실시간 적재에 활용하는 기술
HBase
- HTable
- 칼럼 기반 데이터 구조를 정의한 테이블
- 행 기반의 기존 RDBMS(ACID)의 문제점 극복
- 원하는 칼럼에 바로 접근할 수 있다는 장점
- 칼럼 패밀리
- 공통점이 있는 칼럼들의 그룹
- 로우키
- 테이블의 로우를 식별해서 접근
- 칼럼 기반 데이터 구조를 정의한 테이블
- HRegion
- HTable의 크기에 따라 자동으로 수평 분할 발생
- 분할된 블록을 HRegion 단위로 지정
- HRegionServer
- 분산 노드별 HRegionServer가 구성
- 하나의 HRegionServer에는 다수의 HRegion 생성
- HRegion 관리
- HMaster
- HRegion 서버 관리
- HRegion들이 속한 HRegion 서버의 메타 정보 관리
- Store
- 하나의 Store에는 칼럼 패밀리가 저장 및 관리
- MemStore와 HFile로 구성
- MemStore
- Store 내의 데이터를 인메모리에 저장 및 관리하는 데이터 캐시 영역
- HFile
- Store 내의 데이터를 스토리지(디스크)에 저장 및 관리하는 영구 저장 영역
- 라이선스
- Apache
- 유사 프로젝트
- MongoDB, Cassandra, ...
redis
- 의의
- HBase로의 적재 과정 중에 일부 데이터를 추출하여 redis에 적재할 수 있다
- 인메모리 캐쉬
- 그러나, 영구 저장 기능 존재
- Master
- 분산 노드 간의 데이터 복제와 Slave 서버 관리를 위한 마스터 서버
- Slave
- 다수의 Slave 서버는 주로 읽기 요청 처리
- Master 서버가 쓰기 요청 처리
- Replication
- Master 서버에 쓰인 내용을 Slave 서버로 복제해서 동기화 처리
- AOF/Snapshot
- 데이터를 영구적으로 저장하는 기능
- 명령어를 기록하는 AOF와 스냅샷 이미지 파일 방식 지원
- Sentinel
- 레디스 3.x부터 지원하는 기능
- Master 서버에 문제가 발생할 경우, 새로운 Master를 선출하는 기능(from Slave)
- 라이선스
- BSD
- 아키텍처
- 클라이언트
- Master에 데이터를 적고 Slave로부터 데이터를 읽음
- Master
- Slave에 데이터 복제
- 클라이언트
Storm
- 개요
- Kafka의 consumer에 해당하는 기능
- 전처리와 집계에 강한 특성
- Spout
- 외부로부터 데이터를 유입받아 가공 처리해서 튜플 생성
- 생성된 튜플 Bolt에 전송
- Bolt
- 튜플을 받아 실제 분산 작업 수행
- 필터링, 집계, 조인 등의 연산을 병렬로 실행
- Topology
- Spout-Bolt의 데이터 처리 흐름 정의
- 하나의 Spout와 다수의 Bolt로 구성
- Nimbus
- Topology를 Supervisor에 배포하고 작업 할당
- Supervisor를 모니터링하다 필요 시, fail over 처리
- Supervisor
- Topology를 실행할 Worker 구동
- Topology를 Worker에 할당 및 관리
- Worker
- Supervisor 상에서 실행 중인 자바 프로세스
- Spout와 Bolt 실행
- Executor
- Worker 내에서 실행되는 자바 스레드
- Tasker
- Spout 및 Bolt 객체 할당
- 라이선스
- Apache
- 유사 프로젝트
- Spark Stream
- 배치 처리를 micro 단위로 수행 >> 실시간
- Spark Stream
Esper
- Event
- 실시간 스트림으로 발생하는 데이터들의 특정 흐름 또는 패턴 정의
- EPL
- 유사 SQL을 기반으로 하는 이벤트 데이터 처리 스크립트 언어
- Input Adapter
- 소스로부터 전송되는 데이터를 처리하기 위한 어댑터 제공
- CSV, Socket, Http...
