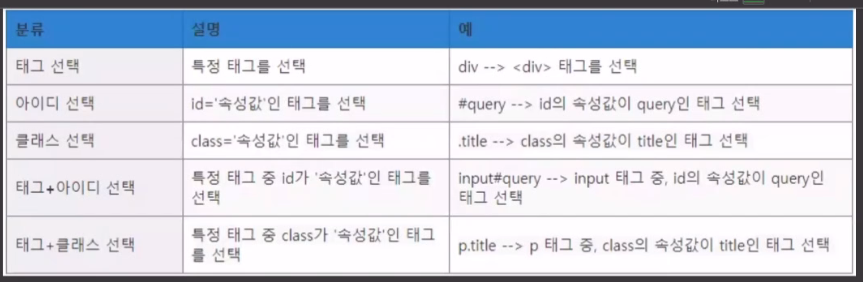
1. 웹페이지 크롤링
웹페이지 크롤링에는 위 라이브러리를 사용한다.
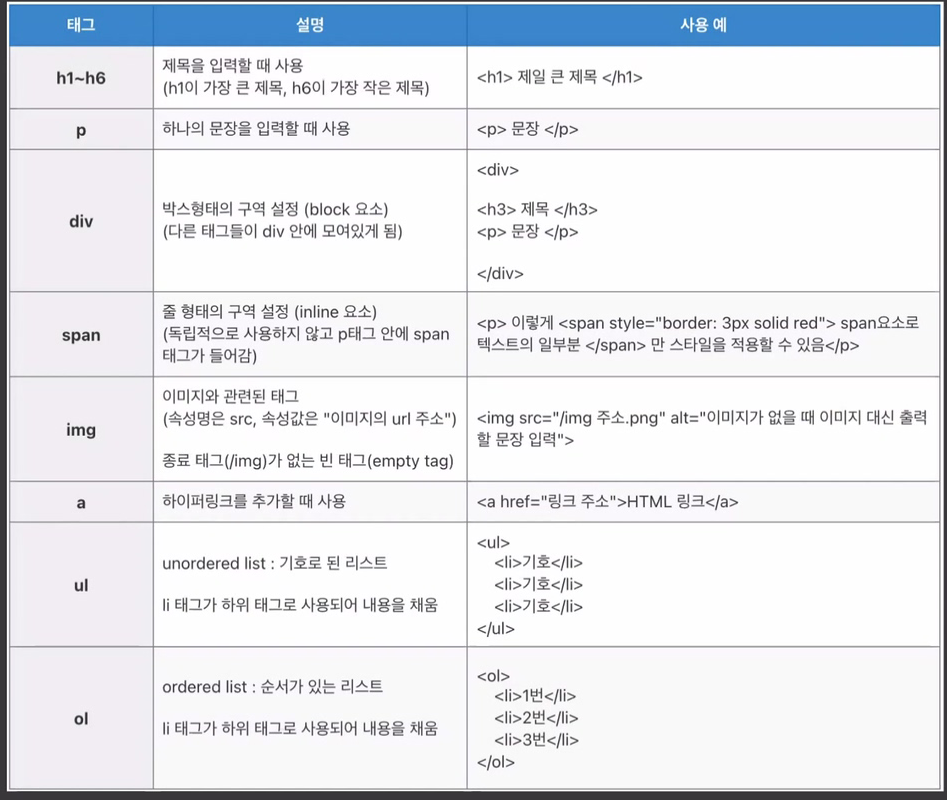
위 html 규격으로 작성된 웹 페이지를 파싱해주는 라이브러리라 보면 된다.
참고로 해당 매서드로 css 규격의 웹 페이지 또한 파싱하는 것이 가능하다
웹페이지 크롤링의 실습은
홈페이지를 바탕으로 수행하고자 한다.
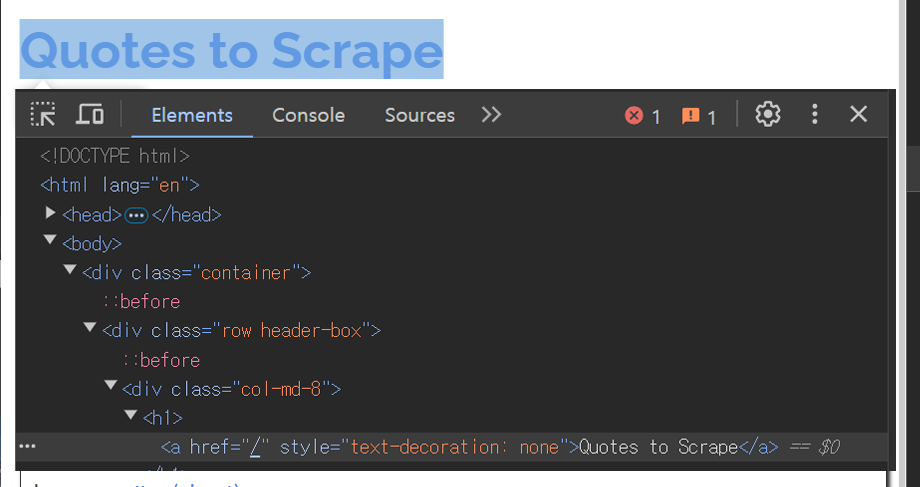
먼저 웹 브라우저를 열고 F12를 클릭하면 해당 웹페이지의 html혹은 cssformat로 작성된 페이지 코드를 확인할 수 있다.
이를 커서로 클릭을 하면 해당 코드가 웹페이지에서 어느 부분에 위치하고 있는지를 확인할 수 있는데 위 사진처럼 항목을 찾다보면 '제목'부분에 해당하는 코드가 어떤 카테코리 코드 안에 있는지 알 수 있다.
import requestsdef get_req_page(url):
try:
# URL에 GET 요청 보내기
response = requests.get(url)
# 요청이 성공했는지 확인
if response.status_code == 200:
# 페이지의 내용을 텍스트로 반환
return response.text
else:
return f"페이지 가져오기 실패: {response.status_code}"
except Exception as e:
return f"오류발생: {str(e)}"url = 'https://quotes.toscrape.com/'
quote = get_req_page(url)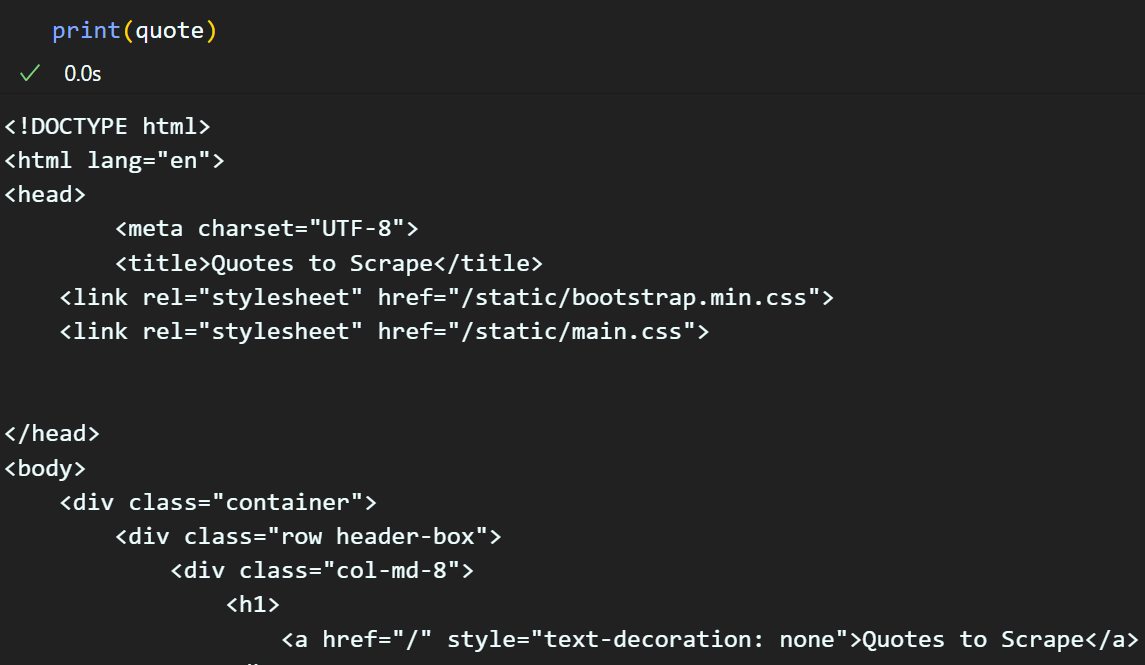
크롤링한 결과물을 확인한다면 웹 브라우저에서 F12를 눌렀을 때와 동일한 코드구문이 크롤링 된것을 확인할 수 잇다.
