
💆♀️ 데이터 클리닝: 완결성
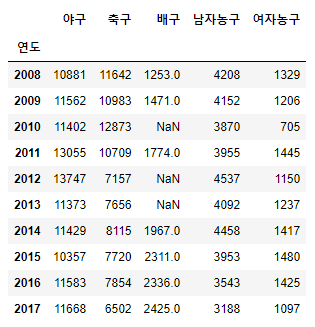
- 결측값
- 채워져야 하는데 비어 있는 값
- 데이터의 완결성이 없다는 지표
- 완전한 정보가 아니므로 판단을 어렵게 한다
- 없는 것이 제일 좋으나 필연적으로 발생한다면 원인을 파악해야 한다
- 결측값 찾는 법
.isnull()- 결측값만 True 반환
.isnull().sum()- 결측값의 수 파악 가능
df.isnull().sum()
- 결측값이 없는 dataset 만들기
- 결측값이 있는 레코드 제거
- 기존 DataFrame을 건들지 않고 새로운 DataFrame 생성
inplace=True를 통해 기존 DataFrame 변경
- 문제가 되는 열 자체를 제거
- 결측값이 많은 배구 column
- 단점
- 제거한 데이터를 완전히 잃어버린다
df.dropna()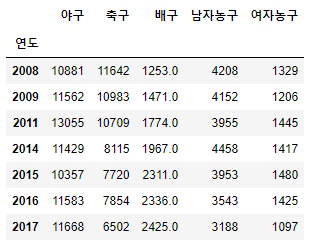
# 배구 column만 제외
df.dropna(axis='columns')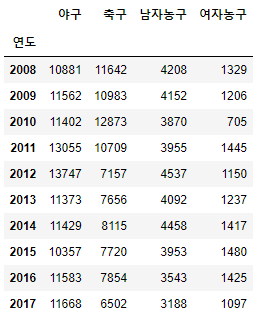
- 결측값 대체하기
.fillna()- 인자에 들어가는 값으로 대체
- 새로운 DataFrame 생성
# 0으로 대체
df.fillna(0)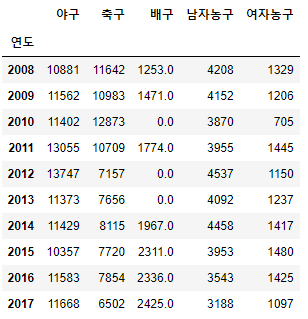
# 평균으로 대체
df.fillna(df.mean())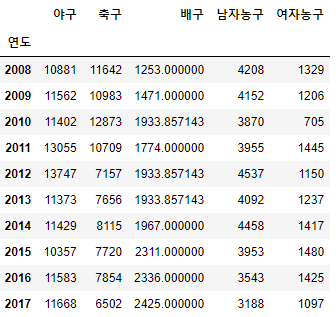
# 중간값으로 대체
df.fillna(df.median())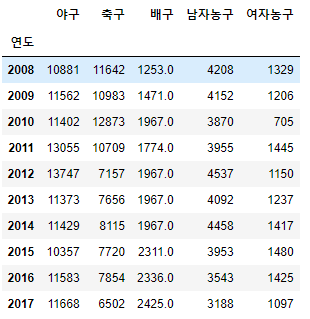
