Abstract
📝 연구 배경
문서 레이아웃 분석은 실제 문서 이해 시스템에서 매우 중요하지만, 속도와 정확도 사이에서 어려운 절충점이 존재합니다:
- 텍스트와 시각 특징을 모두 활용하는 멀티모달 방법은 높은 정확도를 보이지만 상당한 지연시간이 발생
- 시각 특징만을 사용하는 단일모달 방법은 빠른 처리 속도를 제공하지만 정확도가 떨어짐
💡 제안하는 해결책
DocLayout-YOLO는 사전학습과 모델 설계 양면에서 문서 특화 최적화를 통해 속도의 이점을 유지하면서 정확도를 향상시키는 새로운 접근 방식을 제시합니다.
주요 혁신점
-
강건한 문서 사전학습
- Mesh-candidate BestFit 알고리즘 도입
- 문서 합성을 2차원 빈 패킹 문제로 정의
- 대규모 다양성을 갖춘 DocSynth-300K 데이터셋 생성
-
모델 최적화
- Global-to-Local Controllable Receptive Module 제안
- 문서 요소의 다중 스케일 변화에 대한 더 나은 처리 능력
-
성능 검증
- 복잡하고 도전적인 새로운 벤치마크 DocStructBench 도입
- 다양한 문서 유형에 대한 성능 검증
🎯 연구 결과
- DocSynth-300K 데이터셋을 통한 사전학습으로 다양한 문서 유형에서 파인튜닝 성능 크게 향상
- 다운스트림 데이터셋에서의 광범위한 실험을 통해 속도와 정확도 모두에서 우수한 성능 입증
🔗 리소스
Introduction
📚 연구 배경
대규모 언어 모델과 검색 증강 생성(RAG) 연구의 빠른 발전으로, 고품질 문서 내용 파싱의 중요성이 더욱 커지고 있습니다.
문서 레이아웃 분석(DLA)의 중요성
- 문서 내 다양한 영역(텍스트, 제목, 표, 그래픽 등) 정확한 위치 파악
- 문서 파싱의 핵심 단계
- 일반적인 문서 유형에서 상당한 발전 달성
- 다양한 문서 형식에서 여전히 속도와 정확도 문제 존재
🔍 현재 접근 방식
1. 멀티모달 방법
- 시각 및 텍스트 정보 결합
- 통합 텍스트-이미지 인코더 사용
- 특징:
- 높은 정확도
- 복잡한 아키텍처로 인한 느린 처리 속도
2. 단일모달 방법
- 시각적 특징만 사용
- 특징:
- 빠른 처리 속도
- 문서 데이터 특화 사전학습 부재로 정확도 부족
💡 DocLayout-YOLO 소개
주요 목표
- 실시간 응용 프로그램 요구사항 충족
- 다양한 실제 문서에서 강건한 성능 달성
- 멀티모달과 단일모달 접근방식의 장점 결합
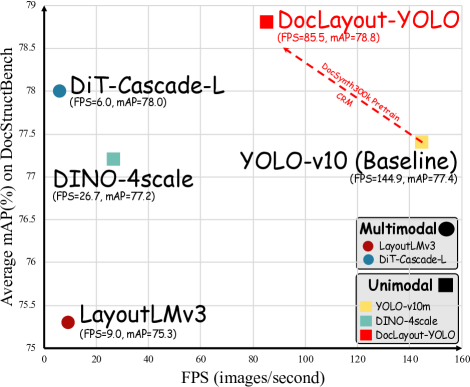
성능 비교
- YOLOv10의 처리 속도와 대등
- 기존 방법들 대비 우수한 정확도:
- 단일모달: DINO-4scale, YOLO-v10
- 멀티모달: LayoutLMv3, DiT-Cascade
최적화 전략
- 시각적 어노테이션이 있는 다양한 문서 데이터로 사전학습
- 문서 레이아웃 분석을 위한 타겟 탐지 네트워크 구조 개선
Diverse DocSynth-300K Dataset Construction
📌 기존 데이터셋의 한계
현재 단일모달 사전학습 데이터셋은 주로 학술 논문으로 구성되어 있어 상당한 동질성을 보이며, 이는 사전학습 모델의 일반화 능력을 크게 제한합니다.
