
지난 시간에는 프로그램 개발에 꼭 필요한 개념인 모듈과 스탠다드 라이브러리에 대해 배웠습니다. 이번 시간에는 사용자 입력 받기, 파일 읽고 쓰기 등 Python을 응용하기 위한 방법들을 익혀보겠습니다.
💾 사용자 입력받기, input
이제까지는 개발자의 입장에서 모든 동작들을 결정했습니다. 이 말은 즉, 코딩에 필요한 값을 개발자가 직접 설정했다는 것이죠.
그러나 배포된 프로그램을 실제로 사용하는 것은 User 혹은 고객입니다. 즉, 프로그램은 실 사용자들이 원하는 값을 입력했을 때에도 동작해야 합니다.
실제로는 콘솔을 통해 사용자로부터 정보를 받아옵니다. 이를 다르게 표현하면 '사용자의 입력을 받는다'라고 하는데요. 사용자 입력을 받기 위해서는 input이라는 함수가 필요합니다.
input 함수는 문자열 파라미터를 받습니다.
input("이름: ")이 문자열은 사용자에게 입력을 받기 전에 출력되는데 보통 사용자에게 어떤 값을 입력할 지 설명하는 용도로 쓰이곤 합니다. 위 코드의 경우에는 사용자에게 이름을 입력하라고 설명하고 있습니다. 한 번 실행해 볼까요?
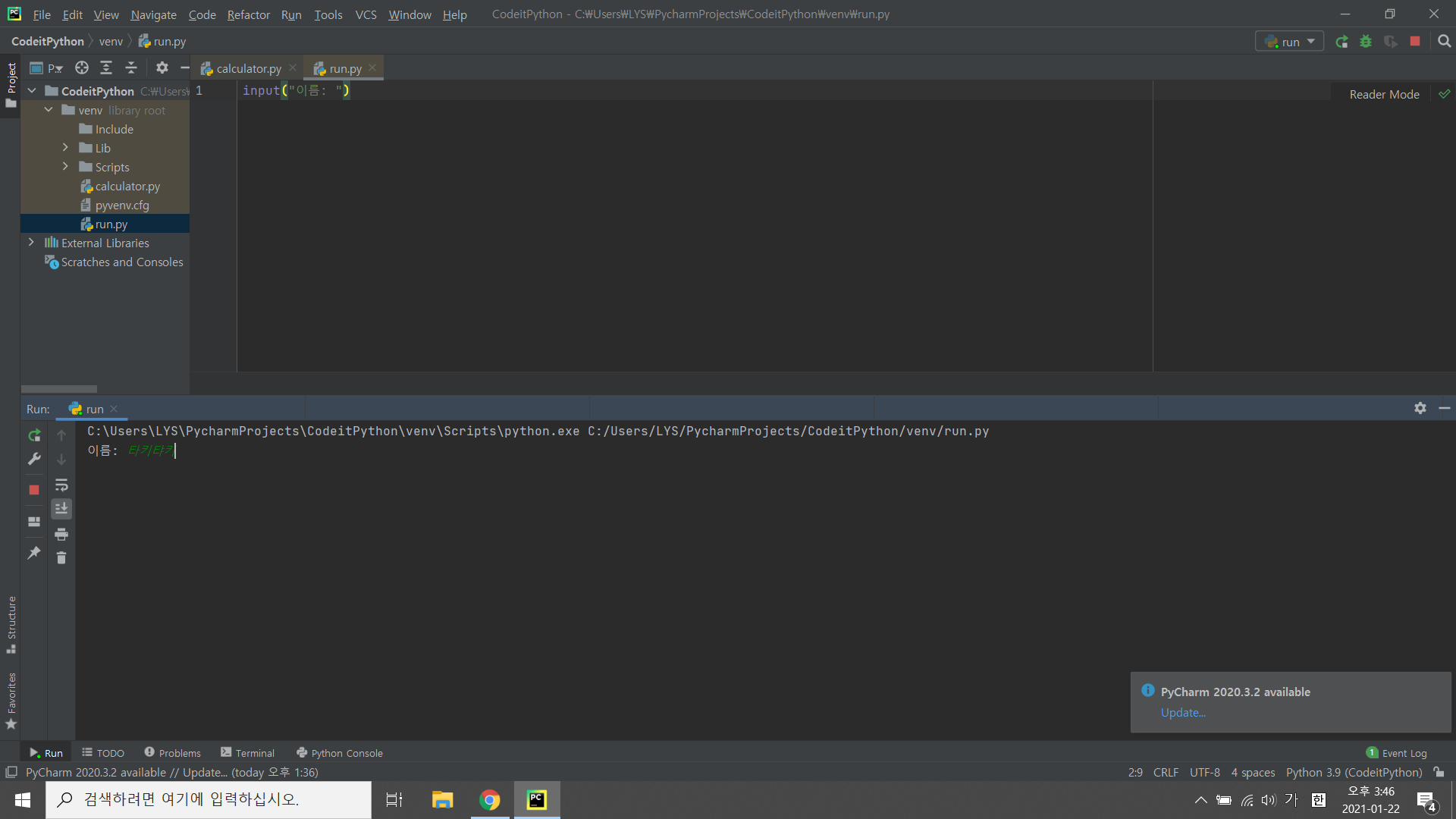
우선, 문자열을 출력하고 프로그램이 잠시 중단됩니다. 사용자가 어떤 값을 입력하기를 기다리는 것이죠. 그 증거로 콘솔창을 클릭하면 마우스 커서가 깜빡입니다. 이때, 콘솔창에 바로 '타키탸키'를 입력하고 엔터를 치면 프로그램이 종료됩니다.
그런데 이렇게 프로그램이 종료되면 의미가 없죠? 그 말은 즉, 어떻게든 사용자가 입력한 값을 활용할 수 있는 추가적인 코드가 필요하다는 뜻입니다.
name = input("이름: ")
print(name)따라서 아주 간단하게 응용해볼 수 있도록 변수에 input 함수의 결과를 저장하고 해당 변수를 출력해봅시다.
이번에도 문자열이 먼저 뜨고 프로그램이 잠시 중단되는데요. 마찬가지로 이름을 입력하고 엔터를 치면 이번에는 입력한 이름이 출력됩니다.
이름: 타키탸키
