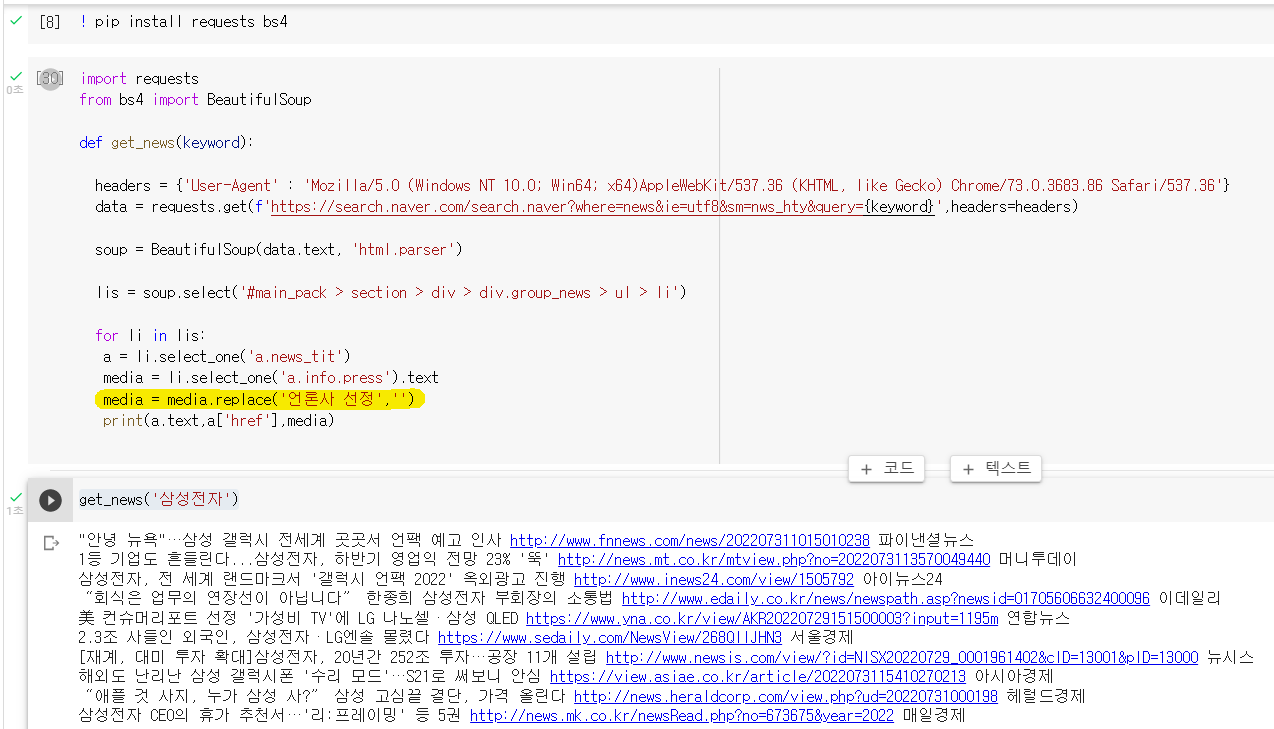
#라이브러리 설치
!pip install bs4 requests
#크롤링 기본 코드
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=삼성전자',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
#여기서 함께 시작합니다!
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')
#이 부분을 채워주세요.
for li in lis:
a = li.select_one('a.news_tit')
media = li.select_one('a.info.press').text.replace('언론사 선정','')
print(a.text,a['href'],media)

Learning Coding