- Output Adapter
- 타깃으로 전송하는 데이터를 처리하기 위한 어댑터 제공
- HDFS, CSV, Socket, Email...
- Window
- 실시간 스트림 데이터로부터 특정 시간 또는 개수를 설정한 이벤트들을 메모리 상에 등록한 후 EPL을 통해 결과 추출
- 라이선스
- GPL
HBase 실습
- HBase shell 열기
hbase shell- HBase Table 만들기
cf: 컬럼 패밀리
create 'smartcar_test_table', 'cf'- 테이블에 데이터 넣기
- key-value
put 'smartcar_test_table', 'row-key1', 'cf:model', 'Z0001'- 테이블에서 데이터 불러오기
- timestamp
get 'smartcar_test_table', 'row-key1'
- 테이블 삭제
- disable 후, 삭제
disable 'smartcar_test_table'
drop 'smartcar_test_table'- HBase 관리자
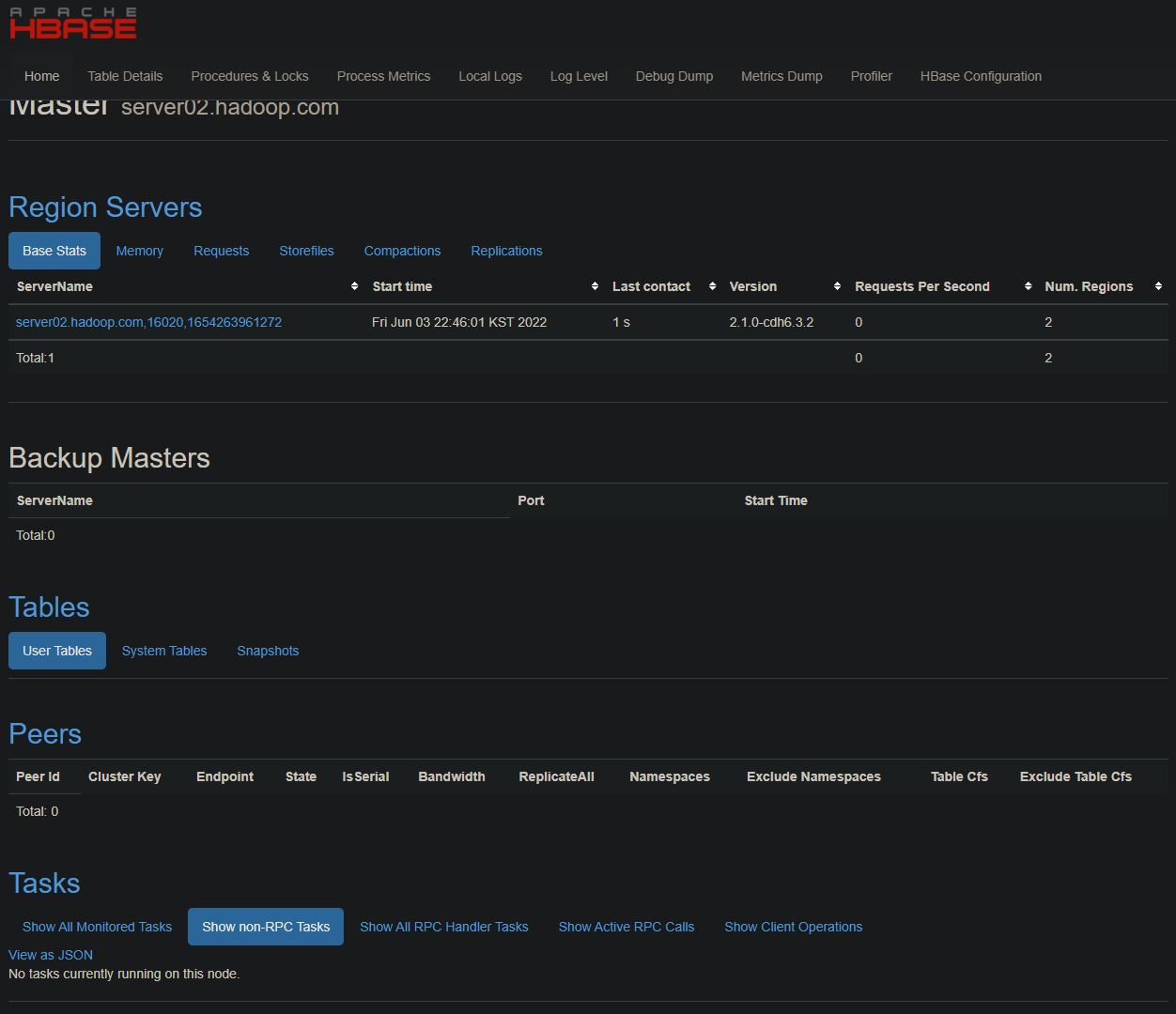
- 16010
Redis 설치
- build를 위한 gcc 및 tcl 설치
yum install -y gcc*
yum install -y tcl- redis 설치
// 압축 파일 다운로드
wget http://download.redis.io/releases/redis-5.0.7.tar.gz
// 압축 파일 해제
tar -xvf redis-5.0.7.tar.gz
// make build
make
make install- 서버 실행
// 실행 권한 주기
chmod 755 install_server.sh
// 실행
./install_server.sh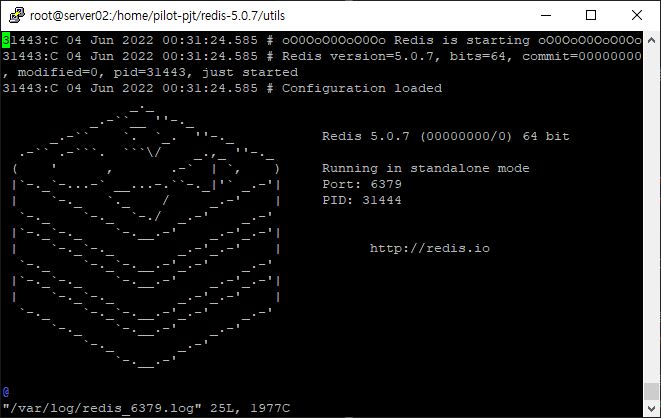
- 서비스 상태 확인
service redis_6379 statusRedis is running...- 서비스 재시작
service redis_6379 restart- redis cli 사용하기