타키탸키코드의 원리를 알아볼까요? 우리가 input값을 입력하고 엔터를 치면 input 함수의 리턴값으로 문자열 '타키탸키'가 돌아옵니다. 이 말은 곧, "이름: "이라는 문자열이 "타키탸키"로 대체되어 변수 name에 저장된다는 뜻입니다. 그리고 저장된 그 값이 print함수에 의해 출력됩니다.
input함수를 쓸 때 주의해야 할 사항이 있습니다. 다음 상황을 함께 볼까요?
a = input("숫자: ")
print(a + 3)위 코드를 실행하면 입력값을 기다리는 단계까지는 성공적으로 진행되지만 값을 입력하고 엔터를 치면 오류가 나옵니다. 사실 input 함수는 사용자 입력값으로 문자열만을 받습니다.
사용자는 정수를 입력했다고 생각하지만 실제로 그 값은 input에서 문자열로 인식되어 결국에는 정수와 연산을 하는 과정에서 오류를 일으킨 것입니다.
이를 해결하기 위해서는 input의 리턴값을 정수형으로 변환해야 합니다. 다음과 같이 수정하고 실행하면 성공적으로 프로그램이 돌아갑니다.
a = int(input("숫자: "))
print(a + 3)💾 파일 읽기
이번에는 Python으로 파일을 읽는 방법을 알아보겠습니다.
※ 이번 챕터는 눈으로만 익히셔도 좋습니다.
우선, 불러올 파일이 필요하겠죠? 메모장을 켜고 다음 내용을 복사하여 붙여넣기 한 후 chicken.txt 파일을 저장합니다.
1일: 453400
2일: 388600
3일: 485300
4일: 477900
5일: 432100
6일: 665300
7일: 592500
8일: 465200
9일: 413200
10일: 523000
11일: 488600
12일: 431500
13일: 682300
14일: 633700
15일: 482300
16일: 391400
17일: 512500
18일: 488900
19일: 434500
20일: 645200
21일: 599200
22일: 472400
23일: 469100
24일: 381400
25일: 425800
26일: 512900
27일: 723000
28일: 613600
29일: 416700
30일: 385600
31일: 472300
다음으로 Pycharm에 해당 파일을 드래그합니다.
