[Redis]
레디스 데이터의 원래 소스보다 더 빠르고 효율적으로 액세스할 수 있는 임시 데이터 저장소를 말합니다.
회사에서 Redis에서 cluster를 사용하기에 , 알아보는 김에 어떤게 있는지 더알아보게되었습니다.
1. Caching Strategies
(1) Look-Aside(Lazy Loading)
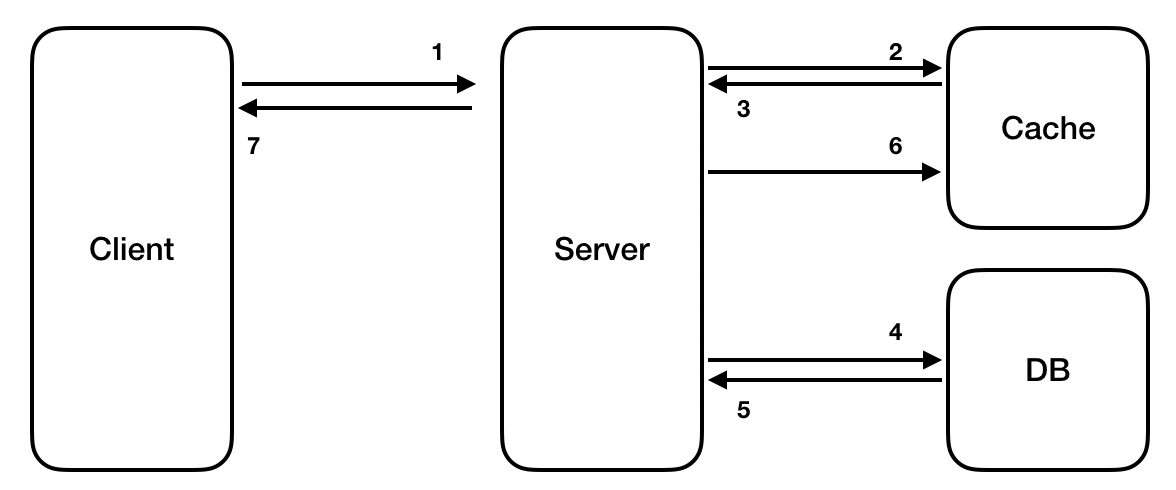
클라이언트에게서 데이터가 필요로 해질 때 Cache에 로딩하는 전략입니다. DB나 외부 API에 접근하기 전에 Cache를 먼저 확인한 후에 Cache 데이터가 존재한다면 Cache 데이터를 그렇지않다면 원본에 접근하여 값을 가져와 캐시에 둡니다
장점
-
요청 받은 데이터만 캐시에 저장되기 때문에 실제로 사용한 데이터만 캐시에 담을 수 있습니다.
-
캐시 미스가 발생했을 때 치명적이지 않습니다. 차선책으로 메인 DB에 접근해 최신의 데이터를 가져오기 때문입니다.
단점
- 캐시미스가 있을 때마다 부하가 증가합니다.
이를 해결하기위해 cache warming 을 합니다. 미리 db에서 cache로 올리는 작업을 말합니다.
- 캐시미스가 발생할때마다 캐시에 데이터를 쓰기 때문에 캐시의 데이터가 최신으로 유지못할 가능성이 있습니다.
=> 반복적으로 동일 쿼리르 수행하는 서비스에 적합합니다.
(2) Read Through
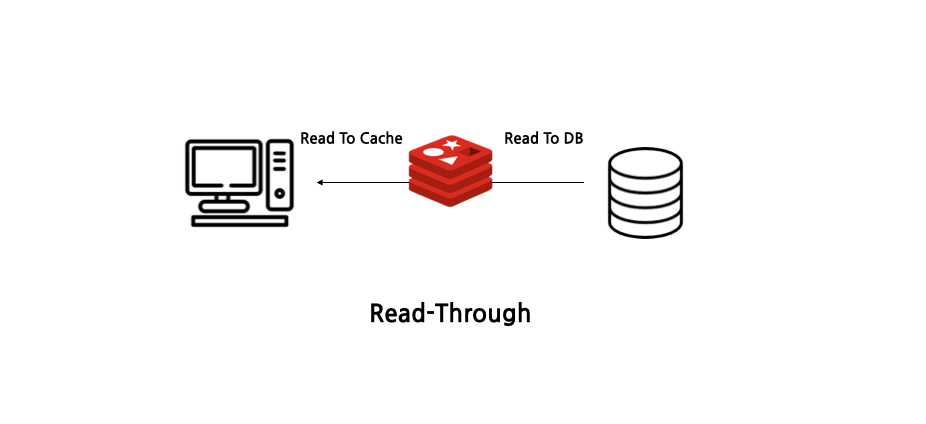
Cache Aside의 업그레이드 버전으로, 데이터를 읽을 때 캐시로만 데이터를 읽어옵니다. 만약 Cache Miss가 발생한다면 데이터를 캐시에 바로 저장합니다.