이제 BeautifulSoup를 통해 데이터 파싱을 수행하자.
from bs4 import BeautifulSoupquote_html = BeautifulSoup(quote, features='html.parser')위 코드를 수행하면 변수 'quote_html'에는 파서 규칙에 따라 메타정보를 제거한 content 항목만 온전히 추출해 낼 수 있다.
이것이 무슨뜻이냐면
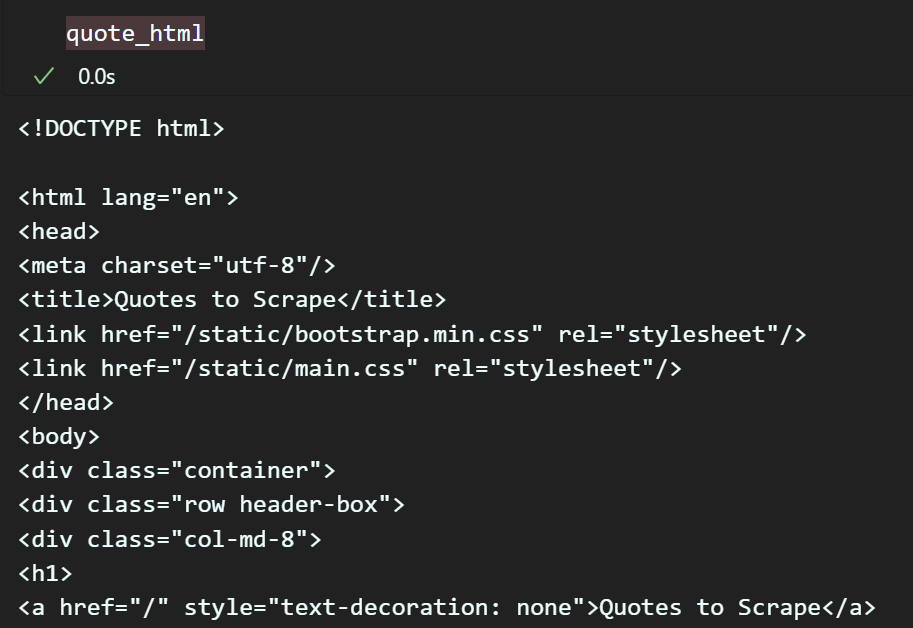
파싱된 항목을 print한다면 뭐 딱히 수행된 것같지 않은 느낌이지만

위 사진처럼 quote_html에 파싱된 항목중
<head> ~~~ </head> 태그 내부 컨텐츠만을 추출 및 인덱싱 하는것이 가능해진다.
# 파싱한 quote_html에서 <div>태그 중
# class="quote"속성인 요소를 찾아서 리스트로 저장
quote_div = quote_html.find_all('div', class_='quote')
print(quote_div[0])# 다음으로 파싱한 quote_div 중 <span>태그에서
# 속성정보가 text인 항목만 추출
quote_span = quote_div[0].find_all('span', class_='text')
print(quote_span[0].text)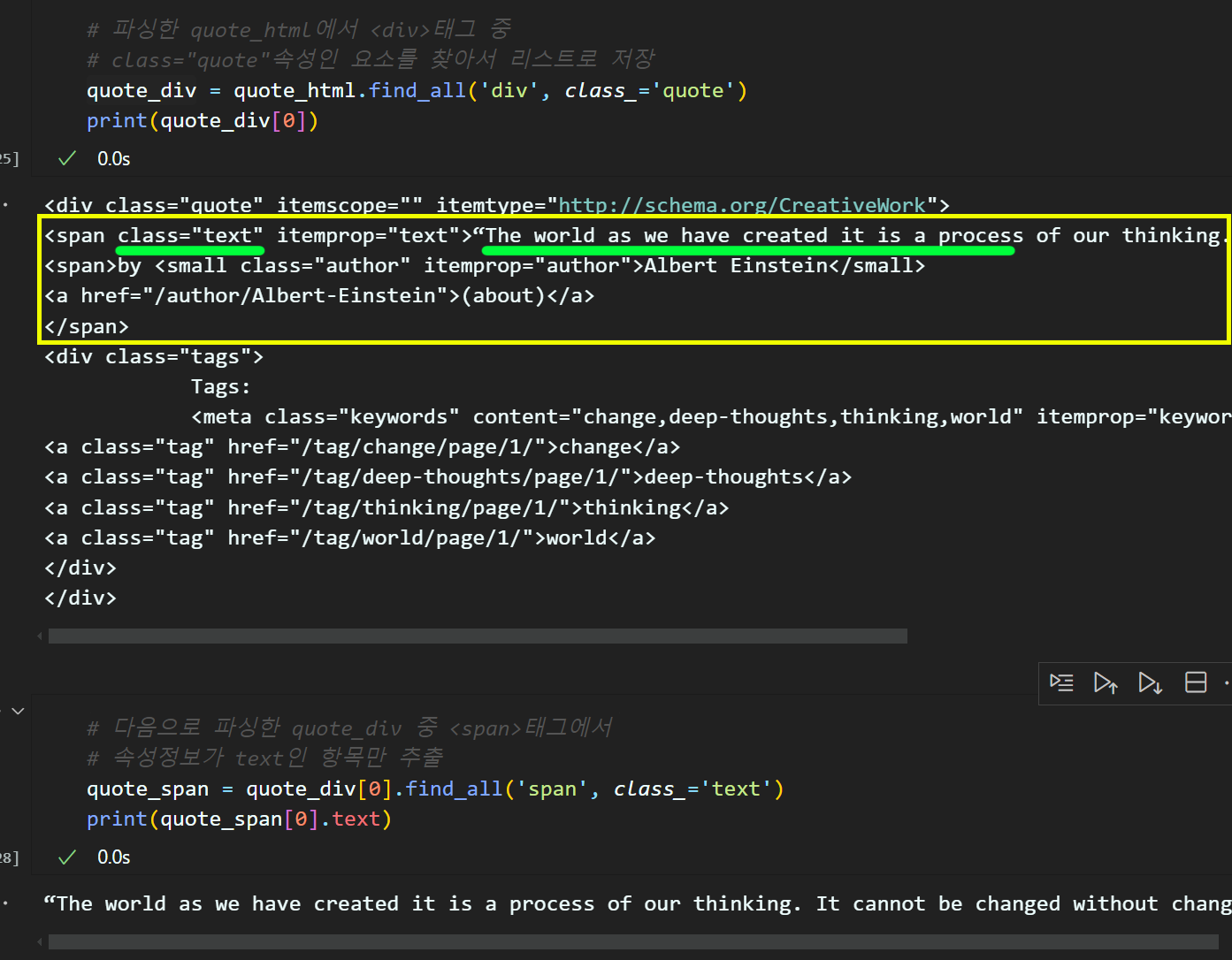
위 두개의 구문을 수행하면
특정태그 -> 태그내 특정 속성으로 분류된
컨텐츠 항목을 추출하는것이 가능하다.