💡 데이터 다양성의 두 가지 차원
1. 요소 다양성
- 다양한 글꼴 크기의 텍스트
- 여러 형태의 표
- 기타 다양한 문서 요소
2. 레이아웃 다양성
- 단일 컬럼
- 더블 컬럼
- 다중 컬럼
- 학술 논문 특화 포맷
- 잡지 및 신문 형식
🛠 Mesh-candidate BestFit 방법론
1. 전처리: 요소 다양성 확보
- M6Doc 테스트 데이터 활용
- 2,800개 다양한 문서 페이지
- 74가지 서로 다른 문서 요소
- 세부 카테고리별 요소 풀 구축
- 희소 카테고리 증강 파이프라인
- 100개 미만 요소 보유 카테고리 대상
- 데이터 풀 확장
2. 레이아웃 생성: 레이아웃 다양성 확보
기존 접근방식의 한계
- 무작위 배치: 혼란스러운 레이아웃 생성
- 디퓨전/GAN 기반 모델: 동질적 레이아웃 생성 한계
제안하는 생성 알고리즘
-
후보 샘플링
- 요소 크기 기반 계층적 샘플링
- 후보 집합 구성
- 초기 요소 배치
-
메시그리드 구성
- 현재 레이아웃 기반 그리드 구축
- 겹침 영역 제외
- 유효 그리드 필터링
-
최적 쌍 검색
- 크기 요구사항 충족 그리드 탐색
- 최대 채움률 메시-후보 쌍 탐색
- 최적 후보 제거 및 레이아웃 갱신
-
반복적 레이아웃 채움
- 2~3단계 반복
- 크기 요구사항 만족할 때까지 진행
- 최종 중앙 스케일링 적용
📊 결과 및 검증
- 잘 조직된 시각적 문서 이미지 생성
- 높은 다양성 확보
- 실제 문서 타입 적응력 향상
- 인간 디자인 원칙 준수 (정렬, 밀도)

Experiments
📊 실험 설정
평가 지표
- 정확도: COCO-style mAP
- 속도: FPS (초당 처리 이미지)
평가 데이터셋
-
D4LA
- 11,092개 노이즈 이미지
- 27개 카테고리
- 훈련: 8,868 / 테스트: 2,224
-
DocLayNet
- 80,863 페이지
- 11개 카테고리
- 훈련/검증/테스트: 69,103/6,480/4,994
-
DocStructBench (자체 제작)
- 문서 유형별 구분:
- 학술 논문
- 교과서
- 시장 분석
- 금융 문서
- 10개 카테고리 수동 주석
- 훈련: 7,310 / 테스트: 2,645
- 문서 유형별 구분:
🔍 비교 실험
비교 대상
-
멀티모달 방법
- LayoutLMv3
- DiT-Cascade
- VGT
-
단일모달 방법
- DINO-4scale-R50
구현 세부사항
- DocLayout-YOLO 설정:
- 사전학습: 이미지 긴 변 1600
- 배치 크기: 128
- 학습률: 0.02
- 에폭: 30
📈 주요 실험 결과
1. 최적화 전략 효과
- DocSynth-300K 사전학습:
- D4LA: +1.2 향상
- DocLayNet: +2.6 향상
- DocStructBench 전체 서브셋 개선
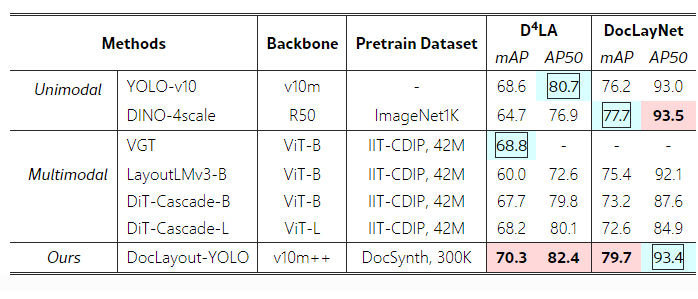
2. 기존 방법과 비교
- 단일모달 방법 대비:
- DINO 대비 DocLayNet에서 2.0 향상
- 멀티모달 방법 대비:
- D4LA에서 mAP 70.3 달성
- VGT(68.8) 상회
3. 속도 비교
- DIT-Cascade-L 대비 14.3배 빠름
- DINO 대비 3.2배 빠른 FPS
💡 주요 발견점
문서 합성 방법 비교
- 무작위 레이아웃: 실제 문서와의 큰 불일치
- 디퓨전 레이아웃: 제한된 다양성
- DocSynth-300K: 모든 유형에서 우수한 일반화 능력
GL-CRM 효과
- 글로벌 레벨: 중대형 객체 탐지 정확도 향상
- 블록 레벨: 중간 크기 객체에서 최대 성능 개선
- 계층적 설계의 효과성 입증

ML Engineer 🧠 | AI 모델 개발과 최적화 경험을 기록하며 성장하는 개발자 🚀 The light that burns twice as bright burns half as long ✨