(3) Write Back
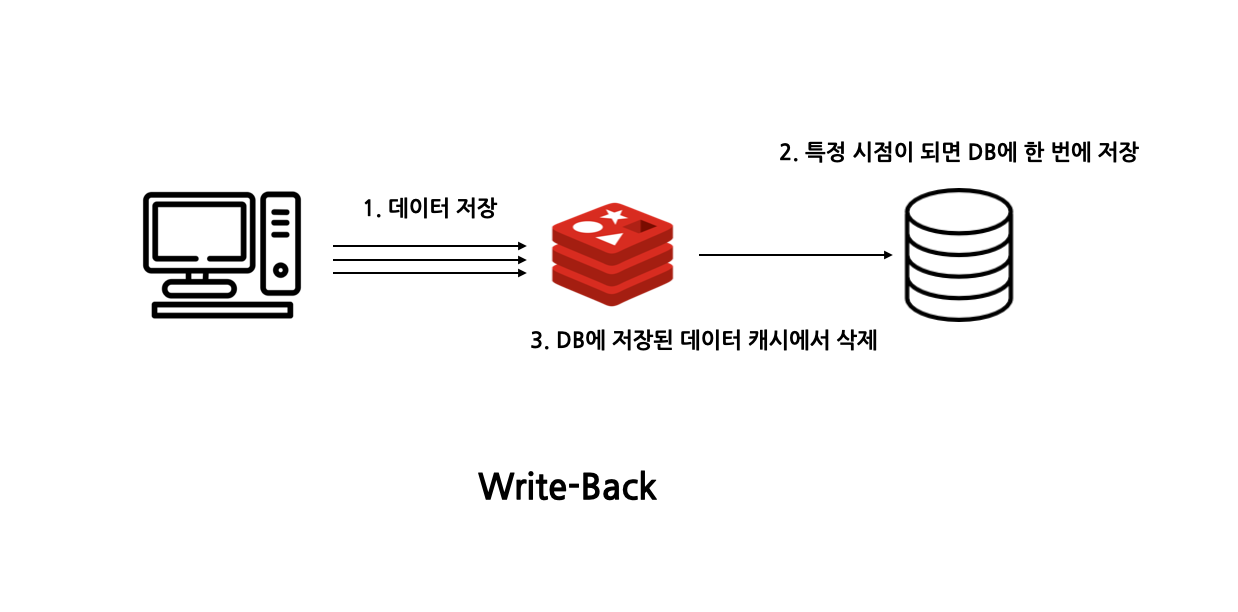
모든 데이터를 캐시에 저장하였다가 특정 시점이 되면 캐시에 저장된 데이터를 DB에 저장하고 저장된 데이터는 캐시에서 삭제하는 걸 말합니다.
장점
-
쓰기가 많은 경우에 적합합니다. DB에 디스크 쓰기 비용을 절약할 수 있습니다
-
데이터를 캐시에 모아뒀다가 DB에 옮기기 때문에 캐시에 장애가 발생한다면 데이터 유실이 발생합니다.
(4) Write-Througth
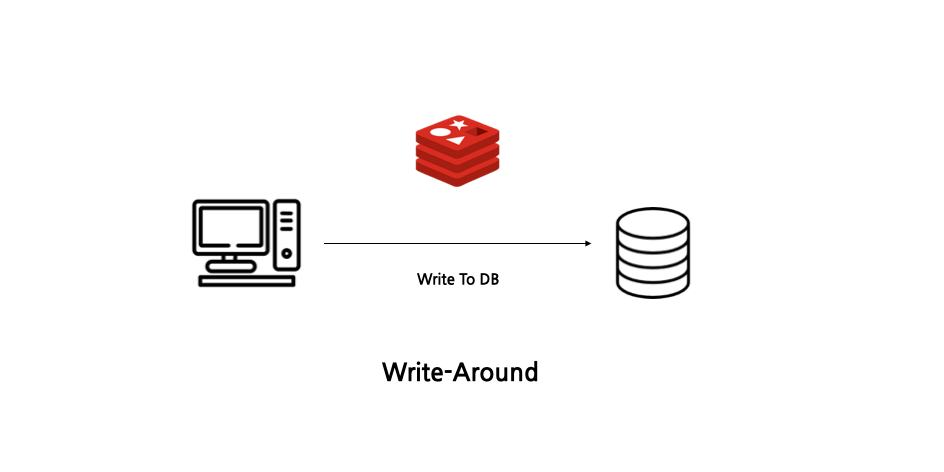
모든 데이터를 DB에 저장하고 Cache Miss가 발생한 경우에만 DB에서 캐시로 데이터를 저장합니다.
