🤖 머신러닝이란?
- 머신러닝(Machine Learning)
- 기계 학습
- 기계가 학습을 통해 발전하는 것
- 일반적인 프로그램 vs. 머신러닝 프로그램
- 일반적인 프로그램
- 주어진 업무만 수행
- 머신러닝 프로그램
- 경험을 통해 스스로 업무 능력 향상
- 일반적인 프로그램
- 스팸 메일 분류 프로그램
- 인간이 정해주는 규칙에는 한계가 있다
- 규칙을 코드에 명시
- 스팸 메일 기준 다양함
- 설명할 수 없는 기준들
- 머신러닝은 스스로 규칙을 찾는다
- 규칙을 코드에 명시X
- 새로운 데이터를 통해 학습
- 80%의 정확도 >> 92%의 정확도
- 인간이 정해주는 규칙에는 한계가 있다
- 톰 미첼(Tom Mitchell)의 정의
- 기계 학습
- 프로그램이 특정 작업(T)을 하는 데 있어서 경험(E)을 통해 작업의 성능(P)을 향상시키는 것
- 스팸 메일 분류 프로그램
- 작업(T): 스팸 분류
- 경험(E): 새로운 이메일 분류
- 성능(P): 분류 정확도
- 새로운 이메일 분류를 반복함에 따라 분류 정확도가 향상하면 머신러닝 프로그램에 해당
- 기계 학습
🤖 머신러닝이 핫해진 이유
- 사용 가능한 데이터의 증가
- 경험 = 데이터
- 새로운 데이터를 통해 경험 가능
- 데이터가 충분하지 않으면 경험할 수 없다
- 아날로그
- 데이터 경시
- 인터넷의 발달과 스마트폰의 보급
- 데이터양 기하급수적 증가
- 머신러닝에 필요한 데이터 양 충족
- 경험 = 데이터
- 컴퓨터 성능 향상
- 방대한 양의 데이터 처리 및 빠른 연산 필요
- 머신러닝 활용성 증명
- 예:) 유튜브
- 시청자들 수가 많을 수록, 많은 시간을 시청할 수록 더 많은 데이터가 쌓이는 구조
- 수집된 데이터를 통해 콘텐츠 추천 및 개인 맞춤형 광고
- 광고 효율 증가에 따른 광고주들의 투자 증가
- 사용자의 서비스 만족도 증가
- 머신러닝을 통해 좋은 서비스 제공과 수익 창출 효과
- 예:) 유튜브
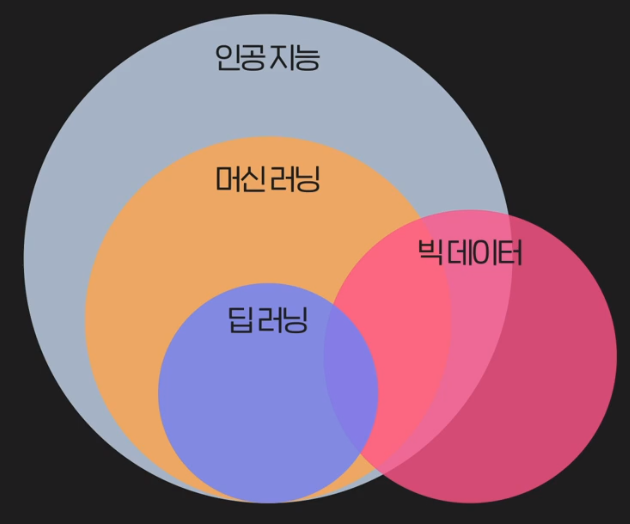
🤖 인공지능/빅데이터/딥러닝
- 빅데이터
- 엄청나게 많은 데이터를 다루는 분야
- 데이터 보관/처리법
- 데이터 분석 방법들
- 엄청나게 많은 데이터를 다루는 분야
- 인공지능
- 프로그램이 인간처럼 생각/행동하게 하는 학문
- 머신러닝은 인공지능의 수단 중 하나
- 딥러닝

- 머신러닝 기법 중 하나
- 프로그램을 학습시키는 방법 중 하나
- 깊어지는 층 >> 딥(Deep)러닝
- 머신러닝 기법 중 하나
- 정리
🤖 학습의 유형
- 지도 학습(Supervised Learning)
- 답이 있고 답을 맞추는 게 학습의 목적