예제로 위 홈페이지에서 명언 부분에 해당하는 컨텐츠만 크롤링을 한다면 아래의 코드로 수행할 수 있다.

# select 함수를 통해 <div> 태그 중 class="quote" 속성을 갖는 요소 추출
# 그 다음 '>' 연산자로 그 아래의 자식 요소를 서치
# 이때 상위 조건을 만족하는 직속 자식 항목 중 <span>태그, class='text'속성
# 정보를 갖는 항목만 추출
quote_text = quote_html.select('div.quote > span.text')
quote_wise = [i.text for i in quote_text]
for i in quote_wise:
print(i)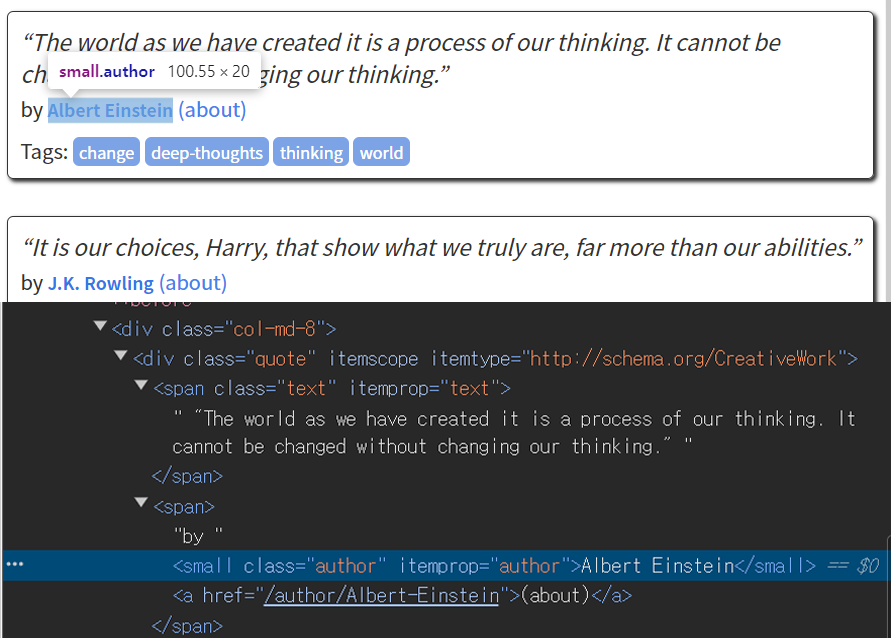
추가 실습으로 'author' 항목을 추출하려면 아래의 코드로 추출하는것이 가능하다
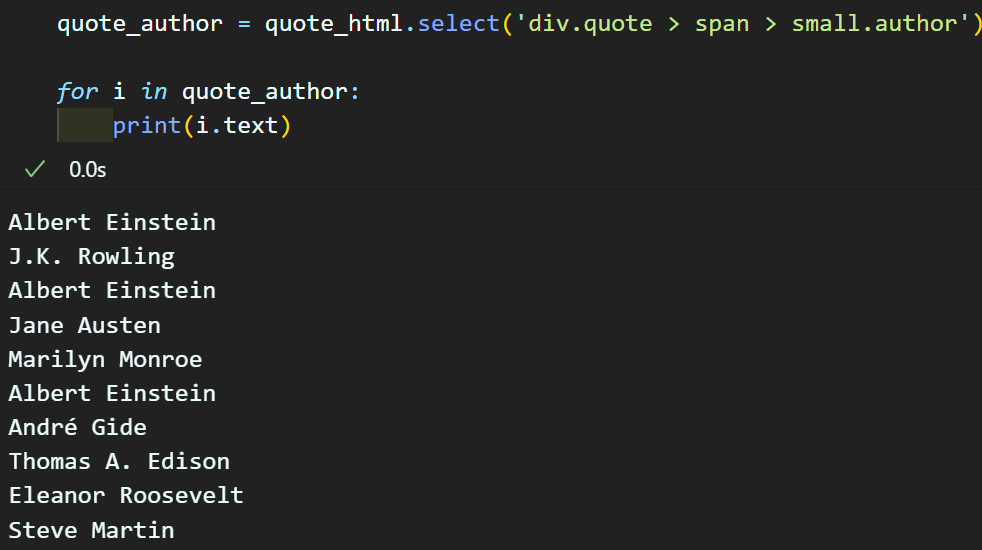
이렇게 request 라이브러리로 크롤링 하고자 하는 웹페이지를 크롤링 한 raw_text 정보를 바탕으로
BeautifulSoup 라이브러리로 파싱을 수행한 뒤
find, select함수를 통해 추출하고자 하는 주요 컨텐츠 항목을 추출할 수 있다.
마지막으로 추출한 정보는
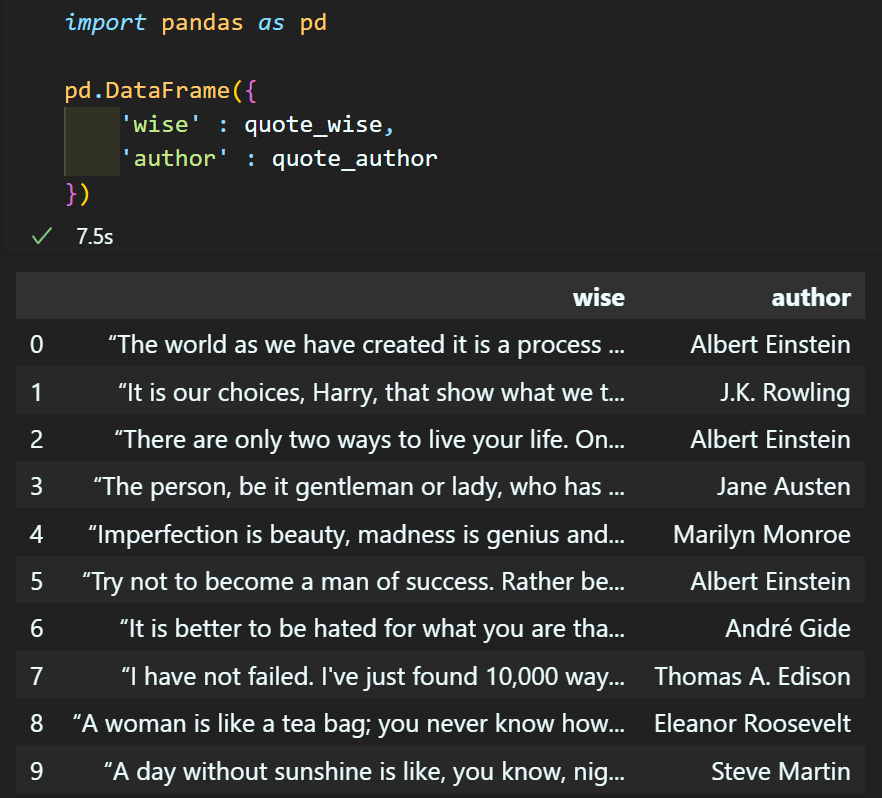
pandas라이브러리를 통해 데이터베이스로 정리를 수행하자
2. Numpy
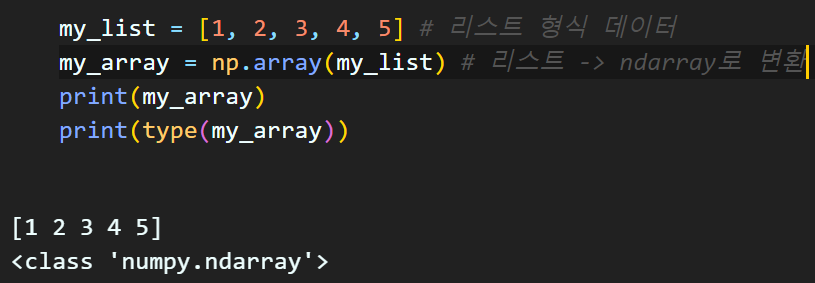
np.array : 입력데이터(리스트, 리스트의 튜플, 다른 배열 형식을 갖는 데이터타입)을 ndarray 자료형으로 변환하는 메서드
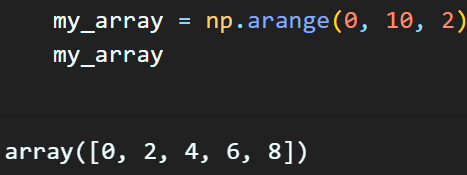
np.arange : 특정 구간에서 일정한 값의 간격으로 구성된 배열을 생성
입력 인자값 : start, stop, step