장점
- 자주 읽히지 않는 데이터는 캐시에 로드되지 않으니 리소스를 절약할 수 있습니다
단점
- 캐시 내의 데이터와 DB내의 데이터가 다를 수 있습니다.
=> 실시간 로그 , 채팅방 메시지
(5) Write-Through
Read-Through 전략과 같이 DB에 데이터를 저장할 때 먼저 캐시에 기록한 다음 DB에 저장하는 방식입니다.
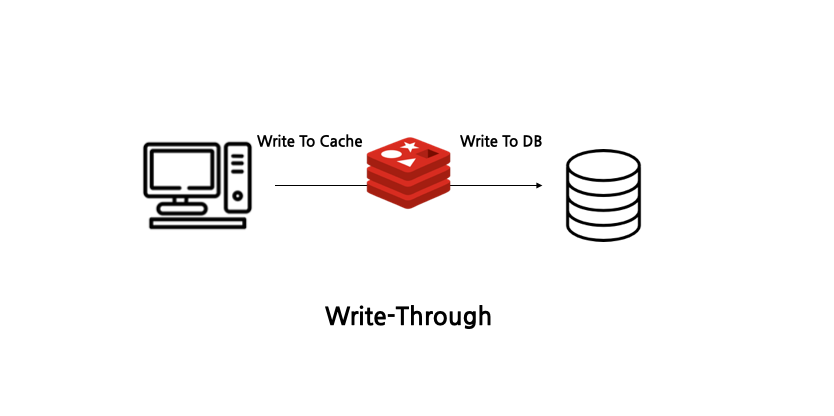
장점
- 캐시는 항상 최신 정보를 가지고 있고 DB와 동기화되어 데이터 일관성을 보장합니다
단점
-
저장할 때 마다 두 단계 스텝을 거쳐야하기 때문에 추가 쓰기 시간이 발생하여 상대적으로 느립니다.
-
데이터가 재사용하지않을 수도 있는데 캐시에 넣는 것은 리소스 낭비입니다.
-
새로운 노드가 추가되거나 했을 경우 데이터를 찾지 못할 수도 있습니다.
-
읽을 때 캐시미싱이 일어났다면 다시 채우기가 애매해집니다
2. Redis 데이터 타입

(1) Strings
키와 연결할 수 있는 가장 간단한 유형의 데이터입니다.
set으로 설정하고 get으로 가져올 수 있습니다.
단순증감 연산 또한 가능합니다.
set counter 100
incr counter
> 101
incrby counter 50
> 151
client.set('name', 'kweather')
client.get('name', (err, data) => {
console.lig(data) // kweather
})(2) List
리스트는 linked list로 만들어졌습니다. value에 list를 저장합니다.
- LPUSH : 가장 왼쪽에 데이터 추가
- RPUSH : 가장 오른쪽에 데이터 추가
- LRANGE : 리스트의 범위로 아이템을 추출
반대로 pop 값을 뺴는 것도 가능합니다.
client.rpush('fruits', 'apple', 'orange', 'apple')
client.lpush('fruits', 'banana', 'pear');
client.lrange('ruits', 0, -1, (err, arr) => {
console.log(arr)// ['peer', 'banana', 'apple', 'orange', 'apple']
})(3) Hashes
field-value 쌍을 사용한 hash 형태로 저장합니다.
- HMSET : hash의 여러 필드를 한번에 설정합니다
- HGET : 단일 필드를 검색합니다.
client.hmset('information', 'name', 'ccm', 'age', 26)
client.hgetall('information', (err, obj) => {
console.log(obj) // {name : "ccm", age: "26"}
})(4) Set
중복되지않고 정렬되지않는 문자열의 모음을 말합니다. 그러다보니 데이터가 있는지 중복 체크용이나, 관계 표현을 할때 주로 활용됩니다
client.sadd('animals', 'dog', 'cat', 'bear', 'cat', 'lion')
client.smembers('animals', (err, set) => {
console.log(set); //['cat', 'dog', 'bear', 'lion']
})(5) Sorted Sets
정렬된 셋의 모든 요소는 score 값과 연결됩니다.