redis-cli- redis 서버에 데이터 set 하기
set key:1 Hello!Bigdata- redis 서버로부터 데이터 get 하기
get key:1"Hello!Bigdata"- 데이터 삭제하기
del key:1- cli 종료하기
quitstorm 설치
- storm 설치
wget http://archive.apache.org/dist/storm/apache-storm-1.2.3/apache-storm-1.2.3.tar.gz- storm 압축 해제
tar -xvf apache-storm-1.2.3.tar.gz- 경로 심볼릭 링크 걸기
ln -s apache-storm-1.2.3 storm- yaml 파일 수정하기
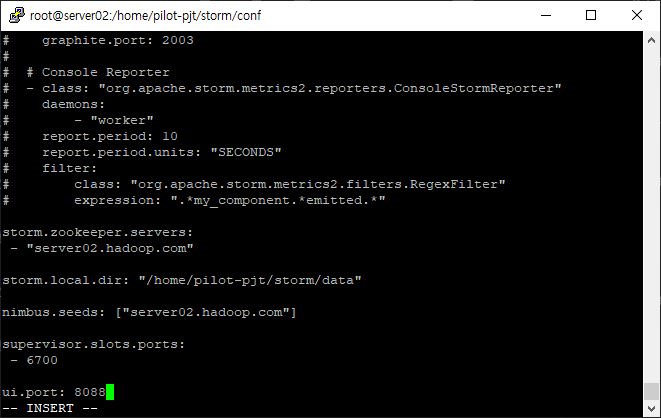
- 주키퍼 정보
- local 경로
- nimbus
- supervisor
- ui 서버
- 오버헤드 방지 설정하기
- INFO를 ERROR로 수정
vi worker.xml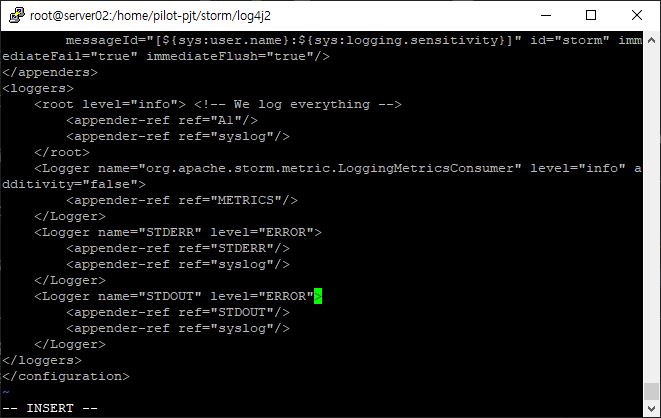
vi cluster.xml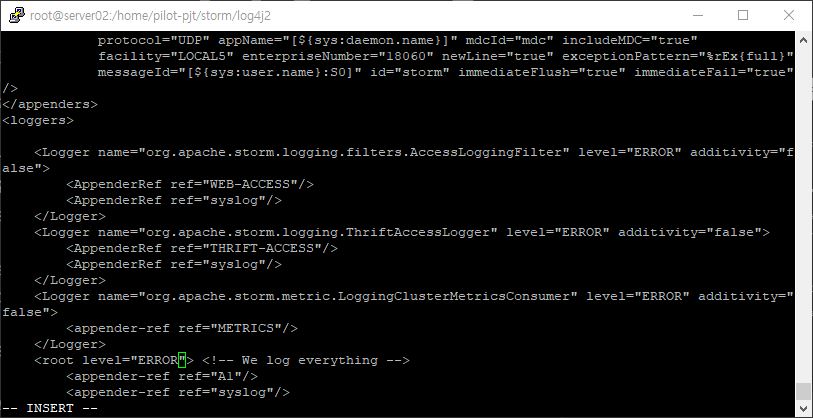
- root 환경 설정하기
bin- 실행 파일이 모여있는 곳
vi /root/.bash_profile
// 적용하기()
cd ~
source .bash_profile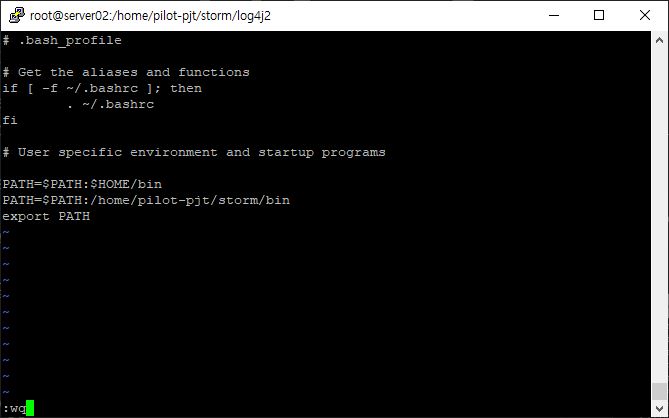
- java version 확인하기
java -version- 자동 실행 스크립트 파일 옮기기
- 리눅스 시작 시, 스톰 자동 실행
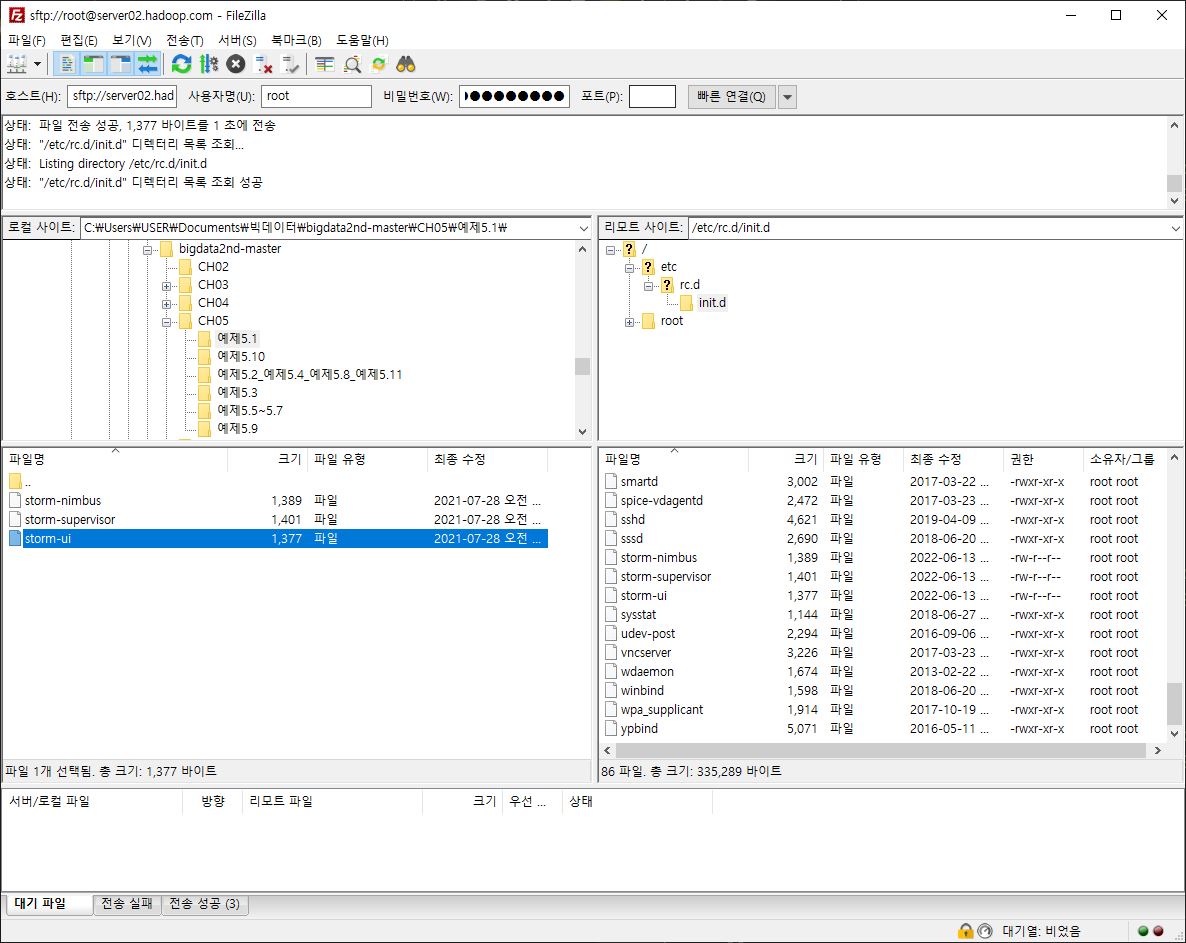
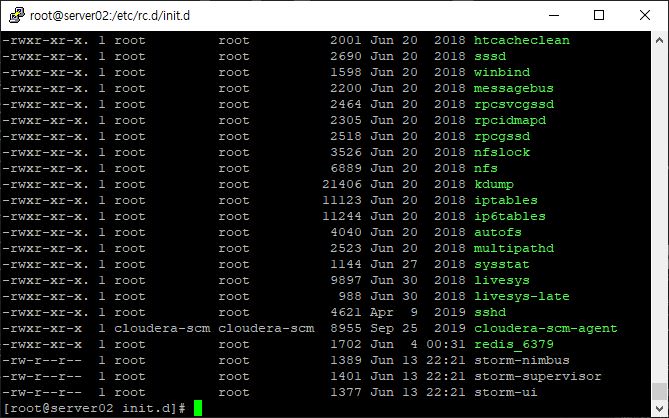
- 리눅스 시작 시, 스톰 자동 실행
- 파일 권한 변경
// 실행 가능
chmod 755 storm-nimbus
chmod 755 storm-supervisor