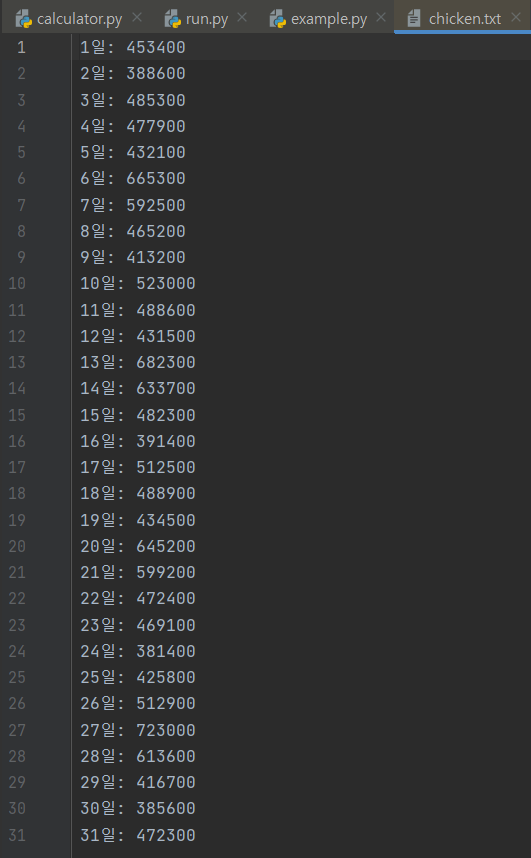
그럼 이렇게 Pycharm에 메모장 파일이 불러와집니다. 이제 이 파일을 가지고 작업을 해봅시다.
새로운 Python 파일을 열고 에디터에 다음과 같이 작성합니다.
with open('chicken.txt', 'r') as f:open은 파일을 열어주는 함수입니다. 첫번째 파라미터에는 파일 이름을 쓰고 두번째 파라미터에는 'read'의 약어인 'r'을 씁니다. 참고로 파일을 쓰고 싶을 때는 'write'의 약어인 'w'을 쓰면 됩니다.
현재는 파일 이름만 적어도 파일을 읽어올 수 있는데요. 그 이유는 chicken.txt 파일이 새로 만든 파일과 같은 폴더에 있기 때문입니다.
그럼 파일이 서로 다른 경로에 있는 경우를 살펴볼까요? data라는 폴더를 만들고 그 안에 chicken.txt를 넣어주겠습니다. 그럼 예제 파일과 chicken.txt 파일의 경로가 분리되는데요. 지금부터는 파일 이름뿐만 아니라 'data/chicken.txt'와 같이 폴더명을 함께 적어야합니다. 파일을 찾을 수 있는 경로를 알려줘야 하는 것이죠.
open함수 뒤 'as f'는 f라는 변수에 읽어들인 파일을 저장한다는 의미를 가지고 있습니다. 변수 f의 자료형을 한 번 볼까요?
<class '_io.TextIOWrapper'>처음 보는 자료형이 나왔습니다. 문자열도, 정수열도 아닌 이 자료형의 정보를 어떻게 읽을 수 있을까요? 사실 이 자료형은 for문을 사용하면 리스트와 유사하게 사용이 가능합니다.
with open('data/chicken.txt', 'r') as f:
for line in f:
print(line)위 코드를 실행하면 파일에 있는 목록들이 불러와집니다.
처음으로 for문의 수행 부분에 들어갈 때, 파일의 첫 줄이 변수 line에 들어가서 출력됩니다. 그 다음부터는 파일의 다음 줄이 line에 저장되고 출력되는 과정을 반복합니다. 수행 부분을 돌 때마다 한줄 한줄 line에 저장되고 출력되는 것이죠.
💾 Strip
앞서 for문을 통해 chicken.txt를 불러오면 다음과 같은 결과가 나옵니다.
1일: 453400
2일: 388600
3일: 485300
.
.
.위와 같이 한 줄씩 나올 때마다 공백이 생기는데요. 왜 그런 걸까요?
chicken.txt를 보면 한 줄을 작성할 때마다 enter를 치고 그 다음 줄을 적었습니다. Python에서 enter는 '백슬래시 n'으로 표현됩니다. 따라서, txt에 있는 하나의 문장은 Python의 다음 문자열과 같이 표현됩니다.
