
개요
https://velog.io/@tbvjvsladla/series/%EC%98%A8%EB%94%94%EB%B0%94%EC%9D%B4%EC%8A%A4LLM
필자가 온디바이스 기반의 RAG시스템을 개발하면서 정리가 되지 않았던 내용을 다시 복기 후 좀 더 전달력있게 재 포스팅을 하고자 본 시리즈를 작성합니다.
1. RAG시스템의 이해
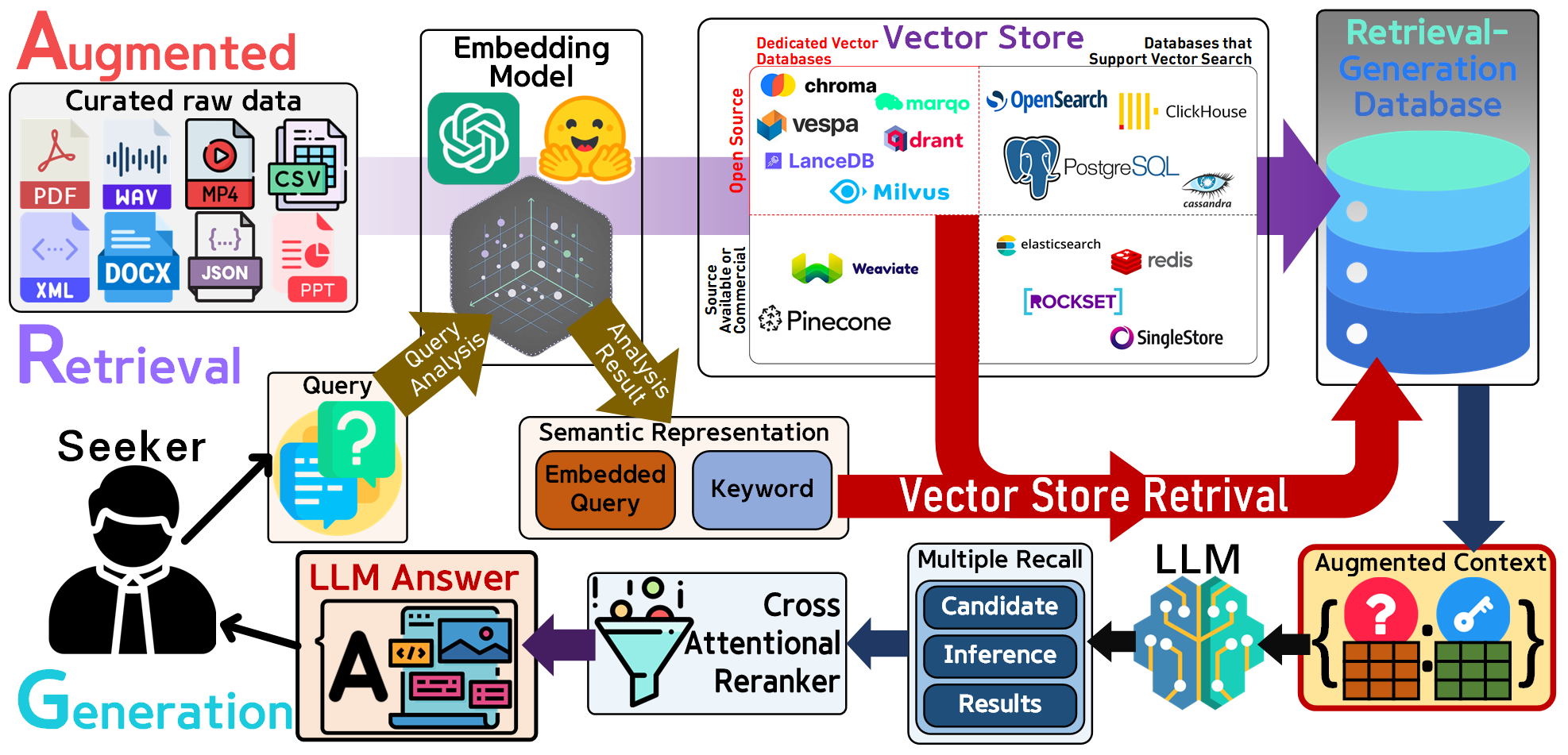
먼저 LLM(Large Language Model)의 답변 성능을 향상시키는 방안은 여러가지가 존재하지만,
현재 가장 지지를 받는 방법은 위 사진처럼 RAG(Retrival Augmented Generation) 시스템을 구축하는 것이다.
이 시스템의 workflow는 총 4단계로 동작한다.
1) Augmented 준비단계 : LLM의 답변 성능을 향상시키기 위한 가장 첫번째 단계는 원칙을 지키는 것,
여기서 필자가 생각하는 원칙은 GIGO(garbage in garbage out)이다.
즉, LLM이 좋은 답변을 이끌어 낼 수 있도록 좋은 재료 : 질문에 적합한 답변이 될 수 있는 다양한 형태의 정보를 수집하는 것이다.
이를 사진에서는 Curated raw data, 질문에 답변이 될 수 있는 정보를 수집하는 작업을 사전에 수행해야 한다.
이것은 Seeker이라 표현한 RAG 시스템을 사용하는 User의 질문은 대충 어느 특정한 분야에 해당하는 질문을 하겠구나.. 라고 어느정도는 예측이 되는 상태여야 한다.
즉, RAG 시스템기반의 Agent는 필연적으로 Domain Specific Agent가 될 수 밖에 없다.
모든 분야의 질문에 대해 좋은 답변을 만들어 낸다는 것은 모든 분야에서 선별된 정보 수집이 완료된 상태라는건데
그 어느 누구도 이런 대규모의 다양하고 방대한 데이터베이스를 운영하면서 RAG 시스템를 만들어 내기는 매우 어려울 것이다.
아무튼 질문에 적합한 답변을 내기 위한 Curated raw data를 수집했다면, 이를 Embeding model을 통해 유사도 정보를 연상해 낼 수 있는 통일된 규격의 벡터 데이터셋으로 변환하고,
이를 벡터 데이터셋을 전용으로 관리할 수 있는 DBMS(Database Management system) : Vector Store을 통해 수집한 데이터를 정제 및 관리한다.
이것이 Retrieval-Generation Database이며, 여기까지가 첫번째 단계이다.