chmod 755 storm-ui- log 디렉토리 및 pid 디렉토리 지정
mkdir /var/log/storm
mkdir /var/run/storm- 서비스 기동하기
// 순서 지키기
service storm-nimbus start
service storm-supervisor start
service storm-ui start- 서비스 가동 확인하기
service storm-nimbus status
service storm-supervisor status
service storm-ui status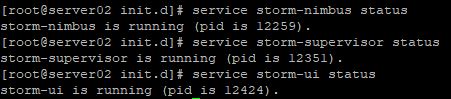
- storm ui
경로: server02.hadoop.com:8088
실시간 적재
- StormTopology 생성하기
- spout
- Kafka
- 데이터 유입(from Flume) 담당
- Bolt
- split >> HBase
- Esper >> Redis (과속 이벤트 only)
- spout
- StormTopology 내부 코드
- java program
TopologyBuilder driverCarTopologyBuilder = new TopologyBuilder();
// kafka 서버
String bootstrapServers = "server02.hadoop.com:9092";
// kafka 브로커에 생성한 topic
String topic = "SmartCar-Topic";
// spout configuration 설정
Config conf = new Config();
conf.setMaxSpoutPending(20);
conf.setNumWorkers(1);
// 데이터 유입 시간 간격
KafkaSpoutRetryService kafkaSpoutRetryService = new KafkaSpoutRetryExponentialBackoff(
KafkaSpoutRetryExponentialBackoff.TimeInterval.microSeconds(500),
