
📈 시각화의 두 가지 목적
- 시각화가 중요한 이유
- 분석에 도움을 준다
- 데이터셋이 커질수록 인사이트를 찾기 어렵다
- 그래프의 패턴을 통해 보이지 않는 문제들을 볼 수 있다
- 이상점(Outlier)을 쉽게 찾을 수 있다
- 리포팅에 도움이 된다
- 리포팅: 데이터 분석 결과를 보고하는 것
- 그래프는 직관적이고 이해하기 쉽다
- 예쁜 그래프는 이목 끌기 쉽다
- 분석에 도움을 준다
📈 선 그래프
- 선 그래프
- 변화를 보여주기에 적합한 그래프
- 예:) 매년 자라는 아이의 키 그래프
- x축: 년도
- y축: 키
- 각 해에 잰 키를 점으로 찍고 각 점을 연결하여 선을 그린다
- 해가 지날수록 어느 정도 성장하는지 알 수 있다
- x축: 시간과 관련된 값
- y축: 관찰하고 싶은 값
- Python으로 선 그래프 그리기
%matplotlib inline- 그림, 도표, 소리 같은 결과물인 Rich output에 대한 표현 방식
df.plot()- 파라미터로 kind를 넘겨줘야 한다(kind='line')
- 선 그래프는 기본 그래프이기 때문에 생략 가능
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
df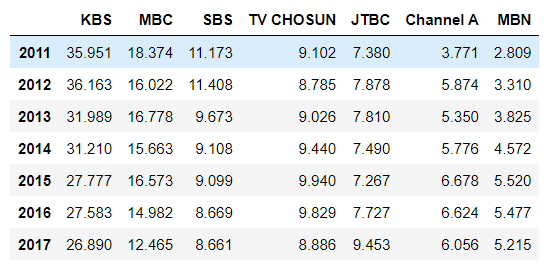
df.plot()
- 하나의 열에 대한 그래프만 출력하기
df.plot(y='KBS')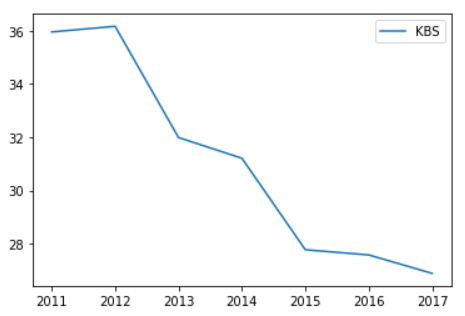
- 원하는 열들에 관한 그래프만 출력하기
- 첫번째 방법
- 원하는 열들이 담긴 리스트를 넘겨주기
- 두번째 방법
- DataFrame에서 원하는 열들만 추출 후 그래프로 나타내기
- 첫번째 방법
df.plot(y=['KBS, 'JTBC'])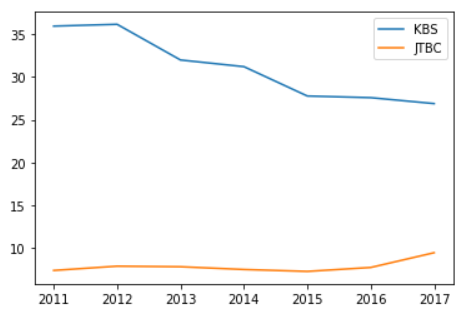
df[['KBS', 'JTBC']] # 2차원 >> DataFrame
df[['KBS', 'JTBC']].plot()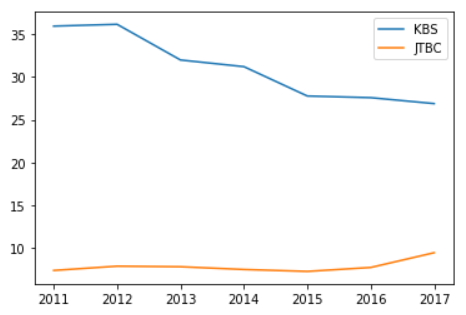
- Pandas Series에도 plot() 적용 가능
df['KBS'] # 1차원 >> Pandas Series
df['KBS'].plot()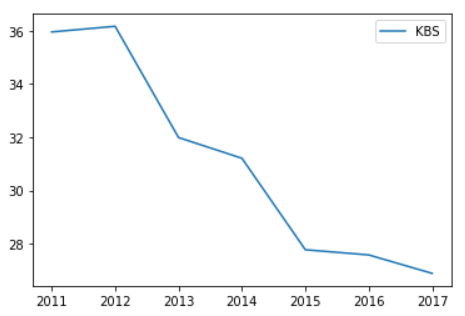
- 선그래프 데이터는 수치만 가능
- 문자 데이터는 오류 발생하므로 주의