💆♀️ 데이터 클리닝: 유일성
- row의 중복 확인
df.index
df.index.value_counts()
df.loc['07월 31일']
- row의 중복 제거
.drop_duplicates()- 기존 DataFrame을 건드리지 않고 새로운 DataFrame 생성
df.drop_duplicates()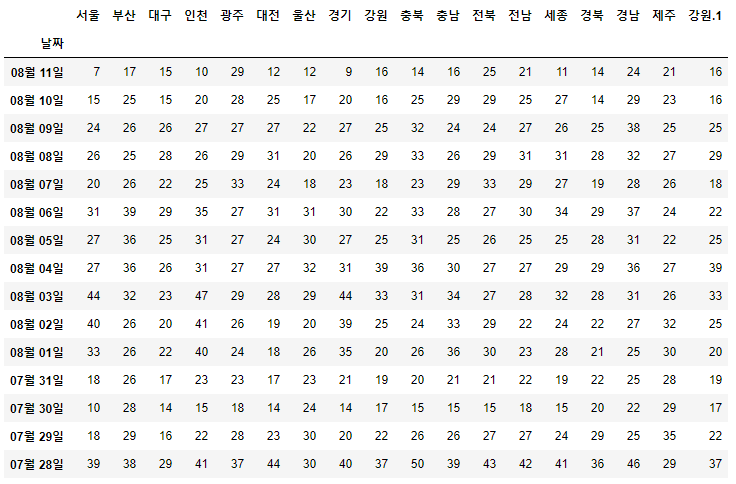
- column의 중복 제거
.T- 행/열 자리 바꾸기
- inplace 옵션 사용할 수 없으므로 df 변수에 저장
.drop_duplicates()- 완전히 동일한 값일 경우, 중복이므로 제거됨
df.T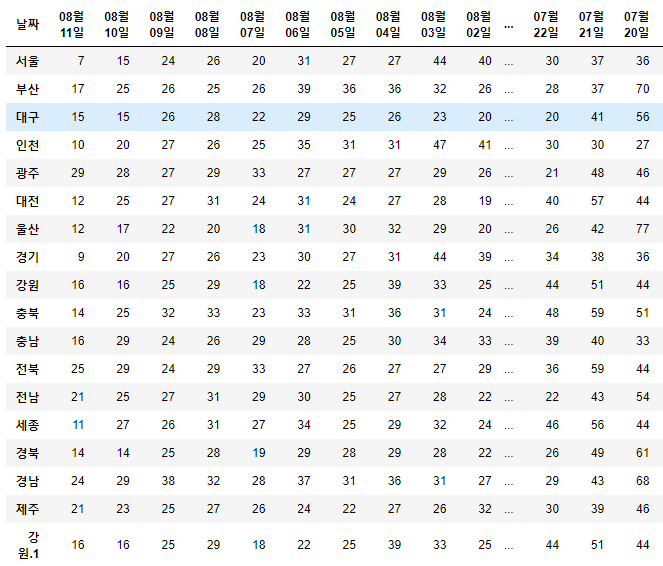
df.T.drop_duplicates()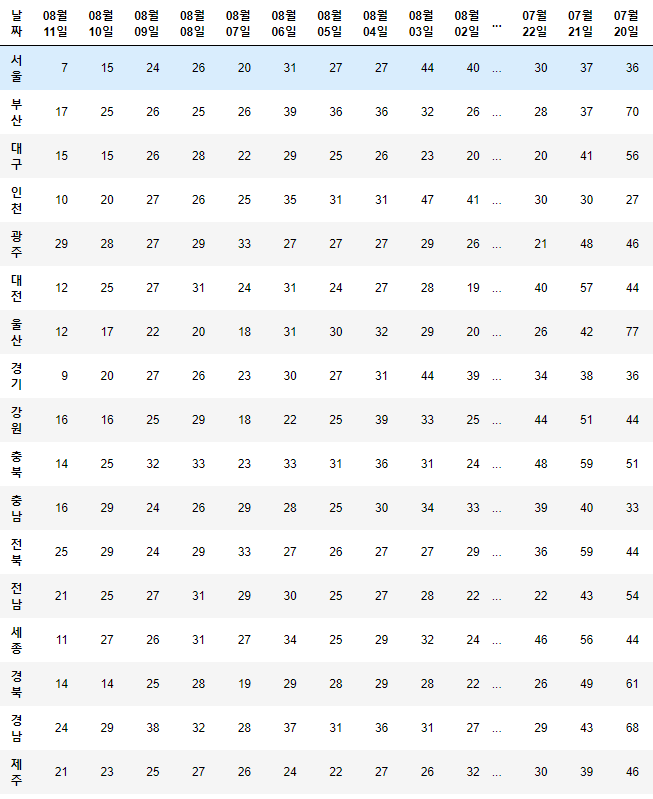
df = df.T.drop_duplicates().T
df
💆♀️ 데이터 클리닝: 정확성
- 이상점
- 다른 값들과 멀리 떨어져 있는 데이터
- 데이터의 부정확성을 알려주는 지표
- 이상점을 판단하는 기준
- 절대적인 기준은 없다
- 이상점 판단 예시: 박스플롯
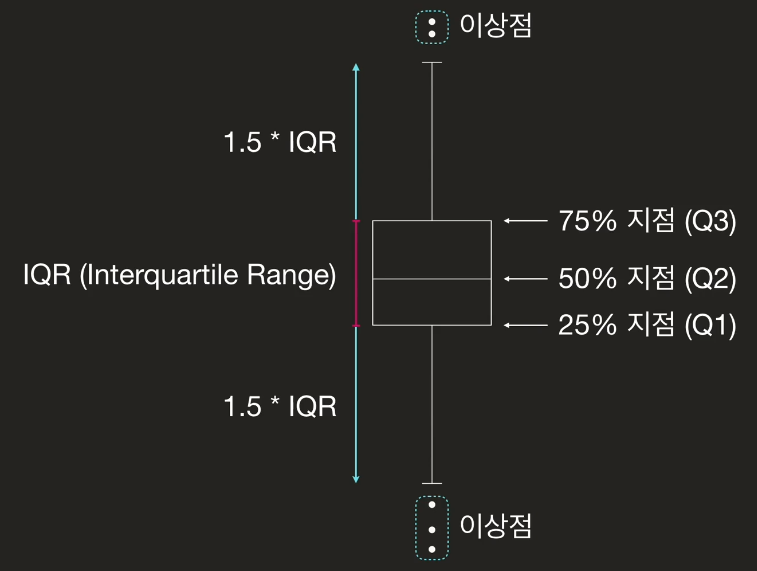
- IQR(Interquartile Range)
- 75% 지점과 25% 지점의 거리
- 25% 지점에서
1.5 * IQR밑으로 떨어질 때 - 75% 지점에서
1.5 * IQR위로 벗어날 때
- IQR(Interquartile Range)
- 이상점이 잘못된 정보라면?
