🤔 이게 왜 문제인가
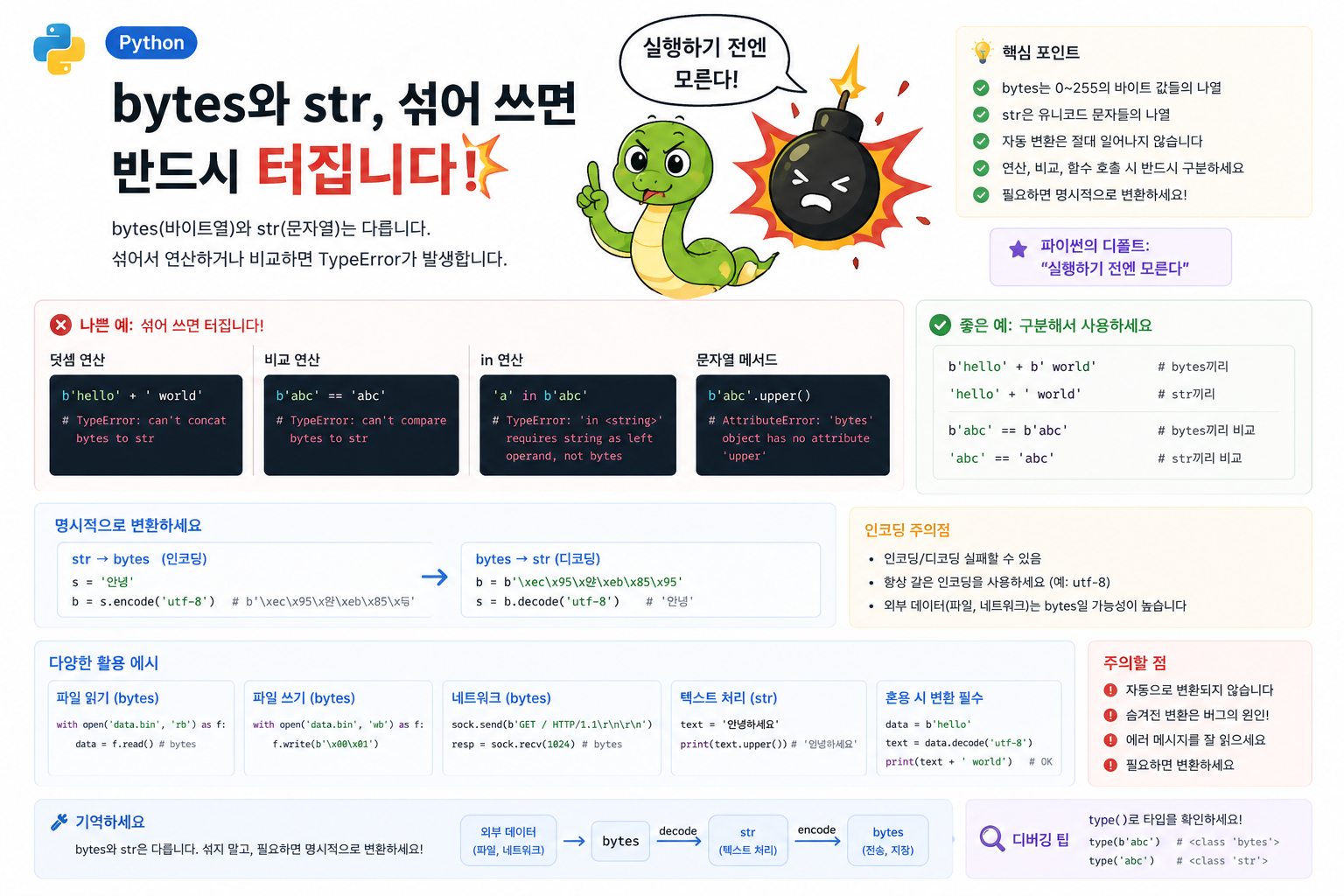
파일에서 데이터를 읽다가 TypeError: a bytes-like object is required, not 'str' 에러를 만난 적 있나요? 아니면 HTTP 응답을 파싱하는데 b'...' 형태로 나와서 .replace()가 먹히지 않아 당황했던 적은요? 파이썬의 bytes와 str은 겉보기엔 비슷하지만 완전히 다른 타입이고, 이 차이를 모르면 한글 깨짐, 파일 읽기 오류, 네트워크 통신 버그로 끝없이 시달리게 됩니다.