📈 막대 그래프
-
막대 그래프
- 다양한 카테고리를 특정 기준으로 비교하기 위해 사용
- 예) 한국에서 가장 인기 있는 운동
- 골프, 축구, 야구, 수영, 볼링 등 다양한 카테고리
- 성별에 따른 구분 가능
-
Python으로 막대 그래프 그리기
- 파라미터:
kind='bar'
- 파라미터:
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/sports.csv', index_col=0)
df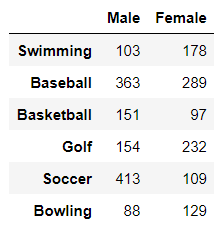
df.plot(kind='bar')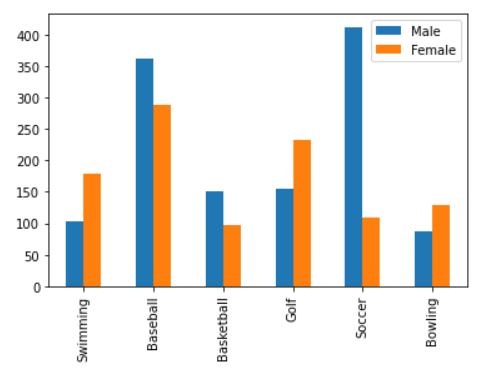
- 가로 막대 그래프 그리기
- 파라미터:
kind='barh'(horizontal)
- 파라미터:
df.plot(kind='barh')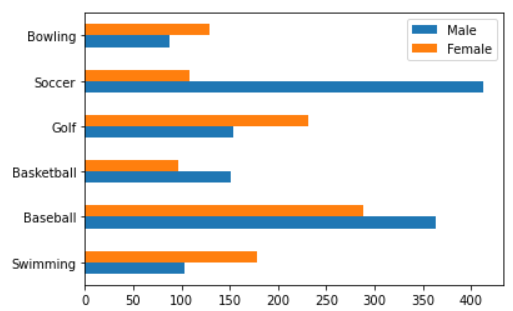
- 누적 막대 그래프
stacked옵션을 준다
df.plot(kind='bar', stacked=True)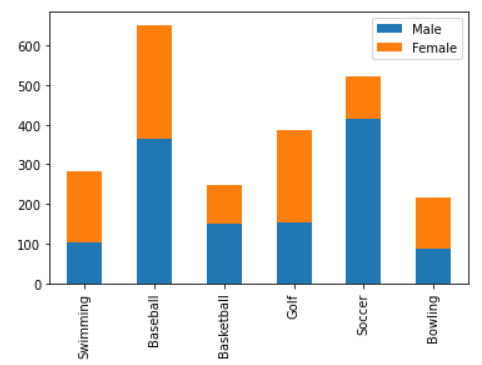
- 특정 열에 대한 그래프만 추출
df['Female'].plot(kind='bar')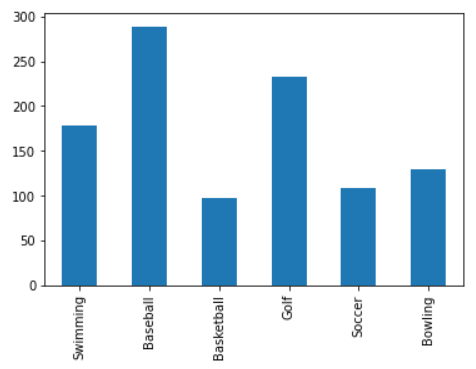
📈 파이 그래프
- 파이 그래프
- 비율을 나타내는 그래프
- 절대적인 수치보다 상대적인 수치(비율)를 표현하기에 적합하다
- 예:) 대통령 선거 결과
- 표의 수보다 몇 퍼센트를 차지했는지에 더 관심이 많다
- Python으로 파이 그래프 그리기
- 파라미터:
kind=pie
- 파라미터:
%matplotlib inline
import pandas as pd
df=pd.read_csv('data/broadcast.csv', index_col=0)
df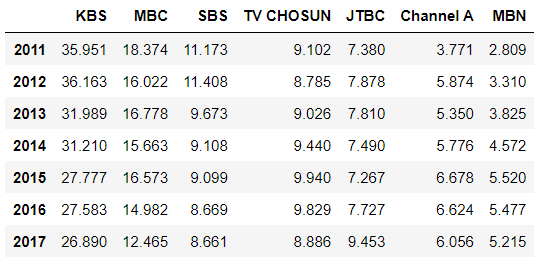
df.loc[2017].plot(kind='pie')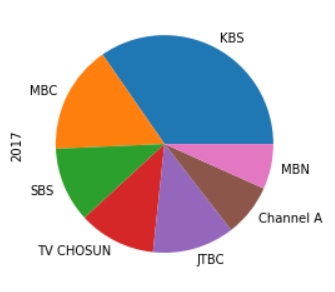
📈 히스토그램
- 정리
- 선 그래프 for 변화
- 막대 그래프 for 항목 비교
- 파이 그래프 for 비율
- 히스토그램
- 여러 값들을 하나의 항목으로 묶어 값들의 분포를 확인하는 그래프
- 예:) 남고생의 키 분포
- 160~170 / 170.1~180 / 180.1~190 / ...