2) Retrieval : 이제 Seeker(User)가 Query(질문)을 시스템에 입력하면 이를 Embeding model을 통하여 벡터화 작업 그리고 Retrieval-Generation Database에서 적합한 자료를 찾기 위한 Keyword을 생성해낸다. 이 Keyword를 운영중인 Retrieval-Generation Database에 입력하여 적합한 자료를 찾아내는 것,
여기까지가 Retrieval과정이다.
3) Augmented : Retrieval과정을 통해 Query(질문)에 대한 적합한 답변을 낼 수 있는 후보 자료군을 찾아냈다면, 이를 LLM에 입력하기 위하여 Query(질문)를 증강(Augmented)하는 과정을 수행한다. 말이 조금 어렵긴 한데 RAG 시스템을 구성하지 않은 상태라면 LLM에 Query만 입력하지만,
RAG 시스템은 LLM에 Query : Key쌍으로 구성된 증강된 데이터를 입력하는 것이다.
여기서 Key가 Retrieval과정을 통해 찾아낸 후보 자료들에 속하는 것이다.
이것이 사진에서는 Augmented context라 표현하고 있으며, LLM은 증강된 데이터를 입력를 입력받는 것이니 더 풍부한 답변을 하게 되는 것이다.
4) Generation : LLM이 Augmented context를 입력받아서 풍부한 정보가 담긴 답변을 만들어 냈다면 이를 후속 처리하는 과정을 말한다.
답변도 여러개를 생성한 뒤 이를 필터링 하는 Reranker, 그리고 Seeker가 습득하기 쉬운 형태로 Answer을 규격화 하는 Prompt Template를 적용한다.
2. LLM Pool
위 RAG 시스템에 대한 사전 이해를 마쳤다면 뭔가 절차는 복잡하지만 Core는 여전히 LLM이란 것을 눈치챘을 것이다.
이 LLM은 개인이 제작하는건 당연히 무리가 있고 현재 선두를 달리고 있는 AI 연구개발 회사에서 배포 및 서비스를 하는데 이를 그림으로 표현하면 아래와 같다.

크게 LLM을 연구개발하는 선도기업과 LLM을 배포/관리하는 플랫폼으로 나누어 볼 수 있으며,
LLM Research Origanization에서 신규 LLM을 출시하면 이를 Local 혹은 온라인 서비스 형태로 이용할 수 있게 배포를 진행하고, 이를 관리해 주는 플랫폼이 LLM Deploy & Manage Platform 이라 볼 수 있다.
2.1 GGUF
이제 여기서부터 필자가 이야기 하고싶은 GGUF라는 컨텐츠가 등장할 때이다.
https://github.com/ggerganov/llama.cpp

LLM Deploy & Manage Platform이 여러 기업에서 서비스를 진행하고 있고, 또 각각 LLM을 배포하는 방식과 포맷이 독자규격이라 서로간의 규격 호환이 안 맞는 부분이 존재하고 포맷 변환을 수행하는 복잡한 절차가 필요하다.
이렇게 여러개의 포맷이 있으면 모든 플랫폼에서 동작가능한 호환성이 높은 오픈소스 기반의 모델 배포 규격이 발생하는데
현재로써는 GGUF 포맷이 해당 포지션을 선점할 가능성이 가장 높다.
GGUF는 LLama.cpp의 개발자인 Georgi Gerganov의 이름을 딴 바이너리 형식의 LLM 배포 규격으로

Onnx와 같이 MS와 Meta가 공동으로 개발한 표준과 달리 한명의 개발자가 제작한 모델 배포 규격이 거의 표준처럼 받아들여지는데는 범용성&호환성이 우수하고, 손쉽게 양자화를 수행할 수 있으며, 단일 파일구조 형식을 띄고 있어 배포의 편의성을 갖는 등 여러 장점이 있기 때문이다.
포스트에서는 임의의 LLM을 GGUF 형식으로 변환하고, 다시 이 변환된 모델에 대한 양자화를 적용, 배포가 용이한 형태로 Local PC에서도 능히 구동 가능한 sLLM을 제작하는 실습을 수행하고자 한다.
3. llama.cpp
https://github.com/ggerganov/llama.cpp
지금까지의 설명을 들어보면 llama.cpp는 단순히 여러
LLM Deploy & Manage Platform에서 배포하는 독자규격의 LLM을 호환성 높은 포맷으로만 변환하는 기능을 제공하는 컨버터 정도로만 이해할 수 있으나
실제로 llama.cpp는 다양한 하드웨어(로컬 및 클라우드)에서 LLM의 추론을 수행하는 실행기 및 개발 프레임워크를 지향하고 있으며
C/C++ 기반으로 배포된 모델을 변환 실행하기에 효율성이 높고
x86, ARM, 임베디드와 같은 다양한 하드웨어에서도 LLM이 구동될 수 있도록 다양한 SIMD 명령어set을 지원한다.
또 더 빠른 추론 & 적은 RAM 사용을 위한 다양한 종류의 Quantiaztion 기능 지원과
GPU(CUDA) 및 HW 가속기 기반의 추론기능 지원 -> CPU+GPU 하이브리드 실행이 가능한 환경 구축도 가능하다.
요약을 하자면 LLM실행 및 배포를 극한까지 최적화&호환성을 보증하는 프레임워크라 볼 수 있다.
주요 기능으로는
1) llama-cli : LLM에 대한 간단한 추론
2) llama-server : 외부에서 Agent에 접속하여 추론
3) llama-perplexity : 웹서치 Agent
4) llama-bench : 구현한 Agent에 대한 벤치마크
이 존재한다.
하지만 필자가 llama.cpp를 사용해 본 결과로는
Ubuntu 환경에서 구동하는것이 안정적이고
모델 변환(*.GGUF파일 생성)과 GGUF파일에 대한
경량화(양자화)가 가장 잘 되는 것 같다.
그 외 기능은...현재 설계하고자 하는 RAG 시스템과는 맞지 않아서 사용해보지는 않았다.

Windows 환경에서 뭐 어떻게든 써보려고 했는데
이것저것 설치할것도 많고 괜히 잘못설치했다가 시스템 터질거 같아서 WSL-Ubuntu 환경에서 실습을 진행한다.
