1. 강의 복습 준비
강의 실습 환경은 MySQL Workbench 8.0 으로 진행한다.
DB생성
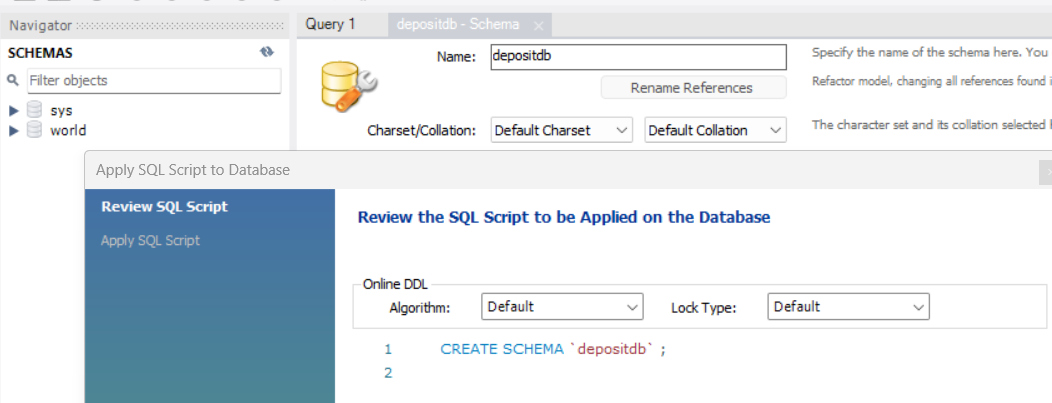
DB 생성은 위 사진처럼 SCHEMAS 네비게이터 창에서 오른쪽 탭 Create Schemas를 선택하면 데이터베이스를 생성할 수 있다.
이때 생성하는 창에서 데이터베이스를 UI로 생성하는 것이 아닌 SQL 언어로 생성하는 코드도 같이 Display해준다.
CREATE SCHEMA `new_schema` ;테이블 생성
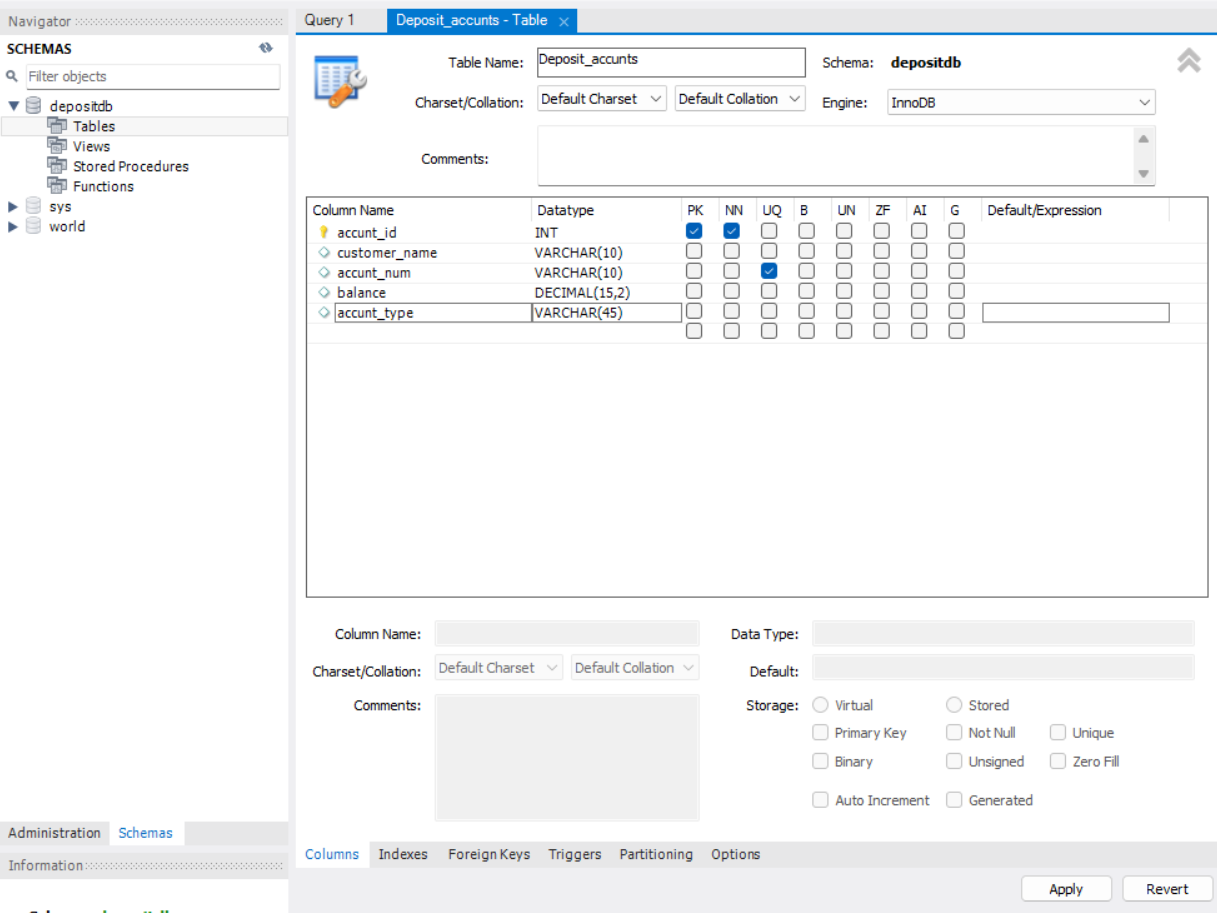
다음으로 생성한 depositdb 데이터베이스를 클릭 후 테이블 create table를 클릭하면
위 사진처럼 테이블 내 column을 정의할 수 있는 창이 뜬다.
여기에 각각 생성하고자 하는 컬럼을 입력 후 Apply 버튼을 클릭하면
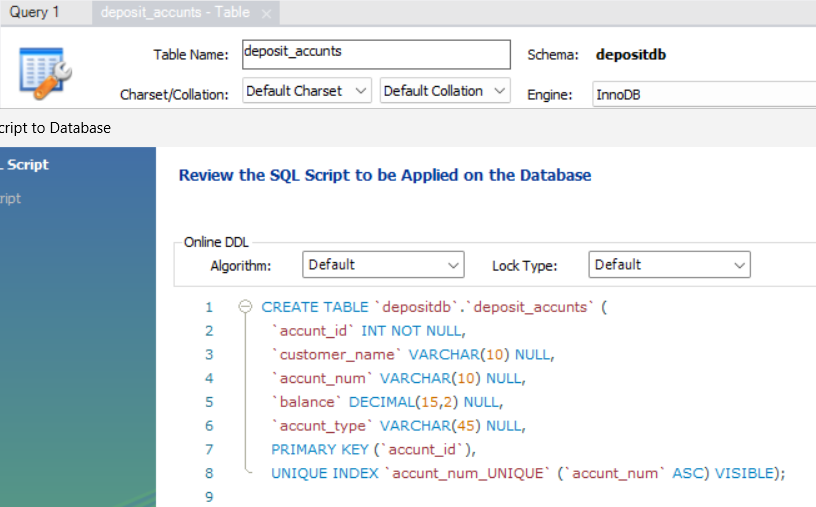
마찬가지로 생성하고자 하는 테에블에 대한 SQL코드가 디스플레이 되어 크로스체크를 가능케 해준다
CREATE TABLE `depositdb`.`deposit_accunts` (
`accunt_id` INT NOT NULL,
`customer_name` VARCHAR(10) NULL,
`accunt_num` VARCHAR(10) NULL,
`balance` DECIMAL(15,2) NULL,
`accunt_type` VARCHAR(45) NULL,
PRIMARY KEY (`accunt_id`),
UNIQUE INDEX `accunt_num_UNIQUE` (`accunt_num` ASC) VISIBLE);생성한 테이블에 데이터 채우기
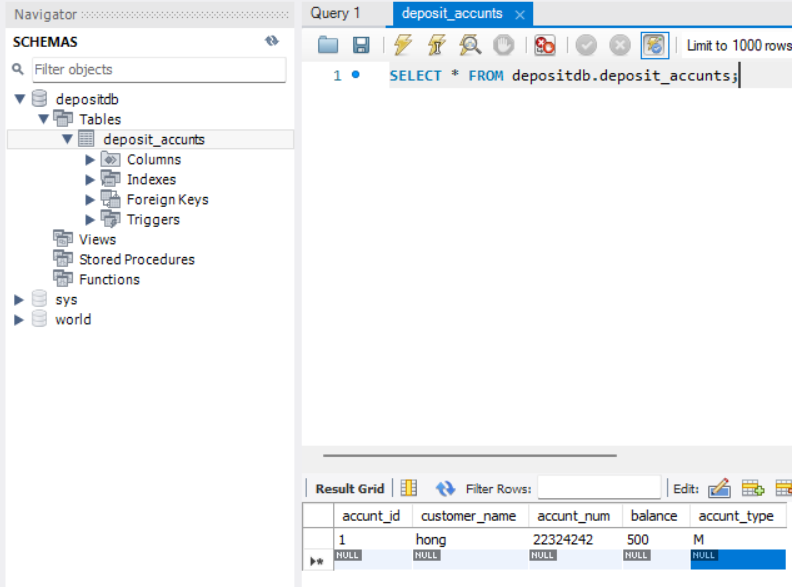
그리고 생성한 테이블 deposit_accunts 를 클릭하고 select rows - limit 1000버튼을 클릭하면
위 사진처럼 데이터를 보여주는 SQL 코드
SELECT * FROM depositdb.deposit_accunts;이 자동으로 쿼리창에 입력되며 그 아래 하단부에 해당 테이블의 현재 상태가 보여진다.
처음에는 아무런 값도 없는 테이블이 뜨지만
첫번째 행에 임의의 값
1, hong, 22324242, 500, M을 입력하고
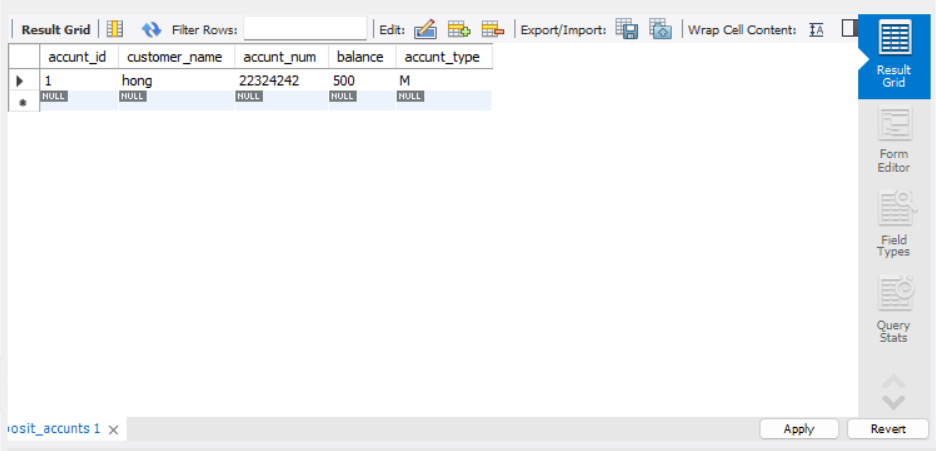
오른쪽 하단의 apply버튼을 클릭하자
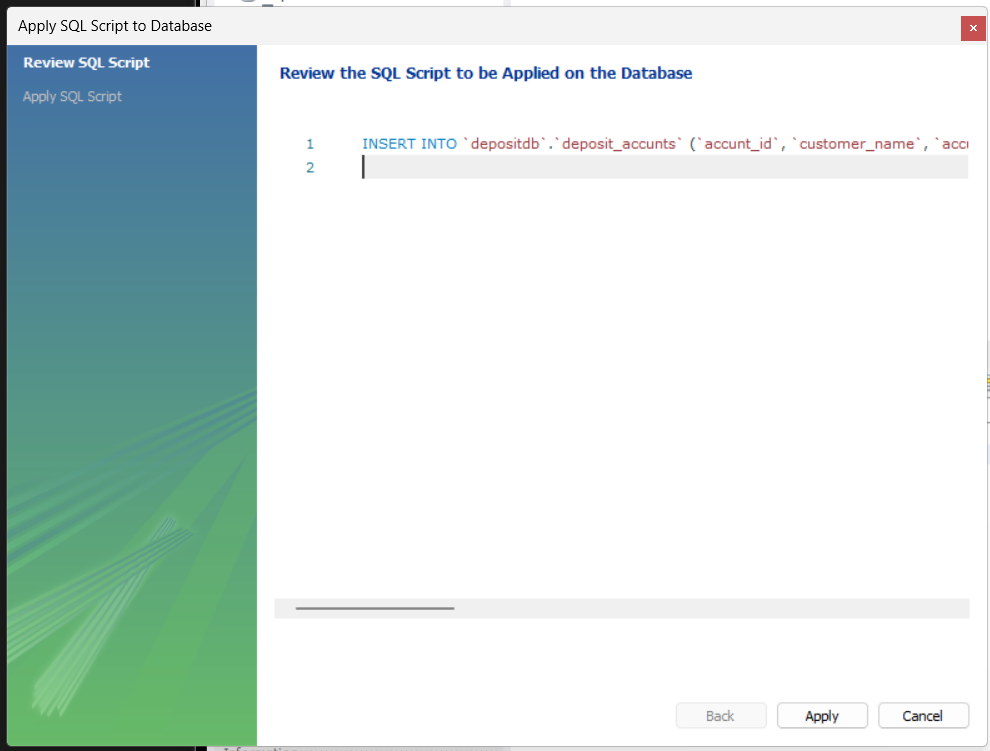
그러면 또다시 UI로 수행한 작업물에 대한 SQL코드가 자동생성 되면서 크로스체크 기능을 제공한다.