KafkaSpoutRetryExponentialBackoff.TimeInterval.milliSeconds(2),
Integer.MAX_VALUE,
KafkaSputRetryExponentialBackoff.TimeInterval.seconds(10));// 주키퍼 호스트 정보
String zkHost = "server02.hadoop.com:2181";
// storm topology 설정
TopologyBuilder driverCarTopologyBuilder = new TopologyBuilder();
// kafka의 brokerhost 정보를 zookeeper로부터 가져오기
BrokerHosts brkBost = new ZkHosts(zkHost);
String topicName = "SmartCar-Topic";
String zkPathName = "/SmartCar-Topic";
// spoutconfig 정보 생성
SpoutConfig spoutConf = new SpoutConfig(brkBost, topicName, zkPathName, UUID.randomUUID().toString());
// 스키마 데이터 타입
spoutConf.scheme = new SchemeAsMultiScheme(new StringScheme());
// 데이터 offset 정보 사용
spoutConf.useStartOffsetTimeIOffsetOutOfRange=true;
// start offset time 설정
spoutConf.startOffsetTime=kafka.api.OffsetRequest.LatestTime();
// kafka spout 객체 생성
KafkaSput kafkaSpout = new KafkaSpout(spoutConf);// kafka spout 설정
driverCarTopologyBuilder.setSpout("kafkaSpout", kafkaSpout, 1);
// split 및 esper bolt 설정
// allGrouping: 모든 bolt에 작업 스트림 복제
