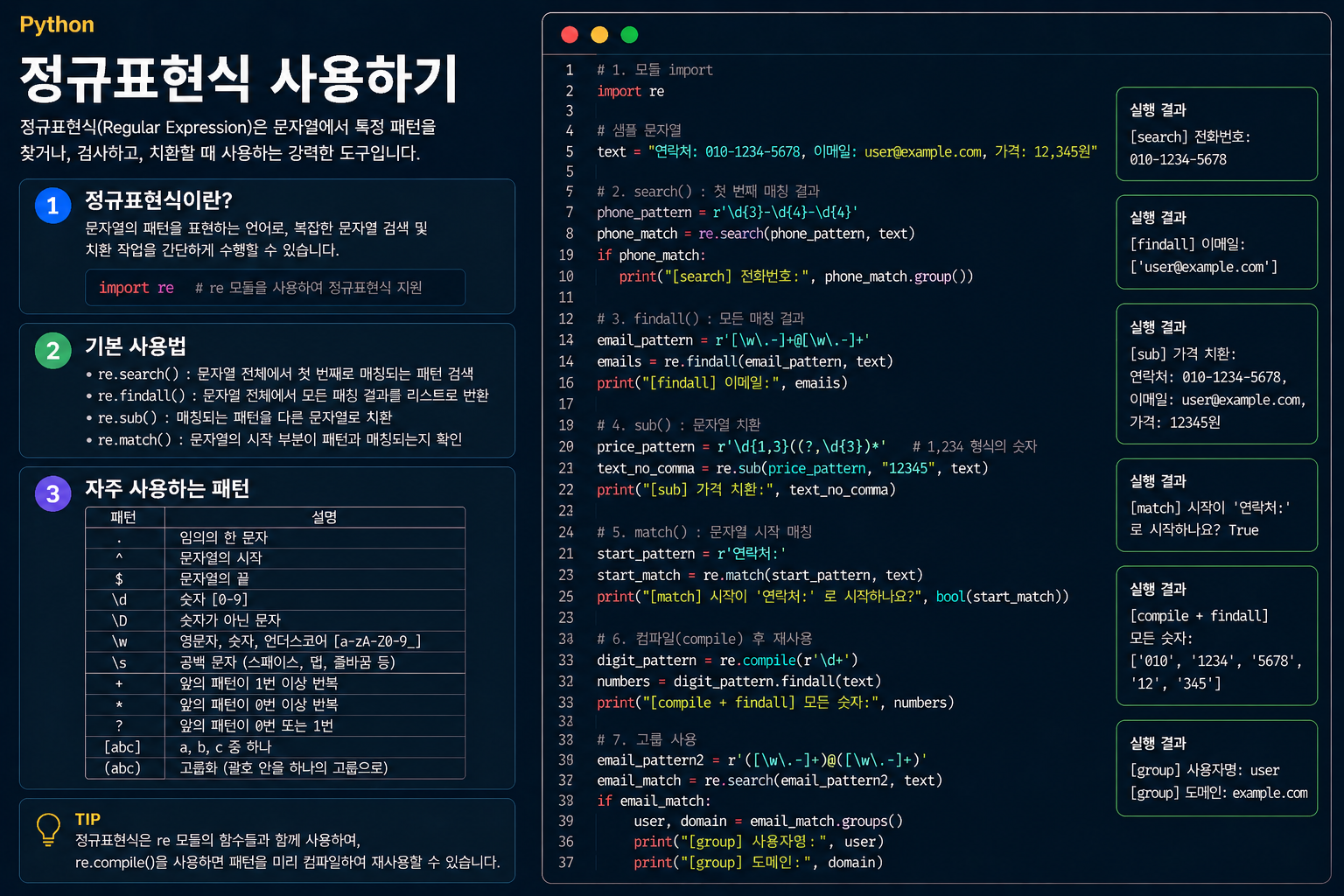
1. 정규표현식이란?
정규표현식은 일정한 규칙을 가진 문자열을 표현하는 방법입니다. 복잡한 문자열 속에서 특정 패턴을 검색, 추출, 치환할 때 사용합니다. 파이썬에서는 re 모듈을 사용합니다.
import re
# match: 문자열 처음부터 패턴이 매칭되는지 판단
result = re.match('hello', 'hello, world!')
print(result) # <re.Match object; span=(0, 5), match='hello'>
# 매칭되지 않으면 None 반환
result = re.match('world', 'hello, world!')
print(result) # Nonematch는 문자열 처음부터 매칭되는지 판단하고, search는 문자열 일부분이 매칭되는지 판단합니다.
# search: 문자열 어디서든 패칭되면 반환
print(re.search('world', 'hello, world!')) # <re.Match object ...>
print(re.match('world', 'hello, world!')) # None ← 처음이 아니라서2. 자주 쓰는 패턴 문법
위치 지정 — ^, $
re.search('^hello', 'hello world') # 문자열 맨 앞에 hello가 있는지
re.search('world$', 'hello world') # 문자열 맨 뒤에 world가 있는지OR 연산 — |
# hello 또는 world 중 하나라도 포함되는지
re.search('hello|world', 'hello!') # 매칭
re.search('hello|world', 'world!') # 매칭문자 개수 판단 — *, +, ?, ., {n}
| 기호 | 의미 | 예시 |
|---|---|---|
* | 앞 문자가 0개 이상 | ab* → a, ab, abb... |
+ | 앞 문자가 1개 이상 | ab+ → ab, abb... |
? | 앞 문자가 0개 또는 1개 | ab? → a, ab |
. | 아무 문자 1개 | a. → ab, ac, a1... |
{n} | 정확히 n개 | a{3} → aaa |
{n,m} | n개 이상 m개 이하 | a{2,4} → aa, aaa, aaaa |
re.match('[0-9]+', '123abc') # 숫자 1개 이상
re.match('[a-z]{3}', 'abc') # 소문자 정확히 3개
re.match('[0-9]{2,4}', '1234') # 숫자 2~4개범위 지정 — []
re.match('[a-z]+', 'hello') # 소문자 영문
re.match('[A-Z]+', 'HELLO') # 대문자 영문
re.match('[0-9]+', '12345') # 숫자
re.match('[가-힣]+', '안녕하세요') # 한글
# ^ 를 [] 안에 넣으면 해당 범위 제외
re.match('[^0-9]+', 'hello') # 숫자가 아닌 문자⚠️
^의 위치에 따라 의미가 달라집니다.[]밖에 있으면 문자열 시작,[]안에 있으면 범위 제외입니다.