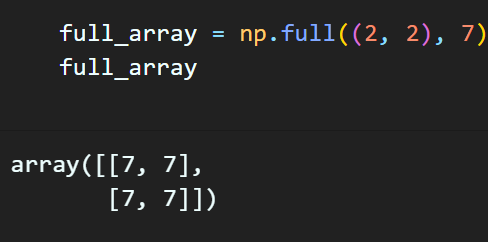
임의 배열을 생성하는 방법
np.zeros : 모든 원소가 0인 배열 생성
np.ones : 모든 원소가 1인 배열
np.empty : 모든 원소가 쓰레기값인 배열 생성
np.full : 모든 원소가 특정 값으로 채워진 배열 생성
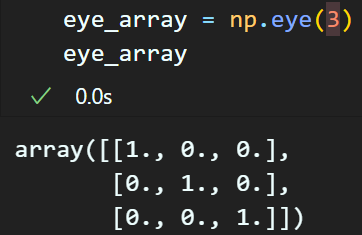
np.eye() : 정사각형의 단위행렬(Identity matrix) 생성
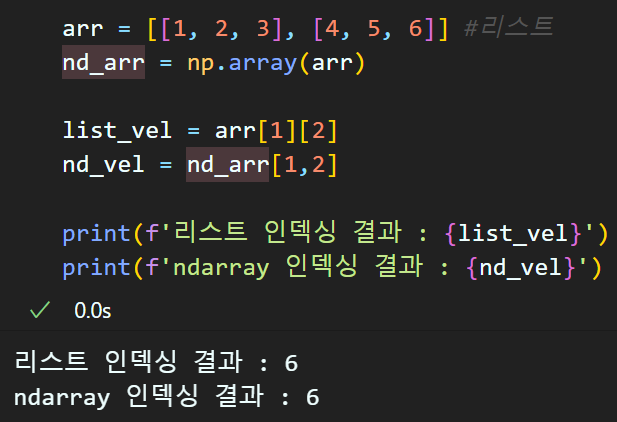
인덱싱 및 슬라이싱
ndarray 형식의 데이터 타입은 리스트 인덱싱 및 슬라이싱과 거의 유사하게 동작하기에 스킵하며
차이가 나는 부분만 정리한다
1) 다차원 인덱싱
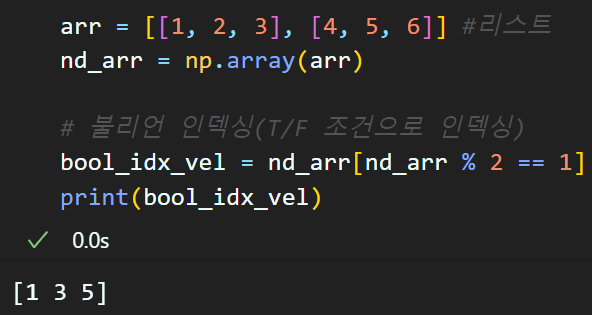
2) Boolean 인덱싱 (T/F로 인덱싱)
브로드 캐스팅은 넘어간다
numpy의 집계함수
np.sum : 모든 원소 요소 합
np.min, np.max : 모든 원소 중 가장 작은 값(value)를 리턴
np.mean : 평균, np.median : 중앙값
np.std : 표준편차, np.var : 분산
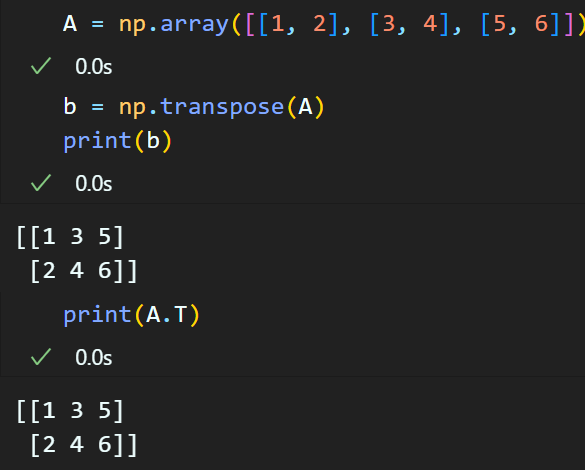
np.transpose 전치행렬 : 사용방법은 아래 2가지이다
np.sort : 배열을 오름차순/내림차순으로 정렬
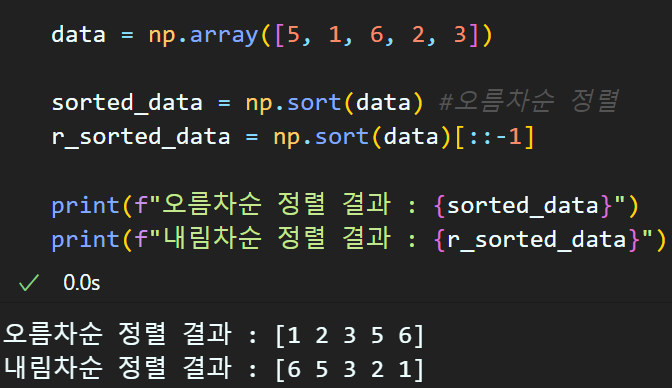
np.argsort : 정렬을 수행하게 되면
각 원소의 위치가 변경되는데
어떻게 변경되는지를 알려주는 함수
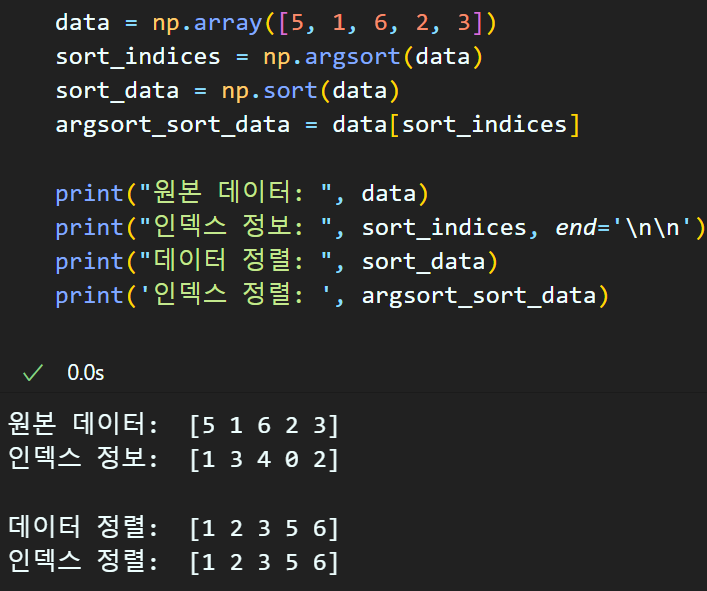
위와 같이 data[np.argsort(data)] 연산으로 정렬결과값
np.sort(data)와 같은 값이 출력된다.
