1. 그래프란 무엇인가
그래프 기반 시스템을 다루기에 앞서, 그래프 자료구조의 정의를 명확히 할 필요가 있다. 관계 자체를 일급 객체로 취급하는 데이터 모델이 그래프이다.
이산수학과 그래프 이론에서 그래프는 객체(node)와 그 객체들 사이의 연결(relationship)로 구성된 구조로 정의된다. 객체는 vertex, node, point 등으로 불리며, 객체 사이의 연결은 edge, relationship, link로 불린다. 본 글에서는 객체를 node, 연결을 relationship으로 통일한다.
가장 직관적인 예시는 사회 관계망이다. 한 사람을 node로, 두 사람 사이의 친구 관계를 relationship으로 표현하면 social graph가 만들어지며, 이를 통해 사람들이 어떻게 상호 연결되어 있고 정보가 어떻게 흐르는지 분석할 수 있다.
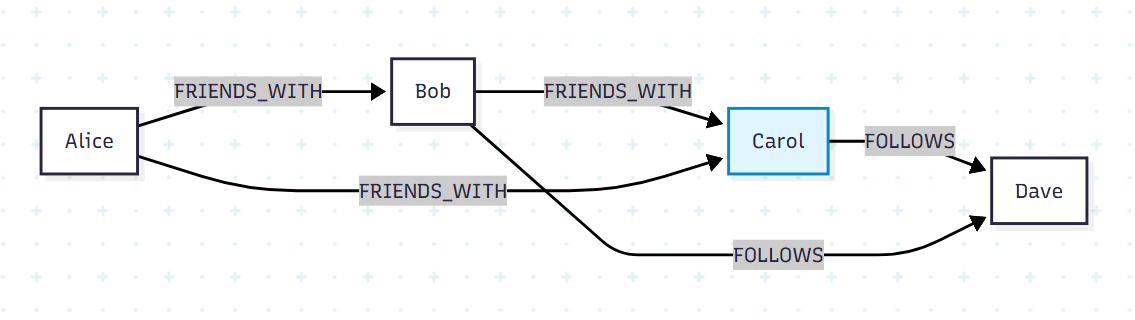
Neo4j 같은 그래프 데이터베이스에서는 node뿐 아니라 relationship에도 데이터를 저장할 수 있고, 이를 property라고 부른다. 즉 "Alice와 Bob이 친구다"라는 사실 위에 "2019년부터 친구이며 신뢰도 0.8" 같은 속성을 relationship 자체에 부여할 수 있다. 관계형 DB가 join table에 별도 컬럼을 두어 흉내내는 것과 달리, 그래프 DB는 이를 구조적으로 자연스럽게 표현한다.
2. Neo4j: native graph database
Neo4j는 native graph database로 분류된다. 여기서 native라는 표현이 핵심이다. 그래프 자료구조와 그 위에서 수행되는 알고리즘·연산을 처리하기 위해 처음부터 설계되었다는 의미이며, 이는 다른 데이터베이스들이 그래프 모델을 "지원"하는 방식과 구별된다.
저장소 종류를 정리하면 다음과 같다.
| 분류 | 대표 제품 | 특징 |
|---|---|---|
| Native graph DB | Neo4j | 그래프 구조에 최적화된 저장·탐색 엔진. relationship 자체가 1급 객체 |
| Non-native graph (NoSQL/RDB 기반) | MongoDB, Amazon Neptune, SQL Server, ArangoDB | 다른 데이터 모델 위에 그래프 추상을 얹은 형태 |
| RDF database | Virtuoso, Stardog | 웹 데이터 교환(triple 기반)에 특화 |
| Vector database | Pinecone, Milvus, FAISS | 벡터 임베딩의 similarity search에 특화 |
Neo4j는 vector database가 아니다. 다만 vector를 저장하고 similarity search를 수행하는 기능을 제공하므로, 그래프 구조와 벡터 검색을 한 시스템에서 결합하려는 경우 선택지가 된다. 이 결합 가능성이 GraphRAG 아키텍처의 기술적 토대가 된다.