특수 문자 이스케이프 — \
특수 문자(., *, + 등)를 그대로 판단하려면 앞에 \를 붙입니다.
re.search('\.', 'hello.world') # 점(.)을 문자 그대로 검색
re.search('\$', 'price: $100') # 달러 기호 검색단축 표현
범위를 매번 직접 쓰면 패턴이 길어집니다. 아래 단축 표현을 사용하면 편리합니다.
| 단축 표현 | 의미 |
|---|---|
\d | 숫자 [0-9] |
\D | 숫자가 아닌 문자 [^0-9] |
\w | 영문, 숫자, 밑줄 [a-zA-Z0-9_] |
\W | \w가 아닌 문자 |
\s | 공백 문자 (스페이스, 탭 등) |
\S | 공백이 아닌 문자 |
re.match('\d+', '12345') # 숫자 1개 이상
re.match('\w+\s\w+', 'hello world') # 단어 공백 단어3. compile — 패턴 재사용하기
같은 패턴을 자주 쓴다면 compile()로 패턴 객체를 만들어두면 편리합니다.
# 매번 패턴을 직접 넣는 방식
re.match('[0-9]+', '123')
re.match('[0-9]+', '456')
# compile로 패턴 객체 생성 후 재사용
pattern = re.compile('[0-9]+')
print(pattern.match('123')) # <re.Match object ...>
print(pattern.match('456')) # <re.Match object ...>4. 그룹 — ()
패턴 안에서 ()로 묶으면 그룹이 됩니다. 매칭된 문자열에서 그룹별로 값을 꺼낼 수 있습니다.
# 날짜 패턴에서 연/월/일 그룹 추출
m = re.match('(\d{4})-(\d{2})-(\d{2})', '2024-01-15')
print(m.group(0)) # 2024-01-15 (전체)
print(m.group(1)) # 2024 (첫 번째 그룹)
print(m.group(2)) # 01 (두 번째 그룹)
print(m.group(3)) # 15 (세 번째 그룹)
print(m.groups()) # ('2024', '01', '15') (튜플로 반환)그룹이 많아지면 숫자로 구분하기 어렵습니다. ?P<이름> 형식으로 그룹에 이름을 붙이면 가독성이 높아집니다.
# 이름 있는 그룹
m = re.match('(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})', '2024-01-15')
print(m.group('year')) # 2024
print(m.group('month')) # 01
print(m.group('day')) # 155. findall — 모든 매칭 문자열 찾기
그룹 지정 없이 패턴에 매칭되는 모든 문자열을 리스트로 반환합니다.
# 문자열에서 모든 숫자 추출
text = "사과 3개, 바나나 5개, 딸기 12개"
numbers = re.findall('\d+', text)
print(numbers) # ['3', '5', '12']
# 이메일 주소 추출
text = "문의: hong@example.com, kim@test.co.kr"
emails = re.findall('\w+@\w+\.\w+', text)
print(emails) # ['hong@example.com', 'kim@test.co.kr']6. sub — 문자열 치환하기
sub()는 패턴에 매칭된 문자열을 다른 문자열로 바꿉니다.
# sub(패턴, 바꿀 문자열, 원본 문자열, 바꿀 횟수)
text = "hello world hello python"
result = re.sub('hello', 'hi', text)
print(result) # hi world hi python
# 횟수 제한
result = re.sub('hello', 'hi', text, count=1)
print(result) # hi world hello python바꿀 문자열 대신 교체 함수 또는 람다를 넣을 수도 있습니다.
# 매칭된 숫자를 2배로 바꾸기
text = "사과 3개, 바나나 5개"
result = re.sub('\d+', lambda m: str(int(m.group()) * 2), text)
print(result) # 사과 6개, 바나나 10개그룹을 치환 결과에 재사용하기
\숫자 또는 \g<이름>으로 매칭된 그룹을 치환 결과에 다시 사용할 수 있습니다.
# 날짜 형식 변환: 2024-01-15 → 15/01/2024
text = "오늘은 2024-01-15입니다."
result = re.sub('(\d{4})-(\d{2})-(\d{2})', r'\3/\2/\1', text)
print(result) # 오늘은 15/01/2024입니다.
# 이름 있는 그룹으로 더 명확하게
result = re.sub(
'(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})',
r'\g<day>/\g<month>/\g<year>',
text
)
print(result) # 오늘은 15/01/2024입니다.정리
| 함수/기호 | 용도 |
|---|---|
match() | 문자열 처음부터 패턴 매칭 |
search() | 문자열 어디서든 패턴 매칭 |
findall() | 모든 매칭 문자열을 리스트로 반환 |
sub() | 패턴에 매칭된 문자열 치환 |
compile() | 패턴 객체로 만들어 재사용 |
group() | 그룹별 매칭 문자열 반환 |
groups() | 모든 그룹을 튜플로 반환 |

ML Engineer 🧠 | AI 모델 개발과 최적화 경험을 기록하며 성장하는 개발자 🚀 The light that burns twice as bright burns half as long ✨