1일: 453400\n이 상태로 자동으로 enter가 추가되는 print문의 특성 때문에 두 번의 enter를 친 것과 같은 결과가 나오는 것입니다. 아직 이해가 안 된다면 다음 코드의 결과를 한 번 봅시다.
print("Hi")
print("Hi")Hi
Hi이처럼 print문을 실행하면 문장을 출력한 후 enter를 하게 됩니다. 이 상태로 '백슬래시 n'을 추가해보겠습니다.
print("Hi\n")
print("Hi")Hi
Hi이렇게 하면 두 줄 사이에 공백이 하나 늘어납니다. enter를 두 번 한 것과 같은 결과가 나오는 것이죠.
그렇다면 이 빈 줄을 제거하기 위해서는 어떤 방법을 사용해야 할까요? 문자열 앞뒤 화이트 스페이스를 제거해주는 strip을 사용하면 됩니다. 화이트 스페이스란, "", "백슬래시 t", "백슬래시 n"과 같은 공백들을 말합니다.
다음 예시를 한 번 봅시다.
print(" love you ".strip())love you이처럼 strip을 호출하면 love와 you 앞 뒤의 화이트 스페이스가 사라집니다. 그러나 가운데 공백은 여전히 존재하죠.
print(" \t \n love you\n\n\n".strip())이번에는 문장 앞에 스페이스와 백슬래시 t와 n이 있고 단어 사이의 공백이 있으며 문장 끝에 백슬래시 n이 세 번 들어가 있습니다. 위 코드를 실행하면 마찬가지로 단어 사이의 공백을 제외한 모든 화이트 스페이스가 제거됩니다.
이제 원래 파일로 돌아가서 strip을 호출해 볼까요?
with open('data/chicken.txt', 'r') as f:
for line in f:
print(line.strip())문자의 끝에 백슬래시 n이 있기 때문에 변수 뒤에 strip을 추가해주면 됩니다. 위 코드를 실행하면 줄 사이의 공백이 사라지는 것을 확인해볼 수 있습니다.
외부 파일을 다루거나 자료 분석을 하다보면 불필요한 공백을 자주 발견할 수 있는데요. 이때, strip이 아주 유용하게 사용될 수 있습니다.
💾 Split
이번에는 strip과 마찬가지로 데이터 분석에서 유용하게 쓰이는 split을 배워보겠습니다.
some_string = "2. 4. 6. 8. 10"
print(some_string.split("."))위 코드는 수와 점(.)으로 이루어진 문자열을 생성하고 split을 호출하여 그 결과를 출력합니다. 결과를 한 번 볼까요?
['2', ' 4', ' 6', ' 8', ' 10']하나의 리스트가 만들어졌습니다!
split은 파라미터를 기준으로 문자열을 나눕니다. 위 코드의 경우 점(.)이 문자열을 나누는 기준이 되었죠. 위 리스트를 자세히 보면 첫번째 요소를 제외한 나머지 요소의 앞 부분에 공백이 있는데요. 이는 점을 기준으로 나누는 과정에서 공백이 제외되었기 때문입니다.
그런데 이 공백은 보기 영 거슬립니다. 이럴 때 앞서 배운 strip을 사용할 수 있지만 지금은 다른 방법을 한 번 활용해보겠습니다.
원래의 문자열을 살펴보면 숫자들 사이에 점과 공백이 하나씩 있습니다. 그럼 문자열을 나누는 기준을 점에서 점과 공백으로 바꿔주기만 하면 됩니다.
print(some_string.split(". "))['2', '4', '6', '8', '10']이렇게만 해줘도 불필요한 공백을 제거할 수 있습니다.
또 다른 예시를 한 번 봅시다.
real_name = "차, 정원"
print(real_name.split(", "))['차', '정원']이 예시는 다음과 같이 응용이 가능합니다.
real_name = "차, 정원"
name_list = real_name.split(", ")
family_name = name_list[0]
given_name = name_list[1]
print(family_name, given_name)차 정원성과 이름이 담긴 문자열에서 공백을 제거한 후 name_list 변수에 리스트 형태로 저장합니다. 그 상태에서 인덱스를 통해 각 요소를 분리하면 성과 이름을 깔끔하게 분리한 형태로 출력할 수 있습니다.