3.1 WSL-Ubuntu 사전작업
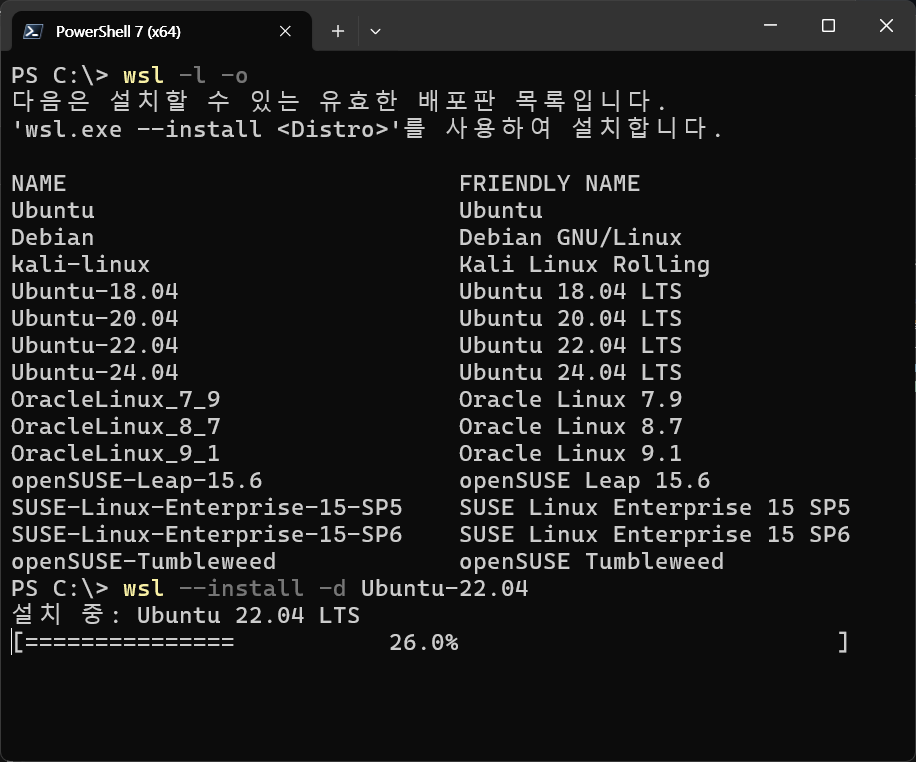
먼저 wsl을 통해서 Ubuntu를 설치해주자.
배포판은 22.04를 선택했다.
wsl --install -d Ubuntu-22.04다음으로 Nvidia 그래픽 드라이버 + CUDA Toolkit을 설치를 진행하자.
WSL-Ubuntu환경은 윈도우에 Nvidia 그래픽 드라이버가 설치되어 있으면 이것이 자동으로 연동이 되는듯 하니 그래픽 드라이버는 따로 설치를 안해도 되긴 한다.
따라서 CUDA Toolkit만 설치를 진행하면 된다
nvidia-smi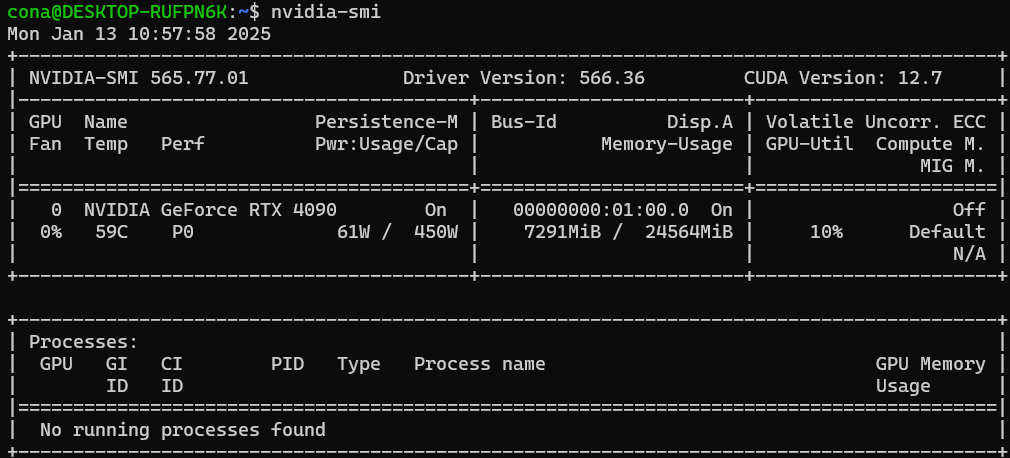
https://developer.nvidia.com/cuda-toolkit-archive

위 사진대로 선택을 수행하면 아래의 설치를 수행하기 위한 명령어 구문이 발생하니 따라치면된다.
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.4.1/local_installers/cuda-repo-wsl-ubuntu-12-4-local_12.4.1-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-12-4-local_12.4.1-1_amd64.deb
sudo cp /var/cuda-repo-wsl-ubuntu-12-4-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-4설치를 다 수행했다면 .bashrc에 설치한 cuda-Toolkit이 올바르게 환경변수에 등록되도록 작업을 진행해야 한다.
먼저 설치가 잘 되었는지 경로확인을 진행한다
ls -la /usr/local/cuda-{설치한 버전}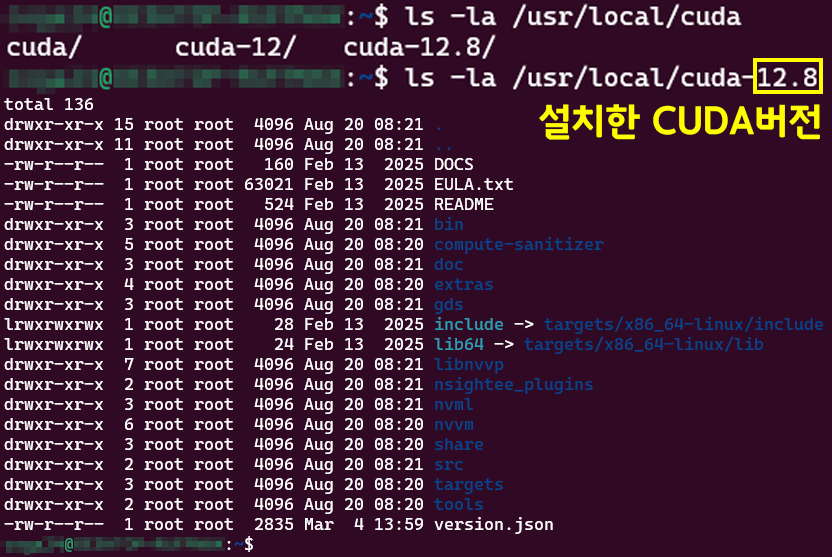
이는 .bashrc를 편집기로 열고 아래의 구문을 추가하면 된다.