- 프로그램에 수많은 문제와 그 문제에 대한 답을 가르침(지도)
- 예:) 스팸 메일 분류 프로그램
- 답: 스팸
- 예:) 아파트 가격 예측 프로그램
- 답: 아파트 가격
- 분류(Classification)
- 주어진 옵션 중에서 고르는 것
- 스팸 메일 분류 프로그램
- 회귀(Regression)
- 결괏값이 무수히 많고 연속적
- 아파트 가격 예측 프로그램
- 직관적, 더 많이 사용되는 학습 방법
- 비지도 학습(Unsupervised Learning)
- 답이 없으나 답을 맞추는 게 학습의 목적
- 프로그램이 정답 없이 '비슷한' 기준대로 묶음
- 답의 기준은 프로그램 스스로 정함
- 예:) 기사 분류 프로그램
- 날짜, 주제, 언론사 등의 기준을 사람이 정해주지 않고 기계 스스로 정의하여 분류
- 수학적으로 복잡한 내용이 담긴 학습 방법
🤖 k-NN 알고리즘
- 타이타닉 생존자 예측 프로그램
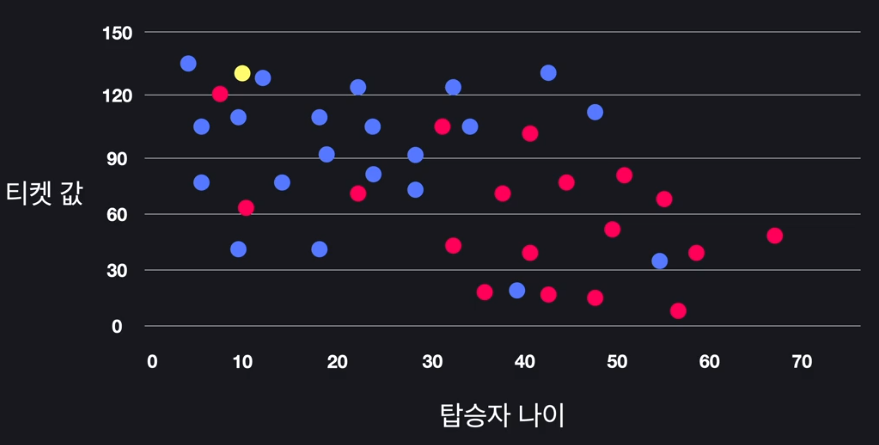
- 지도 학습
- 타이타닉 생존자
- 분류 학습
- 생존(blue)/사망(red)
- 가로(x축)
- 탑승자의 나이
- 세로(y축)
- 탑승자가 낸 티켓값
- 새로운 탑승자(yellow)
- 지도 학습
- k-최근접 이웃(k-Nearest Neighbors) 알고리즘
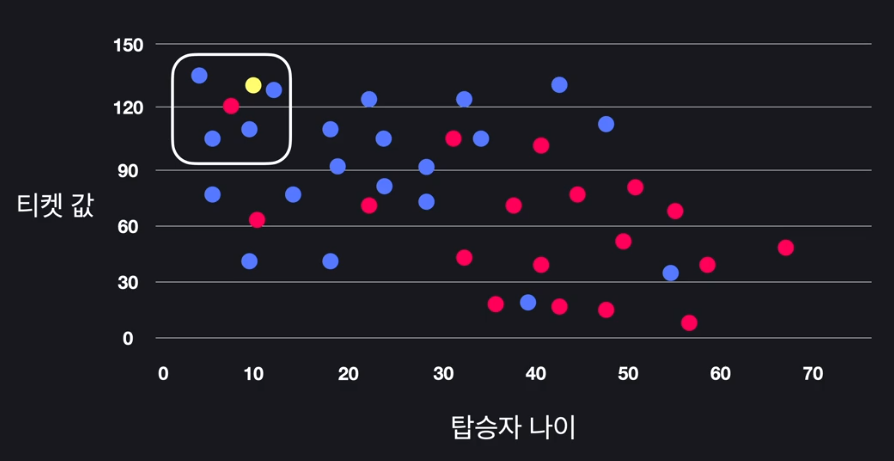
- 대상 데이터에서 가장 가까운 이웃 데이터 k개를 찾음
- k = 5, 가장 가까운 이웃 데이터 5개
- 가장 가까운 데이터들 중 4개가 blue, 1개가 red
- 새로운 데이터를 생존자로 예측
- 대상 데이터에서 가장 가까운 이웃 데이터 k개를 찾음
- kNN이 머신러닝 기법에 속하는 이유
- 데이터 양이 많을수록 결과에 대한 신뢰성 향상
- 더 많은 경험을 통해 성능 향상
- 데이터 양이 많을수록 결과에 대한 신뢰성 향상
🤖 머신러닝의 수학
- 머신러닝에 수학이 필요한 이유
- 머신러닝은 컴퓨터 과학과 수학의 분야
- 상황에 맞는 알고리즘 선택과 최적화를 위해 이론 공부 필요
- 선형대수학
- 행렬
- 많은 정보를 한 번에 묶음
- 효율적 계산 가능
- 데이터를 행렬로 묶어서 사용
- 행렬
- 미적분학
- 머신러닝의 최적화에 필요
- 그래프 양상에 따른 최적의 알고리즘 파악 가능
- 통계
- 데이터에서 큰 흐름을 파악하는 데 필요
- 결과 예측에 용이
- 확률
- 가능성을 공부하는 학문
- 예:) 생존 확률이 70%이면, 확률적으로 50%를 넘으므로 생존자로 분류
* 출처: CODEIT - 데이터 사이언스 입문
There's Only One Thing To Do: Learn All We Can