INSERT INTO `depositdb`.`deposit_accunts` (`accunt_id`, `customer_name`, `accunt_num`, `balance`, `accunt_type`) VALUES ('1', 'hong', '22324242', '500', 'M');2. 데이터 Import
신규 데이터 베이스 생성
CREATE DATABASE 무역 DEFAULT CHARSET utf8mb4 COLLATE utf8mb4_general_ci;데이터 베이스를 생성한 뒤에는
생성한 데이터베이스 내에서 작업하는것을 명시해줘야 한다
USE 무역;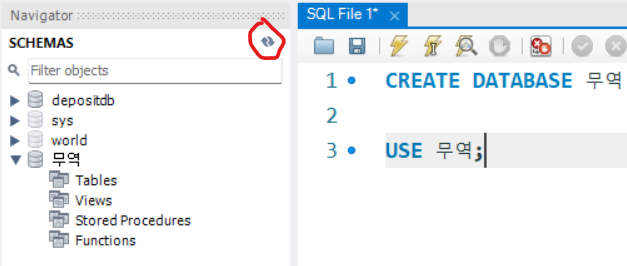
생성한 데이터베이스 무역이 네이게이터 창에서 보이지 않는다면 붉은색으로 표시한 새로고침 버튼을 클릭하면 된다.
신규 테이블 생성
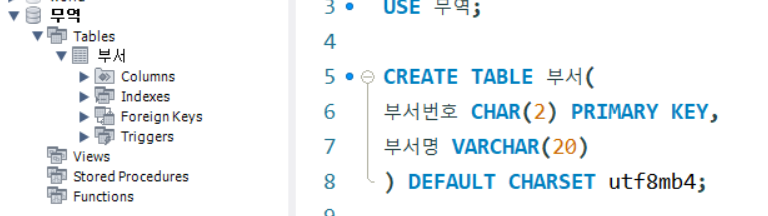
CREATE TABLE 부서(
부서번호 CHAR(2) PRIMARY KEY,
부서명 VARCHAR(20)
) DEFAULT CHARSET = utf8mb4;위 코드를 치고 네비게이션창을 새로고침하자
SQL 코드 기반으로 명령어 수행
https://github.com/tbvjvsladla/SQL_Database_lacture
해당 깃 허브에 업로드한
무역-데이터베이스생성스크립트.sql
를 다운로드 받은 뒤 이를 열람하여 전체실행을 수행하자
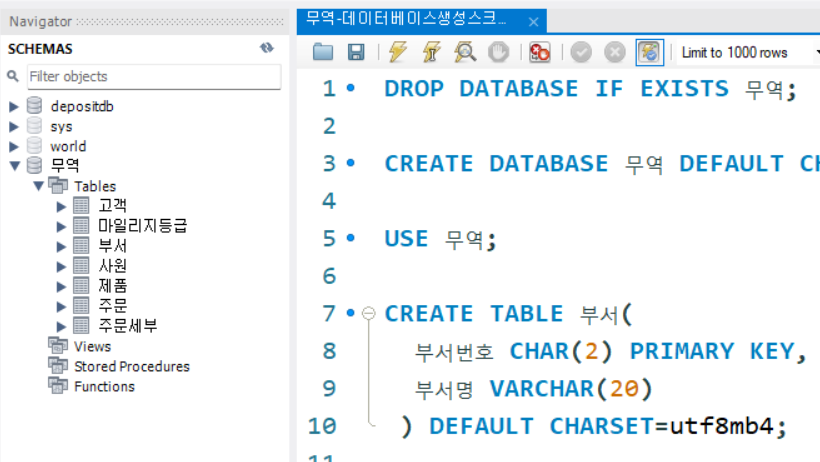
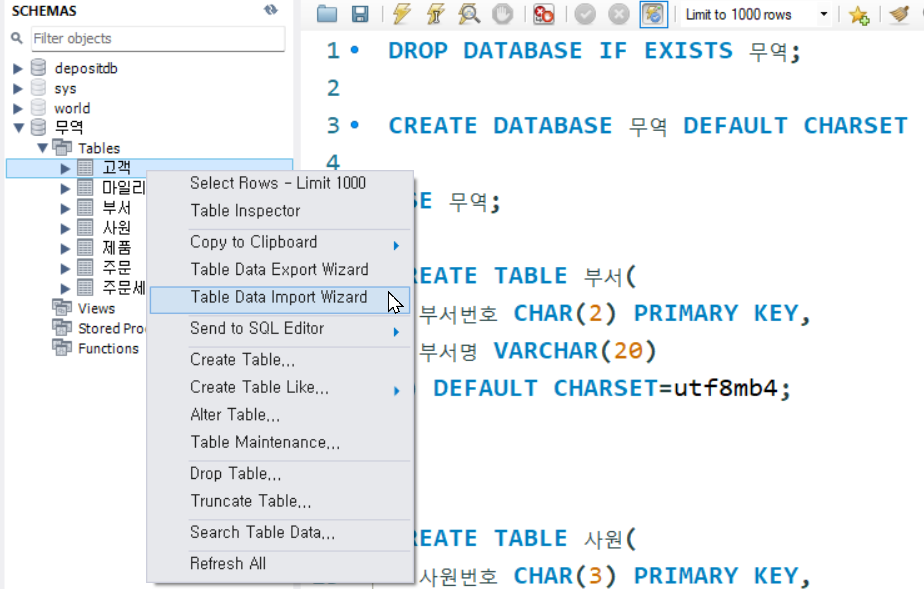
그리고 생성된 각 테이블 고객, 마일리지등급, 부서, 사원, 제품, 주문, 주문세부
에 Table Data Import Wizard 메뉴를 클릭한 뒤
https://github.com/tbvjvsladla/SQL_Database_lacture
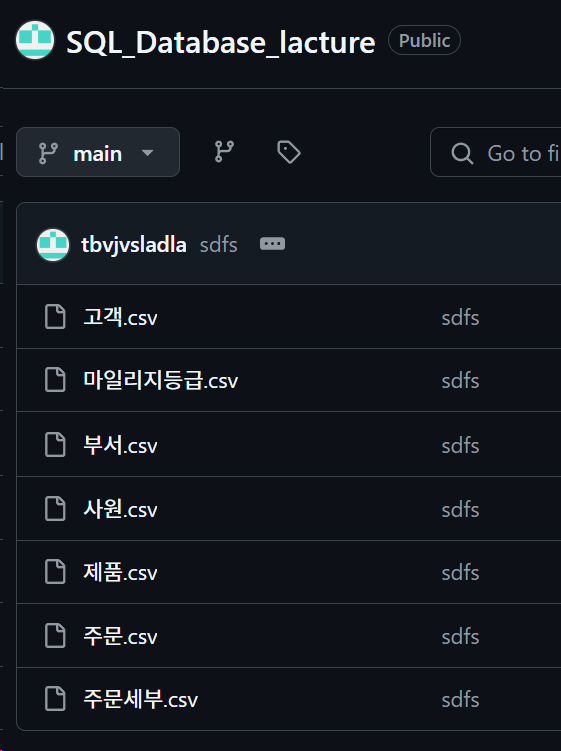
위 깃허브 저장소에 업로드한 각각의 *.csv파일을 붙여넣는다.
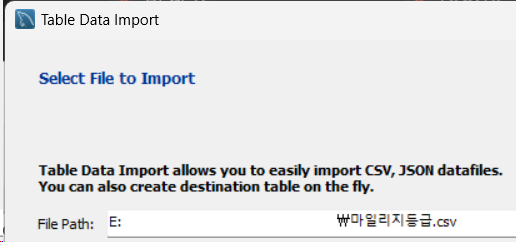
테이블에 각각의 매칭된 *.csv를 붙여넣으면
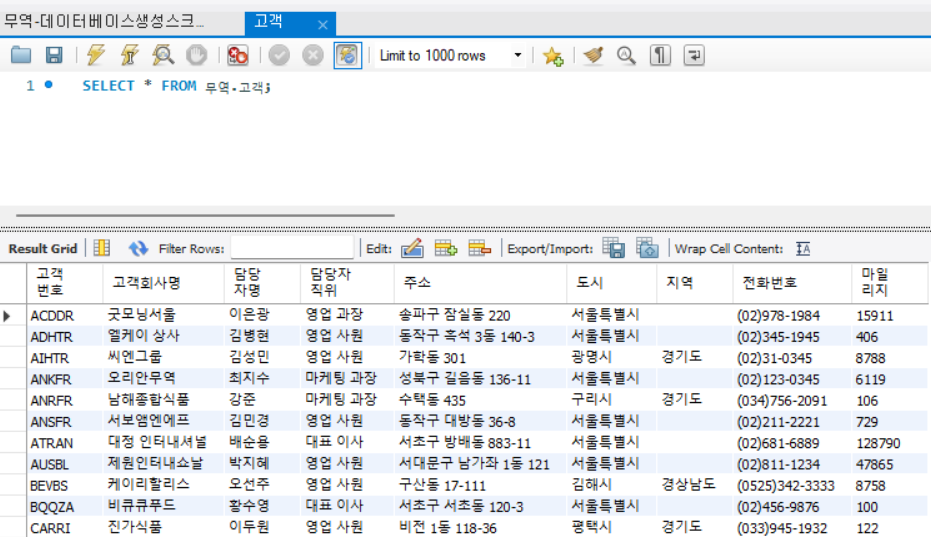
위 사진처럼 해당 테이블 열람 시
데이터가 각각 import가 됨을 확인할 수 있다.
참고로 테이블 - csv 파일 매칭을 잘못 할 시에는 데이터 import가 수행되지 않는다.
3. SQL문법 - 데이터조회
신규 쿼리탭을 연 뒤 실습을 진행한다

우선 데이터 조회의 기본 코드 구조는
위 구조를 따른다 보면 된다.
데이터 조회
# 고객 테이블의 모든 데이터 조회
SELECT *
FROM 고객;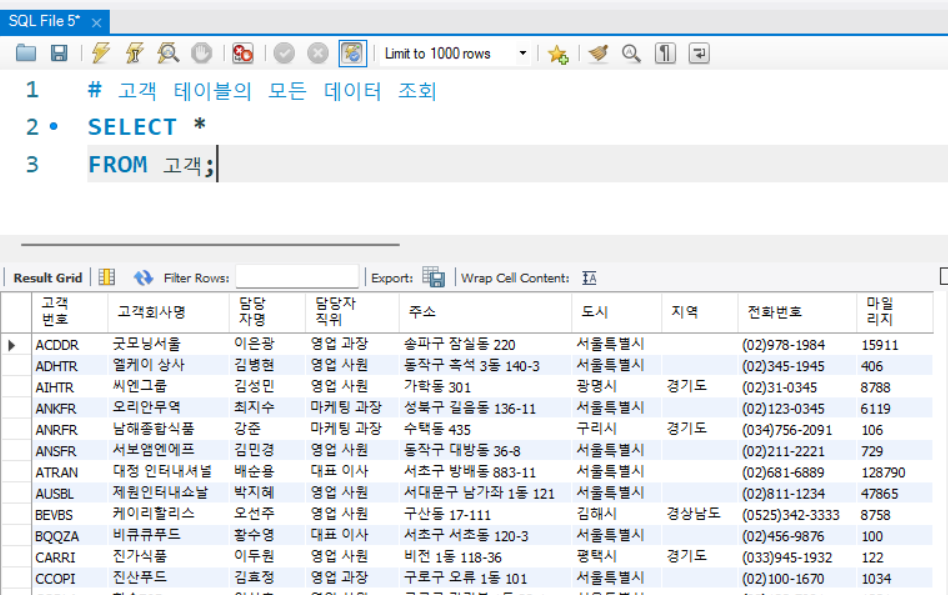
#고객 테이블의 주소, 도시, 지역 조회
SELECT 주소, 도시, 지역
FROM 고객;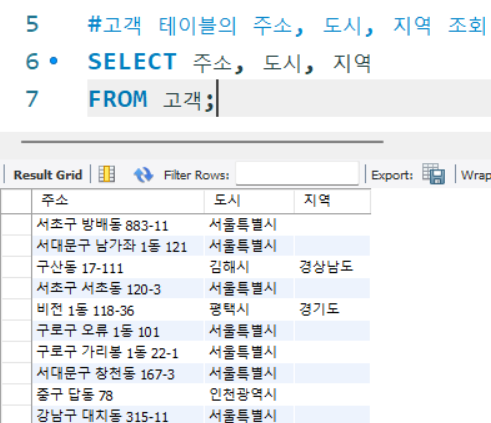
데이터 조회시 기본연산 수행
# 마일리지등급 테이블 : 상한 마일리지 * 0.001
SELECT 상한마일리지 * 0.001 AS 소수점
FROM 마일리지등급;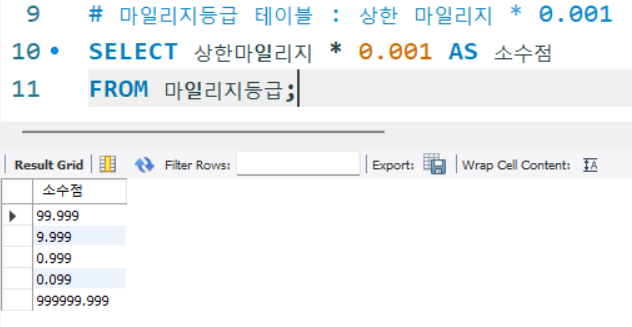
# 고객테이블에서 고객번호, 담당자명, 고객회사명, 마일리지,
# 그리고 10% 인상된 마일리지를 조회하시오
# 이때 마일리지는 '포인트'로 인상된 마일리지는 '인상포인트'
# 로 재명기하시오
SELECT 고객번호, 담당자명, 고객회사명,
마일리지 AS 포인트, 마일리지*1.1 AS 인상포인트
FROM 고객;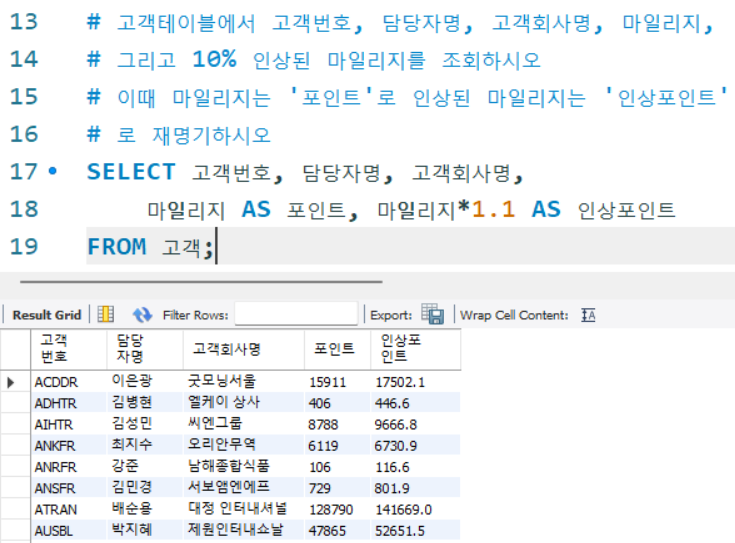
# 고객테이블에서 마일리지가 100,000 이상인
# 고객의 고객번호, 담당자명, 마일리지 조회
SELECT 고객번호, 담당자명, 마일리지
FROM 고객
WHERE 마일리지 >= 100000;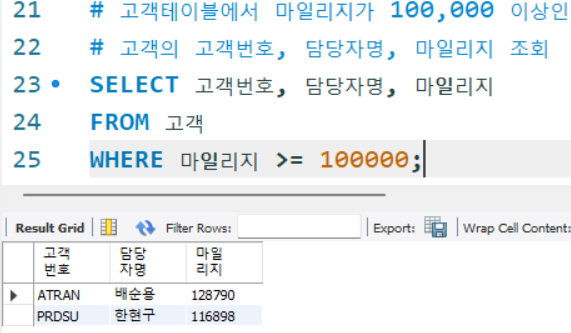
데이터 조회시 정렬
ORDER BY 절로 정렬을 수행하며,
오름차순(ASC), 내림차순(DESC)이다.