예의바르게 .bashrc 편집을 위한 vscode도 설치를 진행하자.
(필자는 vim, nano를 못쓴다.)
https://learn.microsoft.com/ko-kr/windows/wsl/tutorials/wsl-vscode
sudo apt-get update
sudo apt-get install wget ca-certificates
# vscode 설치 & 실행
code .vscode를 설치한 후에는 아래에 맞춰 순차적으로 환경변수를 등록한다
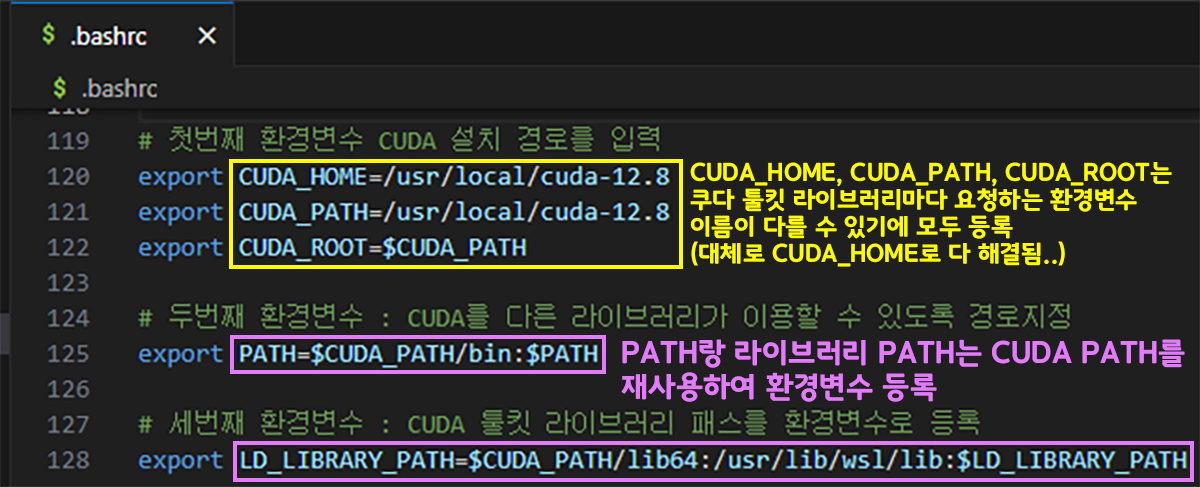
# 첫번째 환경변수 CUDA 설치 경로를 입력
export CUDA_HOME=/usr/local/cuda-{버전}
export CUDA_PATH=/usr/local/cuda-{버전}
export CUDA_ROOT=$CUDA_PATH
# 두번째 환경변수 : CUDA를 다른 라이브러리가 이용할 수 있도록 경로지정
export PATH=$CUDA_PATH/bin:$PATH
# 세번째 환경변수 : CUDA 툴킷 라이브러리 패스를 환경변수로 등록
export LD_LIBRARY_PATH=$CUDA_PATH/lib64:/usr/lib/wsl/lib:$LD_LIBRARY_PATH편집기로 .bashrc 수정을 완료한 후에는
source ~/.bashrc를 입력하여 수정한 내용을 쉘 스크립트에 적용하자
이제 cuda-toolkit 설치버전을 확인하는 명령어를 수행하면 아래와 같이 정상적으로 동작할 것이다.
nvcc --version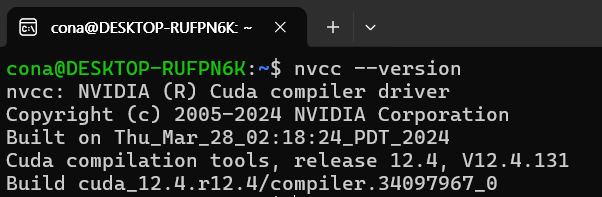
이제 예의상 Pytorch도 설치를 진행하자
https://pytorch.org/get-started/locally/
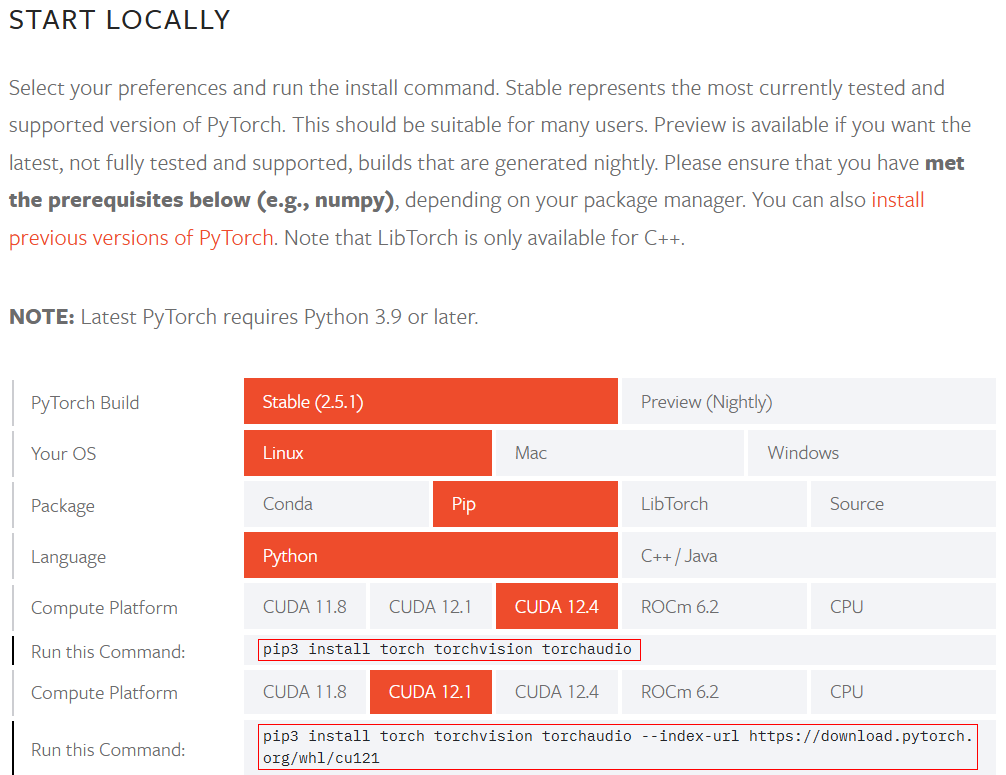
cuda toolkit버전에 따라 설치명령어가 살짝 달라지니 이를 유의하기 바란다.
