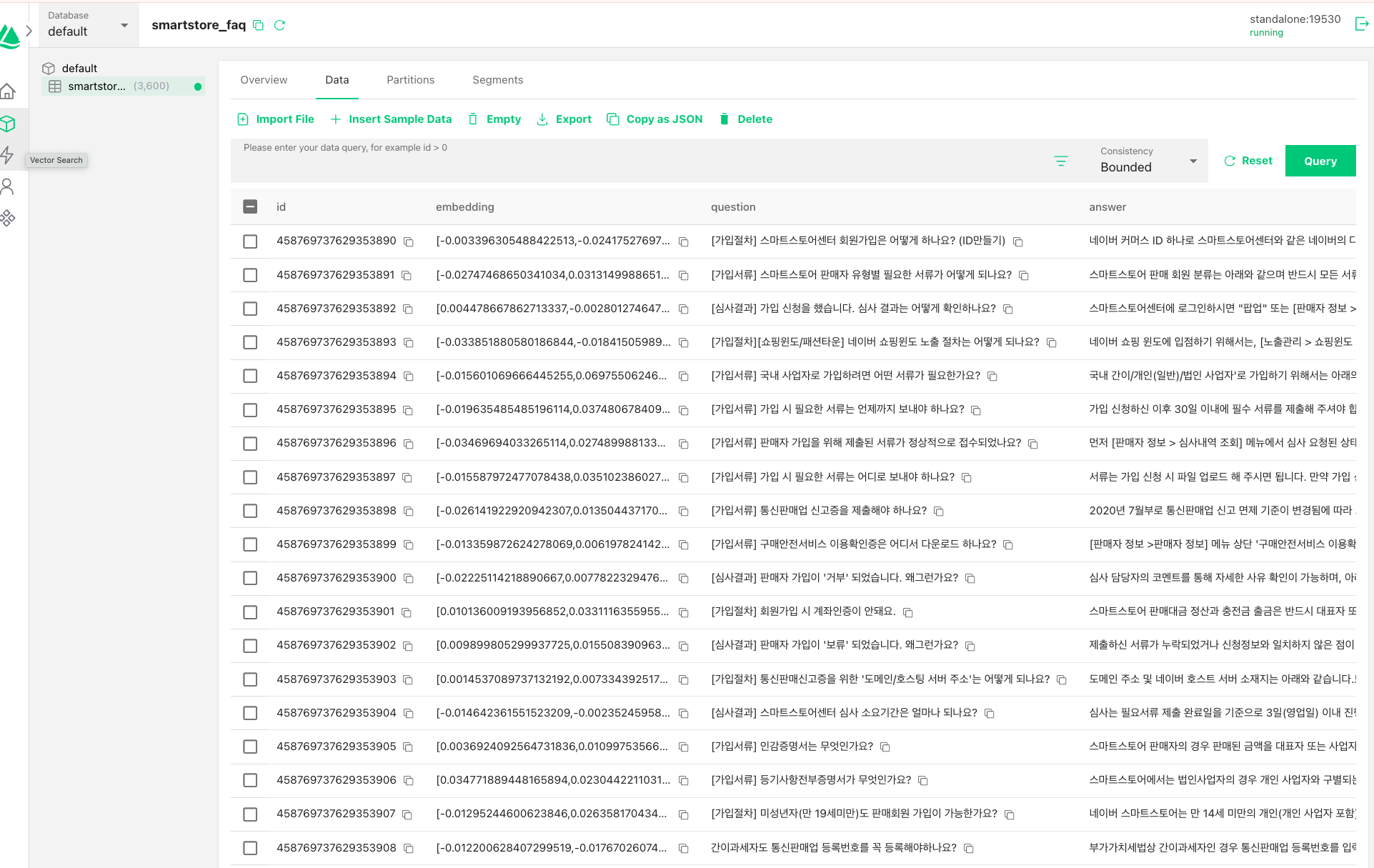
5) milvus에서는 index를 생성하고 load 작업도 해줘야 데이터 쿼리가 된다.