# 서울특별시에 사는 고객에 대해
# 고객번호, 담당자명, 도시, 마일리지 조회
# 이때 마일리지가 많은 순서대로 조회
SELECT 고객번호, 담당자명, 도시, 마일리지
FROM 고객
WHERE 도시 = '서울특별시'
ORDER BY 마일리지 DESC;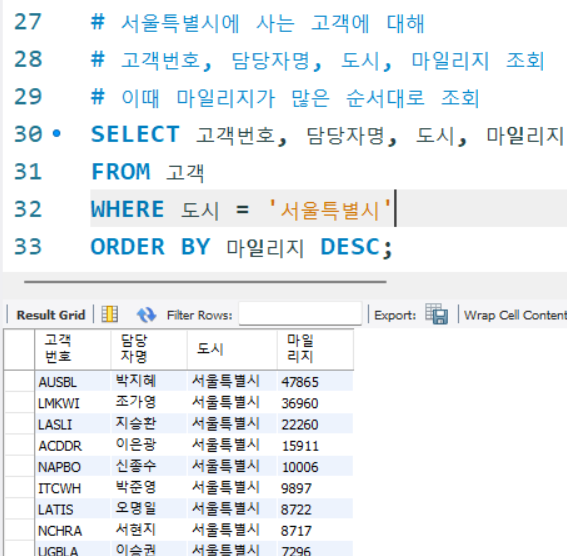
데이터 조회시 제한
LIMIT 절을 통해서 조회하는 데이터의 개수를 제한 할 수 있다.
# 고객 테이블에서 1행부터 시작해 3개의 고객정보 조회
SELECT *
FROM 고객
LIMIT 3;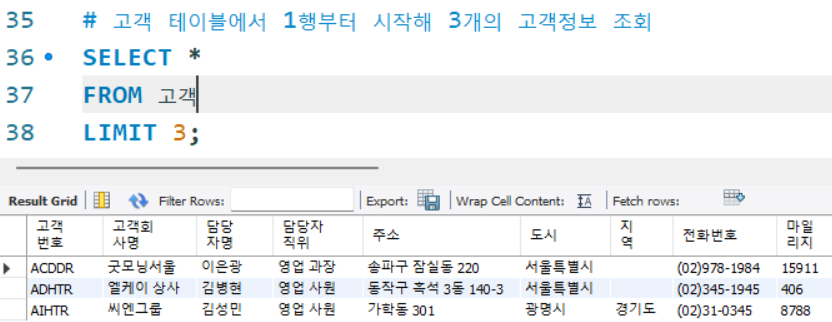
# 마일리지가 많은 고객부터 상위 3명의 고객정보
SELECT *
FROM 고객
ORDER BY 마일리지 DESC
LIMIT 3;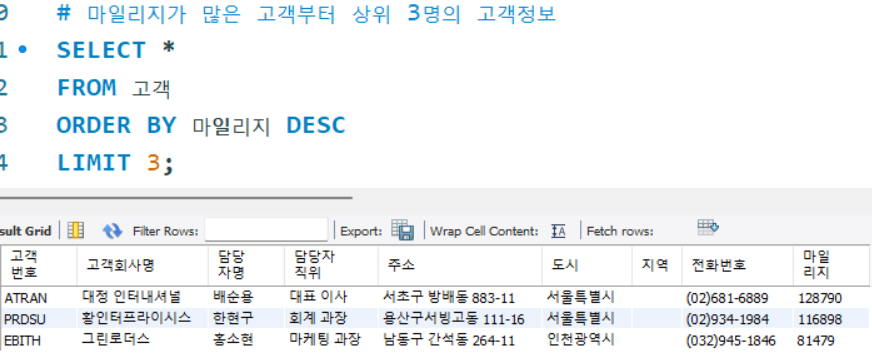
중복 제거
DISTINCT절을 통해 중복한 데이터를 제거하고 조회할 수 있다.
# 도시를 중복한 항목을 제거하고 조회
SELECT DISTINCT 도시
FROM 고객;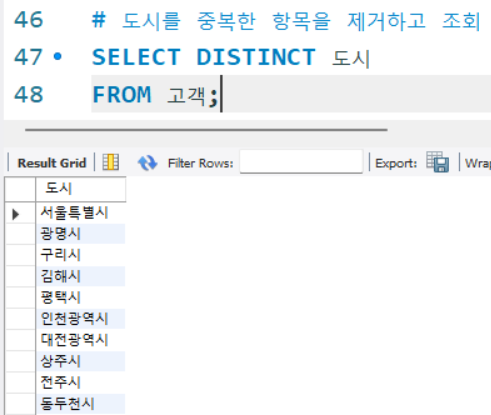
4. SQL - 연산자
SQL도 따지고 보면 프로그래밍 언어라 볼 수 있기에 기본적인 연산자(산술, 비교, 논리) 연산자의 기능 및 수식 구현이 가능하다.
산술연산자
-- 2개의 숫자 23, 5로 다양한 산술연산 수행하기
SELECT
23 + 5 AS 더하기,
23 - 5 AS 빼기,
23 / 5 AS 나누기,
23 % 5 AS 나머지,
23 DIV 5 AS 몫,
23 MOD 5 AS 나머지;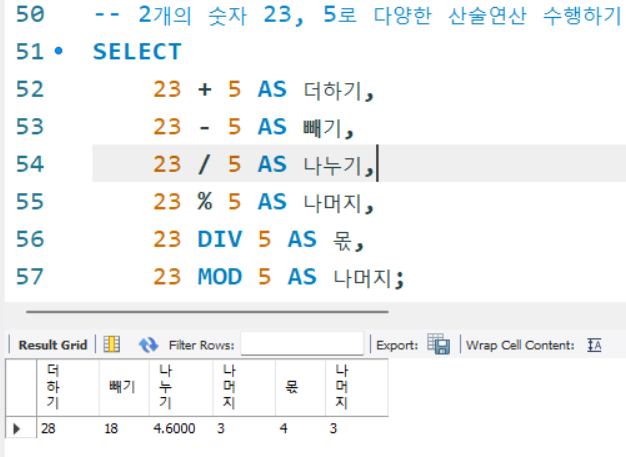
비교연산자
>=, <=, >, <, =, !=, <> 와 같은 연산자를 의미한다.
이때 같다(동치) 를 뜻하는 연산자는 ==이 아닌 =을 사용한다.
# 담당자가 '대표 이사'가 아닌 고객의 모든 정보 찾기
SELECT *
FROM 고객
WHERE 담당자직위 != '대표 이사';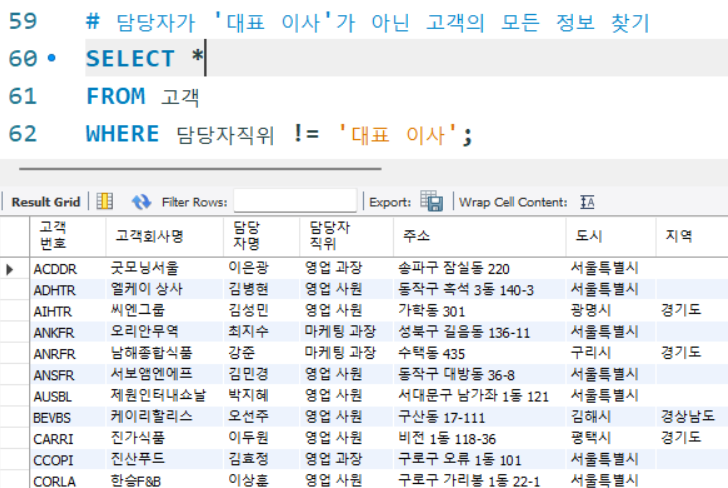
논리연산자
AND, OR, NOT 3개의 연산자를 활용한다.
# 도시가 '부산광역시' 이면서 마일리지가 1000점 미만인
# 고객의 모든 정보를 조회
SELECT *
FROM 고객
WHERE 도시 = '부산광역시' AND 마일리지 < 1000;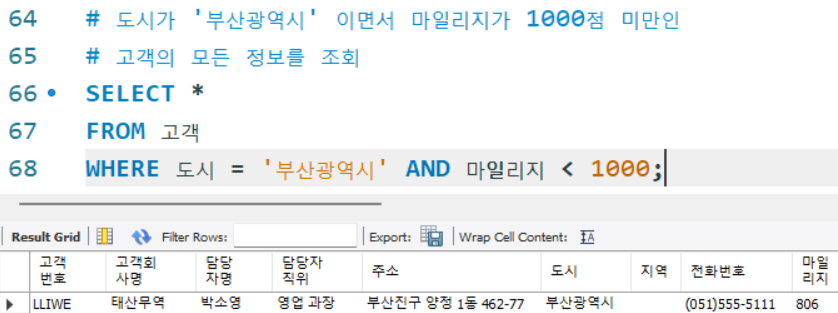
집합연산자
UNION 절을 활용하여 개수 및 데이터 유형이 같은 두개의 집합을 한번에 처리할 수 있다.
문제 :
# '부산광역시'에 살거나 마일리지가 1000점 미만인
# 고객에 대하여 고객번호, 담당자명, 마일리지, 도시
# 정보를 조회. 이때, 결과는 고객번호 순으로 정렬1) OR연산자를 통한 문제 풀이
SELECT 고객번호, 담당자명, 마일리지, 도시
FROM 고객
WHERE 도시 = '부산광역시' OR 마일리지 < 1000
ORDER BY 고객번호 ASC;2) 집합연산자 UNION을 통한 문제 풀이
SELECT 고객번호, 담당자명, 마일리지, 도시
FROM 고객
WHERE 도시 = '부산광역시'
UNION
SELECT 고객번호, 담당자명, 마일리지, 도시
FROM 고객
WHERE 마일리지 < 1000
ORDER BY 고객번호 ASC;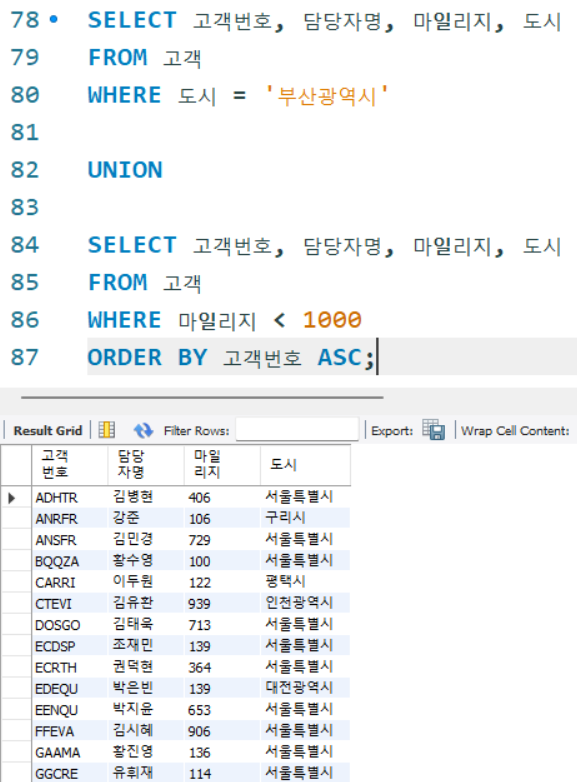
결측치 확인 연산자
IS NULL연산자를 통해 확인이 가능하다
# 지역에 값이 없는 고객의 정보 조회
SELECT *
FROM 고객
WHERE 지역 IS NULL;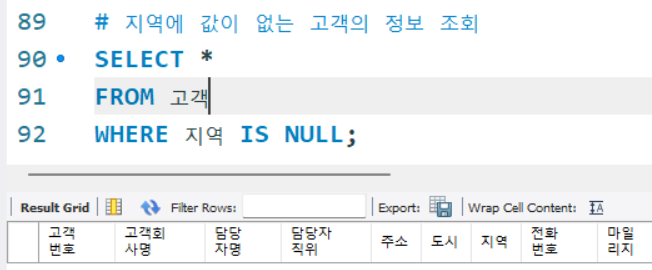
IN,BETWEEN~AND
위 세가지 연산자는 WHERE절을 좀 더 쉽고 효율적으로 사용할 수 있도록 도와주는 연산자이다.