Neo4j가 널리 채택되는 이유는 세 가지로 요약된다. 그래프 자료구조에 대한 native 처리, 확장성, 그리고 오픈소스 기반의 활발한 커뮤니티이다. 데이터 포인트 간 연결이 많고 그 연결의 구조 자체를 분석해야 하는 도메인 — 추천, 사기 탐지, 지식 그래프, 네트워크 분석 — 에서 특히 적합하다.
3. 데이터베이스 선택의 의사결정 흐름
저장소 선택은 단일 기준으로 결정되지 않는다. 데이터의 형태와 질의 패턴이 함께 고려되어야 한다.
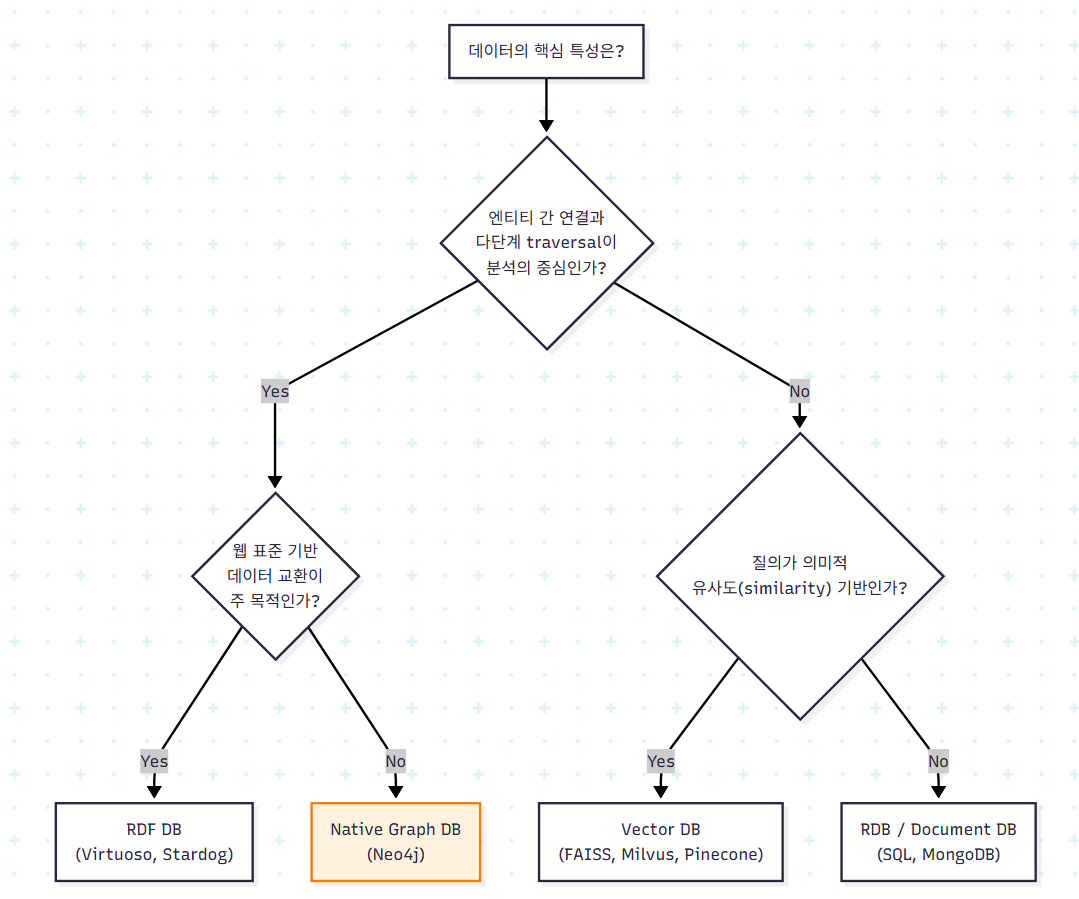
이 흐름도는 본 챕터에서 다룬 데이터베이스 분류에 기반한 의사결정 보조 도구로 이해하면 된다. 실제 시스템 설계에서는 단일 저장소를 선택하기보다, 그래프 DB와 벡터 DB를 병행 운용하거나 한 시스템 안에서 통합하는 polyglot persistence 전략이 일반적이다.