# pip3 설치를 위한 사전 설치
sudo apt install python3-pip
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu1243.2 llama.cpp 빌드
https://github.com/ggerganov/llama.cpp/blob/master/docs/build.md
이제 llama.cpp를 git clone및 빌드를 진행하자.
# Cmake가 설치안되있으면 설치를 수행
sudo apt install cmake
# CURL 개발 라이브러리 설치
sudo apt install libcurl4-openssl-dev
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp이 다음에 빌드를 진행해야 하는데 CUDA설치 및 설정을 완료했으니 아래의 명령어로 Cmake빌드를 진행하자
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release
빌드에 꽤 많은 시간이 소요되니까 여유를 갖자.
빌드를 완료한 뒤에는 llama.cpp가 요구하는 나머지 의존성 패키지를 설치하자
cd ~/llama.cpp/requirements
pip install -r requirements-all.txtllama.cpp 에는 requirements라는 폴더가 존재하는데 해당 폴더 내에는 사용하고자 하는 llama.cpp의 기능별로 의존성 패키지 리스트가 기술되어 있다.
근데 속편하게 requirements-all.txt에 기술되어 있는 모든 패키지 설치가 가장 편하다.
4. 모델 변환 실습
llama.cpp 빌드를 완료했으니 모델 변환을 수행해보자

모델 변환은 Hugging Face에서 제공하는 모델 규격을
llama.cpp의 convert_hf_to_gguf.py코드를 활용하여
*.gguf파일로 변환하는 실습이다.
실습 대상 파일은
https://huggingface.co/microsoft/phi-4

허깅페이스에 업로드 되어 있는 Microsoft의 LLM : Phi-4 모델에 대한 변환이다.
먼저 해당 모델은 총 용량이 50GB는 넘어가는 LLM이기에
git-lfs를 사전에 설치해야 한다
sudo apt install git-lfs
git lfs install설치를 완료한 후 버전확인을 잊지말자
git lfs --version
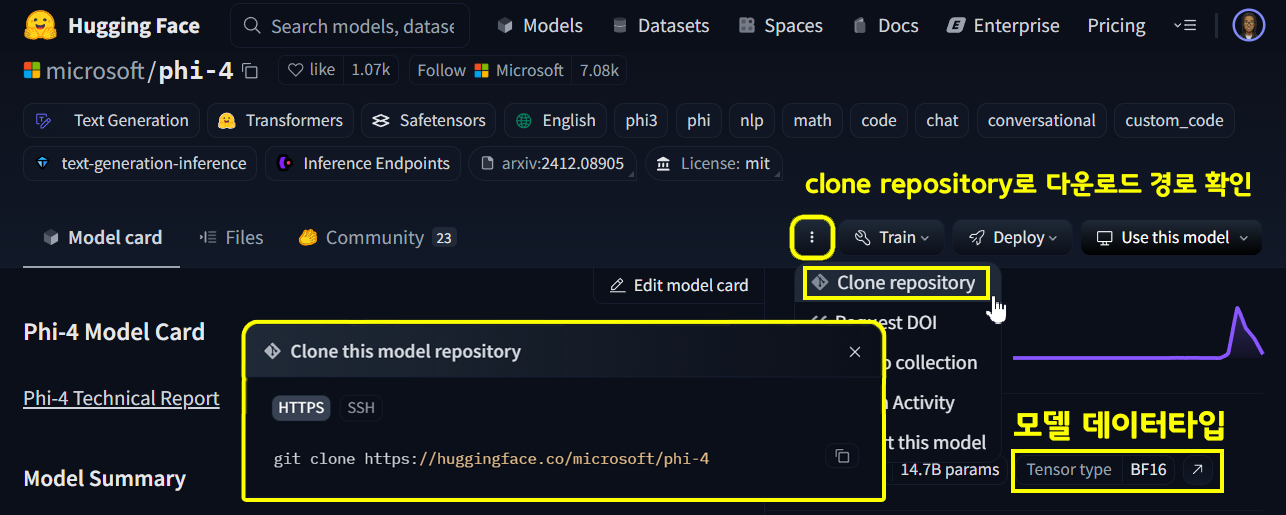
git clone https://huggingface.co/microsoft/phi-4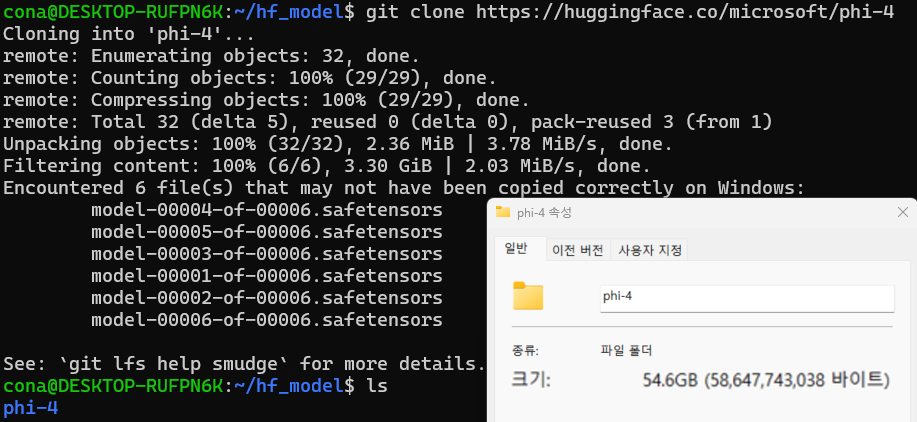
원본 모델의 용량은 약 54.6GB
폴더 내부에 파일도 여러개가 혼재되어 있다.
이를 *.gguf파일 형식으로 변환해보자
참고로

python3 --version이 명령어를 수행하면 현재 설치되어 있는 Python version이 출력되는데 WSL-Ubuntu 22.04는 기본 Python이 3.10.12가 설치되어 있다.