1) IN : 다중 OR 을 쉽게 처리할 수 있는 연산자이다.
# 담당자 직위가 '영업 과장' 이거나 '마케팅 과장'인
# 고객에 대하여 고객번호, 담당자명, 담당자 직위 조회
SELECT 고객번호, 담당자명, 담당자직위
FROM 고객
WHERE 담당자직위 IN ('영업 과장', '마케팅 과장');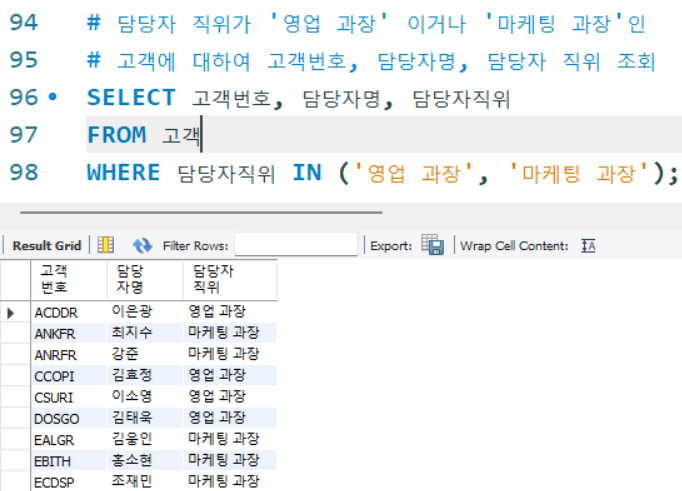
2) BETWEEN ~ AND : 다중 조건문을 쉽게 처리할 수 있는 연산자
# 마일리지가 100,000 이상 200,000 이하
# 고객의 담당자명, 마일리지 조회
SELECT 담당자명, 마일리지
FROM 고객
WHERE 마일리지 BETWEEN 10000 AND 20000;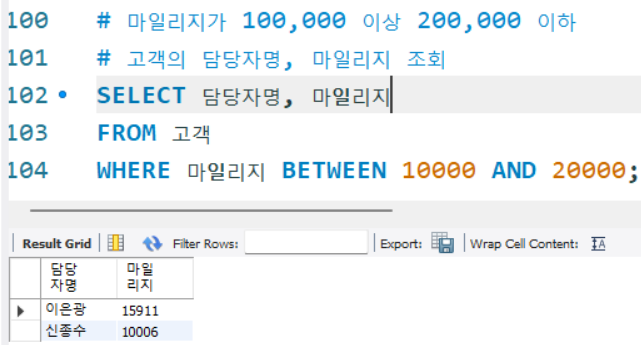
LIKE
좀 더 포괄적으로 조건을 걸어 조회할 때 사용하는 연산자
# 담당자명 이름 중간에 '희'가 포함된 고객의
# 고객번호, 담당자, 담당자직위 조회
SELECT 고객번호, 담당자명, 담당자직위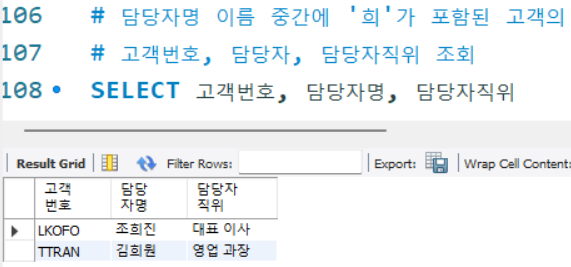
# 도시가 '광역시' 이면서
# 고객번호 2~3번째 단어가 `C`로 되어 있는
# 고객의 모든 정보 조회
SELECT *
FROM 고객
WHERE 도시 LIKE '%광역시'
AND (고객번호 LIKE '_C%' OR 고객번호 LIKE'__C%');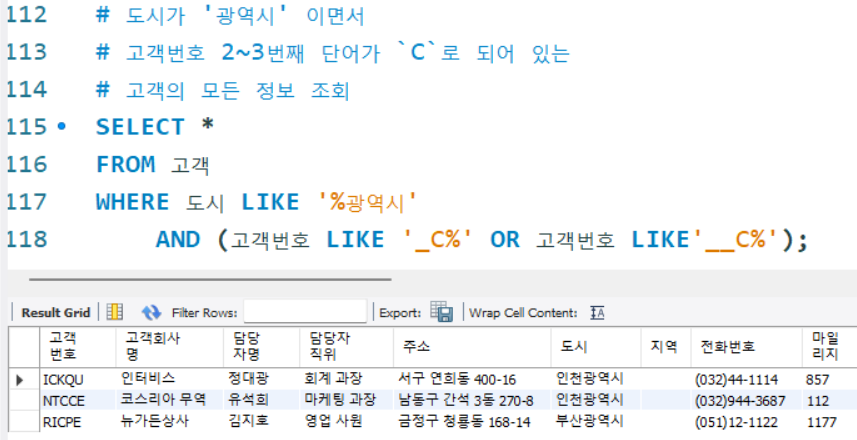
정규표현식 연산자
REGEXP, REGEXP_LIKE는 정규표현식 패턴으로 문자열 매칭을 통해 데이터 색인을 지원하는 연산자이다.
4.1 점검문제 풀이
# '서울'에 사는 고객 중 마일리지가 15000~20000인
# 고객의 모든 정보
SELECT *
FROM 고객
WHERE 도시 LIKE '%서울%'
AND 마일리지 BETWEEN 15000 AND 20000;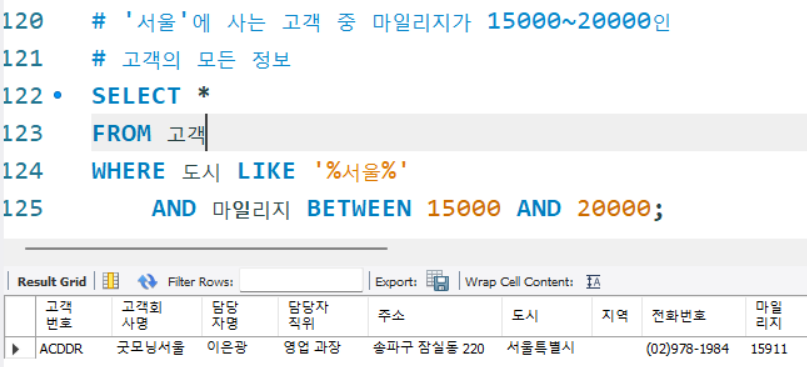
# 고객의 거주지역, 도시를 한번씩만 나타내기
# 둘 다 정렬 수행
SELECT DISTINCT 지역, 도시
FROM 고객
ORDER BY 지역, 도시;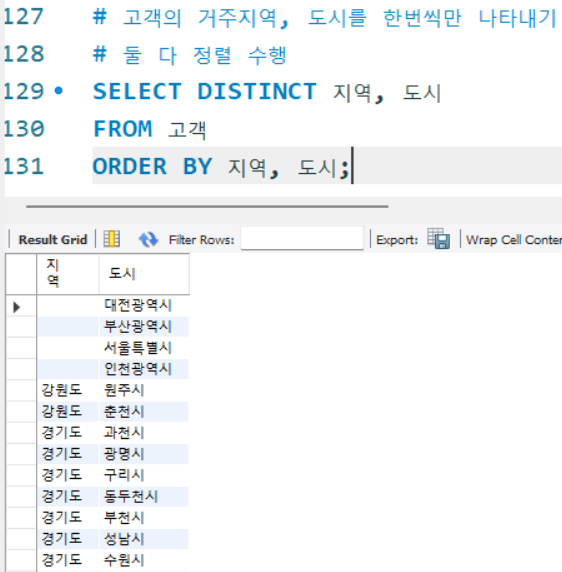
# '춘천시', '과천시', '광명시'에 거주중인 고객 중
# 담당자 직위가 '이사', '사원'인 고객의 정보 조회
SELECT *
FROM 고객
WHERE 도시 IN('춘천시', '과천시', '광명시')
AND 담당자직위 REGEXP '이사|사원';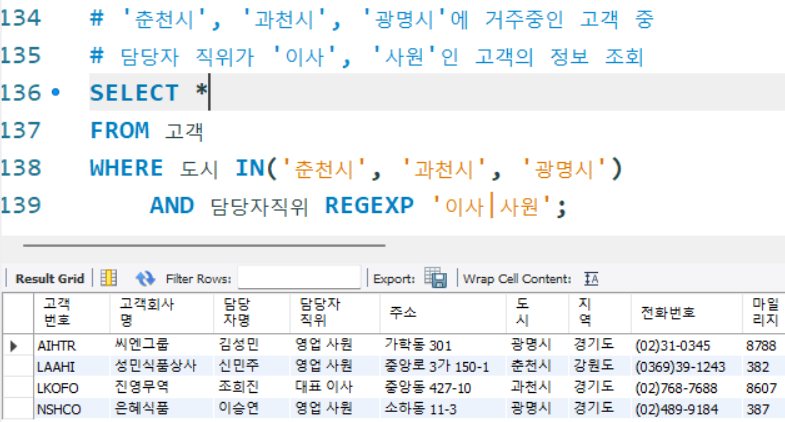
# '광역시', '특별시'에 거주하지 않는 고객 중
# 마일리지가 많은 상위 3명 고객의 모든 정보
SELECT *
FROM 고객
WHERE 도시 NOT REGEXP '광역시|특별시'
ORDER BY 마일리지 DESC
LIMIT 3;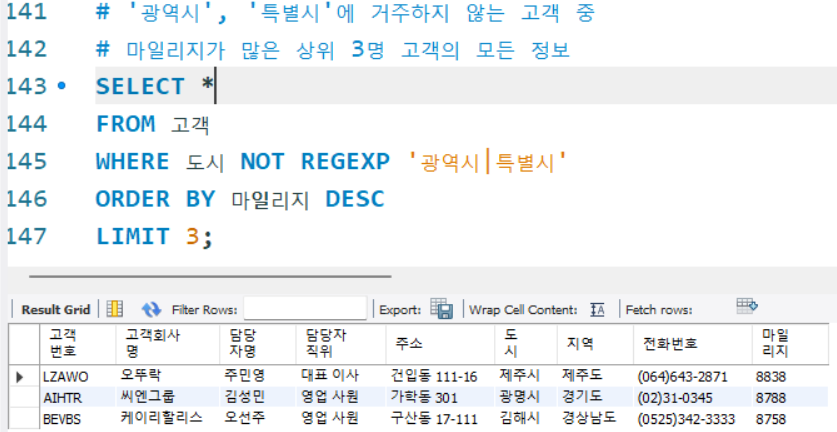
# 지역에 결측치가 아닌 항목 중
# 담당자 직위가 '대표 이사'인 고객을 제외한
# 나머지 고객 정보 조회
SELECT *
FROM 고객
WHERE 지역 IS NOT NULL
AND 담당자직위 != '대표이사';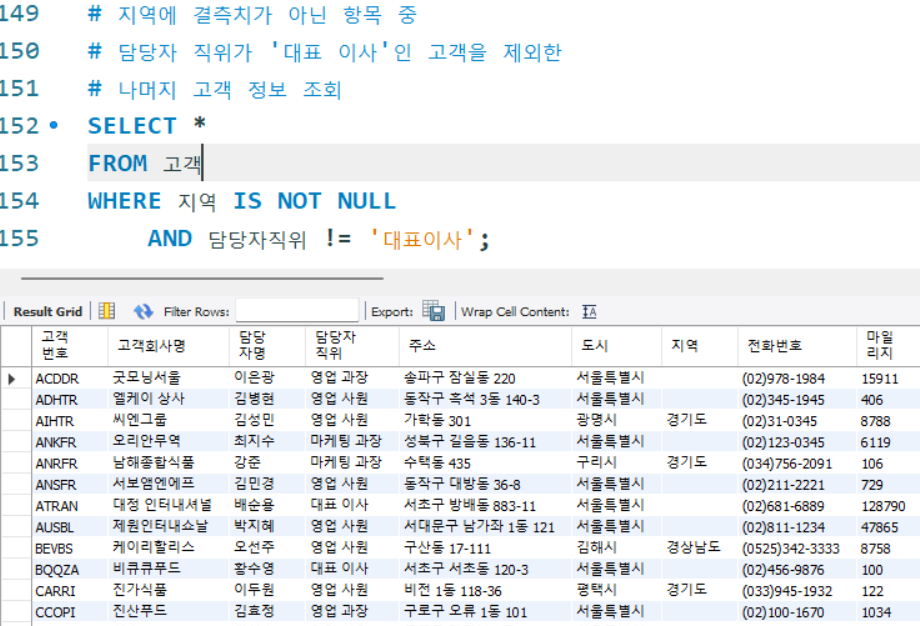
5. SQL - 함수1
문자형 함수
SELECT char_length("hello");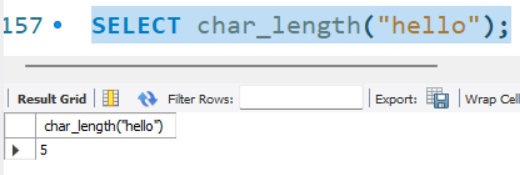
SELECT char_length("안녕"), length("안녕");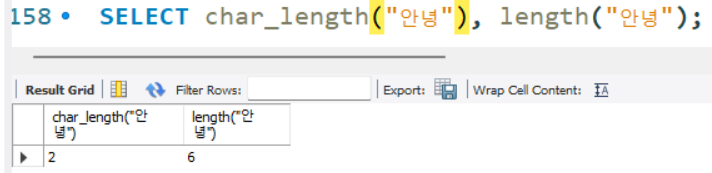
SELECT
concat("dream","come","true") as 컨캣,
concat_ws(' ', "dream","come","true") as 컨캣구분자;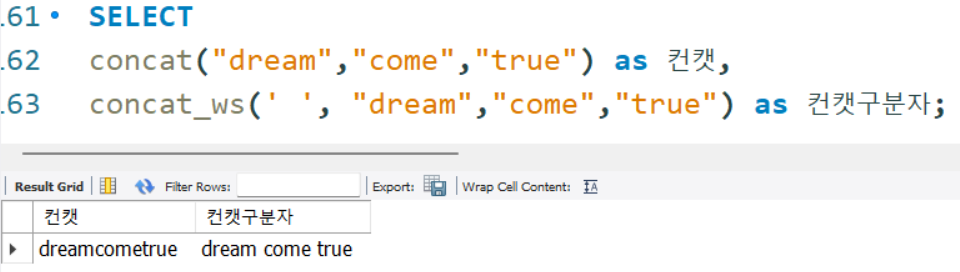
5.1 함수 실습 (길이)
새로운 데이터베이스 + 테이블 생성
CREATE SCHEMA `FUNC`;
USE FUNC;
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100),
email VARCHAR(100)
);
INSERT INTO users (name, email) VALUES
('Alice', 'alice@example.com'),
('Bob', 'bob@example.com'),
('hong', 'hong@example.com'),
('yamada', 'yamada@example.com')
('홍길동', 'gil-dong@example.com'),
('사카모토', 'yamada@example.com');위 코드 실행 후 user테이블 내에 값이 채워졌는지 확인

