🌞 시작하는 글
🎯 오늘의 TODO LIST
[✔] 테이블 안에 테이블일때 해당 내용 빼기
⚗️ 오늘의 실험
docx-pdf tabula 직접추출이 정확할까? pdf2docx 변환 추출이 정확할까?
- tabula로 했을때 단순 테이블 텍스트도 밀림 현상 있음, 셀 배경색 추출 불가능 일반 이미지 추출 불가능, 단 pymupdf로는 이미지 추출 가능할 수 있음
- pdf2docx 로 추출한 것은 텍스트 완전 추출, 셀 배경색 추출 가능, 표 100% 추출, 일반 이미지 100% 추출, 표 내 이미지 90% 추출 됨
=> pdf2docx 변환 추출이 정확도 높을 것으로 판단됨
ppt-pdf랑 docx-pdf 분류해보기
1) PyPDF2 - pdf metadata 사용
from PyPDF2 import PdfReader
def extract_metadata(pdf_path):
reader = PdfReader(pdf_path)
metadata = reader.metadata
return metadata
{'/Producer': 'macOS 버전 14.5(빌드 23F79) Quartz PDFContext', '/CreationDate': "D:20241011035344Z00'00'", '/ModDate': "D:20241011035344Z00'00'"}MacOS에서는 문서를 pdf로 만들때 macOS Quartz PDFcontext를 사용함 따라서 pdf에서 생성된 건지 docx에서 생성된 것인지 확인 불가능. 다만 실제 사용자는 100% Windows를 사용하리라 가정하고 윈도우 테스트 필요함
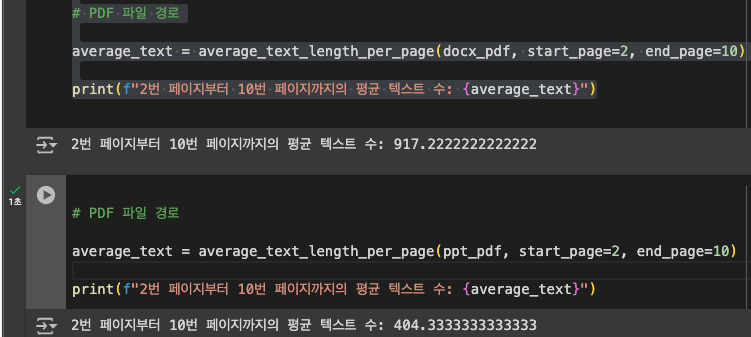
2) 처음 1~5개 테이블 평균 텍스트 수로 분류
맘에 안들지만 이게 현실적인 방법일 수 잇음
테이블 안 테이블 추출 코드 클린코드화

코딩 잘하고 싶다