이제 본격적으로 convert_hf_to_gguf.py로 모델변환을 하면 되는데 명령어는 아래와 같다.
python3 convert_hf_to_gguf.py \
[변경하고자 하는 모델의 경로] \
--outfile [gguf 형식으로 변경한 모델을 저장할 경로] \
--outtype [변경 데이터 타입 -> Default : auto]
# 한줄 복사 코드 -> gguf_model, hf_model 폴더가 사전에 있어야함
python3 convert_hf_to_gguf.py \
~/hf_model/phi-4/ \
--outfile ~/gguf_model/phi-4.gguf \
--outtype auto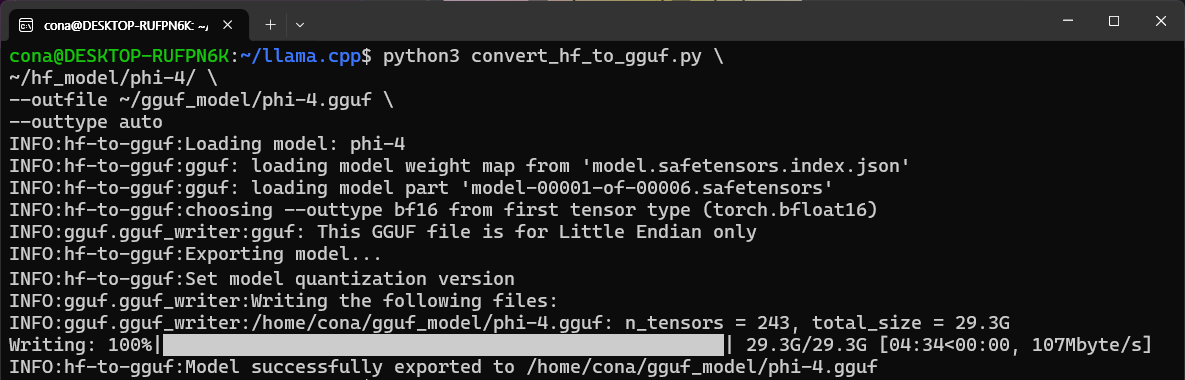
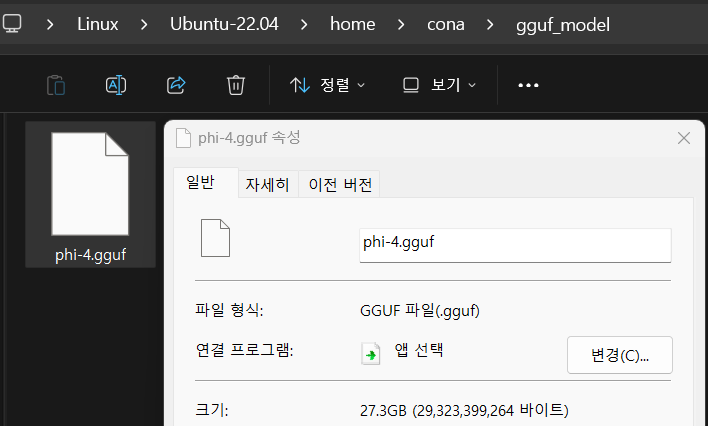
모델변환을 완료하면 용량이 54.6GB에서 27.3GB으로 줄어드는데 이것은 convert_hf_to_gguf.py이 자체 변환시에 살짝 양자화를 적용해서 변환하기 때문이다.
원본 그대로의 성능으로 변환하려면 Phi-4의 초기 배포 데이터 타입인 bf16을 적용하면 된다.
python3 convert_hf_to_gguf.py \
~/hf_model/phi-4/ \
--outfile ~/gguf_model/phi-4.gguf \
--outtype bf16참고로 --outtype에 적용가능한 데이터 타입은
{f32, f16, bf16, q8_0, tq1_0, tq2_0, auto} 이다.
5. 양자화 변환 실습
다음으로 변환을 완료한 *.gguf모델을 Quantize를 적용하여 모델을 경량화 해보자
여기서 사용되는 llama-quantize 스크립트 파일은
~/llama.cpp/build/bin/ 경로에 있기에 아래의 경로로 이동 후 명령을 수행한다.
# 경로 이동
cd ~/llama.cpp/build/bin/
./llama-quantize여기까지만 수행하면 llama-quantize 스크립트의 사용법을 알아볼 수 있는데 아래의 사진처럼 다양한 방식의 quantize를 적용할 수 있다.
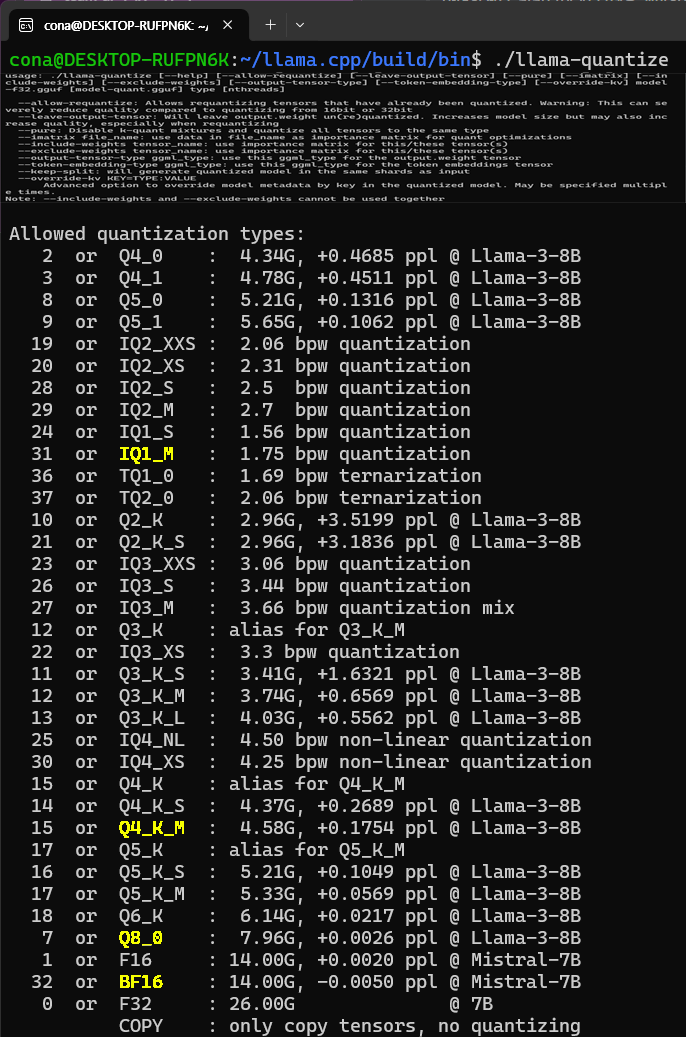
여기서 주로 사용하는 Quantize옵션은
BF16, Q8_0, Q4_K_M, IQ1_M등이 주로 사용되는 듯 하다.