- Python으로 히스토그램 그리기
- 파라미터:
kind='hist' - 측정하고 싶은 column을 y에 넣는다
- default: 범위 개수 = 10
- 막대 개수 지정:
bins=원하는 개수
- 파라미터:
%matplotlib inline
import pandas as pd
df=pd.read_csv('Downloads/body.csv', index_col=0)
df.head(10)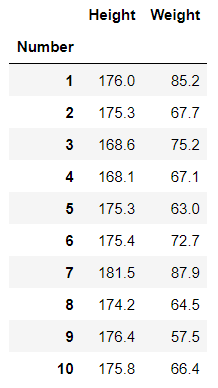
df.plot(kind='hist', y='Height')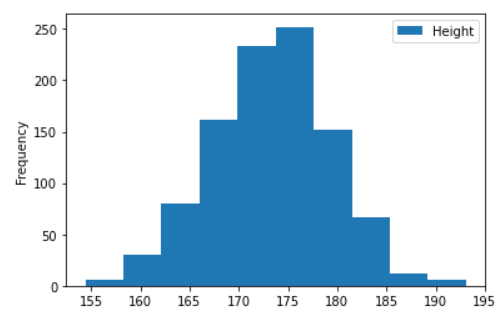
df.plot(kind='hist', y='Height', bins=5)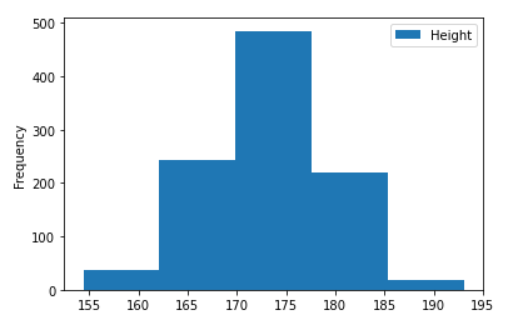