길이 함수
# 각 사용자의 이름(name)의 문자 길이와 바이트 길이를 구하세요.
SELECT char_length(name) as 문자길이,
length(name) as 바이트길이
FROM users;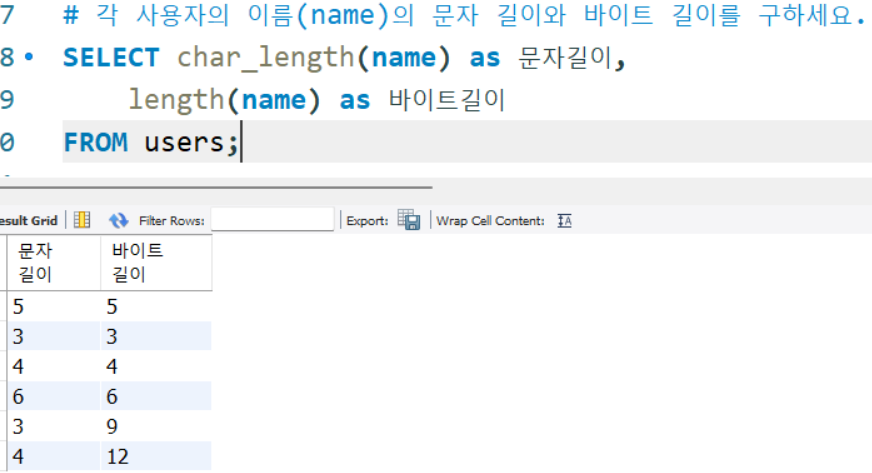
# 이름의 문자 길이가 3인 사용자를 모두 출력하세요.
SELECT name
FROM users
WHERE char_length(name) = 3;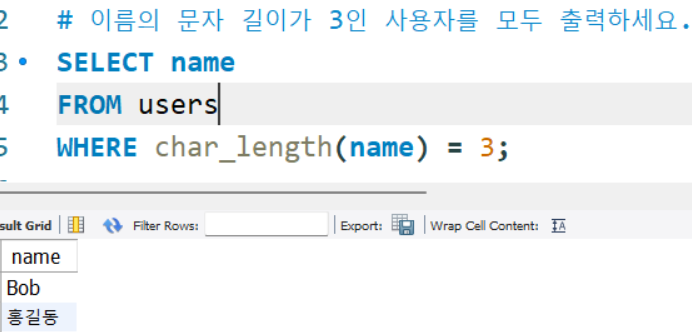
# 이름의 바이트 길이가 5 이상인 사용자를 모두 출력하세요.
SELECT name
FROM users
WHERE length(name) >= 5;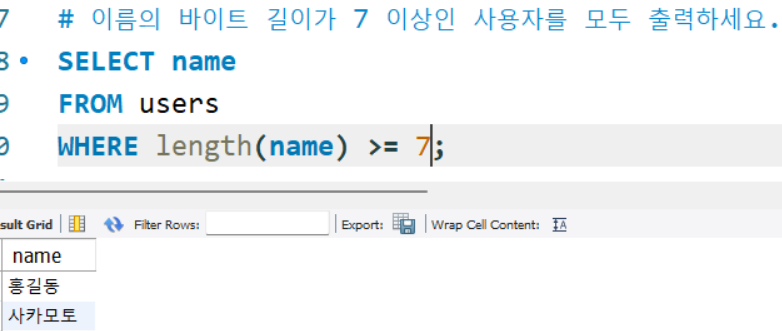
5.2 함수 실습(단어붙이기)
신규 테이블 및 예제 코드 추가
## 문제 항목 추가
CREATE TABLE employees (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50),
last_name VARCHAR(50),
department VARCHAR(50)
);
INSERT INTO employees (first_name, last_name, department) VALUES
('John', 'Doe', 'Sales'),
('Jane', 'Smith', 'Marketing'),
('Mike', 'Johnson', 'Engineering'),
('Tom', NULL, 'HR');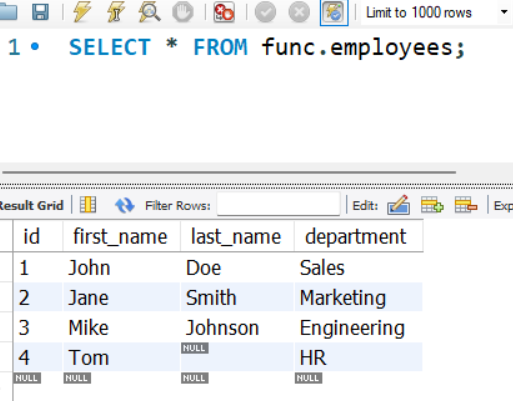
문자열 붙이기
# first_name과 last_name을 공백으로 연결하여 풀네임을 출력하세요.
SELECT concat_ws(' ', first_name, last_name) as 풀네임
FROM employees;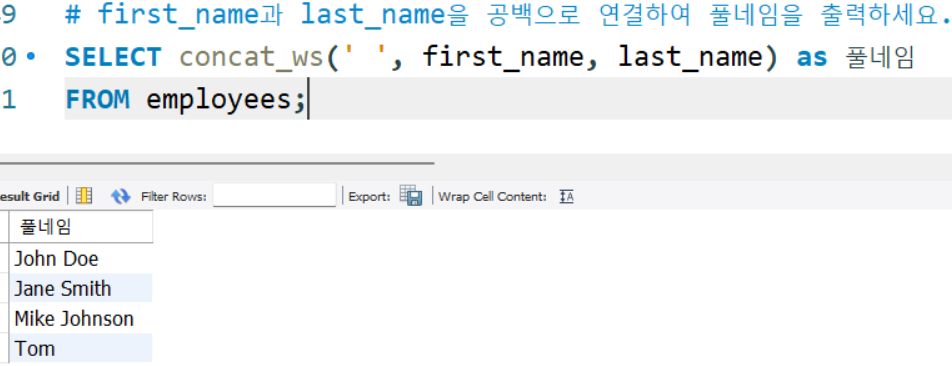
# first_name, last_name, 그리고 department를
# 하이픈()으로 연결하여 출력하세요. 단, NULL 값은 무시하세요.
SELECT concat_ws('-', first_name, last_name, department)
AS 하이픈연결
from employees;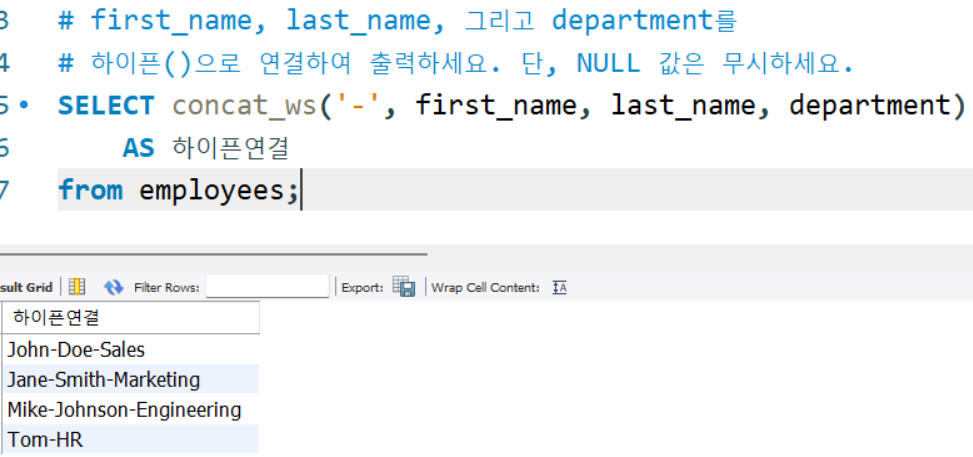
5.3 문자열 반환
LEFT, RIGHT, SUBSTR로 조건을 건 문자열반환 수행할 수 있다.
SELECT left('sql_완전정복', 3) as 'LEFT함수',
right('sql_완전정복', 4) as 'RIGHT함수',
substr('sql_완전정복', 2,5) as 'substr함수1',
substr('sql_완전정복', 2) as 'substr함수2';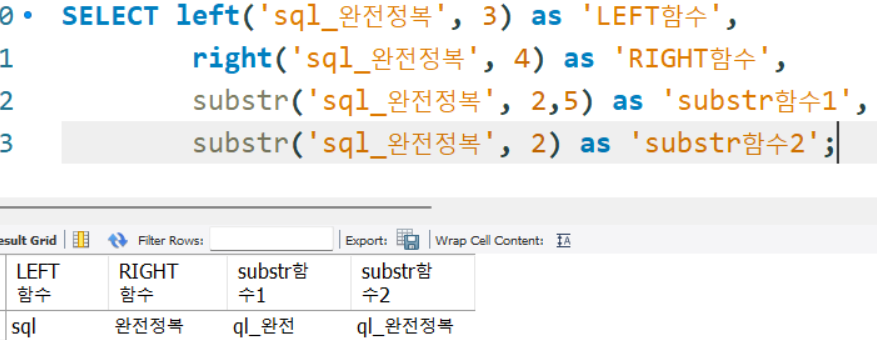
substring_index 함수로는 구분자 조건으로 문자열 반환이 가능하다
SELECT substring_index('서울시 동작구 흑석로', ' ', 2) as 결과;
SELECT substring_index('서울시 동작구 흑석로', ' ', -2) as 결과;
5.4 문자열 반환 실습
실습 예제 코드
CREATE TABLE products (
id INT PRIMARY KEY AUTO_INCREMENT,
product_name VARCHAR(100),
product_code VARCHAR(20)
);