6) 벡터 서치 가능: score가 0에 가까울수록 정확
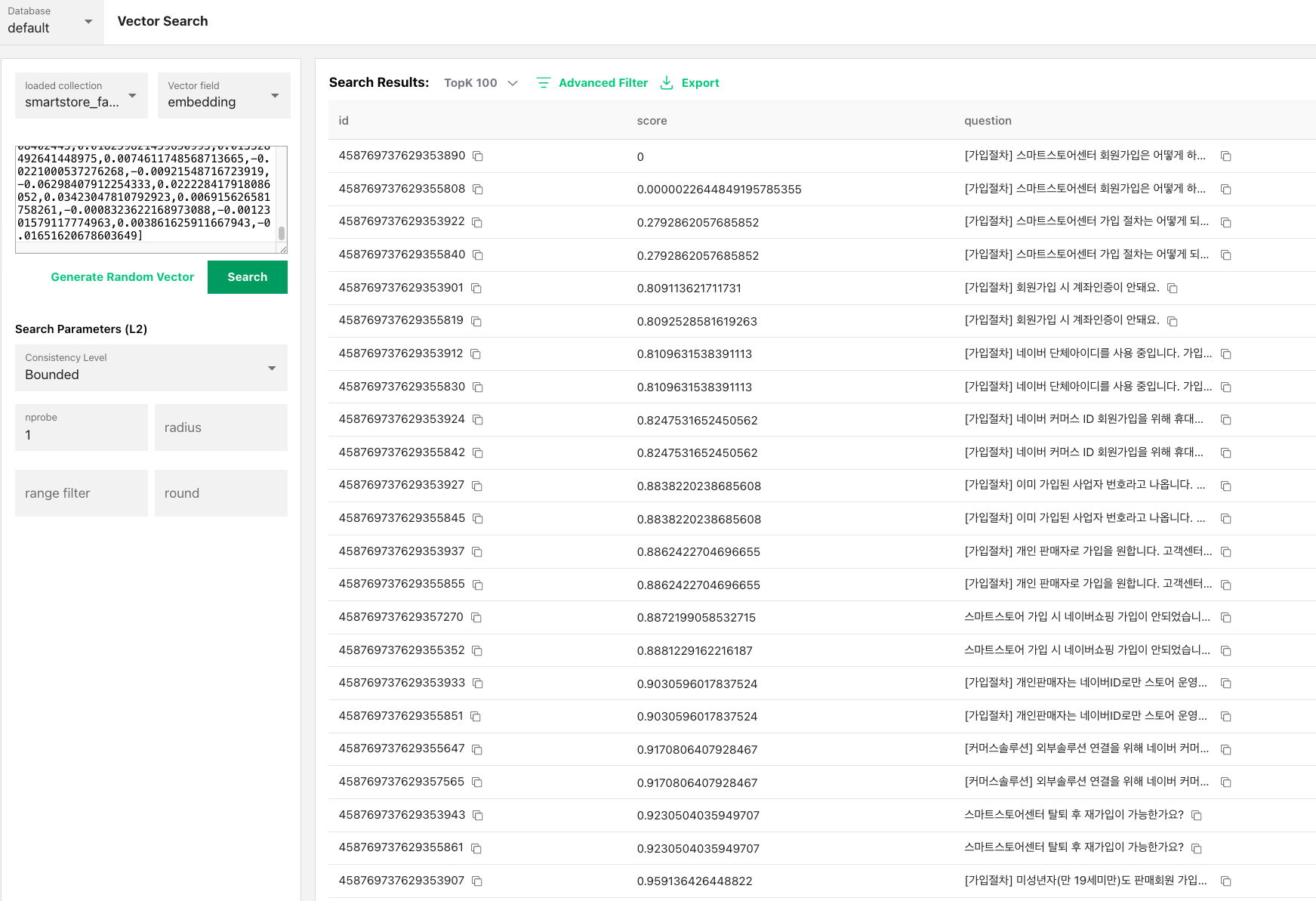
인덱스 생성
index_params = {
"metric_type": "L2", # 유사도 계산 방식
"index_type": "IVF_FLAT",
"params": {"nlist": 1024}
}- metric_type = 유사도 계산 방식
- L2: 유클리디안
- COSINE : 코사인 유사도
- IP : INNER PRODUCT
- index_type = 인덱스의 구조를 정하는 것
- FLAT: 전체 백터 선형탐색
- IVF_FLAT: 벡터를 버킷으로 나눠서 검색
- HNSW: 그래프 기반 탐색( 빠르고 정확도 높음?)
- IVF_SQ8: IVF + 양자화 (아무래도 부정확)
Segment

segment : db가 벡터 데이터를 물리적으로 쪼개서 가지고 있는 단위. 보통 2~3개로 나눌수도 있는데 이거보니까 여기서는 안 짜르고 한 덩어리로 가지고 있는듯.
partition: 논리적 구분 단위. 상황에 따라 partition을 구분하면 필터링에 유리함. 예를들어 카테고리에 따라 파티션 구분을 할 수도 있을듯.
query node: milvus는 분산노드 구조. 쿼리하는 노드를 분리해서 쓰고 있다는거.
인덱스가 필요한 이유
- 벡터는 기본상태일때 유사도비교검색을 선형탐색으로 함 => 느림
인덱스가 있으면 마치 RDBMS에서 WHERE을 거는것처럼 빨라진다. - milvus 인덱스는 벡터 검색용이기 때문에 문자열 검색에 적용하지는 않음
milvus docker 구조
etcd
- 세그먼트 정보, 파티션 상태등 메타데이터 정보 저장 db
minio
- 실제 데이터 스토리지
stand alone
- api 서버 및 서비스
milvus system view
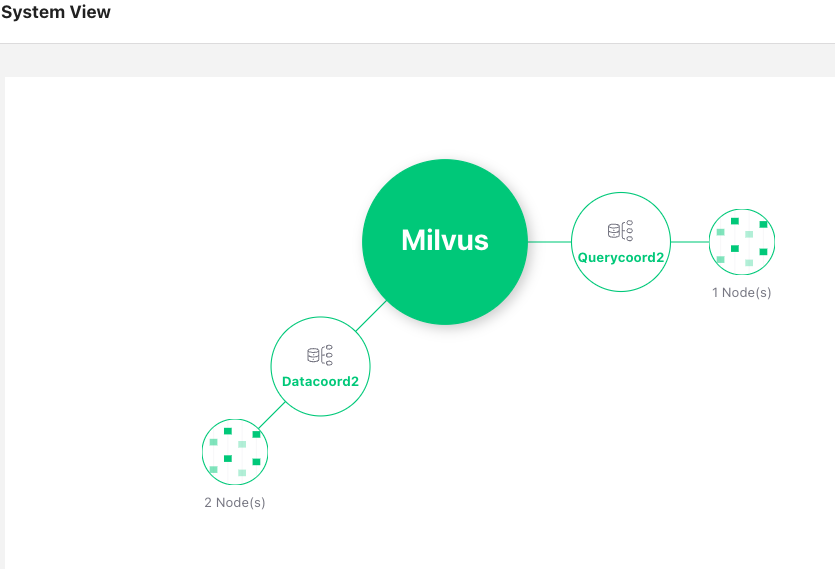
여튼 결과...