필자는 Q4_K_M를 적용하여 양자화를 수행하고자 하며 이 명령어는 아래와 같다.
./llama-quantize [원본 gguf 모델 경로] \
[양자화 적용 모델(gguf) 저장 경로] [양자화 타입]
# 한줄 복사 코드
./llama-quantize ~/gguf_model/phi-4.gguf \
~/gguf_model/phi-4_Q4_K_M.gguf Q4_K_M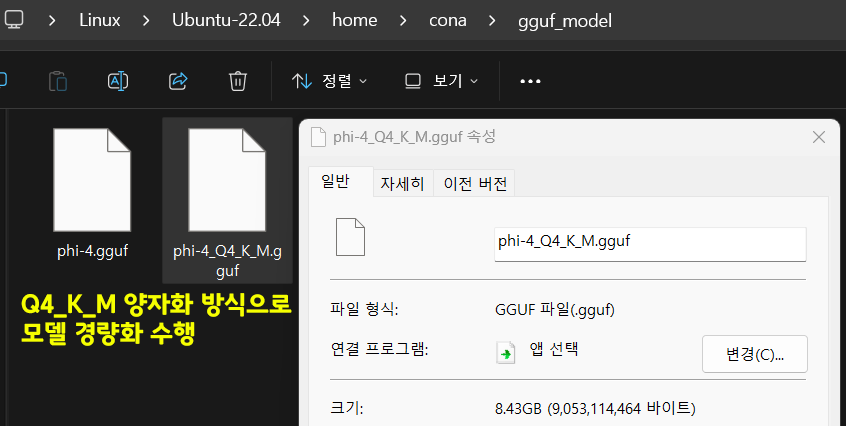
이렇게 경량화를 적용하여 최종 8.4GB으로 용량이 감소된것을 확인할 수 있다.
6. Ollama에 삽입하기
sudo apt update
sudo apt install curl -y
curl -fsSL https://ollama.com/install.sh | sh위 명령어를 수행하여 ollama를 설치하자

설치한 후에는 아까 최종적으로 경량화한 모델
phi-4_Q4_K_M.gguf를 ollama에 등록을 수행해야 하는데 이 때 Modelfile을 만들어주어야 한다.
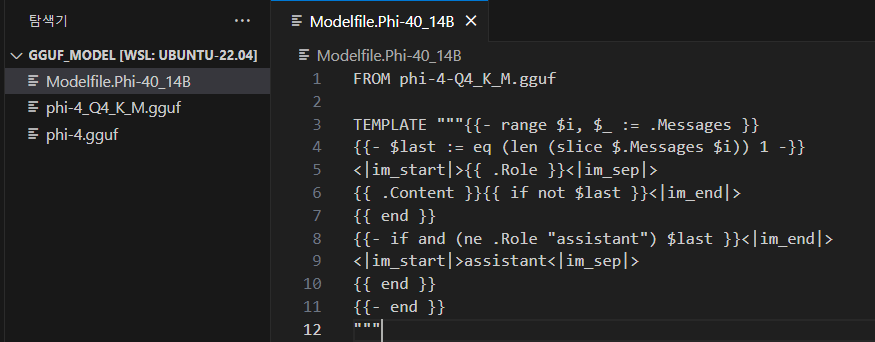
이 Modelfile는
https://ollama.com/library/phi4/blobs/32695b892af8
ollama에 업로드 되어 있는 phi4의 template 파일을 참조하여 작성한 것으로
ollama는 go언어 기반으로 동작하는
LLM Deploy & Manage Platform이기에 template에
ollama에 등록하고 싶은 LLM은 이 template 정보가 포함된 Modelfile이 필요하다.
FROM phi-4-Q4_K_M.gguf
TEMPLATE """{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1 -}}
<|im_start|>{{ .Role }}<|im_sep|>
{{ .Content }}{{ if not $last }}<|im_end|>
{{ end }}
{{- if and (ne .Role "assistant") $last }}<|im_end|>
<|im_start|>assistant<|im_sep|>
{{ end }}
{{- end }}
"""코드 전체는 위와 같으며, template 항목을 분석해보면 LLM이 어떻게 기동해야 하는지에 대한 간단한 내용만 포함된 것이니 빡세게 분석해가면서 사용할 필요는 없다.
아무튼 위와 같이
Modelfile.Phi-40_14B
phi-4_Q4_K_M.gguf
2개의 파일이 준비가 되었으니 이를 ollama에 등록해보자
# Modelfile이 있는 경로로 이동
cd ~/gguf_model
ollama create [등록할 모델 이름] \
-f [Modelfile경로]
# 한줄 복사 코드
ollama create Phi-4:14B-GGUF \
-f ~/gguf_model/Modelfile.Phi-40_14B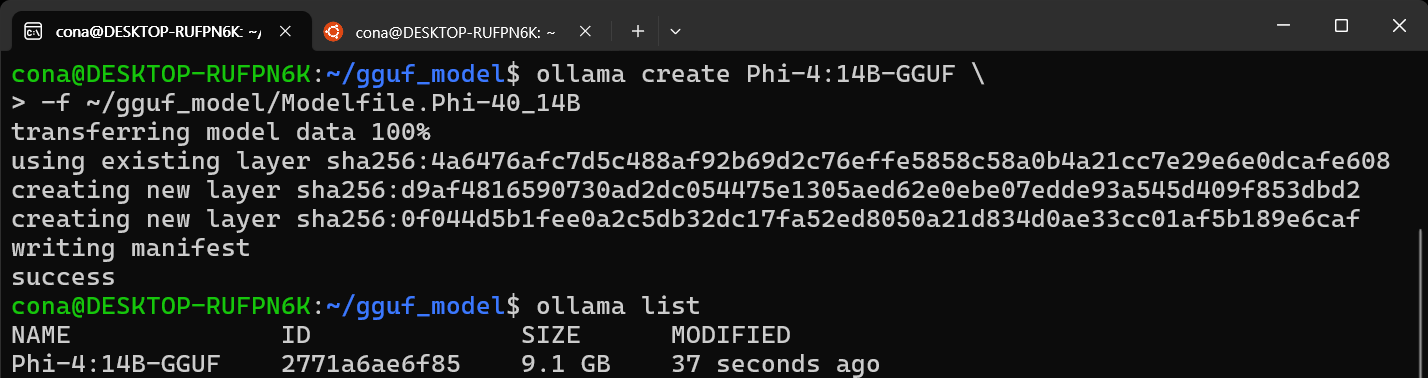
ollama create로 모델 등록이 완료되었으면
검증을 수행하자
ollama list모델이 동작하는지 실행은 ollama을 통해서 해도 되긴하는데 필자는 뭔 에러가 나서
LM Studio로 실행한 화면을 첨부하도록 하겠다.