INSERT INTO products (product_name, product_code) VALUES
('Laptop', 'LP1001'),
('Smartphone', 'SP2002'),
('Tablet', 'TB3003'),
('Smartwatch', 'SW4004');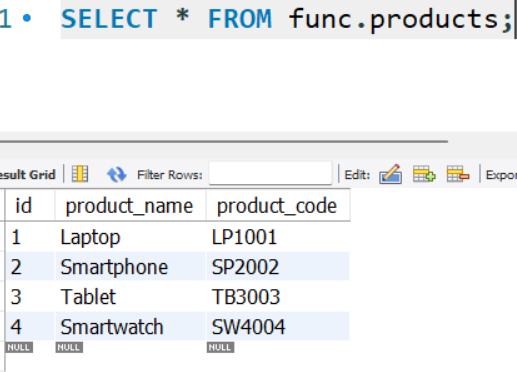
문자열 반환 실습
# 각 상품의 product_code에서 앞의 두 글자만 추출하세요.
SELECT left(product_code, 2)
FROM products;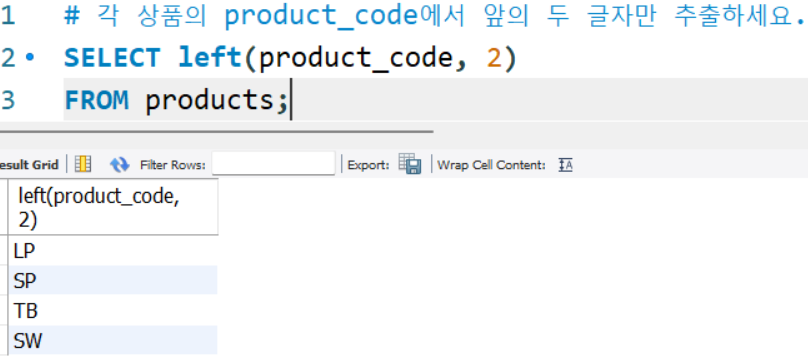
# 각 상품의 product_code에서 뒤의 네 글자만 추출하세요.
SELECT right(product_code, 4)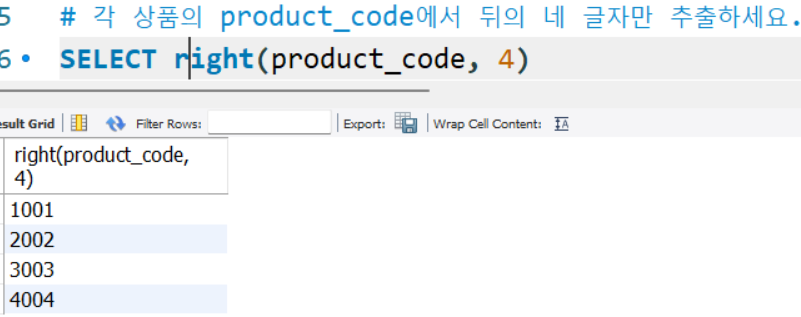
# 각 상품의 product_name의 세 번째 글자부터 4글자를 추출하세요.
SELECT substr(product_code, 3, 4)
FROM products;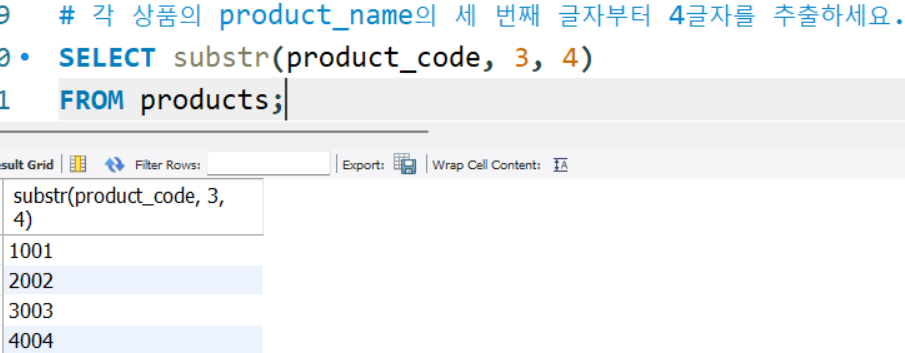
실습 예제 추가
CREATE TABLE customers (
id INT PRIMARY KEY AUTO_INCREMENT,
full_name VARCHAR(100),
email VARCHAR(100)
);
INSERT INTO customers (full_name, email) VALUES
('John Doe', 'john.doe@example.com'),
('Jane Smith', 'jane.smith@domain.org'),
('Michael Johnson', 'michael.johnson@company.net');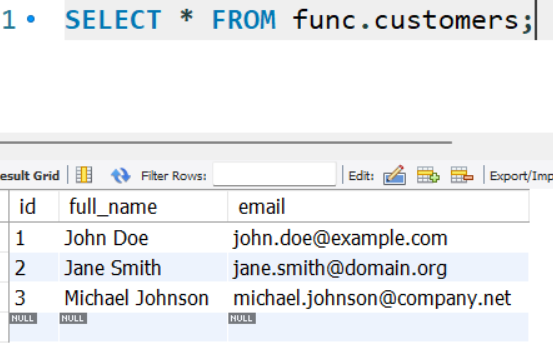
조건 문자열 반환 실습
# 각 고객의 이메일에서 도메인 이름만 추출하세요.
SELECT substring_index(email, '@', -1)
FROM customers;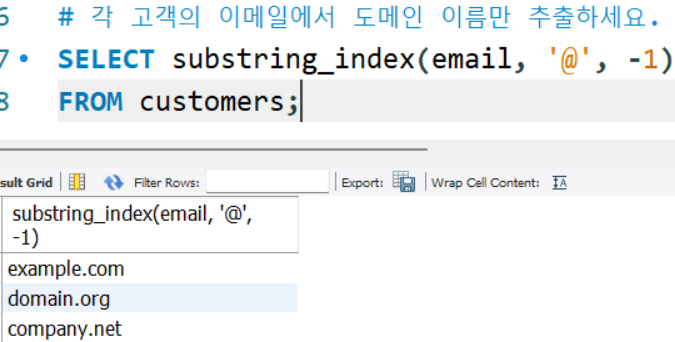
# 각 고객의 이메일에서 '@' 앞부분의 사용자 이름만 추출하세요.
SELECT substring_index(email, '@', 1)
FROM customers;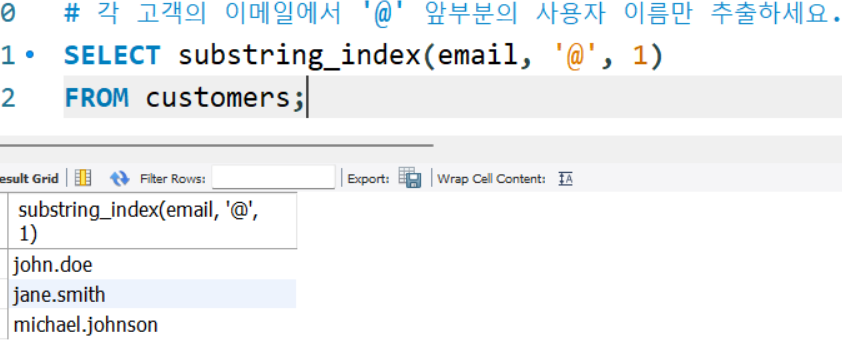
# 각 고객의 full_name에서 성(last name)만 추출하세요.
SELECT substring_index(full_name, ' ', -1) AS 결과
FROM customers;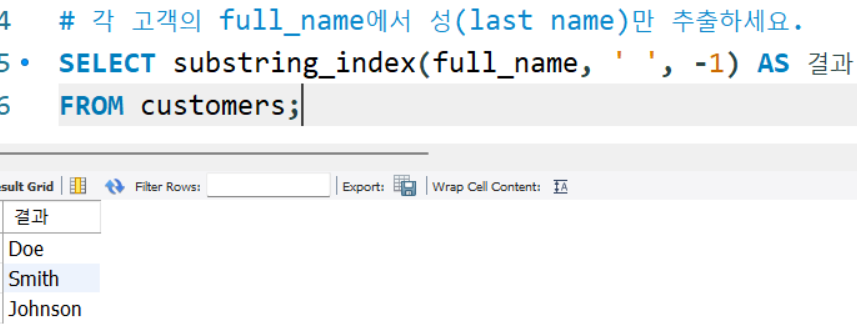
5.5 문자열 변경
lpad(),rpad(),ltrim(),rtraim(),trim()
SELECT lpad('SQL', 10, '#');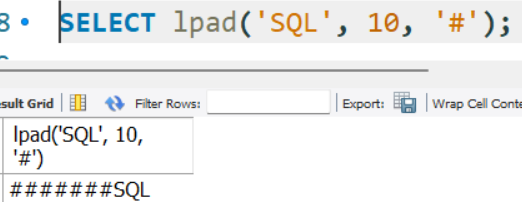
SELECT rpad('SQL', 5, '*');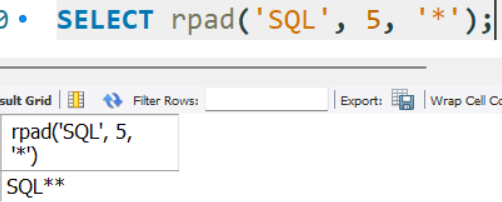
SELECT ltrim(' SQL ') as ltrim결과, #왼쪽 공백제거
rtrim(' SQL ') as rtrim결과, #오른쪽공백제거
length(ltrim(' SQL ')) as ltrim길이결과,
length(rtrim(' SQL ')) as rtrim길이결과;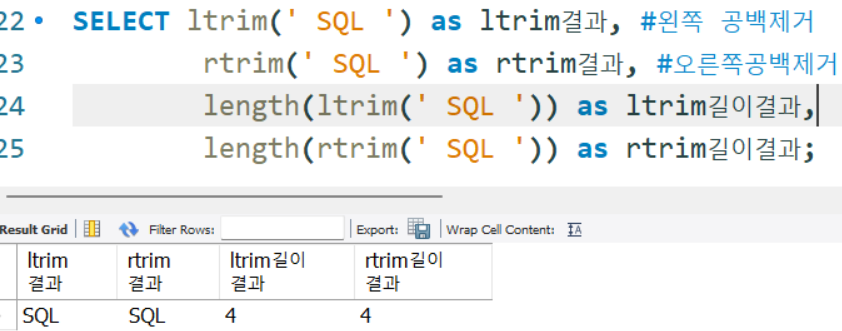
SELECT trim(both 'abc' from 'abcSQLabcabc') as 양쪽제거,
trim(leading 'abc' from 'abcSQLabcabc') as 왼쪽제거,
trim(trailing 'abc' from 'abcSQLabcabc') as 오른쪽제거;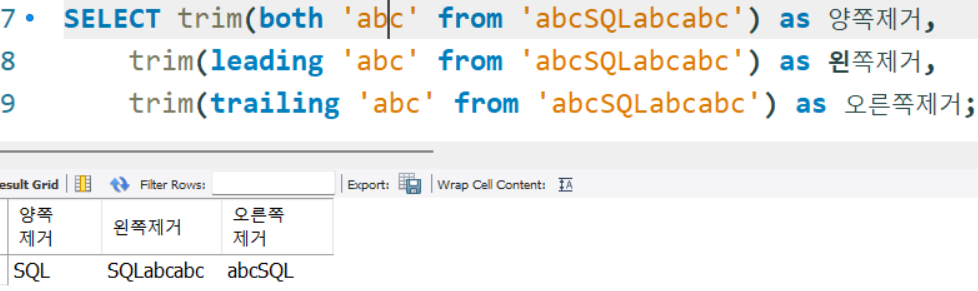
5.6 함수 문제풀이
# product_code가 10자리 숫자가 되도록 왼쪽에 0을 채워 출력하세요.
# product_name의 오른쪽을 길이가 15가 되도록 *로 채워 출력하세요.
SELECT lpad(product_code, 10, '0') as lpad결과,
rpad(product_code, 15, '*') as rpad결과
FROM products;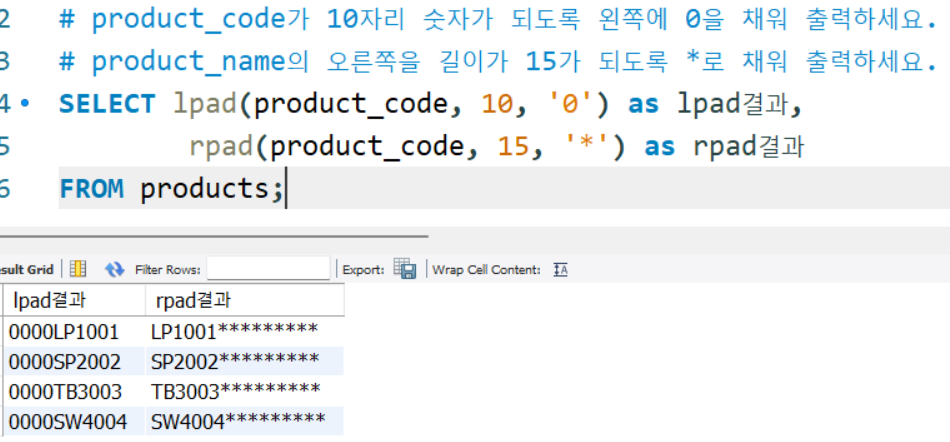
실습 예제 추가
CREATE TABLE contacts (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100),
phone VARCHAR(20)
);
INSERT INTO contacts (name, phone) VALUES
('John Doe', ' 123-456-7890 '),
('Jane Smith', '***555-666-7777***'),
('Mike Johnson', '---888-999-0000---');# phone에서 앞뒤의 공백을 모두 제거하고 출력하세요.