np.where : 특정 조건을 만족하는 요소(value)의 위치(index)를 반환함

난수생성 : 총 4가지가 있음
np.random.rand() : 0~1사이의 균일분포 난수
np.random.randn() : 표준 정규분포(평균 0, 표준편차 1)을 따르는 난수 생성
np.random.randint() : 시작, 끝 두개의 인자값을 받으면 그 사이에 포함되는 난수값을 생성
np.random.random() : 0~1 사이의 균이분포를 따르는 난수를 생성하는데 생성할 때마다 다른값이 생성되게 함
-> 주로 다차원 배열 내 요소를 무작위값으로 채울 때 사용
랜덤 샘플링
np.random.choice() : 입력된 배열 내 임의 요소 선택
np.random.shuffle() : 입력된 배열을 무작위로 섞음
-> 만약 원본 배열을 유지하고 싶다면
np.random.permutation() (순서를 염두한 경우의 수 : 순열을 반환)
3. Pandas
pandas는 dataframe, series 객체 타입으로 데이터 베이스 자료를 핸들링 하는것이 가능하며,
통상적으로 *.csv, *.text, *.xlsx 등의 확장자로 저장된 raw 데이터베이스 파일을 불러와서 사용하는게 일반적이다.
파일은 https://drive.google.com/file/d/1B0DgueZ6OBIaGCS7RRk9yzOf0H6Gnuml/view?usp=drive_link
에 업로드한 'seoul_park.csv'파일로 실습을 진행하겠다.
import numpy as np
import pandas as pd# 실습 파일 경로
csv_path = './Numpy_pandas/data/seoul_park.csv'
df = pd.read_csv(csv_path)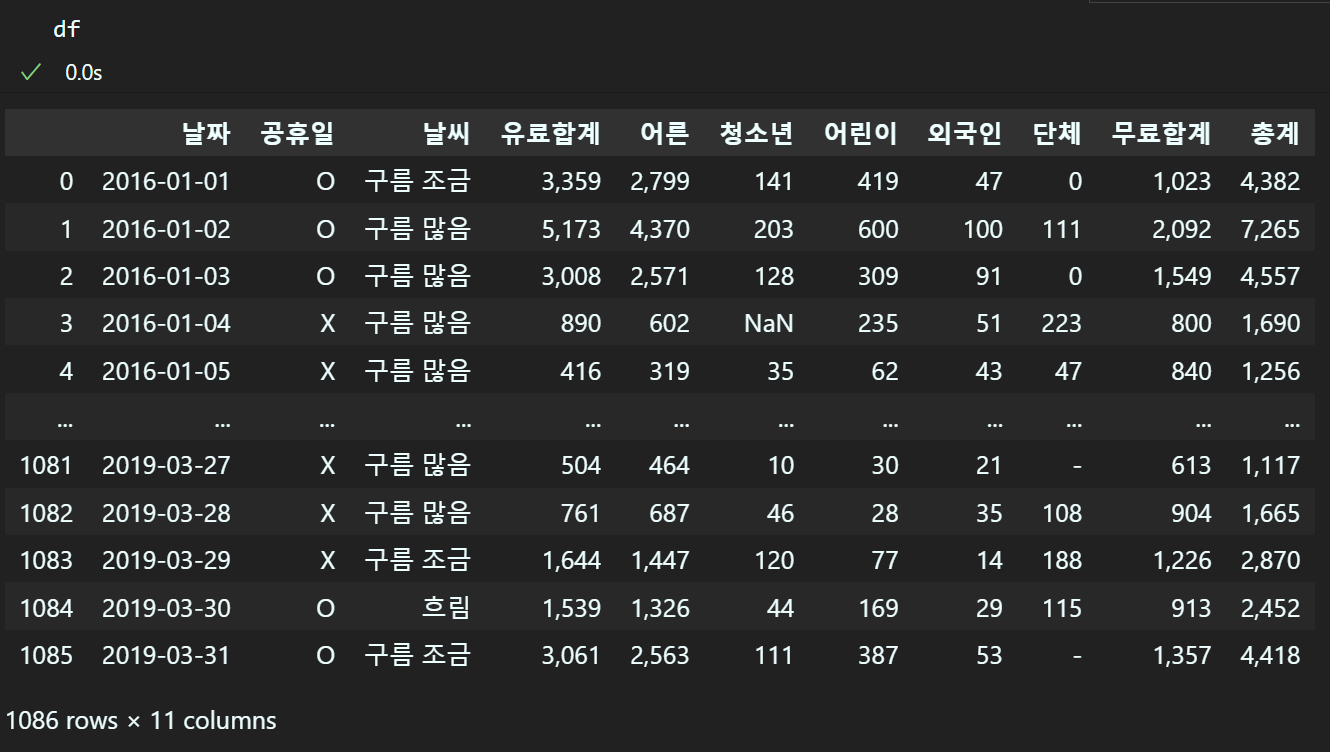
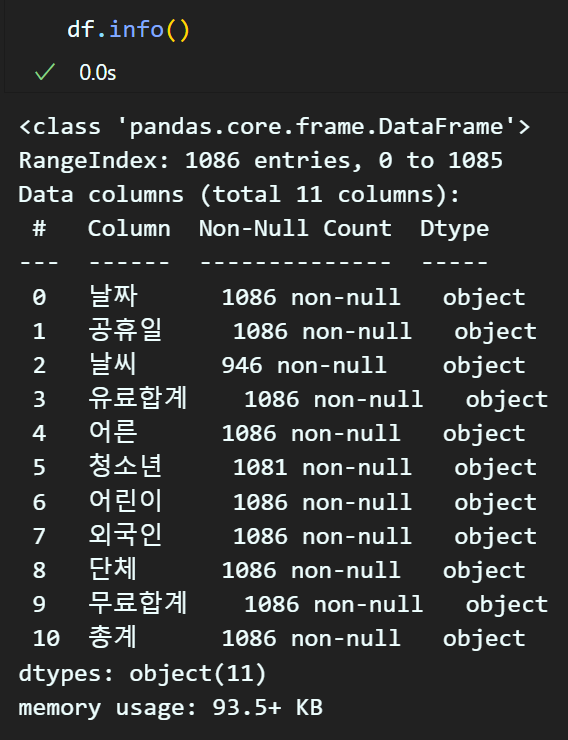
해당 파일의 정보를 확인하려면
df, df.info 메서드로 확인이 가능하다.