📈 박스 플롯
- 박스 플롯
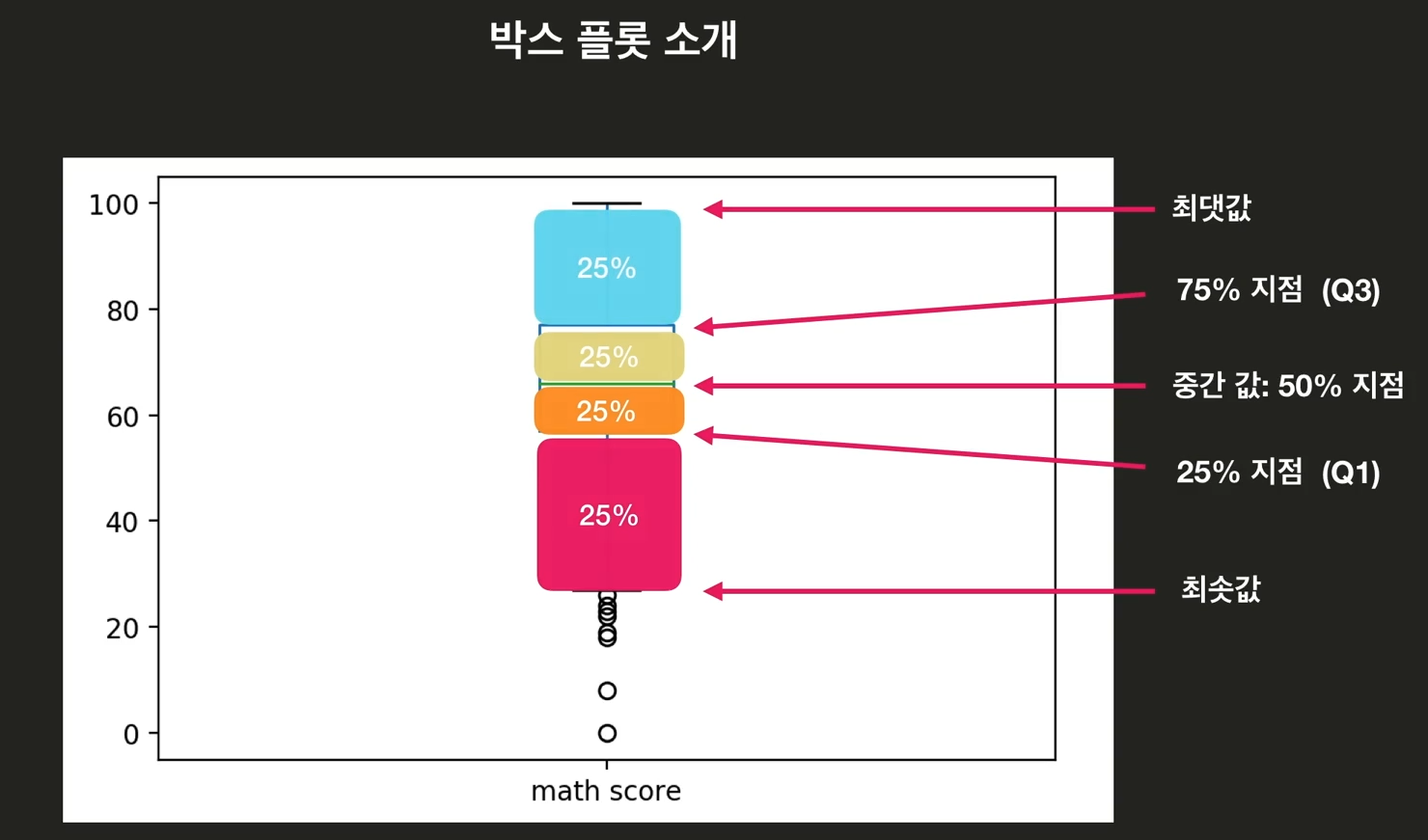
- 데이터 셋에 대한 통계 정보를 시각적으로 보여주기 위해 사용
- 총 5개의 통계 값으로 데이터 셋 요약
- 데이터 셋의 최댓값 / 최솟값 / 중간값(Q2) / 75%(Q3) / 25%(Q2)
- Q1~Q3: 박스(box)
- 최솟값, 최댓값: 위스커(whisker, 수염)
- box and whisker plot
- 이상점: box and whisker를 제외한 영역의 데이터
- 박스 플롯 인사이트
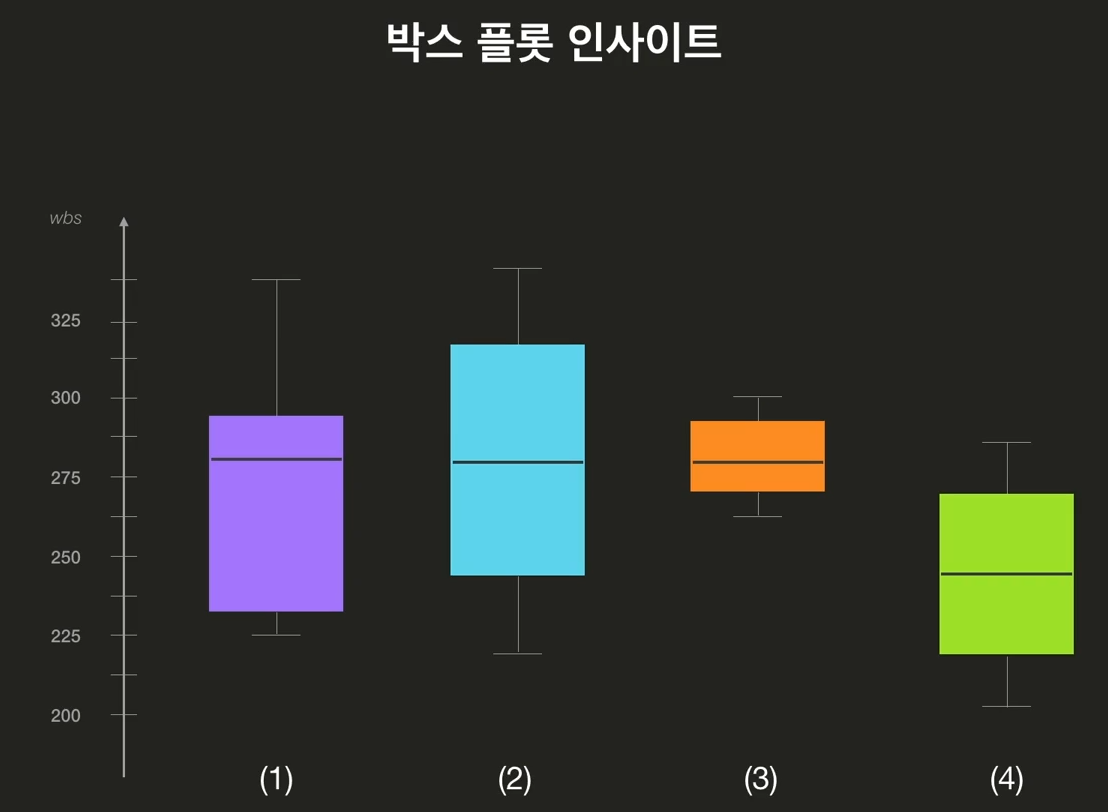
- 아주 큰 데이터 셋에 대해서도 대략적인 파악 가능
- 어느 한 수치만 가지고 판단하면 안 된다!
