OCR- easyOCR
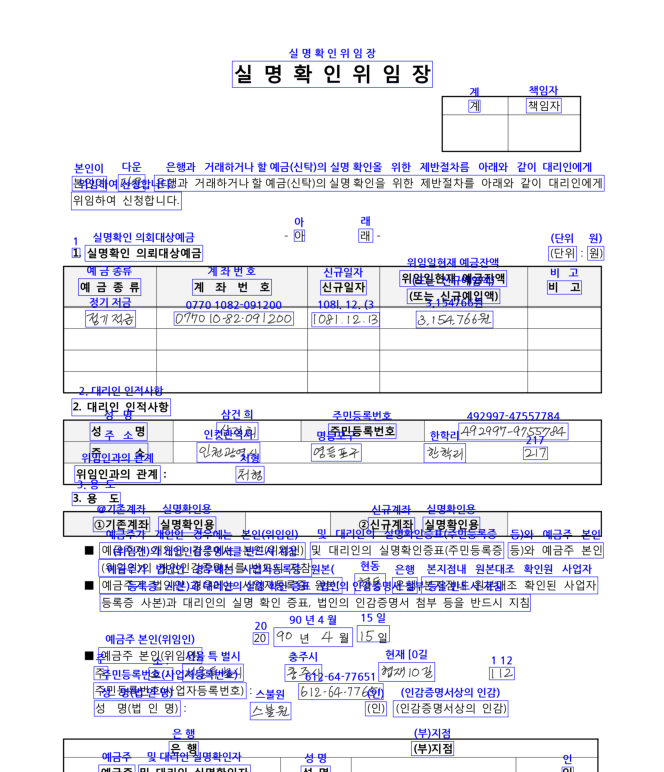
클린한 파일 기준 90% 정도 읽는거 같음. 마찬가지로 학습 안한 상태.
trainable한 한국어 pretrained 모델중엔 그나마 괜찮은거 같음.
90% 정도 나옴. 회=>뢰 이런 어려운 글자 정확도 낮음.
import cv2
import easyocr
import numpy as np
import matplotlib.pyplot as plt
from PIL import ImageFont, ImageDraw, Image
# Initialize EasyOCR reader
reader = easyocr.Reader(['ko', 'en'])
# Perform OCR on the image
result = reader.readtext('/content/IMG_OCR_6_F_0103509.png')
print(result)
# Read the image using OpenCV
img = cv2.imread('/content/IMG_OCR_6_F_0103509.png')
# Convert image to PIL format
img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# Define font and drawing context
font_size = 40 # Adjust this as needed
font = ImageFont.truetype("/content/drive/MyDrive/글씨체/NanumGothic-Bold.ttf", font_size)
draw = ImageDraw.Draw(img_pil)
# Draw rectangles and text on the image
for i in result:
x = int(i[0][0][0])
y = int(i[0][0][1])
w = int(i[0][1][0] - i[0][0][0])
h = int(i[0][2][1] - i[0][1][1])
# Draw the rectangle
draw.rectangle(((x, y), (x+w, y+h)), outline="blue", width=2)
# Draw the text
text_width, text_height = draw.textsize(i[1], font=font)
text_x = int(x + (w - text_width) / 2)
text_y = int(y - text_height - 10)
draw.text((text_x, text_y), str(i[1]), font=font, fill="blue")
# Convert PIL image back to numpy array for display
img_np = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
# Display the image using matplotlib with larger figure size
plt.figure(figsize=(12, 12)) # Adjust width and height as needed
plt.imshow(cv2.cvtColor(img_np, cv2.COLOR_BGR2RGB))
plt.axis('off') # Hide the axes
plt.show()
그때 그때 꽂힌것 하는 개발블로그