# phone에서 앞의 '*' 문자를 제거하고 출력하세요.
# phone에서 뒤의 '-' 문자를 제거하고 출력하세요.
SELECT trim(both ' ' from phone) AS 공백제거,
trim(leading '*' from phone) AS 별표제거,
trim(trailing '-' from phone) AS 하이픈제거
FROM contacts;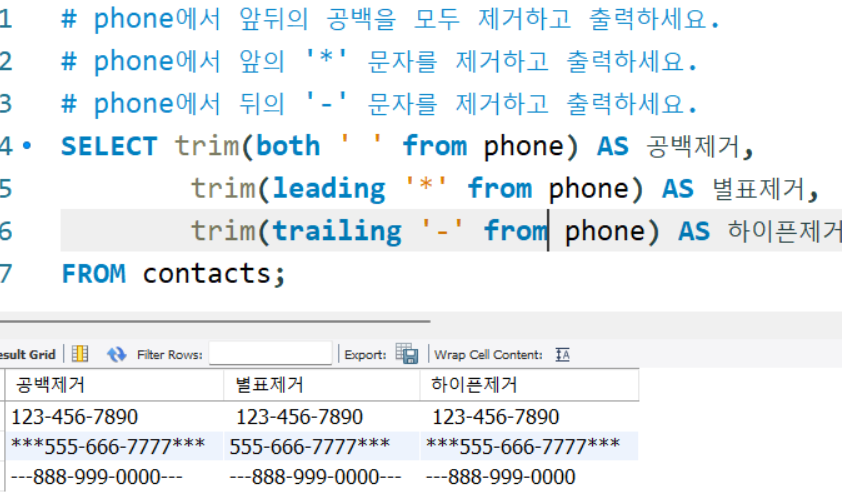
6. SQL - 함수2
색인함수 :
field(),find_in_set(),instr(),locate(),elt()
SELECT field('JAVA', 'SQL', 'JAVA', 'C') as 문자찾기,
find_in_set('JAVA', 'SQL,JAVA,C') as 문자열찾기,
instr('네 인생을 살아라', '인생') as 부분문자열찾기,
locate('인생', '네 인생을 살아라') as 문자를문자열에서찾기,
elt(2, 'SQL', 'JAVA', 'C') as 숫자로문자찾기;
repeat(),replace(),reverse()
SELECT repeat('SQL', 3) as 문자열반복,
replace('010 1234 5678', ' ', '-') as 문자열치환,
reverse('olleh') as 문자열반전;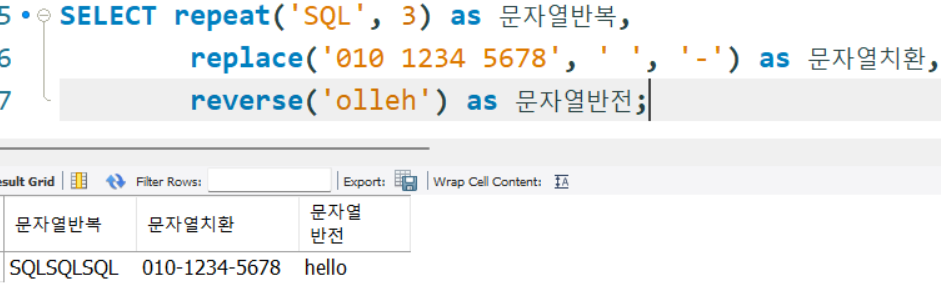
색인함수 실습
CREATE TABLE students (
id INT PRIMARY KEY AUTO_INCREMENT,
student_name VARCHAR(50),
grade INT
);
INSERT INTO students (student_name, grade) VALUES
('Alice', 1),
('Bob', 3),
('Charlie', 2),
('Daisy', 4);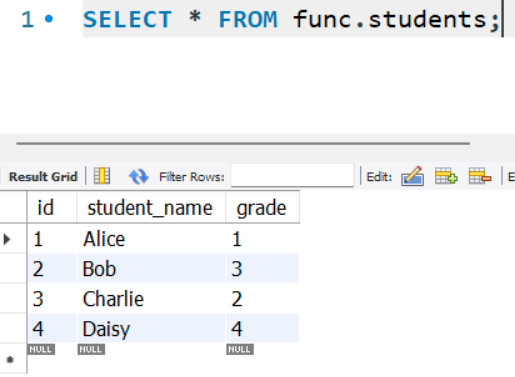
# grade 값에 따라, 각 학생의 등급을 출력하세요.
# 1등은 'Excellent', 2등은 'Good',
# 3등은 'Average', 4등은 'Poor'로 출력되도록 하세요.
SELECT student_name,
REPLACE(
REPLACE(
REPLACE(
REPLACE(
FIELD(grade, 1, 2, 3, 4),
'1', 'Excellent'
),
'2', 'Good'
),
'3', 'Average'
),
'4', 'Poor'
) AS 등급
FROM students;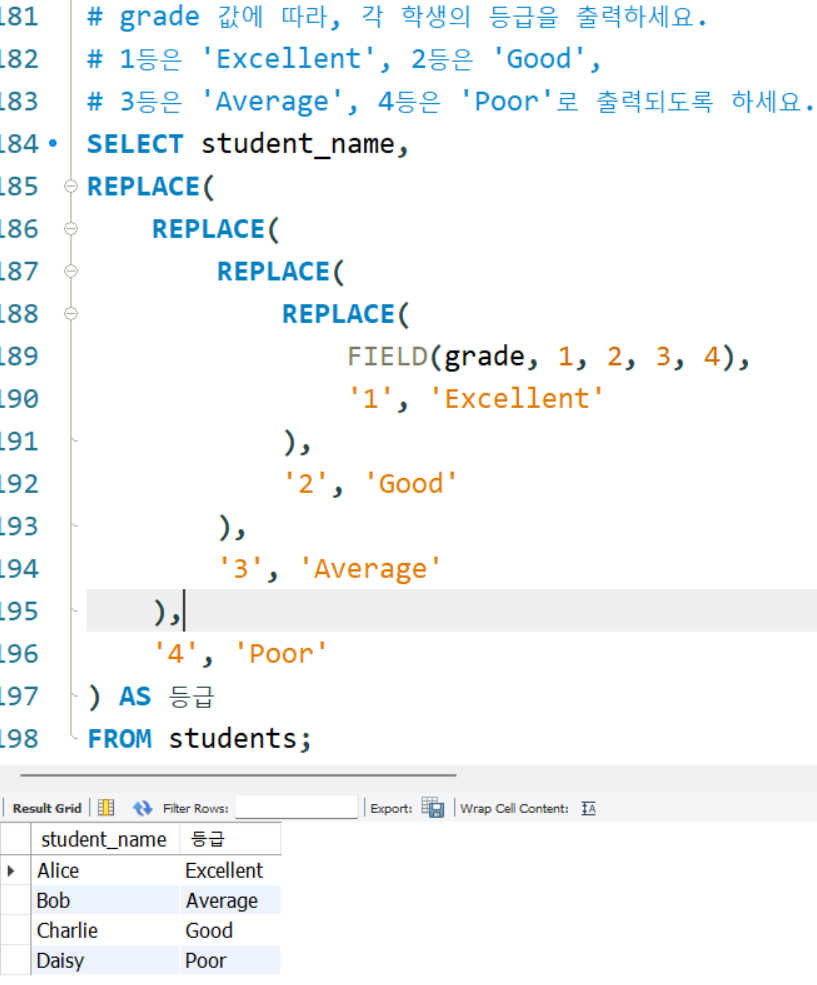
물론 위 코드보다는 elt()를 활용하는게 더 효율적이다.
SELECT student_name,
elt(grade, 'Excellent', 'Good', 'Average', 'Poor') AS 결과
FROM students;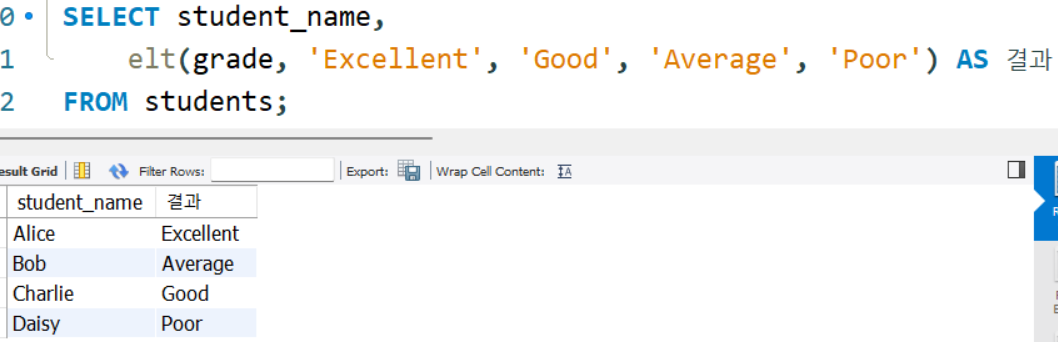
문자열 반복 실습
CREATE TABLE products_rating (
id INT PRIMARY KEY AUTO_INCREMENT,
product_name VARCHAR(50),
rating INT
);