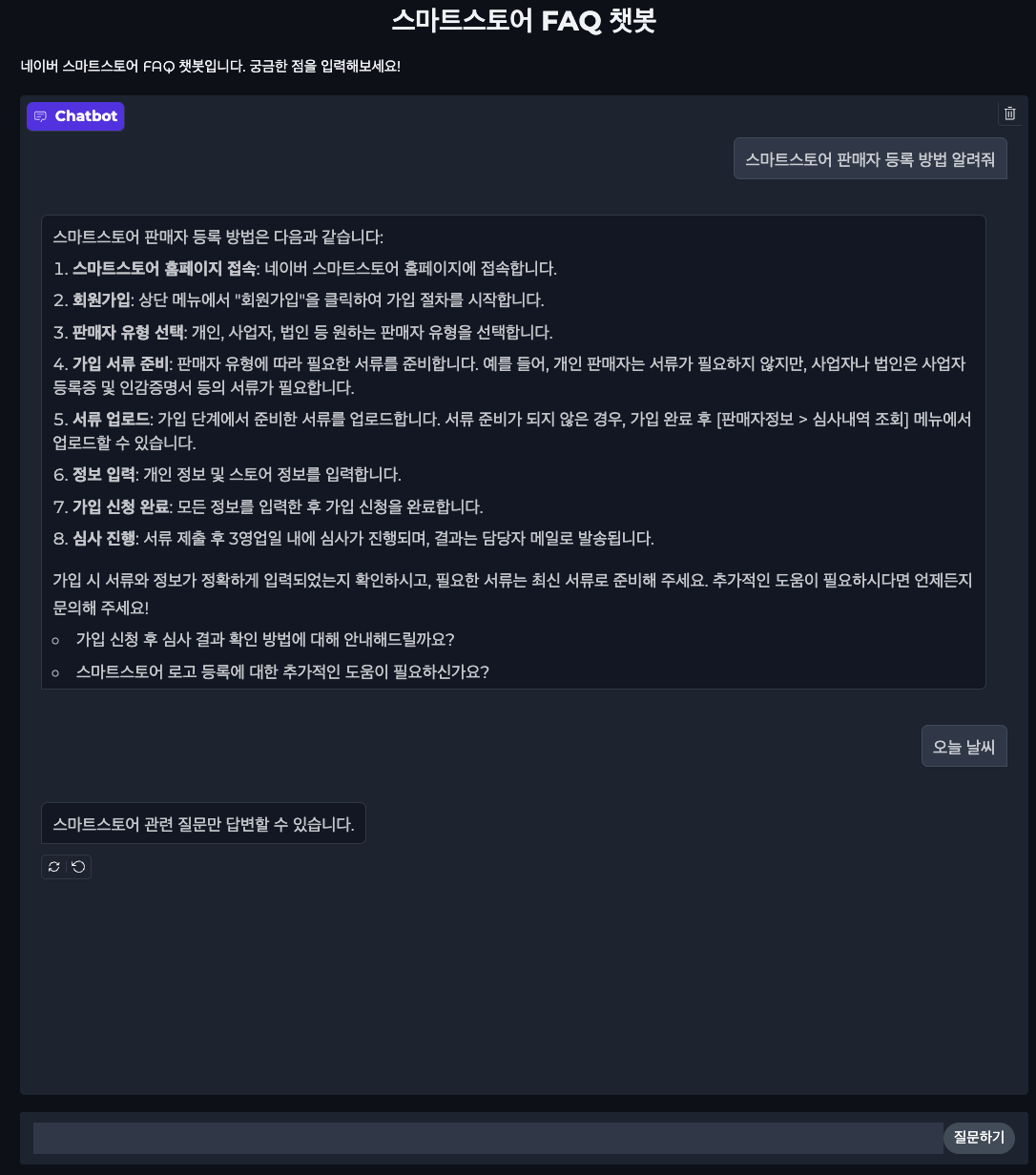
잘 나오는거 같음.... 도라따
내일은 성능테스트 해야징 ㅇ0ㅇ/

그때 그때 꽂힌것 하는 개발블로그