- 1번, 2번에 비해 짧은 3번
- 3번의 값들이 전반적으로 유사하다
- 1번, 2번의 값들은 다양하며 좀 더 분산되어 있다
- 4번에 비해 더 위에 있는 3번
- 3번의 값들이 4번의 값들보다 전반적으로 더 크다
- 1번은 다른 데이터 셋들에 비해 균형이 맞지 않다
- 짧은 구간에서는 비슷한 값들이 있고 긴 구간에서는 분산 된 값들이 있다
- 1번, 2번, 3번의 중간값이 모두 같다
- Python으로 박스 플롯 그리기
- 파라미터:
kind='box' - 원하는 column을 y의 값으로 지정
- 28점 아래 값들은 이상점으로 처리
- 파라미터:
%matplotlib inline
import pandas as pd
df=pd.read_csv('Downloads/exam.csv', index_col=0)
df.head()
df.plot(kind='box', y='math score')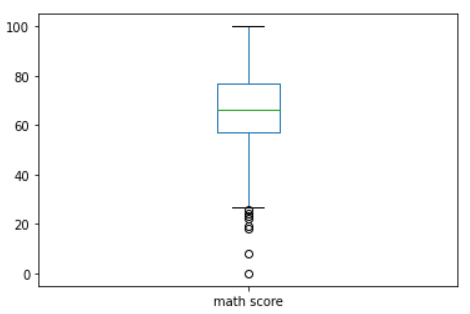
df[math score'].describe() # 통계 결과
- 여러 박스 플롯 동시에 그리기
- y에 리스트 넘겨주기
df.plot(kind='box', y=['math score', 'reading score', 'writing score'])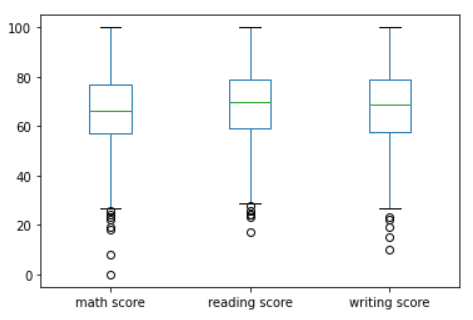
📈 산점도
- 산점도(scatter plot)
- 상관관계를 보여주기에 적합한 그래프
- 예:) 키와 몸무게의 연관성 / 학교 등수와 행복 지수의 연관성
- 점들의 분포 양상에 따라 두 특징의 연관성 파악
- 일직선: 아주 강한 연관성
- 흩어짐: 약한 연관성
- 반대 방향 일직선: 아주 강한 연관성 + 반비례
- Python으로 산점도 그리기
- 파라미터:
kind=scatter - 원하는 column들을 x, y에 각각 넣는다
- 파라미터:
%matplotlib inline
import pandas as pd
df=pd.read_csv('Downloads/exam.csv', index_col=0)
df.head()
df.plot(kind='scatter', x='math score', y='reading score')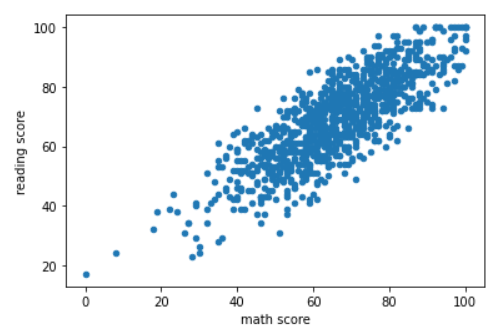
df.plot(kind='scatter', x='reading score', y='writing score')* 출처: CODEIT - 데이터 사이언스 입문
There's Only One Thing To Do: Learn All We Can