driverCarTopologyBuilder.setBolt("splitBolt", new SplitBolt(),1).allGrouping("kafkaSpout");
driverCarTopologyBuilder.setBolt("esperBolt", new EsperBolt(),1).allGrouping("kafkaSpout");- split bolt 핵심 기능
- HBase 스키마에 맞게 분리/재구성하는 역할
- split bolt 기능 구현
public void execute(Tuple tuple, BasicOutputCollector collector) {
String tValue = tuple.getString(0);
//발생일시(14자리), 차량번호, 가속페달, 브레이크페달, 운전대회적각, 방향지시등, 주행속도, 뮤직번호
// , 단위로 분리하여 배열에 담기
String[] receiveData = tValue.split("\\,");
// 새로운 dataset 만들기
collector.emit(new Values(new StringBuffer(receiveData[0]).reverse() + "-" + receiveData[1] ,
receiveData[0], receiveData[1], receiveData[2], receiveData[3],
receiveData[4], receiveData[5], receiveData[6], receiveData[7]));}
// HBase bolt data를 HBase 스키마에 맞게 전달(맵핑)
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("r_key", "date","car_number",
"speed_pedal", "break_pedal", "steer_angle",
"direct_light", "speed", "area_number"));}
There's Only One Thing To Do: Learn All We Can