- 정보 수정
- 정보 삭제
- 이상점이 제대로 된 정보라면?
- 분석에 방해되면 삭제
- 때로는 의미 있는 정보로 활용 가능
- 상황에 맞게 판단할 것
💆♀️ 데이터 클리닝: 정확성 2
- 이상점 확인하기
df.plot(kind='box', y='abv').png)
- 25% 지점과 75% 지점 받아오기
.describe().quantile()
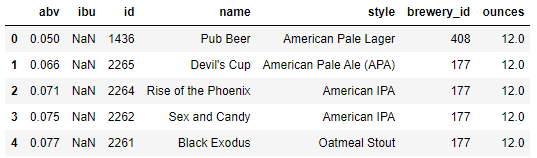
df['abv'].describe()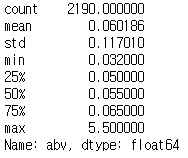
df['abv'].quantile(0.25)0.05df['abv'].quantile(0.75)0.065- iqr 변수 선언하기
q1=df['abv'].quantile(0.25)
q3=df['abv'].quantile(0.75)
iqr = q3-q1- 이상점 구하기
- 소주인 참이슬이 맥주 데이터에 들어감
- 보드카가 맥주 데이터에 들어감
5.500: 데이터 입력 오류
condition = (df['abv'] < q1 - 1.5 * iqr) | (df['abv'] > q3 + 1.5 * iqr)
df[condition]
- 이상점 수정하기
df.loc[2250, 'abv'] = 0.055
df.loc[2250]
condition = (df['abv'] < q1 - 1.5 * iqr) | (df['abv'] > q3 + 1.5 * iqr)
df[condition]
- 이상점 삭제하기
df[condition].indexInt64Index([963, 1856], dtype='int64')df.drop(df[condition].index, inplace=True)df.plot(kind='box', y='abv').png)
💆♀️ 데이터 클리닝: 정확성 3
- 관계적 이상점(Relational Outlier)
- 두 변수의 관계를 고려했을 때 이상한 데이터
- 예:) 키 180cm, 몸무게 40 kg
- 이상점 확인
- 쓰기 점수가 100점 만점에 700점?
df.plot(kind='scatter', x='reading score', y='writing score')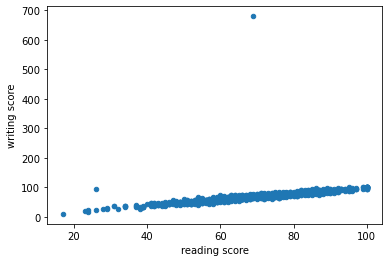
- 상관 관계 파악하기
df.corr()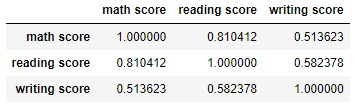
- 이상점 삭제하기
df[df['writing score'] > 100]
df.drop(51, inplace=True)- 결과 확인하기
- writing 관련 상관계수 향상
df.plot(kind='scatter', x='reading score', y='writing score')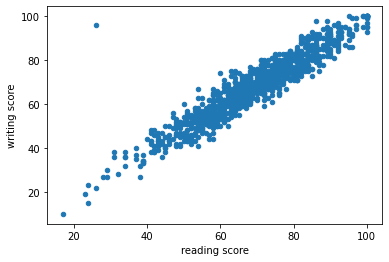
df.corr()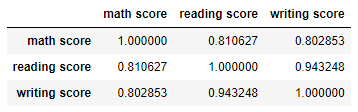
* 출처: CODEIT - 데이터 사이언스 입문
There's Only One Thing To Do: Learn All We Can