INSERT INTO products_rating (product_name, rating) VALUES
('Laptop', 5),
('Smartphone', 4),
('Tablet', 3),
('Smartwatch', 2);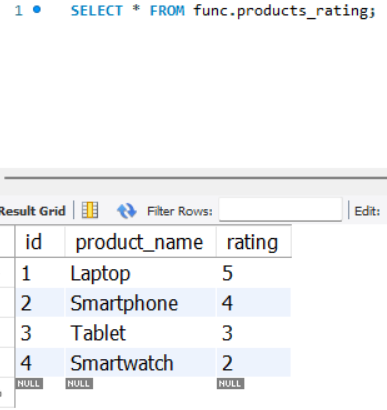
# 각 상품의 rating 값을 별표()로 시각적으로 표현하세요.
# 예를 들어, rating이 5이면 별표 5개,
# rating이 3이면 별표 3개를 출력하세요.
SELECT repeat('*', rating) as 반복결과
from products_rating;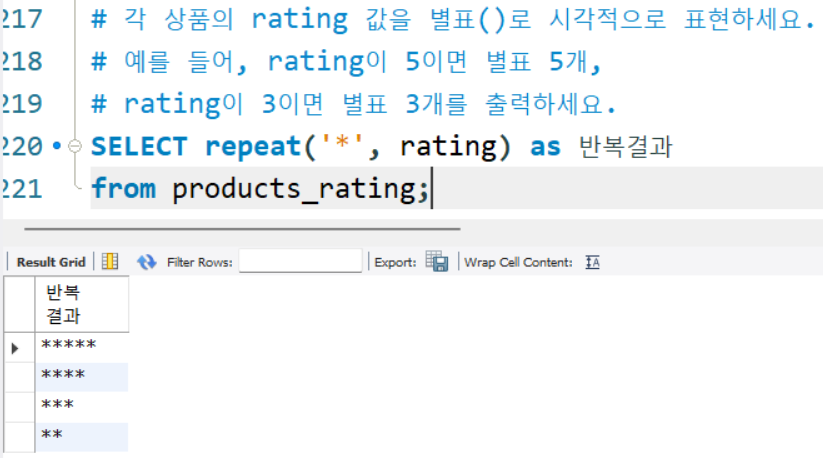
# 1. 각 사용자의 `username`을 역순으로 출력하세요.
# 2. 각 사용자의 이메일 주소를 역순으로 출력하세요.
SELECT reverse(name) as 이름역순,
reverse(email) as 이메일역순
FROM users;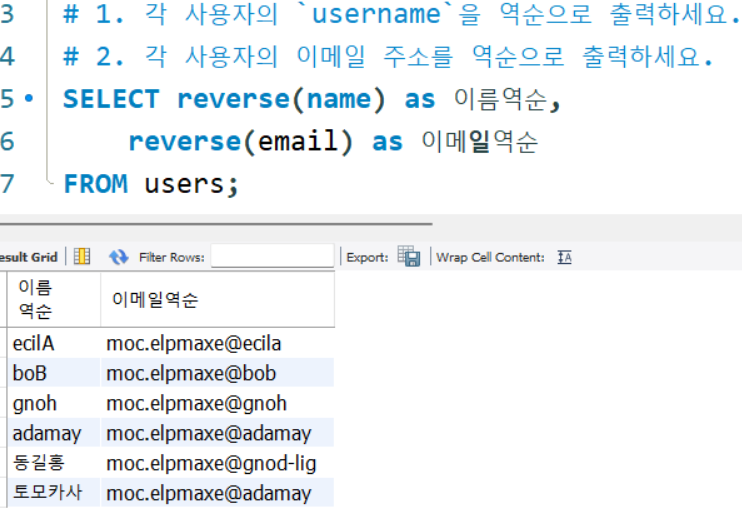
7. SQL - 숫자형함수
ceiling(),floor(),round(),truncate()
SELECT
ceiling(123.56) as 올림,
floor(123.56) as 내림,
round(123.56, 1) as 지정위치에서반올림,
truncate(123.56, 1) as 지정한위치에서버림;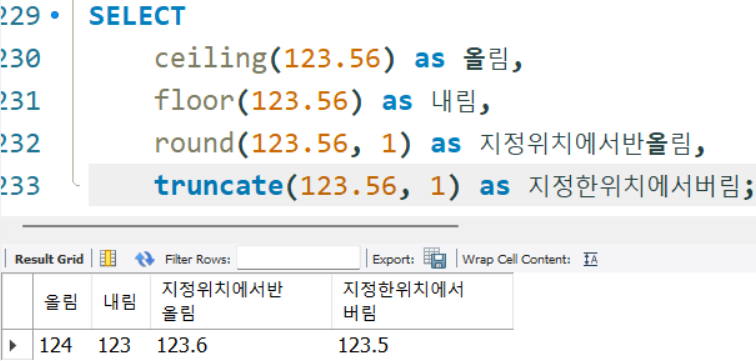
abs(),sign()
SELECT
abs(-120) as 절대값,
abs(120) as 절대값,
sign(-120) as 음수양수판별,
sign(120) as 음수양수판별;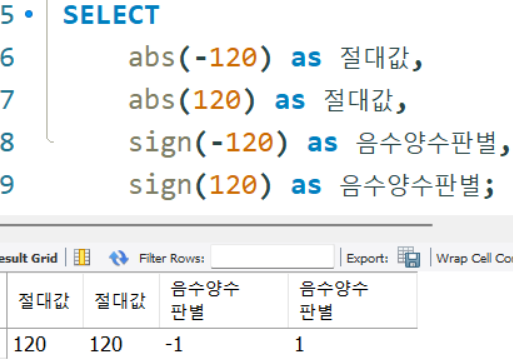
mod(),power(),sqrt(),rand()
SELECT
mod(203, 4) as 나머지,
power(2, 3) as 제곱,
sqrt(16) as 제곱근,
rand() as 랜덤생성,
rand(42) as '랜덤(시드)생성',
round(rand(42)*100) as 랜덤생성2;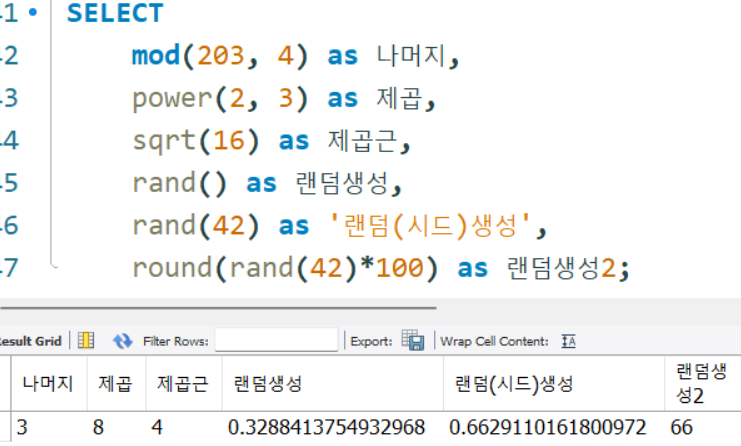
숫자형 함수 실습
CREATE TABLE prices (
id INT PRIMARY KEY AUTO_INCREMENT,
product_name VARCHAR(100),
price DECIMAL(10, 2)
);
INSERT INTO prices (product_name, price) VALUES
('Laptop', 1234.56),
('Smartphone', 987.65),
('Tablet', 432.10),
('Smartwatch', 567.89);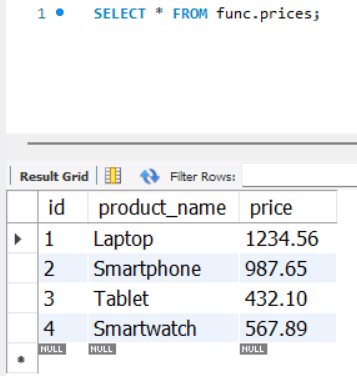
# `prices`내 숫자를 올림/버림/반올림/반버림 적용
SELECT product_name,
ceiling(price) as 올림,
floor(price) as 버림,
round(price, 2) as 소수점반올림,
truncate(price, 1) as 소수점반버림
FROM prices;
CREATE TABLE transactions (
id INT PRIMARY KEY AUTO_INCREMENT,
transaction_amount DECIMAL(10, 2)
);
INSERT INTO transactions (transaction_amount) VALUES
(123.45),
(-678.90),
(0.00),
(345.67),
(-234.56);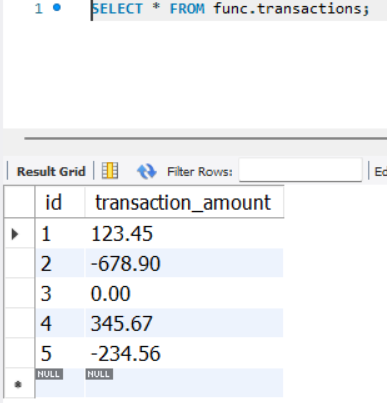
# 절대값 전환 및 음수/양수 판별
SELECT abs(transaction_amount) as 절대값,
sign(transaction_amount) as 음수양수판별
FROM transactions;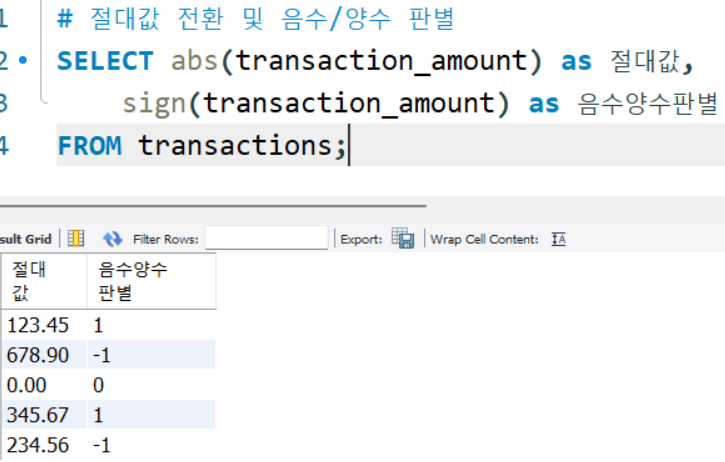
CREATE TABLE items (
id INT PRIMARY KEY AUTO_INCREMENT,
item_name VARCHAR(100),
quantity INT,
base_value DECIMAL(10, 2)
);
INSERT INTO items (item_name, quantity, base_value) VALUES
('Laptop', 10, 2.00),
('Smartphone', 15, 4.00),
('Tablet', 7, 9.00),
('Smartwatch', 20, 16.00);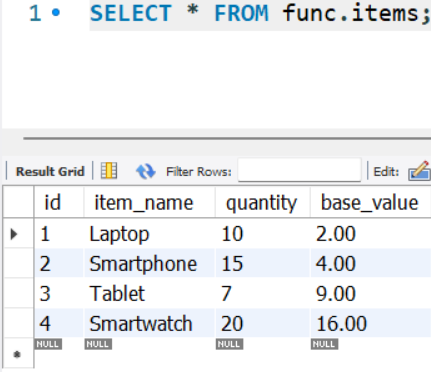
# 각종 나머지, 제곱, 제곱근, 난수 생성
SELECT mod(quantity, 3) as 나머지,
IF(mod(quantity, 5) = 0, '맞음', '아님') as 5의배수,
power(base_value, 3) as 제곱,
sqrt(base_value) as 제곱근,
rand() as 랜덤생성
FROM items;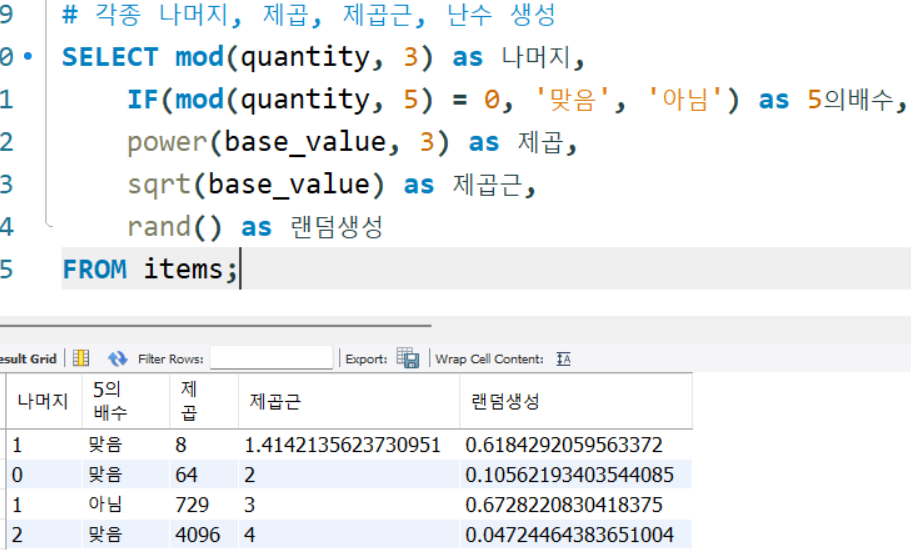
8. SQL - 날짜/시간함수
now(),sysdate(),curdate(),curtime()
현재 날짜와 시간을 다양한 형태로 출력
SELECT
now() as `현재날짜+시간`,
sysdate() as `시스템날짜+시간`,
curdate() as 현재날짜,
curtime() as 현재시간;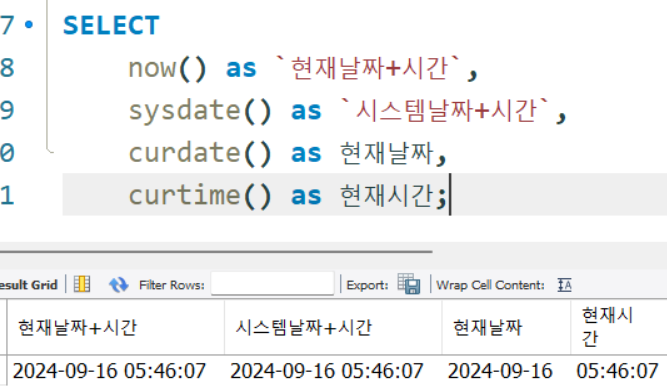
year(),quarter(),month(),day(),hour(),minute(),second()
입력된 시간을 다양한 표현으로 출력
SELECT now() as `현재날짜+시간`,
year(now()) as 연도출력,
quarter(now()) as 분기출력,
month(now()) as '월 출력',
day(now()) as '일 출력',
hour(now()) as '시 출력',
minute(now()) as '분 출력',
second(now()) as '초 출력';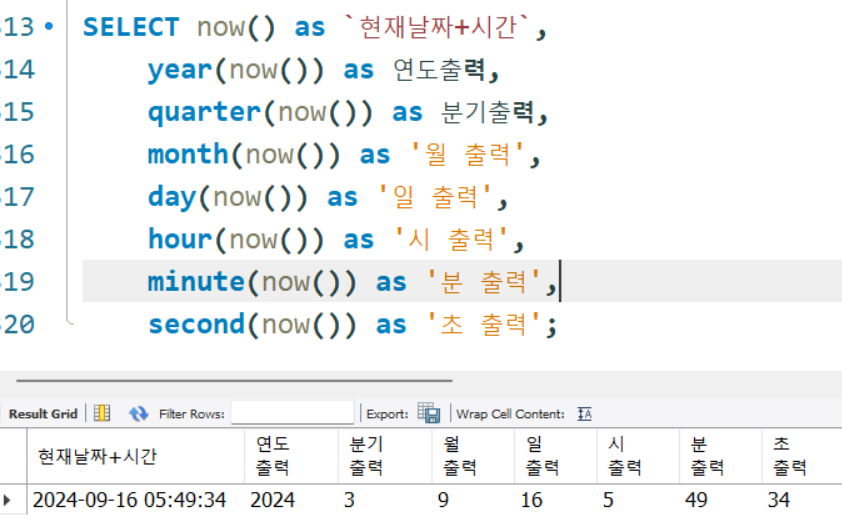
datediff(),timestampdiff()
기간을 출력하는 함수
SELECT datediff('2025-12-20', NOW()) AS 기간,
datediff(NOW(), '2025-12-20') AS 기간2,
timestampdiff(year, NOW(), '2025-12-20') AS 연_단위기간,
timestampdiff(month, NOW(), '2025-12-20') AS 달_단위기간,
timestampdiff(day, '2025-12-20', NOW()) AS 일_단위기간;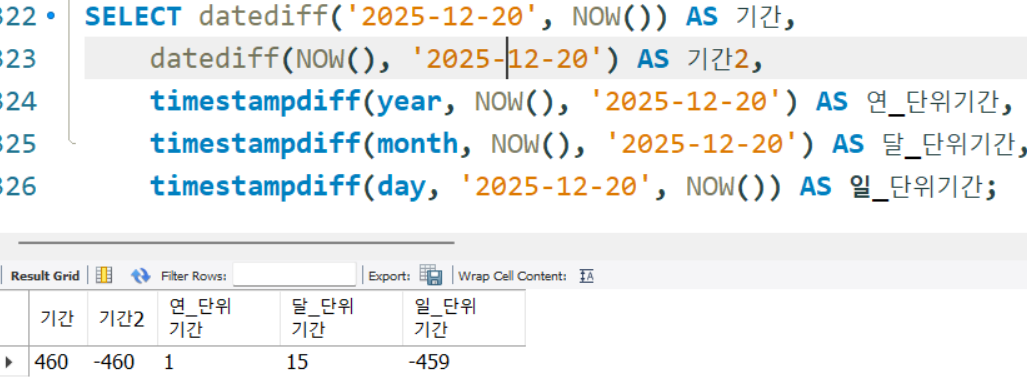
adddate(),subdate()
기간 가산/감산 함수
SELECT now() as '현재시간',
adddate(now(), 50) as '50일 후',
adddate(now(), interval 50 year) as '50년 후',
adddate(now(), interval 50 month) as '50달 후',
adddate(now(), interval 50 hour) as '50시간 후',
subdate(now(), 50) as '50일 전',
subdate(now(), interval 50 year) as '50년 전',
subdate(now(), interval 50 month) as '50달 전',
subdate(now(), interval 50 hour) as '50시간 전';
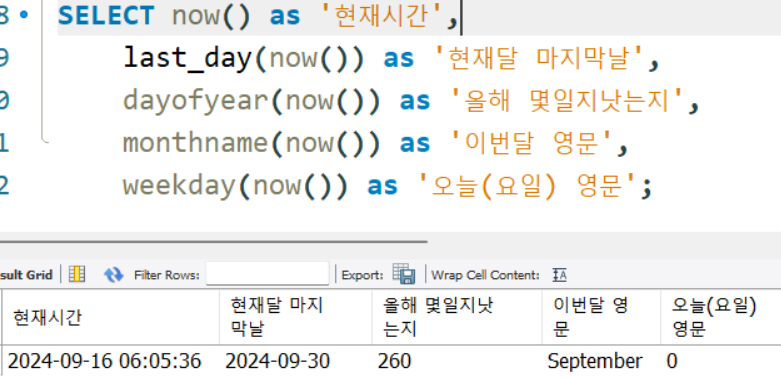
last_day(),dayofyear(),monthname(),weekday()
기타 시간함수...
SELECT now() as '현재시간',
last_day(now()) as '현재달 마지막날',
dayofyear(now()) as '올해 몇일지낫는지',
monthname(now()) as '이번달 영문',
weekday(now()) as '오늘(요일) 영문';