4. 그래프 시각화 도구 생태계
그래프 데이터의 가치는 시각화를 통해 직관적으로 드러나는 경우가 많다. 본 챕터에서 언급된 주요 도구들은 다음과 같다.
| 도구 | 유형 | 주요 용도 |
|---|---|---|
| Linkurious | 상용 시각화 플랫폼 | 사기 탐지, 정보 분석, 사이버 보안 |
| Hume (GraphAware) | Neo4j 기반 분석 플랫폼 | 시각화·분석·머신러닝 통합 |
| VizNetwork | R 패키지 | 인터랙티브 네트워크 그래프 |
| Gephi | 오픈소스 데스크톱 도구 | 학술·연구용 네트워크 탐색 |
| D3.js | JavaScript 라이브러리 | 웹 기반 커스텀 시각화 |
| Power BI | BI 대시보드 | 일반 BI 리포트에 그래프 시각화 부분 통합. 커스터마이징 제약 존재 |
선택 기준은 사용 환경(웹/데스크톱/노트북), 인터랙티브 요구 수준, 그리고 분석 파이프라인과의 통합 여부에 따라 갈린다. 탐색적 분석에는 Gephi, 운영 환경의 대시보드 임베딩에는 D3.js, Neo4j 데이터의 즉시 시각화에는 Hume이 자연스러운 선택이 된다.
5. 한계와 트레이드오프
그래프 데이터베이스가 모든 문제의 해답은 아니다. 본 챕터의 개념에서 도출 가능한 한계는 다음과 같다.
관계가 희박한 데이터에서의 오버헤드. 그래프 DB의 강점은 relationship traversal에 있다. 데이터 포인트 간 연결이 적거나, 분석이 단순 lookup·aggregation 중심이라면 RDB나 document DB 대비 얻는 이점이 작다. 오히려 graph 모델링과 운영 비용이 부담으로 작용할 수 있다.
대규모 분석 워크로드의 한계. Neo4j는 OLTP 성격의 그래프 traversal에 강하지만, 수십억 노드 규모의 그래프 알고리즘 일괄 실행은 별도의 분산 처리 엔진(Spark GraphX, Pregel 계열) 또는 Neo4j Graph Data Science 라이브러리의 클러스터 구성을 요구한다.
의미 기반 검색의 부재. 그래프 traversal은 명시적으로 정의된 relationship을 따라 이동한다. "비슷한 문서 찾기"처럼 의미적 유사도가 핵심인 질의는 vector DB의 영역이다. 이 차이가 vector RAG와 graph RAG를 구분하는 근본 지점이며, 두 접근의 결합이 GraphRAG의 동기가 된다.
6. 실무 적용 시 고려사항
그래프 DB 도입을 검토하는 실무 관점에서 몇 가지 고려사항을 정리한다.
첫째, 도메인의 질의 패턴을 먼저 분석한다. "고객 A와 연결된 모든 거래의 2단계 거래 상대를 찾으라"처럼 multi-hop traversal이 반복된다면 그래프 DB가 적합하다. 반면 "지난달 매출 합계"처럼 집계가 주된 질의라면 데이터 웨어하우스가 우선이다.
둘째, 단일 저장소 선택을 강제할 필요가 없다. 운영 데이터는 RDB에 두고, 그래프 분석용 view를 Neo4j에 별도 구축하거나, similarity search를 위해 vector DB를 병행하는 구성이 일반적이다. 본 시리즈 후속편에서 다룰 GraphRAG는 이 polyglot 전략의 구체적인 한 형태이다.
셋째, 그래프 모델링은 스키마 설계 단계에서 결정된다. 무엇을 node로 두고 무엇을 relationship으로 둘지, 어떤 property를 어디에 부여할지는 이후 질의 성능과 분석 가능성을 좌우한다. 관계형 모델링과 사고방식이 다르므로 초기 학습 비용이 발생한다.
결론: 그래프 데이터베이스는 "연결 그 자체가 데이터인 도메인"에서 가장 큰 가치를 만들어내며, vector·관계형 저장소와 경쟁하기보다 보완하는 위치에 놓일 때 GraphRAG로 이어지는 자연스러운 토대가 된다.
참고 자료
- Graph Data Science with Python and Neo4j. Chapter 1: Introduction to Graph Data Science.