정렬된 셋은 스킵 목록과 해시테이블을 모두 포함하는 이중 포트 데이터 구조를 통해 구현되므로 아이템을 추가할 때마다 O(log(N))연산을 수행합니다. 정렬된 요소를 요청할 때에는 이미 정렬되어 있으므로 정렬 작업 수행할 필요가 없습니다.
client.zadd('height', 180, 'ccm', 168, 'ccd', 173, 'cci');
client.zrange('heigth', 0, -1, (err, sset) => {
console.log(sset); // ['ccd', 'cci', 'ccm'
})(6) HyperLogLogs
고유한 것을 계산하기 위해 사용되는 확률적 데이터 구조입니다. 대용량의 데이터 카운팅을 할 떄 적절합니다.
(7) Streams
추상 로그 데이터 유형을 제공하는 append-only 자료구조입니다.
=> 시간범위로 검색/ 신규 추가 데이터 수신/ 소비자별 다른 데이터 수신에 사용됩니다.
(8) Bitmaps
정보를 저장할 때 데이터 저장공간을 절약 할 수 있습니다 .정수로된 데이터만 사용하여 카운팅 가능합니다.
=> 모든 종류 실시간 분석, 오브젝트 ID와 관련된 bool정보를 고성능이지만 적은 공간을 사용해서 저장할 때 사용합니다.
3. Redis에서 영구 저장
(1) AOF(Append Only File)
명령이 실행될 때마다 파일에 기록합니다. write/update 연산 자체를 모두 log 파일에 기록하는 형태입니다.
- aof 파일을 통해 연속성을 보장합니다.
Redis 데이터 복구 시나리오
만일 실수로 flushall 명령으로 메모리에 있는 데이터를 모두 날렸을 때, 레디스 서버를 shutdown하고 appendonly.aof 파일에서 flushall 명령을 제거 한 후 레디스를 다시 시작하면 데이터 손실없이 데이터를 살릴 수 있다.
=> 모든 데이터가 보장되어야할 경우에 사용
(2) RDB(snapshot)
특정한 간격으로 메모리에 있는 레디스 데이터 전체를 disk에 바이너리 형태로 기록합니다.
.rdb 라는 확장자의 파일에 인메모리 데이터를 저장하도록 디폴트 설정되어있습니다.
방식
- SAVE
순간적으로 redis의 동작을 정지시키고 snapshot을 디스크에 저장합니다.(Blocking)
- BGSAVE
Background SAVE 라는 의미로 별도의 자식 프로세스를 띄운 후, 명령어 수행 당시 sanpshot을 disk에 저장하고, redis는 동작을 멈추지않게 됩니다.(Non-blocking)
자동으로 셋팅되어있으며 save옵션을 통해 시간 조정이 가능합니다.
수동으로는 BGSAVE 커맨드를 이용해 CLI창에서 수동으로 rdb 파일 저장
=> 어느 정도 데이터 손실이 발생해도 괜찮은 경우에, RDB 단독 사용하는 걸 고려합니다.
4. Redis 운영 꿀팁
변경하면 장애막을수 있는 기본 설정값
-
STOP-WRITES-ONBGSAVE-ERROR = NO 옵션
RD 파일 저장 실패 시 Redis로의 모든 WRITE 불가능하게 됩니다. -
MAXMEMORY-POLICY = ALLKEYS-LRU
redis 캐시로 사용할 때 expire time 설정 권장합니다. 설정은 allkeys-lru 로합니다.
이렇게 되면 새로운 값이 추가되었을 때, 자동으로 오래된 데이터먼저 지워집니다.
- Persistence 복제 사용시 MaxMemory 설정 주의
RDB 저장 & AOF rewrite 시 fork()시 Copy-on-Write로 인해 메모리를 두배로 사용하는 경우 발생 가능합니다. 그래서 Persistence/ 복제 사용 시 Maxmemory 실제 메모리의 절반으로 설정해야됩니다.
- user_memory : 논리적으로 Redis가 사용되는 메모리
- used_memory_rss : OS가 Redis에 할당하기 위해 사용한 물리적 메모리양
Adding TTL
레이지 로딩 전략일 경우에는 최신 데이터가 아닐 가능성이 있고, Write-through 전략은 항상 최신의 데이터를 유지합니다.
각 전략에 TTL을 추가함으로 이득을 취할 수 있습니다.
TTL
Key가 자연스럽게 만료되어 없어지게 하는 시간을 설정하는 것입니다.
TTL을 설정함으로 값이 없어지고 캐싱 미스를 일으켜 최신을 유지할 수 있게 됩니다. Write-through 전략에서 TTL을 전략하면 업데이트가 되지않는 데이터는 없어지게됩니다.
출처
https://sabarada.tistory.com/142