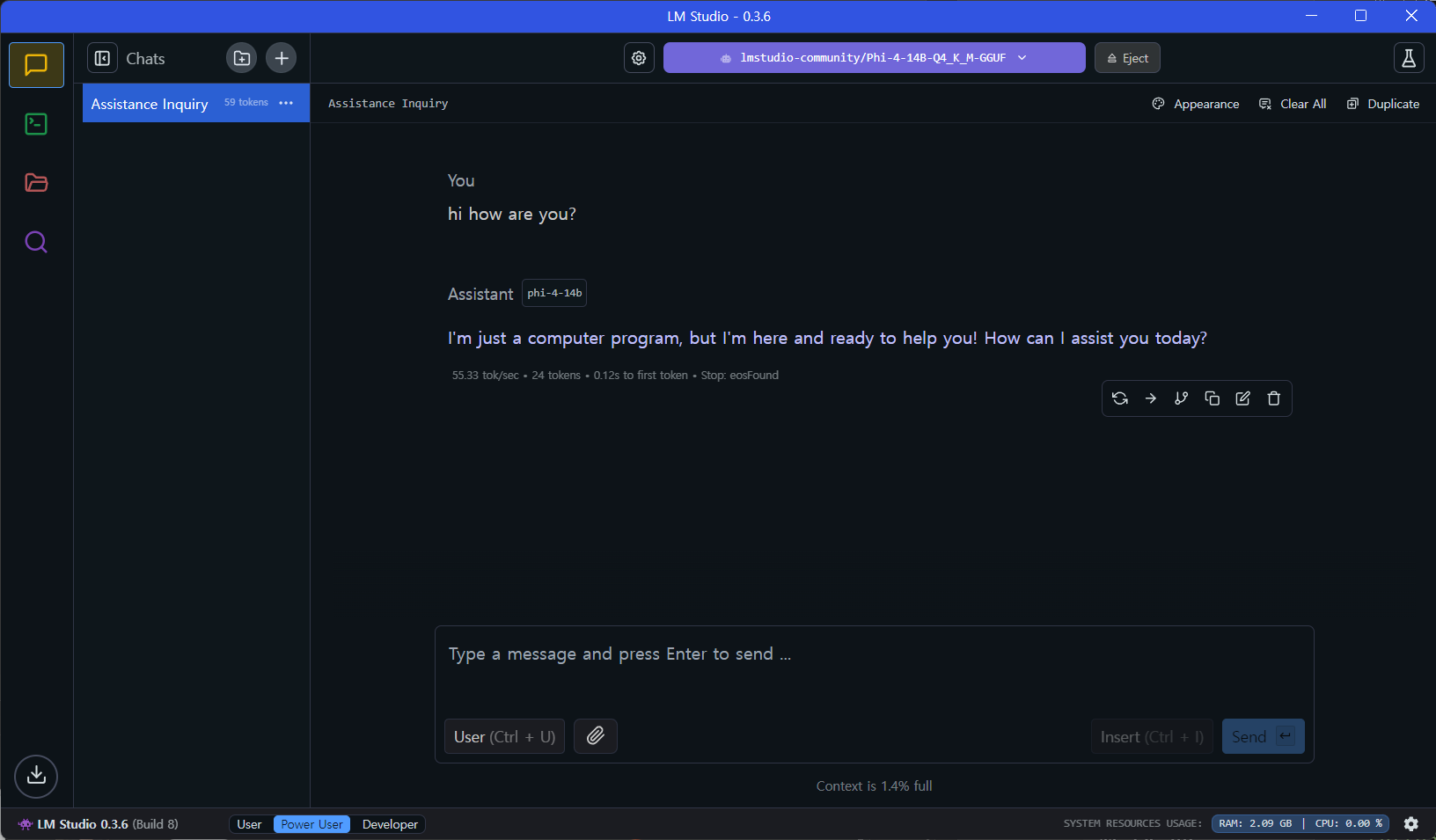
LM studio는 별도의 Modelfile를 생성하지 않고 *.GGUF파일만 있어도 간단하게 등록된다.
이는 LLM Deploy & Manage Platform마다 등록과정에 차이가 있으니 사용하고자 하는 Tool의 요구사항을 사전에 확인해야 한다.
마지막으로 위 과정을 통해 수행한 커스텀 모델 : phi-4_Q4_K_M 모델의 경우 ollama에 등록은 가능하나
25.01.14일 기준 최신버전인 0.55버전에서 기동해야
올바르게 실행됨을 확인했다.
(구버전인 0.54에서는 실행이 안됨)
왜 안되는지는 모르겠지만.. 아무튼 버전별로 안정성 차이도 있으니 이를 유념하자..
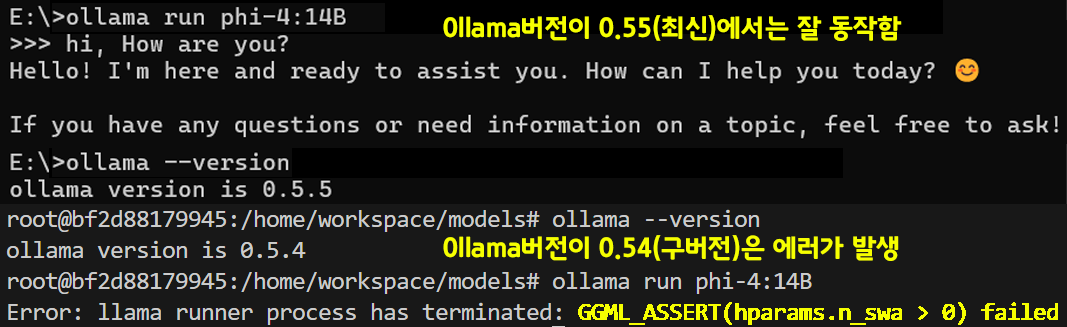
(구버전의 경우 GGML_ASSERT(hparams.n_swa > 0) 에러 발생)