추가로 https://drive.google.com/file/d/1LQlGIAe0dxkXIWPQpyahRm7XCVpIreLd/view?usp=drive_link
'misemunji.csv'
파일도 불러온다
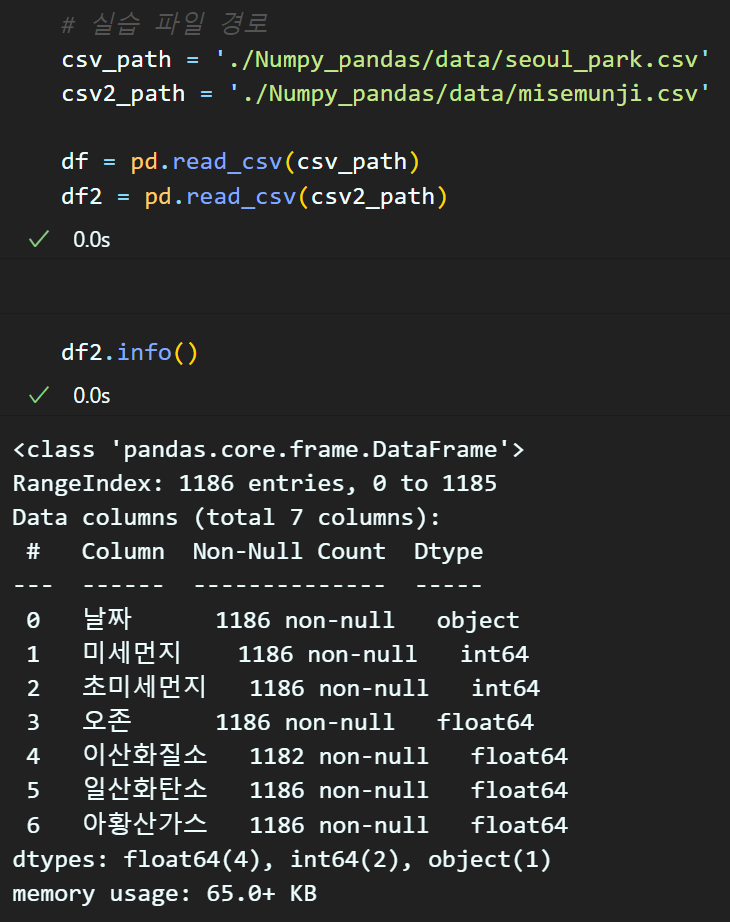
df['컬럼명'].value_count() : 특정 컬럼에 값이 몇개 존재하는지 확인하는 메서드
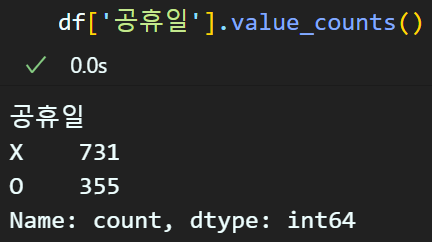
이때 해당 메서드는 '컬럼'을 별도로 지정해주는 것이 좋다
안그러면 위 처럼 알아보기 난해하게 출력됨..
pd.set_option() : 현재 사용중인 IDE의 Pandas 기본 출력 옵션을 조정하는 함수이다.
pd.set_option('display.max_rows', 100) : 기본 60개 행 출력 옵션에서 100개로 증가
pd.set_option('display.max_columns', 10) : 기본 20개 열 출력에서 10개로 감소
pd.set_option('display.width', 100) : 기본 출력너비 80에서 100으로 증가
pd.set_option('display.float_format', '{:.2f}'.format) : 부동소수점 출력을 소수점 2째자리까지
pd.set_option('display.max_colwidth', 100) : 한 열의 최대 너비가 50인 것을 100개의 문자열 출력이 가능하게 변경
pd.set_option('display.precision', 3): 부동소수점 최대 출력 정밀도를 6째 자리(기본)에서 3자리로 줄임
pd.set_option('display.show_dimensions', True) : 마지막에 데이터프레임의 행, 열 개수 출력하는 info부분을 출력하게 변경(기본 False)
display(df) : 출력 형식을 print메서드보다 더 가독성 높게 출력
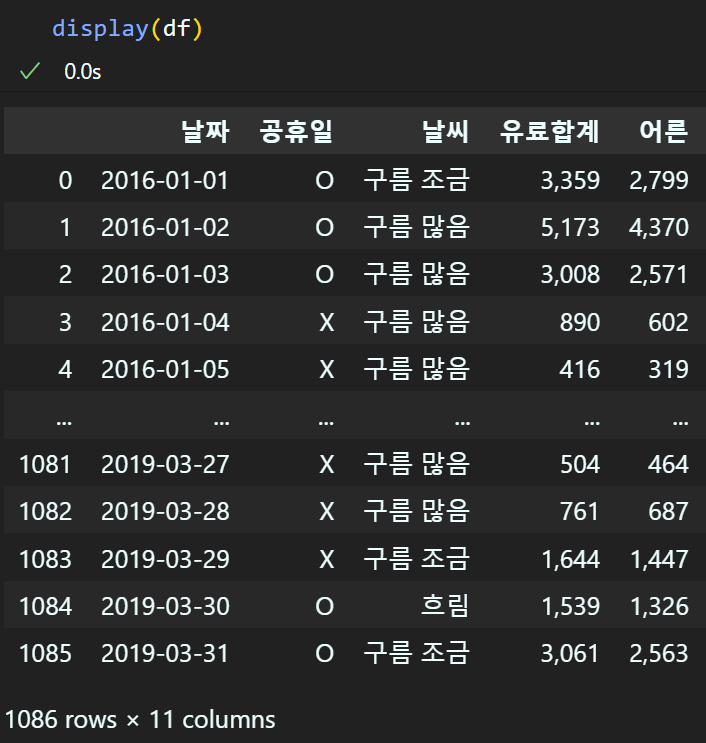
ipynb의 기본 df의 출력형식이 'display()'메서드를 적용한 출력형식임을 알 수 있다.
데이터 클리닝
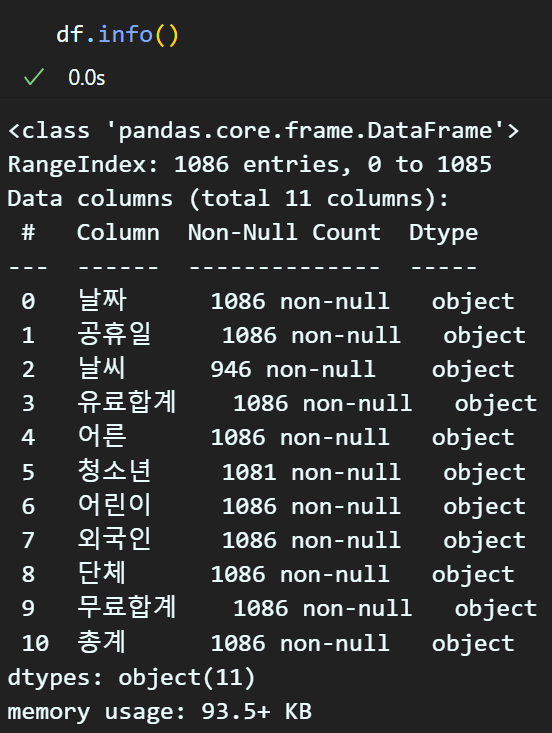
현제 데이터 항목이 모두 object 타입(문자열) 데이터 타입이기에 정수 데이터셋도 문자열이 아니라 int나 float로 변환하는 작업을 수행한다.