핵심 차이는 간단합니다. bytes는 0~255 정수의 나열(raw 바이트)이고, str은 사람이 읽는 문자(유니코드 코드 포인트)의 나열입니다. 디스크나 네트워크는 바이트만 알고, 사람은 글자로 보고 싶어 하죠. 이 둘 사이의 변환이 인코딩/디코딩입니다.
💣 흔한 실수
# 파일을 바이너리로 열고 문자열처럼 다루기
with open('log.txt', 'rb') as f:
data = f.read()
if 'error' in data: # 💥 TypeError: a bytes-like object is required
print("에러 발견")
# bytes와 str을 그냥 합치려 하기
greeting = b'hello, '
name = '세계'
print(greeting + name) # 💥 TypeError
# 한글을 인코딩 안 하고 바이트 취급
data = '안녕'
with open('out.bin', 'wb') as f:
f.write(data) # 💥 TypeError: a bytes-like object is required'rb'로 연 파일은 bytes를 반환하는데 'error'(문자열)로 검색하려니 타입이 안 맞습니다. bytes와 str은 더하기도, 비교도, 포함 검사도 안 돼요. 파이썬이 "비슷하니까 알아서 해주겠지"를 거부하는 몇 안 되는 영역입니다.
✅ 파이썬다운 방법
"유니코드 샌드위치" 패턴이 정답입니다. 입구에서 바로 str로 디코딩, 내부에선 str로만 처리, 나갈 때 다시 bytes로 인코딩하는 구조예요.
# 입구: 바이트를 문자열로 디코딩
with open('log.txt', 'rb') as f:
raw = f.read() # bytes
text = raw.decode('utf-8') # str
# 내부: str로만 처리
if 'error' in text:
print("에러 발견")
# 출구: 다시 바이트로 인코딩
with open('out.bin', 'wb') as f:
f.write('안녕'.encode('utf-8')) # str → bytes
# 타입이 헷갈릴 때 쓸 수 있는 도우미 함수
def to_str(value) -> str:
if isinstance(value, bytes):
return value.decode('utf-8')
return value # 이미 str
def to_bytes(value) -> bytes:
if isinstance(value, str):
return value.encode('utf-8')
return value # 이미 bytes변환의 핵심은 인코딩 이름을 명시하는 것입니다. UTF-8이 사실상의 표준이지만, 레거시 시스템에서는 cp949, euc-kr, latin-1 같은 걸 만날 수도 있어요. 디코딩할 때 인코딩이 다르면 UnicodeDecodeError가 나거나, 최악의 경우 조용히 글자가 깨집니다.
파일을 텍스트 모드('r', 'w')로 열면 파이썬이 자동으로 인코딩/디코딩을 해주니까, 한글 텍스트 파일 다룰 땐 그냥 open('file.txt', 'r', encoding='utf-8')을 쓰는 게 마음 편합니다. 바이너리 모드('rb', 'wb')는 이미지/오디오/네트워크 패킷처럼 진짜 바이트 단위가 필요할 때만 쓰세요.
📎 기억할 것
bytes는 0~255 정수의 시퀀스(raw 데이터),str은 유니코드 문자의 시퀀스입니다.bytes + str,bytes == str,'x' in bytes_value같은 혼용은 전부 에러입니다.bytes.decode('utf-8')으로 문자열화,str.encode('utf-8')으로 바이트화합니다.- 유니코드 샌드위치: 입력받자마자
str로 디코딩, 처리는str로, 출력 직전에bytes로 인코딩. - 파일은 기본적으로 텍스트 모드(
'r','w')로 열고encoding='utf-8'을 명시하세요. 바이너리 모드는 진짜 바이트 단위가 필요할 때만.
🛠 실무에서 어디 쓸까
웹 서버/클라이언트가 대표적입니다. requests.get(url).content는 bytes를, .text는 자동 디코딩된 str을 반환해요. 한글 페이지 크롤링할 때 .text가 깨지면 대부분 인코딩을 잘못 추측한 경우라, response.encoding = 'utf-8'로 지정하거나 .content.decode('euc-kr')로 직접 풀어줘야 합니다. 또 AWS S3, Redis, 카프카 같은 서비스의 파이썬 클라이언트는 대부분 bytes를 주고받기 때문에, 애플리케이션 경계에서 반드시 인코딩/디코딩을 거쳐야 해요. 암호화(hashlib, hmac), 해시(sha256), JWT 서명 같은 보안 관련 API도 bytes를 요구하는 경우가 많아서, "비밀번호".encode('utf-8')을 습관적으로 붙이는 게 실수를 줄입니다.