다음으로 조금 다른 예시를 한 번 봅시다.
print(" \n\n 1 \t 2 \n 3 4 5 \n\n")위 코드의 공백은 규칙성이 없습니다. 따라서 기준을 나누기가 조금 번거로운데요. 하지만 전반적으로 봤을 때, 숫자를 제외한 나머지는 모두 화이트 스페이스라는 패턴을 가지고 있습니다.
따라서, split의 기준을 화이트 스페이스로 두면 되는 것이죠. 화이트 스페이스를 파라미터로 설정할 때는 split의 괄호를 비워두면 됩니다.
print(" \n\n 1 \t 2 \n 3 4 5 \n\n".split())['1', '2', '3', '4', '5']그럼 숫자들 사이의 모든 공백이 사라지고 깔끔한 리스트가 완성됩니다.
마지막으로 주의사항을 알려드리겠습니다.
nums = " \n\n 1 \t 2 \n 3 4 5 \n\n".split()
print(nums[3] + nums[4])리스트의 요소를 출력하여 덧셈을 하고자 인덱스를 넣고 덧셈 연산을 한 뒤 그 결과를 출력하는 코드를 작성했습니다. 이때, 기대하고 있는 결괏값은 인덱스 3의 수 4와 인덱스 4의 수 5의 합인 9인데요. 결과는 '45'가 나옵니다. 왜 그런 걸까요?
split을 사용해서 만들어진 리스트의 모든 요소는 문자열입니다. 따라서, 덧셈 연산을 하게 되면 연결된 문자열이 나옵니다. 만약 정수 연산을 하고 싶다면 형변환을 하면 됩니다.
nums = " \n\n 1 \t 2 \n 3 4 5 \n\n".split()
print(int(nums[3] + nums[4]))9💾 파일 쓰기
파일을 읽는 방법을 알아봤다면 쓰는 방법도 알아봐야겠죠? 파일 읽기와 거의 유사합니다!
with open('my_file.txt', 'w') as f:open의 첫번째 파라미터로는 만들고 싶은 파일의 이름을 적고 두번째 파라미터에는 앞서 설명했듯 wirte의 약어인 'w'를 적습니다. 파일명 뒤에 확장자를 적어야 한다는 사실 잊지 마세요! 이번 파일도 마찬가지로 변수 f에 저장해 줍니다.
이제 파일에 뭔가를 작성할 수 있습니다. 물론 바로 작성하는 것이 아니라 f.write라는 함수가 필요합니다.
with open('my_file.txt', 'w') as f:
f.write("Hello, everyone!")
f.write("I am Takityaki :)")이제 이 코드를 실행하면 폴더에 my_file.txt 파일이 새로 생성됩니다. 이 파일을 클릭하면 에디터에 우리가 작성했던 글이 바로 출력됩니다.
Hello, everyone!I am Takityaki :)위 내용을 보면 두 문장 사이에 공백이 없습니다. 두 문장 사이를 띄어쓰고 싶으면 어떻게 해야할까요? '백슬래시 n'을 활용합시다!
f.write("Hello, everyone!\n")
f.write("I am Takityaki :)\n")Hello, everyone!
I am Takityaki :)그런데 위 코드를 두 번 실행했음에도 최근 코드의 결괏값만 출력됩니다. 이는 실행할 때마다 내용이 덮어 씌워지기 때문인데요. 이를 방지하고 싶으면 open의 파라미터로 'w' 대신 'a'를 넣으면 됩니다. 참고로 'a'는 'append(추가)'의 약어입니다.
with open('my_file.txt', 'w') as f:
f.write("Hello, everyone!\n")
f.write("I am Takityaki :)\n")Hello, everyone!
I am Takityaki :)
Hello, everyone!
I am Takityaki :)'a'를 사용할 때, 기존의 파일명을 쓰면 기존 파일에 내용이 추가되지만 새로운 파일명을 쓰면 새로운 파일을 생성합니다. 따라서, 파일이 존재하지 않아도 'a'를 사용할 수 있습니다.
이번 시간에는 본격적으로 Python을 응용해보기 위해 사용자 입력을 받는 방법과 파일을 읽고 쓰는 방법을 배워봤습니다. 다음 시간에는 이 내용을 바탕으로 본격적으로 프로그램을 작성해봅시다.
* 이 자료는 CODEIT의 '프로그래밍 기초 in Python'을 기반으로 작성되었습니다.