# 데이터 클리닝을 수행할 컬럼 리스트 항목 추출
col_list = df.columns.tolist()
print(col_list)def remove_element(list, idx_list):
for idx in sorted(idx_list, reverse=True):
list.pop(idx)
return list# 클리닝을 적용할 컬럼만 남기기
cel_col_list = remove_element(col_list, [0, 1, 2])
print(cel_col_list)['유료합계', '어른', '청소년', '어린이', '외국인', '단체', '무료합계', '총계']for i in cel_col_list:
# 하이픈 처리된 값은 '0'이란 문자열로 변환
df[i] = df[i].str.replace('-', '0')
# 3자리 단위로 끊는 ',' 문자열은 제거
df[i] = df[i].str.replace(',', '')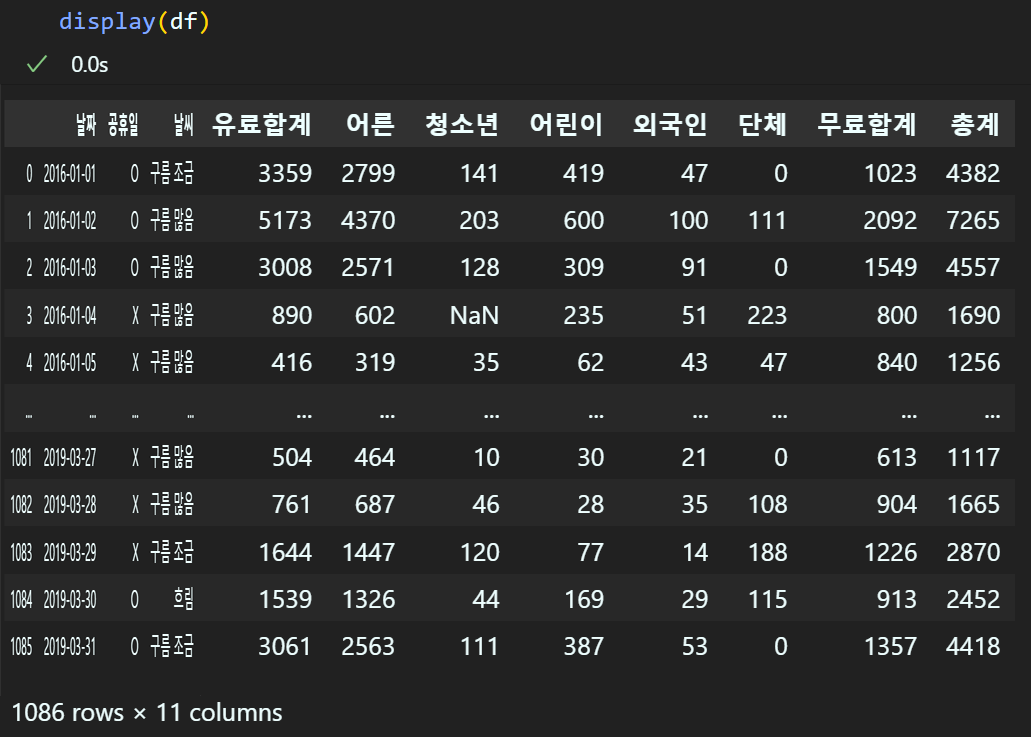
이후 데이터타입 변환 코드를 적용한다.
for i in cel_col_list:
try:
# 데이터의 정수 변환
df[i] = df[i].astype(int)
except ValueError:
# NaN 값이 있거나 변환할 수 없는 경우 패스
pass위 코드는 NaN으로 인해 변환이 불가능한 원소값을 제외하고 나머지 문자열 데이터는 모두 숫자로 변환하는 코드이다.
이것을 더 간편하게 수행하고자 한다면
pd.to_numeric()을 사용하면 된다.
for i in cel_col_list:
# NaN 값을 유지하면서 int로 변환
df[i] = pd.to_numeric(df[i], errors='coerce').astype('Int64')두번재로 '날짜' 컬럼도 object타입이어서 이를 올바르게 날짜 타입의 데이터로 변환해야 한다.
df['날짜'] = pd.to_datetime(df['날짜'])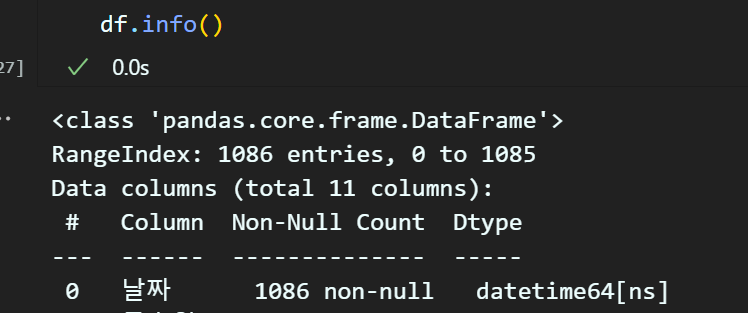
이렇게 pd.to_datetime 메서드로 datatime64형식으로 데이터 타입이 변화하였다.
df3 = pd.DataFrame()
# 날짜 항목으로부터 년,월,일 항목을 생성
df3['년'] = df['날짜'].dt.year
df3['월'] = df['날짜'].dt.month
df3['일'] = df['날짜'].dt.day
# 요일은 숫자로 출력됨 -> 따라소 한글 요일명으로 바꿔야함
# 숫자로 반환된 요일을 한글 요일명으로 변환
df3['요일'] = df['날짜'].dt.dayofweek.replace({
0: '월', 1: '화', 2: '수', 3: '목',
4: '금', 5: '토', 6: '일'
})위 코드처럼 데이터타입이 날짜 타입이 되면 년, 월,일 요일등의 항목을 출력할 수 있다.
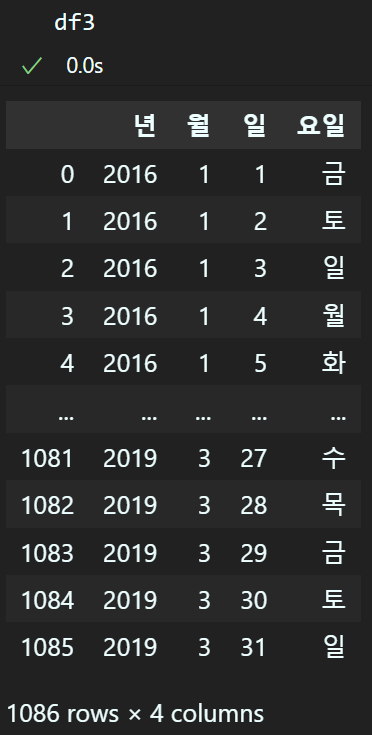
이렇게 신규컬럼 df3을 기존 df의 '날짜', '공휴일'사이의 컬럼에 삽입하자
# df3의 컬럼을 df에 추가
df_combined = pd.concat([df.iloc[:, :1], df3, df.iloc[:, 1:]], axis=1)
다음으로 https://drive.google.com/file/d/1xN4j-RkmOUSdtY38axJ2Se0g1V1Zozig/view?usp=drive_link
'seoul_park02.csv'파일로 실습을 진행하겠다
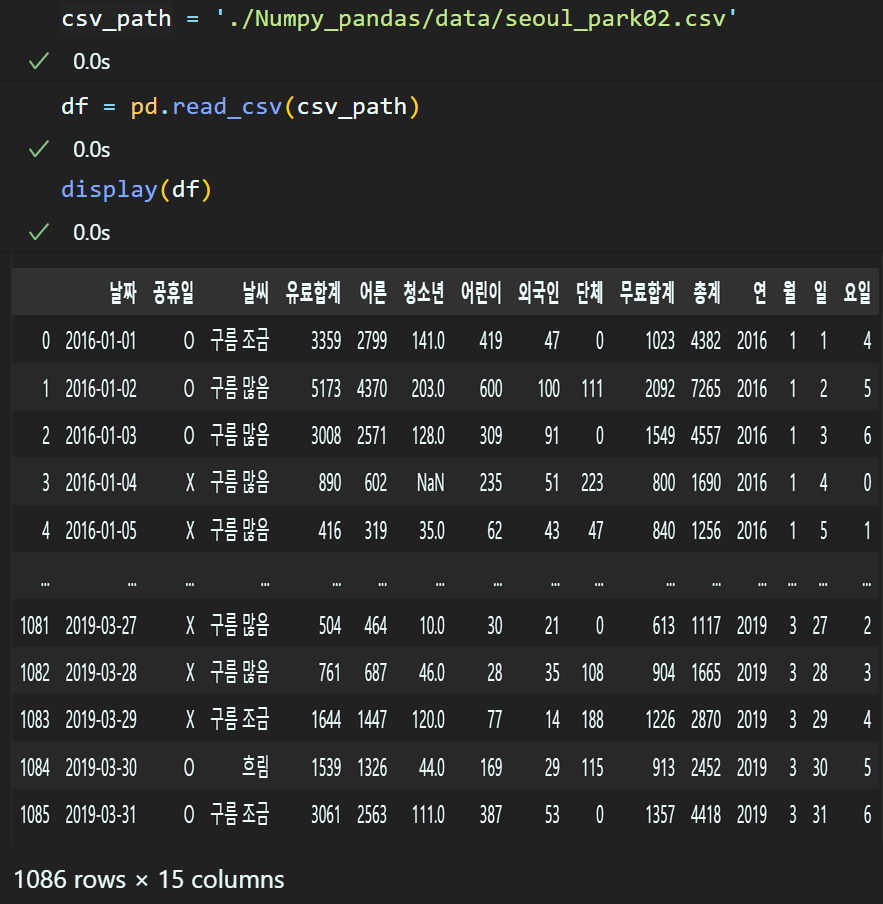
'seoul_park02.csv'는 지금까지 진행한 전처리 과정의 체크포인트 개념의 데이터라 보면 된다.
'seoul_park02.csv'는 '요일'컬럼이 숫자형 데이터로 변환되었기에
올바르게 월~일 문자열로 변환을 다시해보자
week = { 0: '월', 1: '화', 2: '수', 3: '목',
4: '금', 5: '토', 6: '일'}
# map 메서드를 활용한 데이터 변환
df['요일'] = df['요일'].map(week)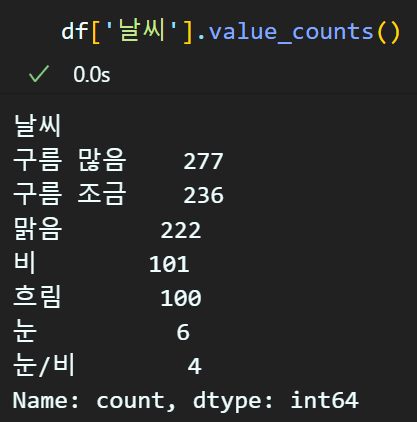
위 조건을 '흐림', '우천', '맑음' 3개로 날씨조건을 축소해보자
def weather(condition):
if condition in ['구름 많음', '흐림']:
return '흐림'
elif condition in ['눈', '눈/비', '비']:
return '우천'
elif condition in ['맑음', '구름 조금']:
return '맑음'
else:
# 조건에 부합하지 않는 예외는 변경X
return conditiondf['날씨'] = df['날씨'].apply(weather)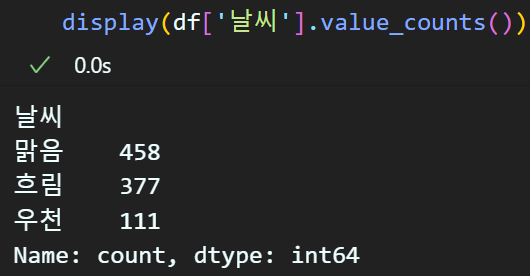
이렇게 임의의 함수를 설계한 뒤 apply메서드로 설계한 함수를 컬럼 내 모든 원소에 일괄적으로 적용할 수 있다.
데이터의 통계값 확인
numpy에서 제공하는 mean, min, max, median도 pandas에서 동일하게 적용 가능하다
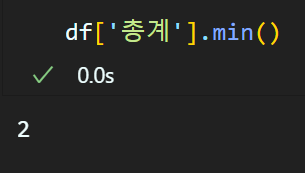
이와 같은 방식으로 적용이 가능하다.
하지만 이것보다는 describe()메서드로 일괄적으로 확인하는 것이 좀 더 편리하다.
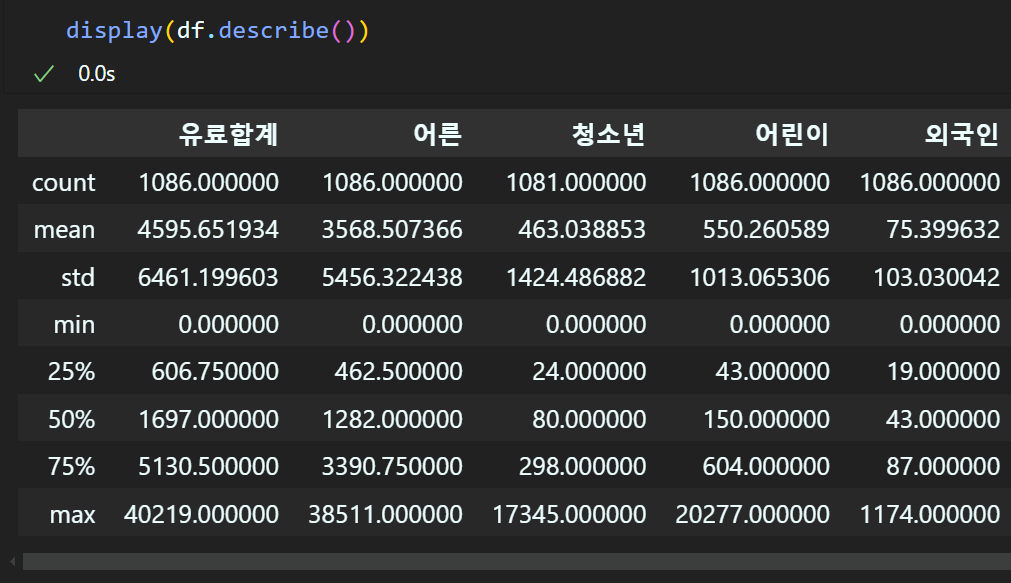
여기서 데이터 집계 및 분석을 좀 더 자세하게 하고 싶다면
groupby() 메서드를 활용하면 된다.
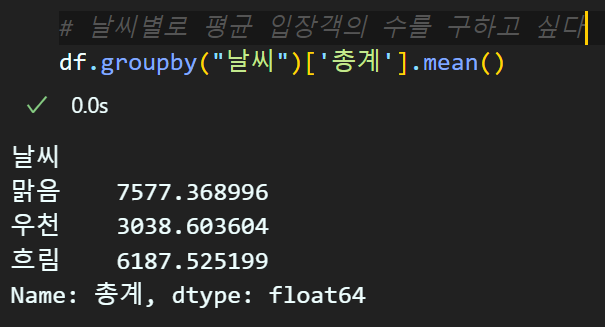
예를 들어 '날씨'에 따라 총 입장객의 수가 변화하는지를 확인하고 싶다면
위 코드를 통해 확인할 수 있다.
이를 통해 우천시에는 입장객이 감소하며, 맑음과 흐림의 정도는 크게 영향이 없는것을 알 수 있다.

이를 응용하면 위와 같이 조건을 여러개 넣어서 MySQL과 유사하게 사용할 수 있다.
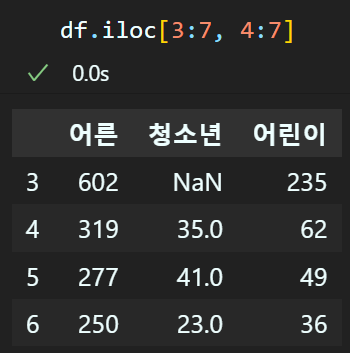
데이터 추출에는 loc, iloc 메서드를 사용하여 특정 행 혹은 열을 추출할 수 있다.
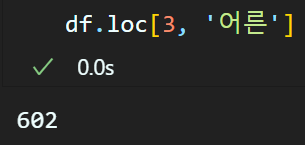
위 방식으로 [행, 열] 순으로 인덱싱하여 데이터 추출이 가능하며
이때 행, 열은 모두 리스트 슬라이싱의 기법,
Numpy라이브러리의 Boolean indexing기법이 동일하게 적용된다.

iloc는 loc함수와 동일하나 인덱싱을 정수형 데이터로만 수행한다.